Einrichten einer Umgebung für Azure KI Services für Big Data
Das Einrichten Ihrer Umgebung ist der erste Schritt beim Aufbau einer Pipeline für Ihre Daten. Nachdem Sie Ihre Umgebung vorbereitet haben, können Sie ein Beispiel schnell und einfach ausführen.
In diesem Artikel führen Sie die folgenden Schritte aus, die Ihnen den Einstieg erleichtern:
Erstellen einer Azure KI Services-Ressource
Damit Sie mit Big Data in Azure KI Services arbeiten können, erstellen Sie zuerst eine Azure KI Services-Ressource für Ihren Workflow. Es gibt zwei Haupttypen von Azure KI Services: Clouddienste, die in Azure gehostet werden, und Containerdienste, die von Benutzern verwaltet werden. Es wird empfohlen, mit dem einfacheren cloudbasierten Typ von Azure KI Services zu beginnen.
Clouddienste
Cloudbasierte Azure KI Services sind intelligente Algorithmen, die in Azure gehostet werden. Diese Dienste sind ohne Training einsatzbereit. Sie benötigen lediglich eine Internetverbindung. Sie können Ressourcen für Azure KI-Dienste im Azure-Portal erstellen oder mit der Azure CLI.
Dienste in Containern (optional)
Wenn für Ihre Anwendung oder Workload große Datasets verwendet werden, private Netzwerke erforderlich sind oder keine Verbindung mit der Cloud hergestellt werden kann, ist die Kommunikation mit Clouddiensten unter Umständen nicht möglich. In dieser Situation haben containerisierte Azure KI Services folgende Vorteile:
Niedrige Konnektivität: Sie können containerisierte Azure KI Services in jeder beliebigen Computerumgebung bereitstellen, sowohl in als auch außerhalb der Cloud. Wenn Ihre Anwendung nicht mit der Cloud in Kontakt treten kann, erwägen Sie die Bereitstellung von containerisierten Azure KI Services für Ihre Anwendung.
Geringe Wartezeit: Da für Dienste in Containern die Roundtrip-Kommunikation von/zur Cloud nicht erforderlich ist, werden Antworten mit erheblich geringeren Latenzzeiten zurückgegeben.
Datenschutz und -sicherheit: Sie können Dienste in Containern in privaten Netzwerken bereitstellen, sodass sensible Daten das Netzwerk nicht verlassen.
Hohe Skalierbarkeit: Für Dienste in Containern gibt es keine Begrenzung der Datenübertragungsrate, und sie werden auf von Benutzern verwalteten Computern ausgeführt. Auf diese Weise können Sie Azure KI Services unbegrenzt skalieren, um weitaus größere Workloads zu verarbeiten.
Befolgen Sie diese Anleitung, um einen containerisierten Azure KI Services-Dienst zu erstellen.
Erstellen eines Apache Spark-Clusters
Apache Spark™ ist ein verteiltes Computing-Framework, das für die Verarbeitung von Big Data-Daten konzipiert ist. Benutzer können mit Apache Spark in Azure mit Diensten wie Azure Databricks, Azure Synapse Analytics, HDInsight und Azure Kubernetes Services arbeiten. Um Azure KI Services für Big Data verwenden zu können, müssen Sie zuerst einen Cluster erstellen. Wenn Sie bereits über einen Spark-Cluster verfügen, können Sie gleich ein Beispiel testen.
