Tutorial: Konfigurieren einer Verfügbarkeitsgruppe in mehreren Subnetzen (SQL Server auf virtuellen Azure-Computern)
Gilt für:![]() SQL Server auf Azure-VM
SQL Server auf Azure-VM
Tipp
Es gibt viele Methoden zum Bereitstellen einer Verfügbarkeitsgruppe. Vereinfachen Sie Ihre Bereitstellung, indem Sie Ihre SQL Server-VMs in mehreren Subnetzen innerhalb desselben virtuellen Azure-Netzwerks erstellen. So benötigen Sie weder eine Azure Load Balancer-Instanz noch einen verteilten Netzwerknamen (DNN) für Ihre Always On-Verfügbarkeitsgruppe. Wenn Sie Ihre Verfügbarkeitsgruppe bereits in einem einzelnen Subnetz erstellt haben, können Sie sie in eine Umgebung mit mehreren Subnetzen migrieren.
In diesem Tutorial erfahren Sie, wie Sie eine Always On-Verfügbarkeitsgruppe für SQL Server auf virtuellen Azure-Computern (Virtual Machines, VMs) in mehreren Subnetzen erstellen. In diesem umfassenden Tutorial werden ein Windows Server-Failovercluster und eine Verfügbarkeitsgruppe mit zwei SQL Server-Replikaten und einem Listener erstellt.
Voraussichtliche Dauer: Wenn die Vorbereitungen abgeschlossen sind, dauert dieses Tutorial etwa 30 Minuten.
Voraussetzungen
Die folgende Tabelle gibt Aufschluss über die Voraussetzungen, die erfüllt sein müssen, bevor Sie mit dem Tutorial beginnen:
| Anforderung | Beschreibung |
|---|---|
 Zwei SQL Server-Instanzen Zwei SQL Server-Instanzen |
– Jeder virtuelle Computer in zwei verschiedenen Azure-Verfügbarkeitszonen oder in der gleichen Verfügbarkeitsgruppe – In separaten Subnetzen innerhalb eines virtuellen Azure-Netzwerks – Mit zwei sekundären IP-Adressen, die den einzelnen virtuellen Computern zugewiesen sind – In einer einzelnen Domäne |
| SQL Server-Dienstkonto |
Ein Domänenkonto, das vom SQL Server-Dienst für die einzelnen Computer verwendet wird |
| Offene Firewallports |
– SQL Server: 1433 für die Standardinstanz – Datenbankspiegelungs-Endpunkt: 5022 oder ein beliebiger verfügbarer Port |
| Domäneninstallationskonto |
– Lokaler Administrator in jedem SQL Server - Mitglied der festen SQL Server-Serverrolle „SysAdmin“ für jede Instanz von SQL Server |
In dieses Tutorial werden Grundkenntnisse im Zusammenhang mit SQL Server-Always On-Verfügbarkeitsgruppen vorausgesetzt.
Erstellen Sie den Cluster.
Die Always On-Verfügbarkeitsgruppe basiert auf der Infrastruktur des Windows Server-Failoverclusters. Daher muss vor dem Bereitstellen der Verfügbarkeitsgruppe zuerst der Windows Server-Failovercluster konfiguriert werden. Dies umfasst das Hinzufügen des Features, das Erstellen des Clusters und das Festlegen der Cluster-IP-Adresse.
Hinzufügen des Failoverclusterfeatures
Fügen Sie das Failoverclusterfeature beiden SQL Server-VMs hinzu. Gehen Sie dazu folgendermaßen vor:
Stellen Sie unter Verwendung eines Domänenkontos, das über Berechtigungen zum Erstellen von Objekten in AD verfügt, eine RDP-Verbindung (Remotedesktopprotokoll) mit dem virtuellen SQL Server-Computer her. Als Domänenkonto können Sie beispielsweise das Konto CORP\Install verwenden, das im Artikel zu den Voraussetzungen erstellt wurde.
Öffnen Sie das Server-Manager-Dashboard.
Wählen Sie im Dashboard den Link Rollen und Features hinzufügen aus.
Wählen Sie Weiter aus, bis Sie zum Abschnitt Serverfeatures gelangen.
Wählen Sie in Features die Option Failoverclustering.
Fügen Sie zusätzliche erforderliche Features hinzu.
Wählen Sie Installieren aus, um die Features hinzuzufügen.
Wiederholen Sie diese Schritte auf dem anderen virtuellen SQL Server-Computer.
Cluster erstellen
Wenn das Clusterfeature den SQL Server-VMs hinzugefügt wurde, können Sie den Windows Server-Failovercluster erstellen.
Führen Sie zum Erstellen des Clusters die folgenden Schritte aus:
Stellen Sie unter Verwendung eines Domänenkontos, das über Berechtigungen zum Erstellen von Objekten in AD verfügt (beispielsweise das Domänenkonto CORP\Install, das im Artikel zu den Voraussetzungen erstellt wurde) eine RDP-Verbindung mit der ersten SQL Server-VM (beispielsweise SQL-VM-1) her.
Wählen Sie im Dashboard Server-Manager die Option Tools aus, und klicken Sie dann auf Failovercluster-Manager.
Klicken Sie im linken Bereich mit der rechten Maustaste auf Failovercluster-Manager, und klicken Sie anschließend auf Cluster erstellen.
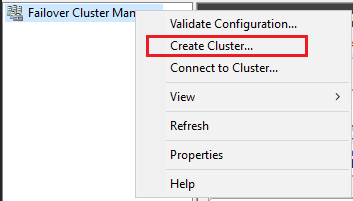
Erstellen Sie im Clustererstellungs-Assistenten einen Cluster mit zwei Knoten, indem Sie die Seiten durchlaufen und dabei die Einstellungen aus der folgenden Tabelle verwenden:
Seite Einstellungen Vorbereitungen Verwenden Sie Standardwerte. Server auswählen Geben Sie unter Servernamen eingeben den Namen der ersten SQL Server-Instanz (beispielsweise SQL-VM-1) ein, und wählen Sie Hinzufügen aus.
Geben Sie unter Servernamen eingeben den Namen der zweiten SQL Server-Instanz (beispielsweise SQL-VM-2) ein, und wählen Sie Hinzufügen aus.Validierungswarnung Wählen Sie Ja. Beim Klicken auf "Weiter" Konfigurationsvalidierungstests ausführen. Danach Erstellung des Clusters fortsetzen. aus. Voraussetzungen Klicken Sie auf Weiter. „Testoptionen“ Wählen Sie Nur ausgewählte Tests ausführen aus. Testauswahl Deaktivieren Sie die Option für den Speicher. Achten Sie darauf, dass Bestand, Netzwerk und Systemkonfiguration ausgewählt sind. Bestätigung Klicken Sie auf Weiter.
