Datenmodellierung in Azure Cosmos DB
GILT FÜR: ![]() NoSQL
NoSQL
Obwohl schemafreie Datenbanken wie Azure Cosmos DB das Speichern und Abfragen unstrukturierter und teilstrukturierter Daten sehr erleichtern, sollten Sie etwas Zeit in die Überlegung investieren, wie Ihr Datenmodell den Dienst im Hinblick auf Leistung, Skalierbarkeit und niedrigste Kosten optimal nutzen kann.
Wie werden die Daten gespeichert? Wie wird Ihre Anwendung Daten abrufen und abfragen? Ist Ihre Anwendung eher leseintensiv oder schreibintensiv?
Nach Lesen dieses Artikels können Sie die folgenden Fragen beantworten:
- Was ist Datenmodellierung und warum sollte ich mich dafür interessieren?
- Inwiefern unterscheidet sich die Datenmodellierung in Azure Cosmos DB von einer relationalen Datenbank?
- Wie kann ich Datenbeziehungen in einer nicht-relationalen Datenbank ausdrücken?
- Wann bette ich Daten ein, und wann verknüpfe ich sie?
Zahlen in JSON
Azure Cosmos DB speichert Dokumente im JSON-Format. Daher muss sorgfältig überprüft werden, ob Zahlen in Zeichenfolgen konvertiert werden müssen, bevor sie im JSON-Format gespeichert werden. Alle Zahlen sollten idealerweise in eine String konvertiert werden, wenn es wahrscheinlich ist, dass sie außerhalb der Grenzen von Zahlen mit doppelter Genauigkeit gemäß IEEE 754 binary64 liegen. In der JSON-Spezifikation sind Gründe dafür genannt, warum die Verwendung von Zahlen außerhalb dieser Grenze im Allgemeinen aufgrund wahrscheinlicher Interoperabilitätsprobleme in JSON nicht empfohlen wird. Diese Bedenken sind besonders für die Partitionsschlüsselspalte relevant, da sie unveränderlich ist und eine Datenmigration erfordert, damit sie später geändert werden kann.
Einbetten von Daten
Versuchen Sie beim ersten Modellieren von Daten in Azure Cosmos DB Ihre Entitäten als eigenständige Elemente, dargestellt als JSON-Dokumente, zu behandeln.
Zum Vergleich betrachten wir zunächst die Datenmodellierung in einer relationalen Datenbank. Das folgende Beispiel zeigt, wie eine Person in einer relationalen Datenbank gespeichert werden kann.
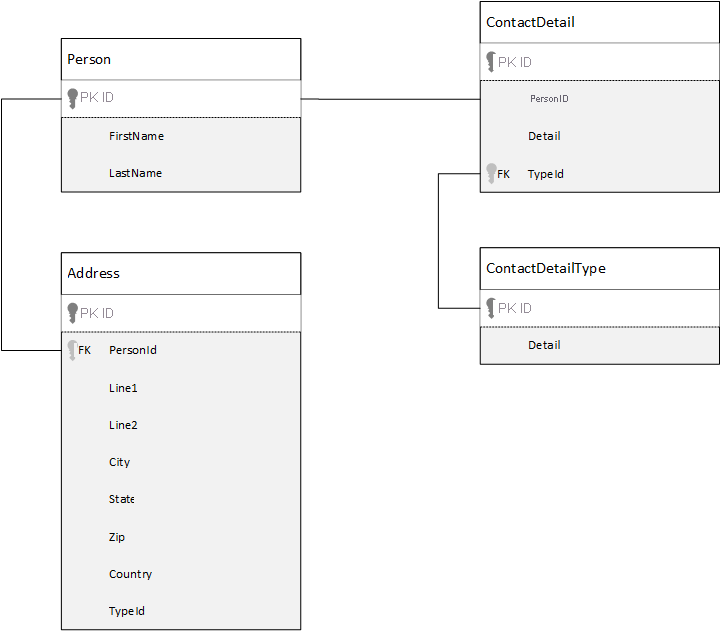
Bei der Arbeit mit relationalen Datenbanken besteht die Strategie im Normalisieren Ihrer gesamten Daten. Beim Normalisieren von Daten wird in der Regel eine Entität, z.B. eine Person, in einzelne Komponenten aufgeschlüsselt. Im obigen Beispiel kann eine Person über mehrere Kontaktdetaildatensätze sowie mehrere Adressdatensätze verfügen. Kontaktdetails können durch weiteres Extrahieren allgemeiner Felder, wie z.B. eines Typs, weiter aufgeschlüsselt werden. Das gleiche gilt für die Adresse, jeder Datensatz kann vom Typ Home oder Business sein.
Die beim Normalisieren von Daten geltende Prämisse besteht darin, dass das Speichern von redundanten Daten in jedem Datensatz zu vermeiden ist und dass stattdessen auf die einzelnen Daten verwiesen werden soll. Um in diesem Beispiel die Informationen zu einer Person mit allen ihren Kontaktdaten und Adressen zu lesen, müssen Sie JOINS verwenden, um Ihre Daten zur Runtime wieder effektiv zusammenzusetzen (oder denormalisieren).