Azure Databricks
Azure Databricks ist eine Apache Spark-basierte Analyseplattform, die mit nur einem Klick eingerichtet werden kann und optimierte Workflows sowie einen interaktiven Arbeitsbereich bietet. Sie wird häufig für die Zusammenarbeit zwischen Datenanalysten, Technikern und Wirtschaftsanalytikern verwendet. Führen Sie die folgenden Schritte aus, um Azure KI Services für Big Data in Azure Databricks zu verwenden:
Installieren Sie die Open-Source-Bibliothek von SynapseML (oder die MMLSpark-Bibliothek, wenn Sie eine Legacyanwendung unterstützen):
Erstellen einer neuen Bibliothek in Ihrem Databricks-Arbeitsbereich
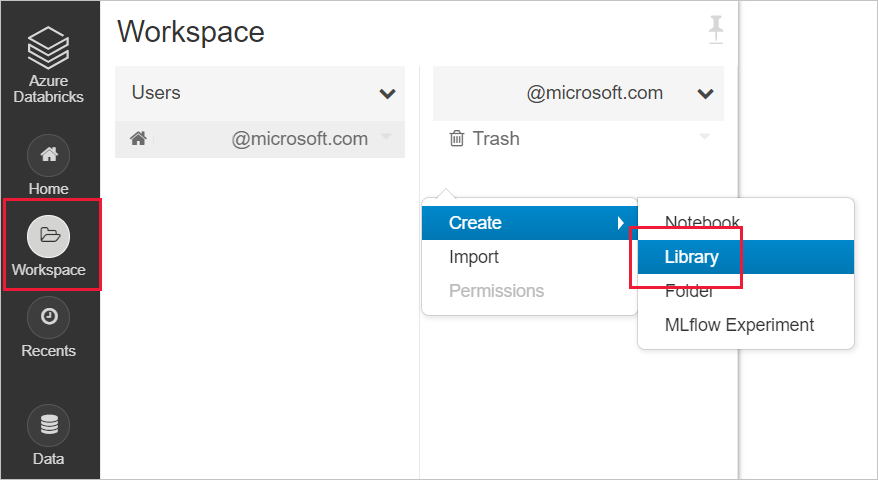
Geben Sie für SynapseML die folgenden Maven-Koordinaten ein:
com.microsoft.azure:synapseml_2.12:0.10.0Repository: default (Standard)Geben Sie für MMLSpark (Legacy) die folgenden Maven-Koordinaten ein:
com.microsoft.ml.spark:mmlspark_2.11:1.0.0-rc3Repository:https://mmlspark.azureedge.net/maven
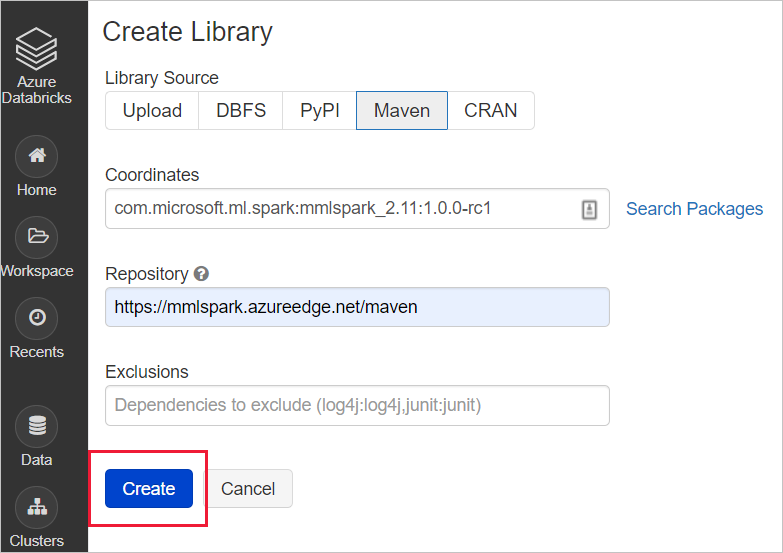
Installieren der Bibliothek auf einem Cluster

Azure Synapse Analytics (optional)
Optional können Sie Synapse Analytics zum Erstellen eines Spark-Clusters verwenden. Azure Synapse vereint Data Warehousing für Unternehmen mit Big Data-Analysen. Er ermöglicht flexible Datenabfragen nach Ihren Vorstellungen, indem serverlose On-Demand-Ressourcen oder bereitgestellten Ressourcen im gewünschten Umfang verwendet werden. Für erste Schritte mit Azure Synapse Analytics gehen Sie folgendermaßen vor:
In Azure Synapse Analytics wird Big Data für Azure KI Services standardmäßig installiert.
