Datenmigration, ETL und Ladevorgänge für die Teradata-Migration
Dieses Tutorial ist der 2. Teil eines siebenteiligen Leitfadens für die Migration von Teradata zu Azure Synapse Analytics. Schwerpunktmäßig behandelt dieses Tutorial bewährte Methoden für ETL-Prozesse und Lademigration.
Überlegungen zur Datenmigration
Erste Entscheidungen für die Datenmigration von Teradata
Beim Migrieren eines Teradata-Datenspeichers sollten Sie sich einige grundlegende Fragen stellen. Beispiel:
Sollen nicht verwendete Tabellenstrukturen migriert werden?
Mit welchem Migrationsansatz lassen sich Risiken und Auswirkungen für Benutzer am besten minimieren?
Soll beim Migrieren von Data Marts eine physische Implementierung (wie bisher) oder lieber eine virtuelle Implementierung verwendet werden?
In den folgenden Abschnitten werden diese Punkte im Kontext der Migration von Teradata erörtert.
Sollen nicht verwendete Tabellen migriert werden?
Tipp
In Legacy-Systemen ist es nicht ungewöhnlich, dass Tabellen im Laufe der Zeit redundant werden – diese müssen in den meisten Fällen nicht migriert werden.
Es ist sinnvoll, nur Tabellen zu migrieren, die im vorhandenen System verwendet werden. Nicht aktive Tabellen können statt migriert archiviert werden, sodass die Daten in Zukunft bei Bedarf verfügbar sind. Es ist am besten, Systemmetadaten und Protokolldateien anstelle der Dokumentation zu verwenden, um festzustellen, welche Tabellen in Gebrauch sind, da die Dokumentation veraltet sein kann.
Falls aktiviert, enthalten die Teradata-Systemkatalogtabellen und -Protokolle Informationen, anhand derer festgestellt werden kann, wann auf eine bestimmte Tabelle zuletzt zugegriffen wurde. Damit kann entschieden werden, ob eine Tabelle für eine Migration in Frage kommt.
Hier ist eine Beispielabfrage von DBC.Tables, die das Datum des letzten Zugriffs und der letzten Änderung zurückgibt:
SELECT TableName, CreatorName, CreateTimeStamp, LastAlterName,
LastAlterTimeStamp, AccessCount, LastAccessTimeStamp
FROM DBC.Tables t
WHERE DataBaseName = 'databasename'
Wenn die Protokollierung aktiviert ist und auf den Protokollverlauf zugegriffen werden kann, stehen in der Tabelle DBQLogTbl und den zugehörigen Protokollierungstabellen weitere Informationen wie z. B. der Text der SQL-Abfrage zur Verfügung. Weitere Informationen finden Sie unter Protokollverlauf von Teradata.
Mit welchem Migrationsansatz lassen sich Risiken und Auswirkungen für Benutzer am besten minimieren?
Diese Frage wird häufig gestellt, da Unternehmen möglicherweise die Auswirkungen von Änderungen auf das Data Warehouse-Datenmodell verringern möchten, um die Agilität zu verbessern. Unternehmen sehen oft eine Möglichkeit, ihre Daten während einer ETL-Migration weiter zu modernisieren oder umzuwandeln. Dieser Ansatz trägt ein höheres Risiko, da mehrere Faktoren gleichzeitig geändert werden, was einen Vergleich der Ergebnisse des alten Systems mit denen des neuen erschwert. Änderungen am Datenmodell an dieser Stelle können sich auch auf vor- oder nachgelagerte ETL-Jobs für andere Systeme auswirken. Aufgrund dieses Risikos ist es besser, nach der Data-Warehouse-Migration eine Neugestaltung in diesem Umfang vorzunehmen.
Auch wenn ein Datenmodell im Rahmen der Gesamtmigration absichtlich geändert wird, empfiehlt es sich, das vorhandene Modell unverändert zu Azure Synapse zu migrieren, anstatt eine Neuentwicklung auf der neuen Plattform vorzunehmen. Das hat den Vorteil, dass die Auswirkungen auf vorhandene Produktionssysteme minimiert und gleichzeitig die Leistung und die elastische Skalierbarkeit der Azure-Plattform für einmalige Aufgaben zum Re-Engineering genutzt werden.
Bei der Migration von Teradata empfiehlt sich die Erstellung einer Teradata-Umgebung in einer VM in Azure als Ausgangspunkt für den Migrationsprozess.