SELECT p.FirstName, p.LastName, a.City, cd.Detail
FROM Person p
JOIN ContactDetail cd ON cd.PersonId = p.Id
JOIN ContactDetailType cdt ON cdt.Id = cd.TypeId
JOIN Address a ON a.PersonId = p.Id
Für das Aktualisieren einer einzelnen Person mit allen ihren Kontaktdaten und Adressen sind Schreibvorgänge über viele einzelne Tabellen hinweg erforderlich.
Sehen Sie sich jetzt an, wie Sie die gleichen Daten als eigenständige Entität in Azure Cosmos DB modellieren können.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"addresses": [
{
"line1": "100 Some Street",
"line2": "Unit 1",
"city": "Seattle",
"state": "WA",
"zip": 98012
}
],
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555", "extension": 5555}
]
}
Mit dem oben stehenden Ansatz haben wir den Personendatensatz denormalisiert, indem wir alle Informationen im Zusammenhang mit dieser Person, beispielsweise ihre Kontaktdaten und Adressen, in ein einzelnes JSON-Dokumenteingebettet haben. Da wir nicht auf ein festes Schema beschränkt sind, haben wir darüber hinaus die Flexibilität, z. B. Kontaktdetails in vollständig verschiedenen Formen zu haben.
Das Abrufen eines vollständigen Personendatensatzes aus der Datenbank besteht jetzt aus einem einzelnen Lesevorgang eines einzelnen Containers und für ein einzelnes Element. Das Aktualisieren eines Personendatensatzes zusammen mit den Kontaktinformationen und Adressen ist auch ein einzelner Schreibvorgang für ein einzelnes Element.
Durch das Denormalisieren von Daten muss Ihre Anwendung u. U. weniger Abfragen und Aktualisierungen ausgeben, um allgemeine Vorgänge abzuschließen.
Wann Sie einbetten sollten
Verwenden Sie in der Regel eingebettete Datenmodelle in den folgenden Fällen:
- Zwischen Entitäten gibt es contained-Beziehungen.
- Zwischen Entitäten gibt es eins-zu-viele -Beziehungen.
- Es gibt eingebettete Daten, die sich selten ändern.
- Es gibt eingebettete Daten, die nicht unbegrenzt wachsen.
- Es gibt eingebettete Daten, die häufig gemeinsam abgefragt werden.
Hinweis
In der Regel bieten denormalisierte Datenmodelle eine bessere Leseleistung .
Wann Sie nicht einbetten sollten
In Azure Cosmos DB gilt zwar die Faustregel, dass alles denormalisiert wird und alle Daten in ein einzelnes Element eingebettet werden sollen. Dies kann jedoch zu Situationen führen, die es zu vermeiden gilt.
Nehmen Sie beispielsweise diesen JSON-Ausschnitt.
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"comments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
…
{"id": 100001, "author": "jane", "comment": "and on we go ..."},
…
{"id": 1000000001, "author": "angry", "comment": "blah angry blah angry"},
…
{"id": ∞ + 1, "author": "bored", "comment": "oh man, will this ever end?"},
]
}
So könnte eine Beitragsentität mit eingebetteten Kommentaren aussehen, wenn wir ein typisches Blog- oder CMS-System modellieren würden. Das Problem bei diesem Beispiel besteht darin, dass das Kommentar-Array unbegrenzt ist. Dies bedeutet, dass es (praktisch) keine Begrenzung hinsichtlich der Anzahl an Kommentaren zu einem einzelnen Beitrag gibt. Dies kann problematisch werden, da die Größe des Elements unendlich zunehmen könnte, daher sollten Sie dieses Design vermeiden.
Mit zunehmender Größe des Elements wird die Möglichkeit zum Übertragen von Daten über das Netz sowie zum Lesen und Aktualisieren des Elements bei Skalierung beeinträchtigt.
In einem solchen Fall sollte lieber das folgende Datenmodell in Betracht gezogen werden.
Post item:
{
"id": "1",
"name": "What's new in the coolest Cloud",
"summary": "A blog post by someone real famous",
"recentComments": [
{"id": 1, "author": "anon", "comment": "something useful, I'm sure"},
{"id": 2, "author": "bob", "comment": "wisdom from the interwebs"},
{"id": 3, "author": "jane", "comment": "....."}
]
}
Comment items:
[
{"id": 4, "postId": "1", "author": "anon", "comment": "more goodness"},
{"id": 5, "postId": "1", "author": "bob", "comment": "tails from the field"},
...
{"id": 99, "postId": "1", "author": "angry", "comment": "blah angry blah angry"},
{"id": 100, "postId": "2", "author": "anon", "comment": "yet more"},
...
{"id": 199, "postId": "2", "author": "bored", "comment": "will this ever end?"}
]
Dieses Modell hat ein Dokument für jeden Kommentar mit einer Eigenschaft, die den Posting-Bezeichner enthält. So können Posting eine beliebige Anzahl von Kommentaren enthalten und effizient wachsen. Benutzer, die mehr als die neuesten Kommentare anzeigen möchten, fragen diesen Container ab und übergeben die postId, die der Partitionsschlüssel für den Kommentarcontainer sein sollte.
Das Einbetten von Daten ist ebenfalls keine gute Idee, wenn die eingebetteten Daten häufig in Elementen verwendet und oft geändert werden.
Nehmen Sie beispielsweise diesen JSON-Ausschnitt.