Warten Sie, bis die Überprüfung abgeschlossen ist.
Wählen Sie Bericht anzeigen aus, um den Bericht zu überprüfen. Die Warnung, dass virtuelle Computer nur über eine einzelne Netzwerkschnittstelle erreichbar sind, kann gefahrlos ignoriert werden. Da die Azure-Infrastruktur über physische Redundanz verfügt, müssen keine weiteren Netzwerkschnittstellen hinzugefügt werden.
Wählen Sie Fertig stellen aus.Zugriffspunkt für die Clusterverwaltung Geben Sie unter Clustername einen Clusternamen ein (beispielsweise SQLAGCluster1). Bestätigung Deaktivieren Sie Der gesamte geeignete Speicher soll dem Cluster hinzugefügt werden. , und wählen Sie Weiter aus. Zusammenfassung Wählen Sie Fertig stellen aus. Warnung
Wenn Sie das Kontrollkästchen Der gesamte geeignete Speicher soll dem Cluster hinzugefügt werden. nicht deaktivieren, trennt Windows die virtuellen Datenträger während des Clusterprozesses. Sie werden daher erst im Datenträger-Manager oder -Explorer angezeigt, nachdem der Speicher aus dem Cluster entfernt und mithilfe von PowerShell erneut angefügt wurde.
Festlegen der IP-Adresse des Failoverclusters
Üblicherweise entspricht die dem Cluster zugewiesene IP-Adresse der IP-Adresse, die auch dem virtuellen Computer zugewiesen ist. Das bedeutet, dass sich die IP-Adresse des Clusters in Azure in einem fehlerhaften Zustand befindet und nicht online geschaltet werden kann. Ändern Sie die IP-Adresse des Clusters, um die IP-Ressource online zu schalten.
Im Rahmen der Vorbereitung haben Sie den einzelnen SQL Server-VMs jeweils sekundäre IP-Adressen zugewiesen, wie in der folgenden Beispieltabelle dargestellt. (Ihre spezifischen IP-Adressen können davon abweichen.)
| VM-Name | Subnetzname | Subnetzadressbereich | Name der sekundären IP-Adresse | Sekundäre IP-Adresse |
|---|---|---|---|---|
| SQL-VM-1 | SQL-subnet-1 | 10.38.1.0/24 | windows-cluster-ip | 10.38.1.10 |
| SQL-VM-2 | SQL-subnet-2 | 10.38.2.0/24 | windows-cluster-ip | 10.38.2.10 |
Weisen Sie diese IP-Adressen als Cluster-IP-Adressen für jedes relevante Subnetz zu.
Hinweis
Unter Windows Server 2019 wird durch den Cluster anstelle des Clusternetzwerknamens ein Name des verteilten Servers erstellt, und das Clusternamenobjekt (CNO) wird automatisch mit den IP-Adressen für alle Knoten im Cluster registriert, wodurch keine dedizierte Windows-Cluster-IP-Adresse benötigt wird. Falls Sie Windows Server 2019 verwenden, können Sie diesen Abschnitt sowie alle anderen Schritte überspringen, die sich auf die Clusterkernressourcen beziehen. Alternativ können Sie mithilfe von PowerShell einen VNN-basierten Cluster (Virtual Network Name, Name des virtuellen Netzwerks) erstellen. Weitere Informationen finden Sie im Blog Failovercluster: Clusternetzwerkobjekt.
Führen Sie die folgenden Schritte aus, um die IP-Adresse des Clusters zu ändern:
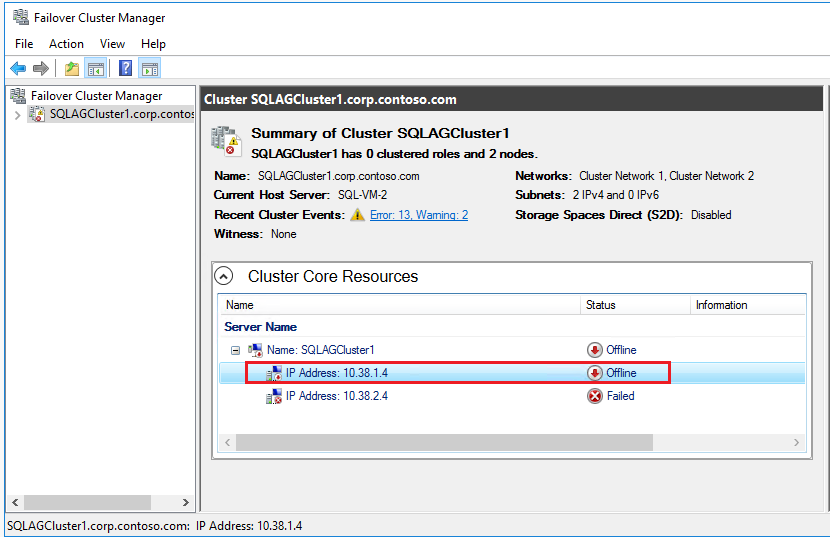
Scrollen Sie im Failovercluster-Manager nach unten bis zu Hauptressourcen des Clusters, und erweitern Sie die Clusterdetails. Dort sollten der Name sowie zwei Ressourcen vom Typ IP-Adresse aus den einzelnen Subnetzen mit dem Zustand Fehler angezeigt werden.
Klicken Sie mit der rechten Maustaste auf die erste fehlerhafte Ressource vom Typ IP-Adresse, und wählen Sie Eigenschaften aus.
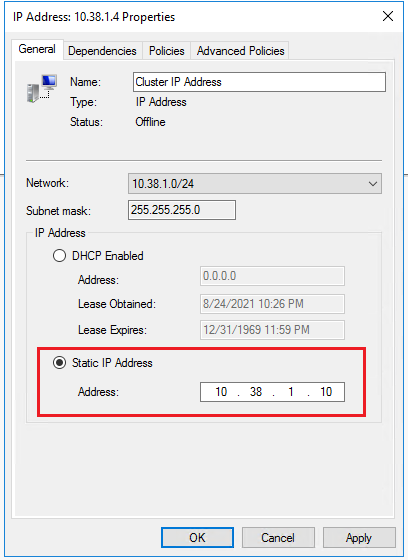
Wählen Sie Statische IP-Adresse aus, und aktualisieren Sie die IP-Adresse auf die dedizierte Windows-Cluster-IP-Adresse in dem Subnetz, das Sie der ersten SQL Server-VM (beispielsweise SQL-VM-1) zugewiesen haben. Klicken Sie auf OK.