Azure Kubernetes Service
Wenn Sie containerisierte Azure KI Services verwenden, ist eine beliebte Option für die Bereitstellung von Spark neben Containern der Azure Kubernetes Service.
Führen Sie zum Einstieg in den Azure Kubernetes-Dienst die folgenden Schritte aus:
Schnellstart: Bereitstellen eines AKS-Clusters (Azure Kubernetes Service) über das Azure-Portal
Installieren des Apache Spark 2.4.0-Helm-Charts – Warnung: Spark 2.4 wurde eingestellt und wird nicht mehr unterstützt.
Beispiel ausprobieren
Nachdem Sie den Spark-Cluster und die Umgebung eingerichtet haben, können Sie ein kurzes Beispiel ausführen. In diesem Beispiel wird davon ausgegangen, dass Azure Databricks und das mmlspark.cognitive-Paket vorhanden sind. Ein Beispiel zum Verwenden von synapseml.cognitive finden Sie unter Hinzufügen der Suche zu KI-angereicherten Daten aus Apache Spark mit SynapseML.
Zunächst können Sie ein Notebook in Azure Databricks erstellen. Verwenden Sie für andere Spark-Clusteranbieter deren Notebooks oder Spark Submit.
Erstellen Sie ein neues Databricks-Notebook, indem Sie im Menü Azure Databricks die Option Neues Notebook auswählen.

Geben Sie in Notebook erstellen einen Namen ein, wählen Sie Python als Sprache und dann den zuvor erstellten Spark-Cluster aus.
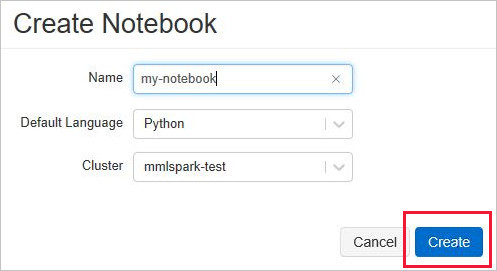
Klicken Sie auf Erstellen.
Fügen Sie diesen Codeausschnitt in Ihr neues Notebook ein.
from mmlspark.cognitive import * from pyspark.sql.functions import col # Add your region and subscription key from the Language service service_key = "ADD-SUBSCRIPTION-KEY-HERE" service_region = "ADD-SERVICE-REGION-HERE" df = spark.createDataFrame([ ("I am so happy today, its sunny!", "en-US"), ("I am frustrated by this rush hour traffic", "en-US"), ("The Azure AI services on spark aint bad", "en-US"), ], ["text", "language"]) sentiment = (TextSentiment() .setTextCol("text") .setLocation(service_region) .setSubscriptionKey(service_key) .setOutputCol("sentiment") .setErrorCol("error") .setLanguageCol("language")) results = sentiment.transform(df) # Show the results in a table display(results.select("text", col("sentiment")[0].getItem("score").alias("sentiment")))Beziehen Sie Ihren Regions- und Abonnementschlüssel über das Menü Schlüssel und Endpunkt aus der Sprachressource im Azure-Portal.
Ersetzen Sie die Platzhalter für Region und Abonnementschlüssel im Code Ihres Databricks Notebooks durch Werte, die für Ihre Ressource gültig sind.
Wählen Sie das Wiedergabesymbol – bzw. das Dreieck – rechts oben in der Notebook-Zelle aus, um das Beispiel auszuführen. Wählen Sie optional Alle am Anfang des Notebooks aus, um alle Zellen auszuführen. Die Antworten werden unterhalb der Zelle in einer Tabelle angezeigt.
Erwartete Ergebnisse
| text | Stimmung |
|---|---|
| Ich bin heute so glücklich, die Sonne scheint! | 0,978959 |
| Ich bin frustriert über diesen Berufsverkehr. | 0,0237956 |
| Azure KI Services in Spark sind gar nicht schlecht | 0,888896 |