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{
"numberHeld": 100,
"stock": { "symbol": "zbzb", "open": 1, "high": 2, "low": 0.5 }
},
{
"numberHeld": 50,
"stock": { "symbol": "xcxc", "open": 89, "high": 93.24, "low": 88.87 }
}
]
}
Dabei kann es sich um das Aktienportfolio einer Person handeln. Wir haben uns dazu entschlossen, die Aktiendaten in jedes Portfoliodokument einzubetten. In einer Umgebung, in der verknüpfte Daten häufig geändert werden, wie z. B. eine Aktienhandelsanwendung, bedeutet das Einbetten von sich häufig ändernden Daten, dass Sie bei jeder Aktienhandelstransaktion jedes Portfoliodokument aktualisieren müssen.
Die Aktie zbzb kann jeden Tag mehrere Hundert Mal gehandelt werden, und Tausende Benutzer besitzen zbzb in ihrem Portfolio. Bei einem Datenmodell wie dem obigen müssten wir zigtausend Portfoliodokumente mehrmals täglich aktualisieren, was zu einem schlecht skalierbaren System führt.
Verweisdaten
Das Einbetten von Daten funktioniert in vielen Fällen gut, aber es gibt Szenarien, bei denen das Denormalisieren von Daten mehr Probleme verursacht als es Nutzen bringt. Was also können wir jetzt tun?
Relationale Datenbanken sind nicht der einzige Ort, an dem Sie Beziehungen zwischen Entitäten herstellen können. In einer Dokumentdatenbank können Informationen in einem Dokument vorhanden sein, die sich auf Daten in anderen Dokumenten beziehen. Es wird nicht empfohlen, Systeme zu erstellen, die besser für eine relationale Datenbank in Azure Cosmos DB oder eine andere Dokumentdatenbank geeignet wären, aber einfache Beziehungen sind in Ordnung und können nützlich sein.
Im JSON-Abschnitt unten verwenden wir das vorherige Beispiel eines Aktienportfolios, aber dieses Mal verweisen wir auf den Aktieneintrag im Portfolio, anstatt ihn einzubetten. Auf diese Weise müssen wir nur dieses eine Aktiendokument aktualisieren, wenn sich der Aktieneintrag mehrmals am Tag ändert.
Person document:
{
"id": "1",
"firstName": "Thomas",
"lastName": "Andersen",
"holdings": [
{ "numberHeld": 100, "stockId": 1},
{ "numberHeld": 50, "stockId": 2}
]
}
Stock documents:
{
"id": "1",
"symbol": "zbzb",
"open": 1,
"high": 2,
"low": 0.5,
"vol": 11970000,
"mkt-cap": 42000000,
"pe": 5.89
},
{
"id": "2",
"symbol": "xcxc",
"open": 89,
"high": 93.24,
"low": 88.87,
"vol": 2970200,
"mkt-cap": 1005000,
"pe": 75.82
}
Ein unmittelbarer Nachteil dieses Ansatzes besteht jedoch darin, dass, wenn Ihre Anwendung Informationen zu jeder Aktie anzeigen muss, die bei der Anzeige des Portfolios einer Person enthalten sein müssen, Sie mehrere Roundtrips zur Datenbank durchführen müssen, um die Informationen für jedes Aktiendokument zu laden. Hier haben wir beschlossen, die Effizienz der Schreibvorgänge zu verbessern, die mehrmals täglich durchgeführt werden, wir nehmen wiederum die Beeinträchtigung der Lesevorgänge hin, die sich potenziell weniger stark auf die Leistung dieses speziellen Systems auswirken.
Hinweis
Normalisierte Datenmodelle können mehrere Roundtrips zum Server erfordern .
Was ist mit Fremdschlüsseln?
Da es derzeit kein Konzept für eine Einschränkung, einen Fremdschlüssel oder etwas Vergleichbares gibt, sind alle Beziehungen zwischen Dokumenten im Grunde „schwache Verbindungen“ und werden von der Datenbank selbst nicht überprüft. Wenn Sie sicherstellen möchten, dass die Daten, auf die ein Dokument verweist, tatsächlich vorhanden sind, müssen Sie dies in der Anwendung durchführen oder serverseitige Trigger oder gespeicherte Prozeduren für Azure Cosmos DB verwenden.
Wann Sie verweisen sollten
Verwenden Sie in der Regel normalisierte Datenmodelle in den folgenden Fällen:
- Zur Darstellung von 1:n -Beziehungen.
- Zur Darstellung von m:n -Beziehungen.
- Wenn sich zugehörige Daten häufig ändern.
- Wenn referenzierte Daten möglicherweise unbegrenztsind.
Hinweis
Wenn eine Normalisierung in der Regel eine bessere Schreibleistung bietet.
Wo erstelle ich die Beziehung?
Das Wachstum der Beziehung hilft bei der Bestimmung, in welchem Dokument der Verweis gespeichert werden sollte.
Sehen Sie sich den unten stehenden JSON-Code an, in dem Verleger und Bücher modelliert werden.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press",
"books": [ 1, 2, 3, ..., 100, ..., 1000]
}
Book documents:
{"id": "1", "name": "Azure Cosmos DB 101" }
{"id": "2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "3", "name": "Taking over the world one JSON doc at a time" }
...
{"id": "100", "name": "Learn about Azure Cosmos DB" }
...