Wiederholen Sie die Schritte für die zweite fehlerhafte Ressource vom Typ IP-Adresse. Verwenden Sie dabei die dedizierte Windows-Cluster-IP-Adresse für das Subnetz der zweiten SQL Server-VM (beispielsweise SQL-VM-2).

Klicken Sie im Abschnitt Hauptressourcen des Clusters mit der rechten Maustaste auf den Clusternamen, und klicken Sie anschließend auf Online schalten. Warten Sie, bis der Name und eine der IP-Adressressourcen online sind.
Da sich die SQL Server-VMs in unterschiedlichen Subnetzen befinden, weist der Cluster eine OR-Abhängigkeit von den beiden dedizierten Windows-Cluster-IP-Adressen auf. Beim Onlineschalten der Clusternamenressource wird für den Domänencontrollerserver (DC) das Computerkonto in Active Directory (AD) aktualisiert. Wenn die Clusterkernressourcen auf einen anderen Knoten verlagert werden, wird eine IP-Adresse offline geschaltet, während die andere online geschaltet wird, und der DC-Server wird mit der neuen IP-Adresszuordnung aktualisiert.
Tipp
Wenn Sie den Cluster auf virtuellen Azure-Computern in einer Produktionsumgebung ausführen, ändern Sie die Clustereinstellungen in einen weniger strengen Überwachungsstatus, um die Clusterstabilität und -zuverlässigkeit in einer Cloudumgebung zu verbessern. Weitere Informationen finden Sie in der Checkliste des Artikels „Bewährte Methoden der HADR-Konfiguration (SQL Server auf Azure-VMs)“.
Konfigurieren des Quorums
In einem Cluster mit zwei Knoten ist ein Quorumgerät erforderlich, um die Zuverlässigkeit und Stabilität des Clusters zu gewährleisten. Auf virtuellen Azure-Computern ist der Cloudzeuge die empfohlene Quorumkonfiguration. Es stehen aber auch noch andere Optionen zur Verfügung. In diesem Abschnitt wird ein Cloudzeuge für das Quorum konfiguriert. Ermitteln Sie die Zugriffsschlüssel für das Speicherkonto, und konfigurieren Sie dann den Cloudzeugen.
Abrufen der Zugriffsschlüssel für das Speicherkonto
Wenn Sie ein Microsoft Azure Storage-Konto erstellen, werden ihm zwei automatisch generierte Zugriffsschlüssel zugeordnet: ein primärer und ein sekundärer Zugriffsschlüssel. Wenn Sie den Cloudzeugen zum ersten Mal erstellen, muss der primäre Zugriffsschlüssel verwendet werden. Danach gibt es hinsichtlich des Schlüssels, der für den Cloudzeugen verwendet werden soll, keine Einschränkungen mehr.
Verwenden Sie das Azure-Portal, um Speicherzugriffsschlüssel für das im Artikel mit den Voraussetzungen erstellte Azure Storage-Konto anzuzeigen und zu kopieren.
Führen Sie die folgenden Schritte aus, um die Speicherzugriffsschlüssel anzuzeigen und zu kopieren:
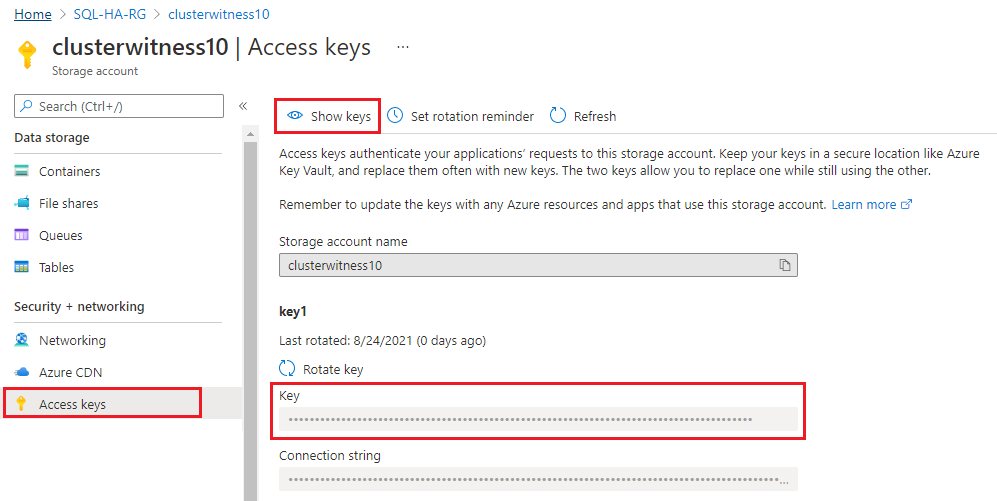
Navigieren Sie im Azure-Portal zu Ihrer Ressourcengruppe, und wählen Sie das von Ihnen erstellte Speicherkonto aus.
Wählen Sie unter Sicherheit + Netzwerkbetrieb die Option Zugriffsschlüssel aus.
Wählen Sie Schlüssel anzeigen aus, und kopieren Sie den Schlüssel.
Konfigurieren des Cloudzeugen
Nachdem Sie den Zugriffsschlüssel kopiert haben, können Sie den Cloudzeugen für das Clusterquorum erstellen.
Führen Sie die folgenden Schritte aus, um den Cloudzeugen zu erstellen:
Stellen Sie eine Remotedesktopverbindung mit der ersten SQL Server-VM (SQL-VM-1) her.
Öffnen Sie Windows PowerShell im Administratormodus.
Führen Sie das PowerShell-Skript aus, um den TLS-Wert (Transport Layer Security) für die Verbindung auf „1.2“ festzulegen:
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12Verwenden Sie PowerShell, um den Cloudzeugen zu konfigurieren. Ersetzen Sie die Werte für Speicherkontoname und Zugriffsschlüssel durch Ihre spezifischen Informationen:
Set-ClusterQuorum -CloudWitness -AccountName "Storage_Account_Name" -AccessKey "Storage_Account_Access_Key"Die folgenden Beispielausgabe gibt an, dass der Vorgang erfolgreich war:

Die Clusterkernressourcen sind mit einem Cloudzeugen konfiguriert.
Aktivieren des Verfügbarkeitsgruppenfeatures
Das Feature „Always On-Verfügbarkeitsgruppe“ ist standardmäßig deaktiviert. Verwenden Sie den SQL Server-Konfigurations-Manager, um das Feature für beide SQL Server-Instanzen zu aktivieren.