{"id": "1000", "name": "Deep Dive into Azure Cosmos DB" }
Wenn die Anzahl der Bücher für jeden Verleger klein ist und nur über begrenztes Wachstum verfügt, kann es nützlich sein, den Buchverweis im Verlegerdokument zu speichern. Wenn die Anzahl der Bücher pro Verleger jedoch unbegrenzt ist, würde dieses Datenmodell zu veränderbaren, wachsenden Arrays führen, wie im obigen Verlegerbeispieldokument gezeigt.
Durch ein paar Änderungen entsteht ein Modell, das weiterhin die gleichen Daten darstellt, aber diese großen veränderbaren Sammlungen werden vermieden.
Publisher document:
{
"id": "mspress",
"name": "Microsoft Press"
}
Book documents:
{"id": "1","name": "Azure Cosmos DB 101", "pub-id": "mspress"}
{"id": "2","name": "Azure Cosmos DB for RDBMS Users", "pub-id": "mspress"}
{"id": "3","name": "Taking over the world one JSON doc at a time", "pub-id": "mspress"}
...
{"id": "100","name": "Learn about Azure Cosmos DB", "pub-id": "mspress"}
...
{"id": "1000","name": "Deep Dive into Azure Cosmos DB", "pub-id": "mspress"}
Im Beispiel oben haben wir die unbegrenzte Auflistung im Verlegerdokument gelöscht. Stattdessen haben wir nur einen Verweis auf den Verleger in jedem Buchdokument hinzugefügt.
Wie modelliere ich n:n-Beziehungen?
In einer relationalen Datenbank werden n:n -Beziehungen häufig mit Verknüpfungstabellen modelliert, bei denen einfach Datensätze aus anderen Tabellen miteinander verknüpft werden.
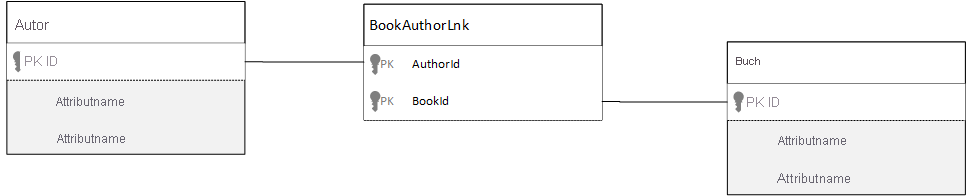
Möglicherweise sind Sie versucht, dasselbe mit Dokumenten zu replizieren, wobei jedoch ein Datenmodell entsteht, das etwa folgendermaßen aussieht.
Author documents:
{"id": "a1", "name": "Thomas Andersen" }
{"id": "a2", "name": "William Wakefield" }
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101" }
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users" }
{"id": "b3", "name": "Taking over the world one JSON doc at a time" }
{"id": "b4", "name": "Learn about Azure Cosmos DB" }
{"id": "b5", "name": "Deep Dive into Azure Cosmos DB" }
Joining documents:
{"authorId": "a1", "bookId": "b1" }
{"authorId": "a2", "bookId": "b1" }
{"authorId": "a1", "bookId": "b2" }
{"authorId": "a1", "bookId": "b3" }
Das würde auch funktionieren. Wenn Sie jedoch einen Autor mit seinen Büchern oder ein Buch mit seinem Autor laden, sind immer mindestens zwei zusätzliche Abfragen für die Datenbank erforderlich. Eine Abfrage, um das Dokument zu verknüpfen, und dann eine weitere Abfrage zum Abrufen des tatsächlichen zu verknüpfenden Dokuments.
Wenn diese Verknüpfung lediglich dazu dient, zwei Informationen miteinander zu verbinden, warum lässt man sie dann nicht ganz weg? Betrachten Sie das folgende Beispiel.
Author documents:
{"id": "a1", "name": "Thomas Andersen", "books": ["b1", "b2", "b3"]}
{"id": "a2", "name": "William Wakefield", "books": ["b1", "b4"]}
Book documents:
{"id": "b1", "name": "Azure Cosmos DB 101", "authors": ["a1", "a2"]}
{"id": "b2", "name": "Azure Cosmos DB for RDBMS Users", "authors": ["a1"]}
{"id": "b3", "name": "Learn about Azure Cosmos DB", "authors": ["a1"]}
{"id": "b4", "name": "Deep Dive into Azure Cosmos DB", "authors": ["a2"]}
Wenn ich nun einen Autor habe, weiß ich sofort, welche Bücher er geschrieben hat. Und im umgekehrten Fall, wenn ich ein Buchdokument geladen habe, kenne ich die IDs der Autoren. Dadurch ersparen Sie sich Zwischenabfragen der Verknüpfungstabelle, wodurch wiederum die Anzahl der Serverroundtrips Ihrer Anwendung reduziert wird.
Hybriddatenmodelle
Wir haben gesehen, wie Daten eingebettet (bzw. denormalisiert) werden und wie auf Daten verwiesen wird (bzw. wie sie normalisiert werden). Beide Ansätze haben Vor- und Nachteile.
Doch es muss nicht immer ein Entweder-oder geben. Trauen Sie sich, die Systeme etwas zu vermischen.
Basierend auf bestimmten Verwendungsmustern und Arbeitsauslastungen gibt es möglicherweise Fälle, in denen eine Mischung aus eingebetteten und referenzierten Daten sinnvoll sein kann und zu einer einfacheren Anwendungslogik mit weniger Serverroundtrips führen kann, wobei gleichzeitig eine gute Leistung gewahrt wird.