Führen Sie die folgenden Schritte aus, um das Verfügbarkeitsgruppenfeature zu aktivieren:
Starten Sie die RDP-Datei auf der ersten SQL Server-VM (beispielsweise SQL-VM-1) mit einem Domänenkonto, das Mitglied der festen Serverrolle „sysadmin“ ist (beispielsweise das Domänenkonto CORP\Install, das im Rahmen der Vorbereitung erstellt wurde).
Starten Sie auf dem Bildschirm Start einer Ihrer SQL Server-VMs den SQL Server-Konfigurations-Manager.
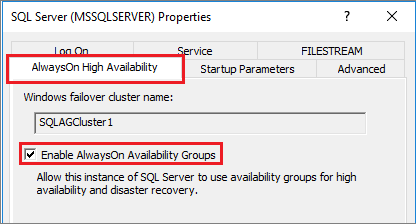
Markieren Sie in der Browserstruktur die Option SQL Server-Dienste, klicken Sie mit der rechten Maustaste auf den Dienst SQL Server (MSSQLSERVER) , und wählen Sie anschließend Eigenschaften aus.
Aktivieren Sie auf der Registerkarte Always On-Hochverfügbarkeit das Kontrollkästchen Always On-Verfügbarkeitsgruppen aktivieren:
Wählen Sie Übernehmen. Klicken Sie im Popupdialogfenster auf OK.
Starten Sie den SQL Server-Dienst neu.
Wiederholen Sie diese Schritte für die andere SQL Server-Instanz.
FILESTREAM-Feature aktivieren
Wenn Sie FILESTREAM nicht für Ihre Datenbank in der Verfügbarkeitsgruppe verwenden, überspringen Sie diesen Schritt, und wechseln Sie zum nächsten Schritt – Datenbank erstellen.
Wenn Sie beabsichtigen, ihrer Verfügbarkeitsgruppe, die FILESTREAM verwendet, eine Datenbank hinzuzufügen, muss FILESTREAM aktiviert werden, da das Feature standardmäßig deaktiviert ist. Verwenden Sie den SQL Server-Konfigurations-Manager, um das Feature für beide SQL Server-Instanzen zu aktivieren.
Gehen Sie folgendermaßen vor, um dieses FILESTREAM-Feature zu aktivieren:
Starten Sie die RDP-Datei auf der ersten SQL Server-VM (beispielsweise SQL-VM-1) mit einem Domänenkonto, das Mitglied der festen Serverrolle „sysadmin“ ist (beispielsweise das Domänenkonto CORP\Install, das im Rahmen der Vorbereitung erstellt wurde).
Starten Sie auf dem Bildschirm Start einer Ihrer SQL Server-VMs den SQL Server-Konfigurations-Manager.
Markieren Sie in der Browserstruktur die Option SQL Server-Dienste, klicken Sie mit der rechten Maustaste auf den Dienst SQL Server (MSSQLSERVER) , und wählen Sie anschließend Eigenschaften aus.
Wählen Sie die Registerkarte FILESTREAM und aktivieren Sie das Kontrollkästchen FILESTREAM für Transact-SQL-Zugriff aktivieren.
Wählen Sie Übernehmen. Klicken Sie im Popupdialogfenster auf OK.
Klicken Sie in SQL Server Management Studio auf Neue Abfrage, um den Abfrage-Editor anzuzeigen.
Geben Sie im Abfrage-Editor den folgenden Transact-SQL-Code ein:
EXEC sp_configure filestream_access_level, 2 RECONFIGUREKlicken Sie auf Ausführen.
Starten Sie den SQL Server-Dienst neu.
Wiederholen Sie diese Schritte für die andere SQL Server-Instanz.
Erstellen einer Datenbank
Für Ihre Datenbank können Sie entweder die Schritte in diesem Abschnitt ausführen, um eine neue Datenbank zu erstellen, oder aber eine AdventureWorks-Datenbank wiederherstellen. Die Datenbank muss außerdem gesichert werden, um die Protokollkette zu initiieren. Nicht gesicherte Datenbanken erfüllen nicht die Voraussetzungen für eine Verfügbarkeitsgruppe.
Führen Sie die folgenden Schritte aus, um eine Datenbank zu erstellen:
- Starten Sie die RDP-Datei auf der ersten SQL Server-VM (beispielsweise SQL-VM-1) mit einem Domänenkonto, das Mitglied der festen Serverrolle „sysadmin“ ist (beispielsweise das Domänenkonto CORP\Install, das im Rahmen der Vorbereitung erstellt wurde).
- Öffnen Sie SQL Server Management Studio, und stellen Sie eine Verbindung mit der SQL Server-Instanz her.
- Klicken Sie im Objekt-Explorer mit der rechten Maustaste auf Datenbanken, und klicken Sie anschließend auf Neue Datenbank.
- Geben Sie unter Datenbankname den Namen MyDB1 ein.
- Wählen Sie auf der Seite Optionen in der Dropdownliste Wiederherstellungsmodell die Option Vollständig aus, sofern diese Option nicht ohnehin standardmäßig festgelegt ist. Die Datenbank muss sich im vollständigen Wiederherstellungsmodus befinden, um Teil einer Verfügbarkeitsgruppe werden zu können.
- Wählen Sie OK aus, um die Seite Neue Datenbank zu schließen und die neue Datenbank zu erstellen.
Führen Sie die folgenden Schritte aus, um die Datenbank zu sichern:
Klicken Sie im Objekt-Explorer mit der rechten Maustaste auf die Datenbank, markieren Sie Aufgaben, und wählen Sie anschließend Sichern... aus.
Wählen Sie OK aus, um am Standardspeicherort für Sicherungen eine vollständige Sicherung der Datenbank zu erstellen.
Erstellen einer Dateifreigabe
Erstellen Sie eine Sicherungsdateifreigabe, auf die sowohl die SQL Server-VMs als auch deren Dienstkonten Zugriff haben.
Führen Sie die folgenden Schritte aus, um die Sicherungsdateifreigabe zu erstellen:
Wählen Sie auf der ersten SQL Server-VM im Server-Manager die Option Tools aus. Öffnen Sie Computerverwaltung.
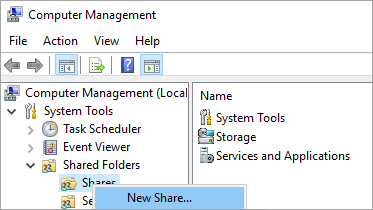
Klicken Sie auf Freigegebene Ordner.
Klicken Sie mit der rechten Maustaste auf Freigaben, wählen Sie Neue Freigabe... aus, und erstellen Sie dann per Assistent zum Erstellen von Ordnerfreigaben eine Freigabe.