Betrachten Sie das folgende JSON-Beispiel.
Author documents:
{
"id": "a1",
"firstName": "Thomas",
"lastName": "Andersen",
"countOfBooks": 3,
"books": ["b1", "b2", "b3"],
"images": [
{"thumbnail": "https://....png"}
{"profile": "https://....png"}
{"large": "https://....png"}
]
},
{
"id": "a2",
"firstName": "William",
"lastName": "Wakefield",
"countOfBooks": 1,
"books": ["b1"],
"images": [
{"thumbnail": "https://....png"}
]
}
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
{"id": "a2", "name": "William Wakefield", "thumbnailUrl": "https://....png"}
]
},
{
"id": "b2",
"name": "Azure Cosmos DB for RDBMS Users",
"authors": [
{"id": "a1", "name": "Thomas Andersen", "thumbnailUrl": "https://....png"},
]
}
Hier haben wir (hauptsächlich) das eingebettete Modell verwendet, bei dem Daten aus anderen Entitäten im übergeordneten Dokument eingebettet sind, in dem jedoch auf andere Daten verwiesen wird.
Wenn Sie das Buchdokument betrachten, sehen Sie ein paar interessante Felder, wenn wir das Array der Autoren betrachten. Es gibt ein id-Feld, bei dem es sich um das Feld handelt, das für einen Rückverweis auf ein Autorendokument verwendet wird (Standardmethode in einem normalisierten Modell). Es gibt aber auch die Felder name und thumbnailUrl. Wir hätten auch nur bei dem Feld id bleiben können, sodass die Anwendung alle zusätzlichen erforderlichen Informationen mithilfe des „Links“ aus dem jeweiligen Autorendokument abruft. Da unsere Anwendung jedoch zusammen mit jedem angezeigten Buch den Namen des Autors und ein Miniaturbild anzeigt, können wir pro Buch einen Roundtrip zum Server in einer Liste speichern, indem wir einige Daten vom Autor denormalisieren.
Sicherlich müssten wir, wenn sich der Name des Autors ändert oder das Foto aktualisiert werden soll, jedes jemals von ihm veröffentlichte Buch aktualisieren. Bei unserer Anwendung ist dies jedoch eine akzeptable Entwurfsentscheidung, da wir von der Annahme ausgehen, dass Autoren ihre Namen nicht sehr häufig ändern.
Im Beispiel gibt es vorab berechnete Aggregatwerte, um die aufwändige Verarbeitung eines Lesevorgangs zu vermeiden. Im Beispiel werden einige der im Autorendokument eingebetteten Daten zur Laufzeit berechnet. Jedes Mal, wenn ein neues Buch veröffentlicht wird, wird ein Buchdokument erstellt, und das Feld „CountOfBooks“ wird auf einen berechneten Wert festgelegt, basierend auf der Anzahl der Buchdokumente, die für einen bestimmten Autor vorhanden sind. Diese Optimierung wäre in schreibintensiven Systemen gut, in denen wir uns Berechnungen für Schreibvorgänge leisten können, um Lesevorgänge zu optimieren.
Die Möglichkeit über ein Modell mit vorab berechneten Felder zu verfügen, wird dank der Unterstützung von Transaktionen mit mehreren Dokumenten durch Azure Cosmos DB ermöglicht. Viele NoSQL-Speicher können keine dokumentübergreifenden Transaktionen durchführen und bevorzugen aufgrund dieser Einschränkung Entwurfsentscheidungen, wie diejenige, immer alles einzubetten. Mit Azure Cosmos DB können Sie serverseitige Trigger oder gespeicherte Prozeduren verwenden, mit denen Bücher eingefügt und Autoren in einer einzigen ACID-Transaktion aktualisiert werden. Sie müssen nicht alles in ein Dokument einbetten, nur um sicherzustellen, dass Ihre Daten konsistent bleiben.
Unterscheiden zwischen verschiedenen Dokumenttypen
In einigen Szenarien möchten Sie möglicherweise verschiedene Dokumenttypen in derselben Sammlung zusammenfassen. Dies ist häufig der Fall, wenn Sie mehrere verwandte Dokumente in derselben Partition speichern möchten. Sie können z. B. Bücher und Buchbesprechungen in derselben Sammlung speichern und anhand der bookId partitionieren. In einem solchen Fall möchten Sie in der Regel Ihre Dokumente mit einem Feld hinzufügen, das ihren Typ angibt, um sie zu unterscheiden.
Book documents:
{
"id": "b1",
"name": "Azure Cosmos DB 101",
"bookId": "b1",
"type": "book"
}
Review documents:
{
"id": "r1",
"content": "This book is awesome",
"bookId": "b1",
"type": "review"
},
{
"id": "r2",
"content": "Best book ever!",
"bookId": "b1",
"type": "review"
}
Datenmodellierung für Azure Synapse Link und den Azure Cosmos DB-Analysespeicher
Azure Synapse Link für Azure Cosmos DB ist eine cloudnative hybride Verarbeitungsfunktion für Transaktionen und Analysen (Hybrid Transactional and Analytical Processing, HTAP), mit der Sie in Azure Cosmos DB in Quasi-Echtzeit Analysen für operative Daten ausführen können. Azure Synapse Link sorgt für eine nahtlose Integration zwischen Azure Cosmos DB und Azure Synapse Analytics.
Diese Integration erfolgt über den Azure Cosmos DB-Analysespeicher, eine einspaltige Darstellung Ihrer Transaktionsdaten, die umfangreiche Analysen ohne Auswirkungen auf Ihre Transaktionsworkloads ermöglicht. Dieser Analysespeicher eignet sich für schnelle, kosteneffiziente Abfragen großer operativer Datensätze, ohne dass Daten kopiert werden und ohne dass die Leistung Ihrer Transaktionsworkloads beeinträchtigt wird. Wenn Sie einen Container mit aktiviertem Analysespeicher erstellen oder den Analysespeicher für einen vorhandenen Container aktivieren, werden alle transaktionalen Einfügungen, Aktualisierungen und Löschungen nahezu in Echtzeit mit dem Analysespeicher synchronisiert, sodass weder ein Änderungsfeed noch ETL-Aufträge benötigt werden.
Mit Azure Synapse Link können Sie sich jetzt direkt von Azure Synapse Analytics aus mit Ihren Azure Cosmos DB-Containern verbinden und auf den Analysespeicher zugreifen – ohne Kosten für Anforderungseinheiten (Request Units, RUs). Azure Synapse Analytics unterstützt derzeit Azure Synapse Link mit Synapse Apache Spark und serverlosen SQL-Pools. Wenn Sie über ein global verteiltes Azure Cosmos DB-Konto verfügen, ist es nach dem Aktivieren des Analysespeichers für einen Container in allen Regionen für dieses Konto verfügbar.
Automatischer Schemarückschluss für Analysespeicher
Während der transaktionale Speicher von Azure Cosmos DB ein zeilenorientierter, halbstrukturierter Datenspeicher ist, weist der Analysespeicher ein einspaltiges und strukturiertes Format auf. Diese Konvertierung erfolgt automatisch für Kunden automatisch und unter Verwendung der Regeln für den Schemarückschluss für den Analysespeicher. Bei der Konvertierung gelten Beschränkungen in Bezug auf die maximale Anzahl von geschachtelten Ebenen, die maximale Anzahl von Eigenschaften, nicht unterstützte Datentypen und mehr.
Hinweis
Im Kontext des Analysespeichers betrachten wir die folgenden Strukturen als Eigenschaft:
- JSON-„Elemente“ oder „Zeichenfolgen-Wert-Paare, die durch ein
:getrennt sind.“ - JSON-Objekte, getrennt durch
{und}. - JSON-Arrays, getrennt durch
[und].
Sie können die Auswirkungen der Schemarückschlusskonvertierung minimieren und die Analysefähigkeiten maximieren, indem Sie die folgenden Techniken anwenden.
Normalisierung
Die Normalisierung verliert ihre Bedeutung, da Sie unter Verwendung von T-SQL oder Spark SQL mit Azure Synapse Link Verknüpfungen zwischen Ihren Containern herstellen können. Die erwarteten Vorteile der Normalisierung sind folgende:
- Geringerer Datenspeicherbedarf sowohl im Transaktions- als auch im Analysespeicher.
- Kleinere Transaktionen.
- Weniger Eigenschaften pro Dokument.
- Datenstrukturen mit weniger geschachtelten Ebenen.
Beachten Sie, dass die beiden letzten Aspekte – weniger Eigenschaften und weniger Ebenen – die Leistung Ihrer Analyseabfragen verbessern, aber auch die Wahrscheinlichkeit verringern, dass Teile Ihrer Daten nicht im Analysespeicher dargestellt werden. Wie im Artikel zu den Regeln für den automatischen Schemarückschluss beschrieben, gelten Beschränkungen hinsichtlich der Anzahl von Ebenen und Eigenschaften, die im Analysespeicher dargestellt werden.
Ein weiterer wichtiger Aspekt für die Normalisierung ist, dass serverlose SQL-Pools in Azure Synapse Ergebnissätze mit bis zu 1.000 Spalten unterstützen, wobei das Verfügbarmachen von geschachtelten Spalten auf diese Obergrenze angerechnet wird. Anders ausgedrückt: Das Limit von 1.000 Eigenschaften gilt sowohl für den Analysespeicher als auch für die serverlosen Synapse SQL-Pools.
Was also tun angesichts der Tatsache, dass die Denormalisierung eine wichtige Datenmodellierungstechnik für Azure Cosmos DB ist? Die Antwort lautet: Sie müssen die richtige Balance für Ihre Transaktions- und Analyseworkloads finden.