Wählen Sie unter Ordnerpfad die Option Durchsuchen aus, und navigieren Sie zu einem Pfad für den freigegebenen Ordner der Datenbanksicherung, oder erstellen Sie einen Pfad (beispielsweise
C:\Backup). Wählen Sie Weiter aus.Überprüfen Sie unter Name, Beschreibung und Einstellungen den Freigabenamen und den Pfad. Wählen Sie Weiter aus.
Legen Sie unter Berechtigungen für freigegebene Ordner die Option Berechtigungen anpassen fest. Wählen Sie Benutzerdefiniert aus.
Klicken Sie unter Berechtigungen anpassen auf Hinzufügen.
Aktivieren Sie das Kontrollkästchen Vollzugriff für beide SQL Server-Dienstkonten (
Corp\SQLSvc), um ihnen Vollzugriff zu gewähren:
Klicken Sie auf OK.
Klicken Sie unter Berechtigungen für freigegebene Ordner auf Fertig stellen. Wählen Sie erneut Fertig stellen aus.
Erstellen der Verfügbarkeitsgruppe
Nachdem die Datenbank gesichert wurde, können Sie Ihre Verfügbarkeitsgruppe erstellen. Dadurch werden automatisch eine vollständige Sicherung und eine Transaktionsprotokollsicherung des primären SQL Server-Replikats erstellt und in der sekundären SQL Server-Instanz mit der Option NORECOVERY wiederherstellt.
Führen Sie die folgenden Schritte aus, um die Verfügbarkeitsgruppe zu erstellen:
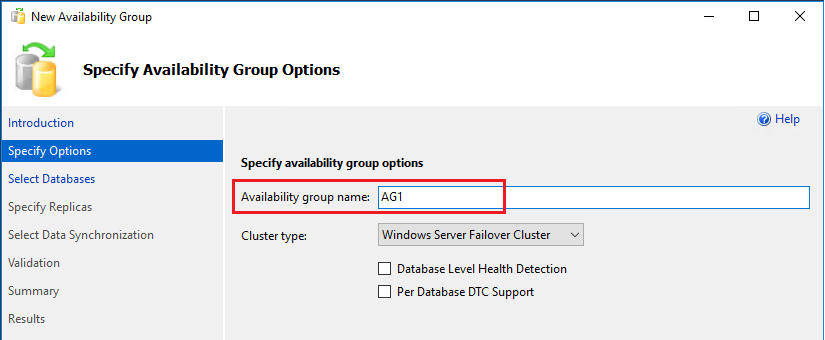
Klicken Sie im Objekt-Explorer in SQL Server Management Studio (SSMS) auf der ersten SQL Server-VM (beispielsweise SQL-VM-1) mit der rechten Maustaste auf Hohe Verfügbarkeit mit AlwaysOn, und wählen Sie Assistent für neue Verfügbarkeitsgruppen aus.

Wählen Sie auf der Seite Einführung die Option Weiter. Geben Sie auf der Seite Namen der Verfügbarkeitsgruppe angeben unter Name der Verfügbarkeitsgruppe einen Namen für die Verfügbarkeitsgruppe ein (beispielsweise AG1). Wählen Sie Weiter aus.
Wählen Sie auf der Seite Datenbanken auswählen Ihre Datenbank und anschließend Weiter aus. Sollte Ihre Datenbank die Voraussetzungen nicht erfüllen, vergewissern Sie sich, dass sie sich im vollständigen Wiederherstellungsmodus befindet, und erstellen Sie eine Sicherung:
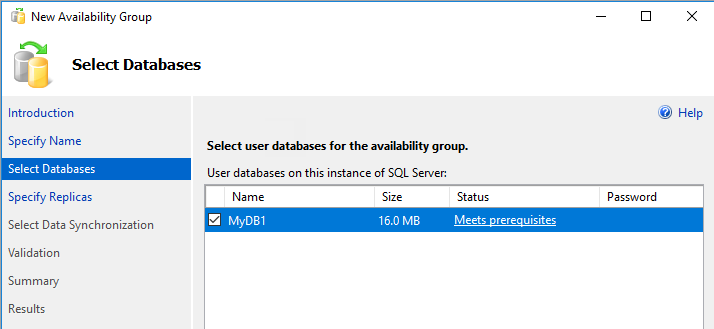
Wählen Sie auf der Seite Replikate angeben die Option Replikat hinzufügen aus.
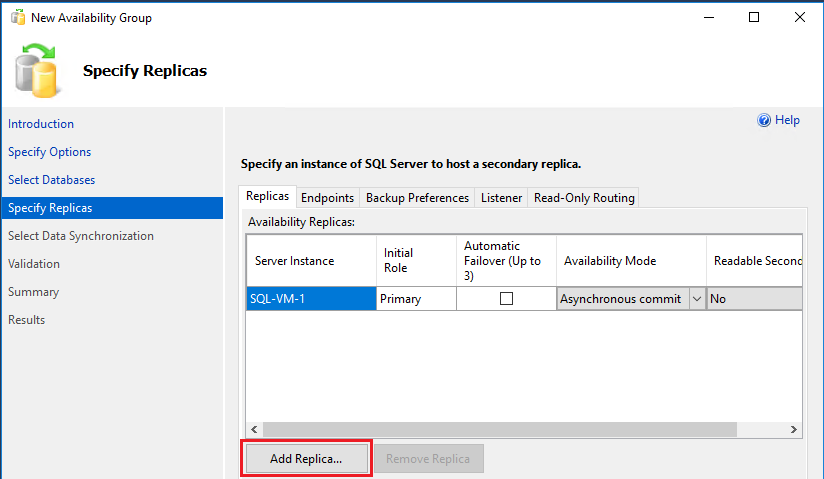
Das Dialogfeld Verbindung mit Server herstellen wird angezeigt. Geben Sie unter Servername den Namen des zweiten Servers ein (beispielsweise SQL-VM-2). Wählen Sie Verbinden.