Partitionsschlüssel
Ihr Azure Cosmos DB-Partitionsschlüssel wird im Analysespeicher nicht verwendet. Und jetzt können Sie die benutzerdefinierte Partitionierung des Analysespeichers für Kopien des Analysespeichers mit Verwendung eines beliebigen Partitionsschlüssels nutzen. Aufgrund dieser Isolation können Sie einen Partitionsschlüssel für Ihre Transaktionsdaten auswählen, bei denen der Schwerpunkt auf Datenerfassung und Punktlesevorgängen liegt, während partitionsübergreifende Abfragen mit Azure Synapse Link durchgeführt werden können. Sehen wir uns ein Beispiel an:
In einem hypothetischen globalen IoT-Szenario ist device id ein guter Partitionsschlüssel, da alle Geräte ein ähnliches Datenvolume aufweisen und somit kein Problem mit heißen Partitionen entsteht. Wenn Sie jedoch die Daten von mehr als einem Gerät analysieren möchten, z. B. „alle Daten von gestern“ oder „Gesamtwerte pro Stadt“, kann es zu Problemen kommen, da es sich dabei um partitionsübergreifende Abfragen handelt. Diese Abfragen können sich negativ auf Ihre Transaktionsleistung auswirken, da sie zur Ausführung einen Teil Ihres RU-Durchsatzes beanspruchen. Aber mit Azure Synapse Link können Sie diese Analyseabfragen ohne RU-Kosten ausführen. Das einspaltige Format des Analysespeichers ist für Analyseabfragen optimiert, und Azure Synapse Link nutzt diese Eigenschaft, um eine hohe Leistung mit Azure Synapse Analytics-Runtimes zu ermöglichen.
Datentypen und Eigenschaftennamen
Im Artikel zu den Regeln für einen automatischen Schemarückschluss werden die unterstützten Datentypen aufgeführt. Während ein nicht unterstützter Datentyp die Darstellung im Analysespeicher blockiert, können unterstützte Datentypen unterschiedlich von den Azure Synapse-Runtimes verarbeitet werden. Ein Beispiel: Bei der Verwendung von DateTime-Zeichenfolgen, die dem UTC-Standard ISO 8601 entsprechen, stellen Spark-Pools in Azure Synapse diese Spalten als „string“ dar, während serverlose SQL-Pools in Azure Synapse diese Spalten als „varchar(8000)“ darstellen.
Eine weitere Herausforderung besteht darin, dass nicht alle Zeichen von Azure Synapse Spark akzeptiert werden. Während Leerzeichen unterstützt werden, sind Zeichen wie Doppelpunkt, Graviszeichen und Komma unzulässig. Angenommen, Ihr Dokument umfasst eine Eigenschaft Vorname, Nachname. Diese Eigenschaft wird im Analysespeicher dargestellt, und ein serverloser Synapse SQL-Pool kann sie problemlos lesen. Azure Synapse Spark kann die Daten jedoch nicht aus dem Analysespeicher lesen, einschließlich aller anderen Eigenschaften. Letztendlich können Sie Azure Synapse Spark nicht verwenden, wenn Sie über eine Eigenschaft verfügen, die nicht unterstützte Zeichen in ihrem Namen verwendet.
Datenvereinfachung
Alle Eigenschaften auf der Stammebene Ihrer Azure Cosmos DB-Daten werden im Analysespeicher als Spalte repräsentiert, und alle weiteren Eigenschaften auf tieferen Ebenen Ihres Dokumentdatenmodells werden als JSON dargestellt, auch in geschachtelten Strukturen. Geschachtelte Strukturen erfordern eine zusätzliche Verarbeitung durch die Azure Synapse Runtimes, um die Daten in einem strukturierten Format zu vereinfachen. Dies kann in Big Data-Szenarien eine Herausforderung darstellen.
Das folgende Dokument enthält nur zwei Spalten im Analysespeicher, id und contactDetails. Alle weiteren Daten, email und phone, erfordern eine zusätzliche Verarbeitung durch SQL-Funktionen, um einzeln gelesen zu werden.
{
"id": "1",
"contactDetails": [
{"email": "thomas@andersen.com"},
{"phone": "+1 555 555-5555"}
]
}
Das nachstehende Dokument umfasst drei Spalten im Analysespeicher, id, email und phone. Alle Daten sind direkt als Spalten zugänglich.
{
"id": "1",
"email": "thomas@andersen.com",
"phone": "+1 555 555-5555"
}
Datentiering
Mit Azure Synapse Link können Sie die Kosten unter folgenden Gesichtspunkten senken:
- Es werden weniger Abfragen in Ihrer Transaktionsdatenbank ausgeführt.
- Ein Partitionsschlüssel, der für Datenerfassung und Punktlesevorgänge optimiert ist, reduziert den Datenspeicherbedarf, Szenarien mit heißen Partitionen und Partitionsaufteilungen.
- Datentiering, da die Gültigkeitsdauer des Analysespeichers (Analytische TTL, ATTL) unabhängig von der Gültigkeitsdauer des Transaktionsspeichers (Transaktionale TTL, TTTL) ist. Sie können Ihre Transaktionsdaten für einige Tage, Wochen oder Monate im Transaktionsspeicher aufbewahren und die Daten im Analysespeicher für mehrere Jahre oder dauerhaft beibehalten. Das einspaltige Format des Analysespeichers sorgt für eine natürliche Datenkomprimierung zwischen 50 % und 90 %. Und seine Kosten pro GB betragen ~10 % des gegenwärtigen Preises eines Transaktionsspeichers. Weitere Informationen zu den aktuellen Sicherungseinschränkungen finden Sie unter Was ist der Azure Cosmos DB-Analysespeicher?.
- In Ihrer Umgebung werden keine ETL-Aufträge ausgeführt, d. h. Sie müssen keine RUs für diese Aufträge bereitstellen.
Kontrollierte Redundanz
Dies ist eine gute Alternative in folgenden Situationen: Es ist bereits ein Datenmodell vorhanden, und dieses kann nicht geändert werden. Außerdem lässt sich das vorhandene Datenmodell aufgrund von Regeln für den automatischen Schemarückschluss, etwa die Begrenzung geschachtelter Ebenen oder die maximale Anzahl von Eigenschaften, nicht gut in den Analysespeicher integrieren. Sollte dies zutreffen, können Sie den Azure Cosmos DB-Änderungsfeed nutzen, um Ihre Daten in einen anderen Container zu replizieren und die erforderlichen Transformationen für ein Azure Synapse Link-freundliches Datenmodell anzuwenden. Sehen wir uns ein Beispiel an:
Szenario
Der Container CustomersOrdersAndItems wird verwendet, um Onlinebestellungen einschließlich Kunden- und Artikeldetails zu speichern: Rechnungsadresse, Lieferadresse, Liefermethode, Lieferstatus, Artikelpreis, usw. Es werden nur die ersten 1.000 Eigenschaften dargestellt, und die Schlüsselinformationen sind nicht im Analysespeicher enthalten. Aus diesem Grund kann Azure Synapse Link nicht verwendet werden. Der Container enthält eine sehr große Anzahl von Datensätzen (mehrere PBs), weshalb es nicht möglich ist, die Anwendung zu ändern und die Daten umzugestalten.
Ein weiterer problematischer Aspekt ist das Big Data-Volume. Milliarden von Zeilen werden ständig von der Analyseabteilung genutzt, weshalb Sie die TTTL nicht zum Löschen von alten Daten verwenden können. Die Pflege der gesamten Datenhistorie in der Transaktionsdatenbank aufgrund der Analyseanforderungen macht es erforderlich, die Bereitstellung von RUs ständig zu erhöhen, was sich wiederum auf die Kosten auswirkt. Transaktions- und Analyseworkloads konkurrieren gleichzeitig um dieselben Ressourcen.
Vorgehensweise
Lösung mit Änderungsfeed
- Das Entwicklungsteam hat beschlossen, einen Änderungsfeed zu verwenden, um drei neue Container aufzufüllen:
Customers,Orders, undItems. Mithilfe des Änderungsfeeds werden die Daten normalisiert und vereinfacht. Nicht benötigte Informationen werden aus dem Datenmodell entfernt, und jeder Container hat annähernd 100 Eigenschaften, wodurch Datenverluste aufgrund von Beschränkungen für den automatischen Schemarückschluss vermieden werden. - Für diese neuen Container ist der Analysespeicher aktiviert, und die Analyseabteilung nutzt nun Azure Synapse Analytics zum Lesen der Daten. Dies verringert die RU-Nutzung, da die Analyseabfragen in Synapse Apache Spark und serverlosen SQL-Pools erfolgen.
- Für Container
CustomersOrdersAndItemsist die TTTL nun so festgelegt, dass die Daten nur sechs Monate aufbewahrt werden. Auf diese Weise kann die RU-Nutzung weiter gesenkt werden, weil in Azure Cosmos DB ein Minimum von 10 RUs pro GB gilt. Weniger Daten, weniger RUs.
Wesentliche Punkte
Die wichtigsten Erkenntnisse dieses Artikels bestehen darin, dass die Datenmodellierung in einer schemafreien Welt genauso wichtig ist wie eh und je.
Genauso wie Daten auf einem Bildschirm nicht nur auf eine einzige Weise dargestellt werden können, gibt es auch nicht nur eine einzige Möglichkeit, Ihre Daten zu modellieren. Sie müssen Ihre Anwendung kennen und wissen, wie die Daten erstellt, verwendet und verarbeitet werden. Erst dann können Sie durch Anwenden von einigen der hier vorgestellten Richtlinien damit beginnen, ein Modell zu erstellen, das die unmittelbaren Anforderungen der Anwendung berücksichtigt. Wenn sich Ihre Anwendungen ändern müssen, können Sie die Flexibilität einer schemafreien Datenbank nutzen, um diese Änderung zu übernehmen und um das Datenmodell problemlos weiterzuentwickeln.
Nächste Schritte
Weitere Informationen zu Azure Cosmos DB finden Sie auf der Dokumentationsseite des Diensts.
Informationen zur horizontalen Partitionierung („Sharding“) Ihrer Daten auf mehreren Partitionen finden Sie unter Partitionieren von Daten in Azure Cosmos DB.
Erfahren Sie mehr über das Modellieren und Partitionieren von Daten in Azure Cosmos DB anhand eines praktischen Beispiels.
Weitere Informationen finden Sie im Trainingsmodul zum Modellieren und Partitionieren Ihrer Daten in Azure Cosmos DB.
Informieren Sie sich über die Konfiguration und Verwendung von Azure Synapse Link für Azure Cosmos DB.
Versuchen Sie, die Kapazitätsplanung für eine Migration zu Azure Cosmos DB durchzuführen? Sie können Informationen zu Ihrem vorhandenen Datenbankcluster für die Kapazitätsplanung verwenden.
- Wenn Sie lediglich die Anzahl der virtuellen Kerne und Server in Ihrem vorhandenen Datenbankcluster kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mithilfe von virtuellen Kernen oder virtuellen CPUs.
- Wenn Sie die typischen Anforderungsraten für Ihre aktuelle Datenbankworkload kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mit dem Azure Cosmos DB-Kapazitätsplaner