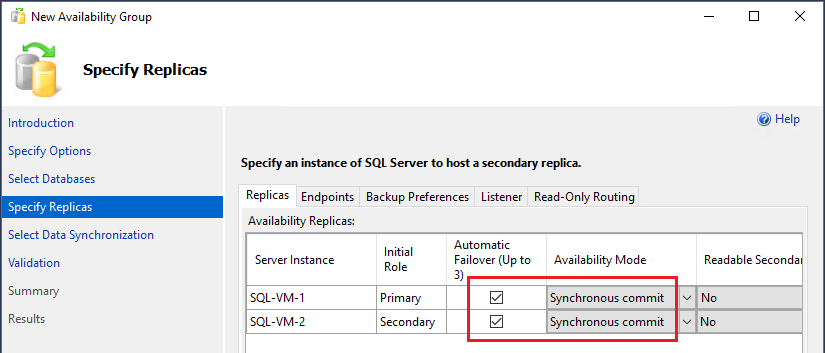
Aktivieren Sie auf der Seite Replikate angeben die Kontrollkästchen für Automatisches Failover, und wählen Sie in der Dropdownliste für den Verfügbarkeitsmodus die Option Synchroner Commit aus:
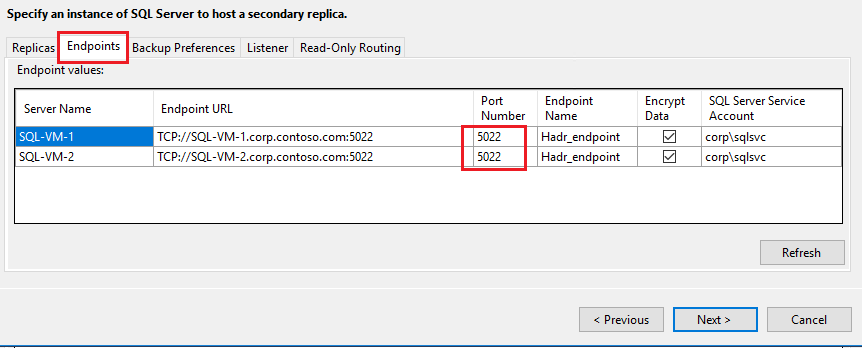
Vergewissern Sie sich auf der Registerkarte Endpunkte, dass es sich bei den Ports, die für den Endpunkt für die Datenbankspiegelung verwendet werden, um die Ports handelt, die Sie in der Firewall geöffnet haben:
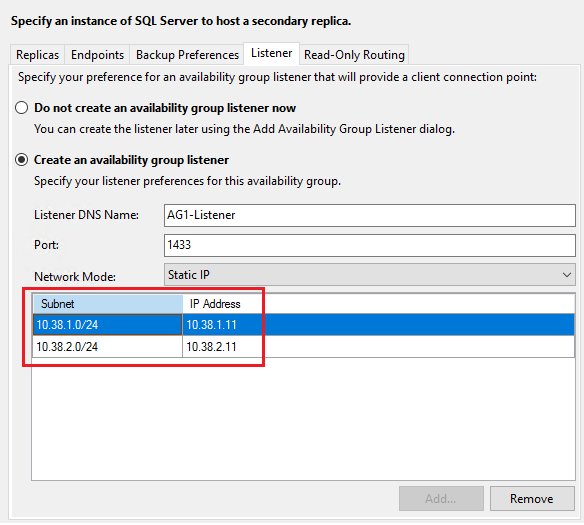
Wählen Sie auf der Registerkarte Listener die Option Verfügbarkeitsgruppenlistener erstellen aus, und verwenden Sie die folgenden Werte für den Listener:
Feld Wert DNS-Name des Listeners: AG1-Listener Port Verwenden Sie den SQL Server-Standardport. 1433 Netzwerkmodus: Statische IP Wählen Sie Hinzufügen aus, um die sekundäre dedizierte IP-Adresse für den Listener für beide SQL Server-VMs anzugeben.
Die folgende Tabelle enthält die für den Listener erstellten Beispiel-IP-Adressen aus dem Dokument mit den Voraussetzungen. Ihre spezifischen IP-Adressen können sich jedoch von diesen Angaben unterscheiden:
VM-Name Subnetzname Subnetzadressbereich Name der sekundären IP-Adresse Sekundäre IP-Adresse SQL-VM-1 SQL-subnet-1 10.38.1.0/24 availability-group-listener 10.38.1.11 SQL-VM-2 SQL-subnet-2 10.38.2.0/24 availability-group-listener 10.38.2.11 Wählen Sie in der Dropdownliste des Dialogfelds IP-Adresse hinzufügen das erste Subnetz (beispielsweise 10.38.1.0/24) aus, und geben Sie dann die IPv4-Adresse des sekundären dedizierten Listeners an (beispielsweise
10.38.1.11). Klicken Sie auf OK.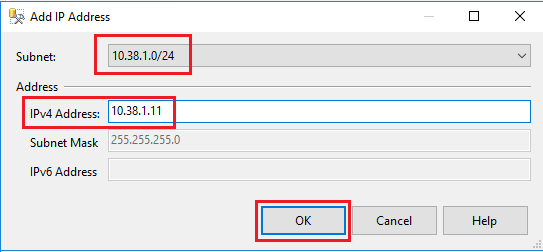
Wiederholen Sie diesen Schritt, wählen Sie diesmal jedoch in der Dropdownliste das andere Subnetz (beispielsweise 10.38.2.0/24) aus, und geben Sie die IPv4-Adresse des sekundären dedizierten Listeners der anderen SQL Server-VM an (beispielsweise
10.38.2.11). Klicken Sie auf OK.
Überprüfen Sie die Werte auf der Seite Listener, und wählen Sie Weiter aus:
Wählen Sie auf der Seite Anfängliche Datensynchronisierung auswählen die Option Vollständige Datenbank- und Protokollsicherung aus, und geben Sie den zuvor erstellten Speicherort der Netzwerkfreigabe an (beispielsweise
\\SQL-VM-1\Backup).
Hinweis
Zur vollständigen Synchronisierung wird die Datenbank der ersten SQL Server-Instanz vollständig gesichert und in der zweiten Instanz wiederhergestellt. Bei umfangreichen Datenbanken wird von einer vollständigen Synchronisierung abgeraten, da sie sehr lange dauern kann. Sie können den Vorgang beschleunigen, indem Sie die Datenbank manuell sichern und mit
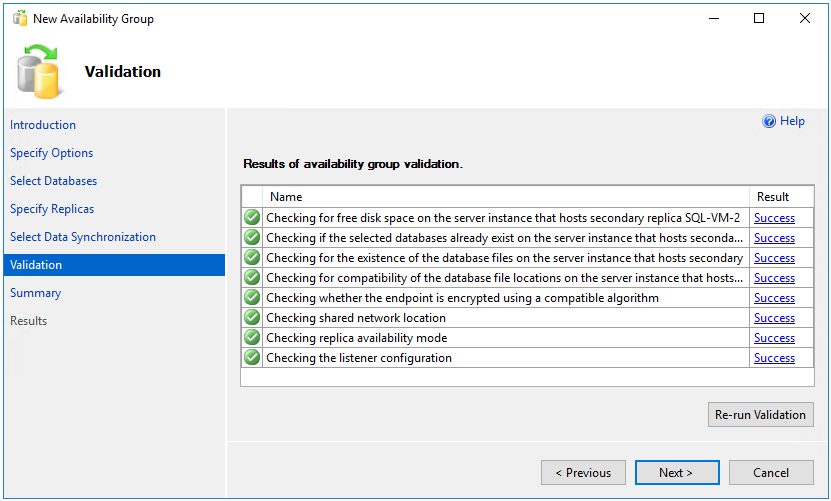
NO RECOVERYwiederherstellen. Falls die Datenbank bereits vor dem Konfigurieren der Verfügbarkeitsgruppe mitNO RECOVERYin der zweiten SQL Server-Instanz wiederhergestellt wurde, wählen Sie Nur verknüpfen aus. Wenn Sie die Sicherung nach dem Konfigurieren der Verfügbarkeitsgruppe erstellen möchten, wählen Sie Anfängliche Datensynchronisierung überspringen aus.Vergewissern Sie sich auf der Seite Überprüfung, dass alle Validierungsüberprüfungen erfolgreich waren, und wählen Sie anschließend Weiter aus:
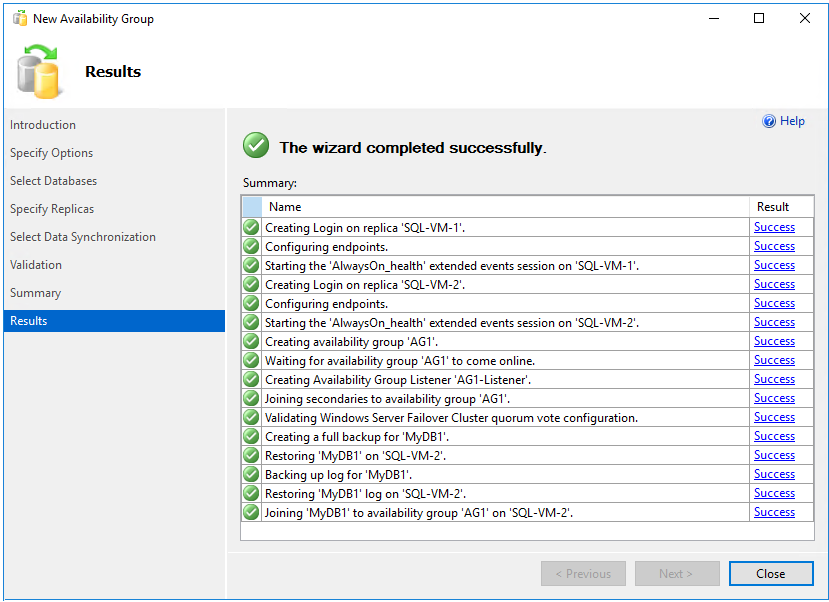
Wählen Sie auf der Seite Zusammenfassung die Option Fertig stellen aus, und warten Sie, bis der Assistent Ihre neue Verfügbarkeitsgruppe konfiguriert hat. Wählen Sie auf der Seite Status die Option Weitere Details aus, um den detaillierten Status anzuzeigen. Wenn auf der Seite Ergebnisse die Meldung Der Assistent wurde erfolgreich abgeschlossen. angezeigt wird, vergewissern Sie sich anhand der Zusammenfassung, dass die Verfügbarkeitsgruppe und der Listener erfolgreich erstellt wurden.
Klicken Sie auf Schließen, um den Assistenten zu beenden.
Überprüfen der Verfügbarkeitsgruppe
Die Integrität der Verfügbarkeitsgruppe kann mithilfe von SQL Server Management Studio sowie mit dem Failovercluster-Manager überprüft werden.
Führen Sie die folgenden Schritte aus, um den Status der Verfügbarkeitsgruppe zu überprüfen:
Erweitern Sie im Objekt-Explorer den Eintrag Hochverfügbarkeit mit Always On, und erweitern Sie dann Verfügbarkeitsgruppen. Sie sollten jetzt die neue Verfügbarkeitsgruppe in diesem Container sehen können. Klicken Sie mit der rechten Maustaste auf die Verfügbarkeitsgruppe, und wählen Sie Dashboard anzeigenaus.

Auf dem Dashboard „Verfügbarkeitsgruppe“ werden das Replikat, der Failovermodus der einzelnen Replikate und der Synchronisierungsstatus angezeigt, wie im folgenden Beispiel zu sehen:
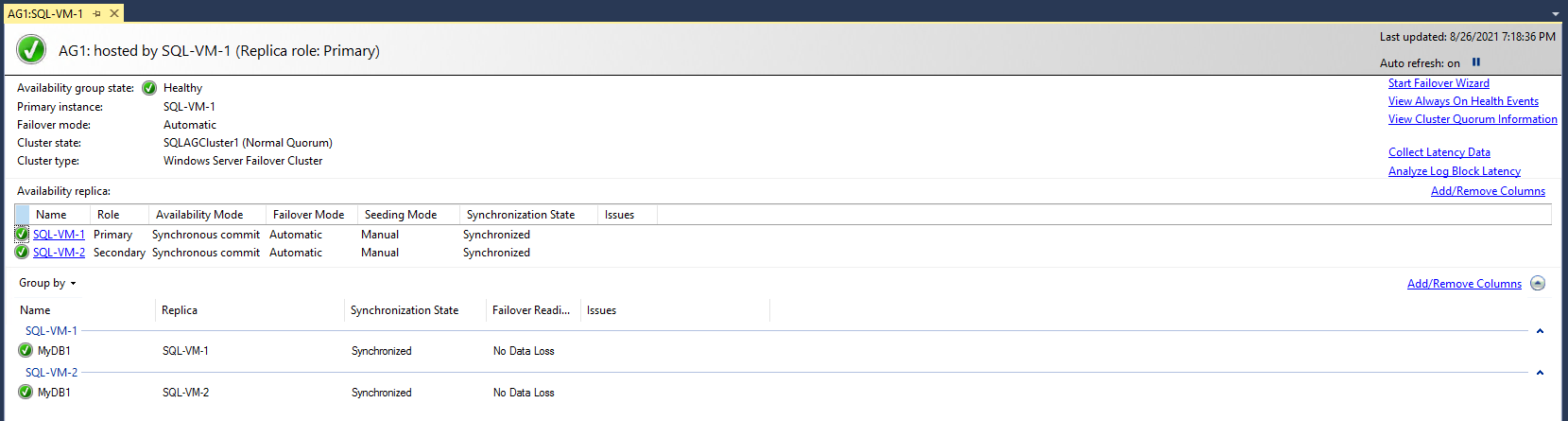
Öffnen Sie den Failovercluster-Manager, wählen Sie Ihren Cluster aus, und wählen Sie Rollen aus, um die Verfügbarkeitsgruppenrolle anzuzeigen, die Sie im Cluster erstellt haben. Wählen Sie die Rolle AG1 und anschließend die Registerkarte Ressourcen aus, um den Listener und die zugeordneten IP-Adressen anzuzeigen, wie im folgenden Beispiel zu sehen:
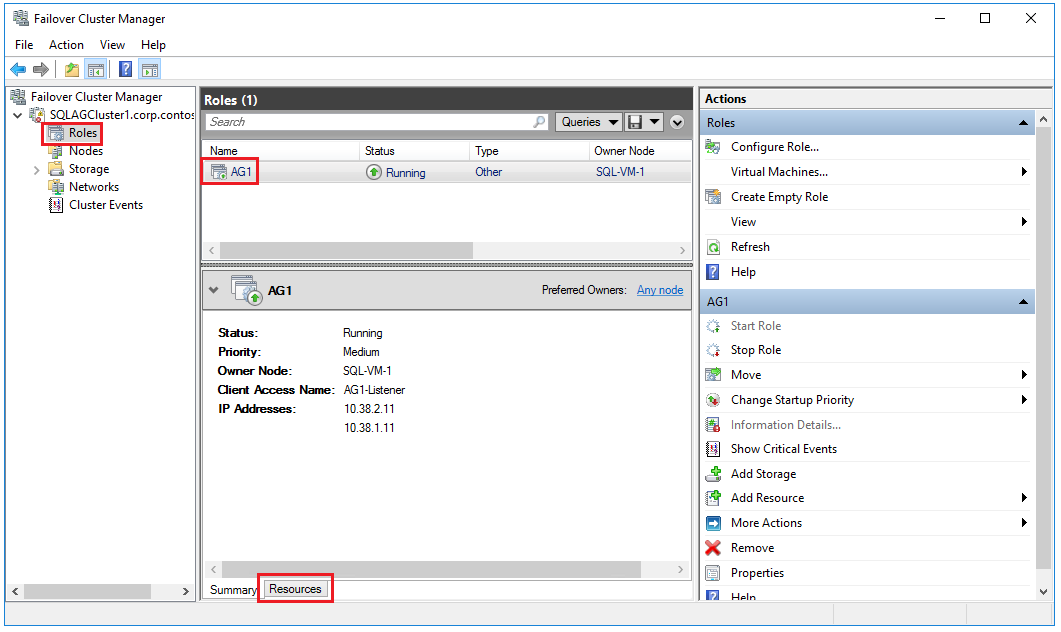
Sie verfügen nun über eine Verfügbarkeitsgruppe mit Replikaten in zwei Instanzen von SQL Server sowie über einen entsprechenden Verfügbarkeitsgruppenlistener. Sie können mithilfe des Listeners eine Verbindung herstellen und die Verfügbarkeitsgruppe mithilfe von SQL Server Management Studio zwischen Instanzen verschieben.
Warnung
Versuchen Sie nicht, über den Failovercluster-Manager ein Failover für die Verfügbarkeitsgruppe durchzuführen. Alle Failovervorgänge sollten über SQL Server Management Studio durchgeführt werden – etwa über das Always On-Dashboard oder mithilfe von Transact-SQL (T-SQL). Weitere Informationen finden Sie unter Failoverclustering und AlwaysOn-Verfügbarkeitsgruppen (SQL Server).
Testen der Listenerverbindung
Wenn Ihre Verfügbarkeitsgruppe bereit ist und Ihr Listener mit den entsprechenden sekundären IP-Adressen konfiguriert wurde, können Sie die Verbindung mit dem Listener testen.
Führen Sie folgende Schritte aus, um die Verbindung zu testen:
Stellen Sie eine RDP-Verbindung mit einer SQL Server-Instanz her, die sich im gleichen virtuellen Netzwerk befindet, aber kein Besitzer des Replikats ist – also beispielsweise mit der anderen SQL Server-Instanz im Cluster oder mit einem beliebigen anderen virtuellen Computer, auf dem SQL Server Management Studio installiert ist.
Öffnen Sie SQL Server Management Studio, geben Sie im Dialogfeld Mit Server verbinden unter Servername: den Namen des Listeners ein (beispielsweise AG1-Listener) , und wählen Sie anschließend Optionen aus:
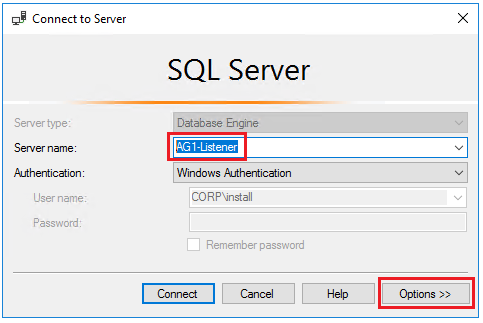
Geben Sie im Fenster
MultiSubnetFailover=TrueZusätzliche Verbindungsparameterdie Zeichenfolge ein, und wählen Sie dann Verbinden aus, um automatisch eine Verbindung mit der Instanz herzustellen, von der das primäre SQL Server-Replikat gehostet wird: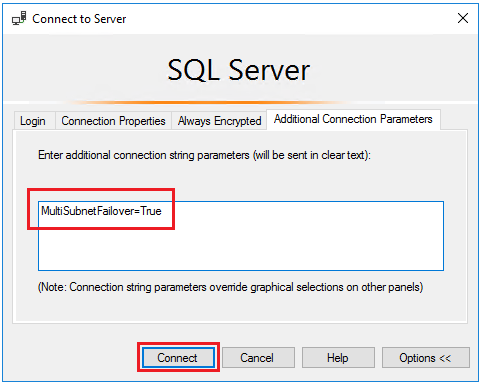
Hinweis
- Bei der Verbindungsherstellung mit einer Verfügbarkeitsgruppe in verschiedenen Subnetzen ermöglicht die Einstellung
MultiSubnetFailover=trueeine schnellere Erkennung des aktuellen primären Replikats sowie eine schnellere Verbindungsherstellung. Weitere Informationen finden Sie unter Verbinden mit MultiSubnetFailover.
Nächste Schritte
Nachdem Sie Ihre Verfügbarkeitsgruppe mit mehreren Subnetzen konfiguriert haben, können Sie diese bei Bedarf auf mehrere Regionen erweitern.
Weitere Informationen finden Sie unter:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für