Tipp
Migrieren Sie das bestehende Modell zunächst im Ist-Zustand, auch wenn eine Änderung des Datenmodells in Zukunft geplant ist.
Verwenden einer Teradata-Instanz auf einer VM als Teil einer Migration
Ein optionaler Ansatz für die Migration einer lokalen Teradata-Umgebung besteht darin, die Azure-Umgebung zu nutzen, um eine Teradata-Instanz in einer VM in Azure zu erstellen, die mit der Azure Synapse-Zielumgebung verbunden ist. Dies ist möglich, da Azure günstigen Cloudspeicher und elastische Skalierbarkeit bietet.
Bei diesem Ansatz können standardmäßige Teradata-Hilfsprogramme wie Teradata Parallel Data Transporter (oder Datenreplikationstools von Drittanbietern wie Attunity Replicate) zum Einsatz kommen, um die Teilmenge der zu migrierenden Teradata-Tabellen effizient in die VM-Instanz zu verschieben. Anschließend können alle Migrationsaufgaben innerhalb der Azure-Umgebung erfolgen. Dieser Ansatz hat mehrere Vorteile:
Nach der ersten Replikation von Daten wird das Quellsystem von den Migrationsaufgaben nicht weiter beeinträchtigt.
Die Azure-Umgebung bietet vertraute Schnittstellen, Tools und Hilfsprogramme von Teradata.
Die Azure-Umgebung sorgt für Verfügbarkeit von Netzwerkbandbreite zwischen dem lokalen Quellsystem und dem Zielsystem in der Cloud.
Tools wie Azure Data Factory können Hilfsprogramme wie Teradata Parallel Transporter effizient aufrufen, um Daten schnell und einfach zu migrieren.
Der Migrationsprozess wird vollständig in der Azure-Umgebung orchestriert und gesteuert.
Soll beim Migrieren von Data Marts eine physische Implementierung (wie bisher) oder lieber eine virtuelle Implementierung verwendet werden?
Tipp
Durch Virtualisierung von Data Marts können Speicher- und Verarbeitungsressourcen eingespart werden.
In bisherigen Data Warehouse-Umgebungen von Teradata ist es üblich, mehrere Data Marts zu erstellen, die so strukturiert sind, dass sie eine gute Leistung für Ad-hoc-Self-Service-Abfragen und Berichte für eine bestimmte Abteilung oder Geschäftsfunktion innerhalb einer Organisation bieten. Daher besteht ein Data Mart in der Regel aus einer Teilmenge des Data Warehouse und enthält aggregierte Versionen der Daten in einer Form, die Benutzern das einfache Abfragen dieser Daten mit kurzen Reaktionszeiten über benutzerfreundliche Abfragetools wie Microsoft Power BI, Tableau oder MicroStrategy ermöglicht. Bei dieser Form handelt es sich in der Regel um ein eindimensionales Datenmodell. Eine Verwendung von Data Marts besteht darin, die Daten in einer nutzbaren Form verfügbar zu machen, selbst wenn das zugrunde liegende Warehouse-Datenmodell z. B. ein Datentresor ist.
Sie können auch separate Data Marts für einzelne Geschäftsbereiche innerhalb einer Organisation verwenden, um zuverlässige Datensicherheitsregelungen zu implementieren, indem nur der Benutzerzugriff auf bestimmte, relevante Data Marts gewährt und vertrauliche Daten entfernt, verborgen oder anonymisiert werden.
Wenn diese Data Marts als physische Tabellen implementiert sind, werden zusätzliche Speicherressourcen nötig, um diese zu speichern, und zusätzliche Verarbeitungsschritte, um sie regelmäßig zu erstellen und zu aktualisieren. Zudem entspricht die Aktualität der Daten im Data Mart nur dem letzten Aktualisierungsvorgang, sodass sie daher möglicherweise für stark veränderliche Datendashboards nicht geeignet sind.
Tipp
Leistung und Skalierbarkeit von Azure Synapse ermöglichen eine Virtualisierung ohne Leistungsbeeinträchtigung.
Mit dem Aufkommen relativ kostengünstiger skalierbarer MPP-Architekturen wie Azure Synapse und den damit verbundenen Leistungsmerkmalen können Sie möglicherweise Data Mart-Funktionalität bereitstellen, ohne den Data Mart als Gruppe physischer Tabellen instanziieren zu müssen. Dies wird durch eine effektive Virtualisierung der Data Marts über SQL-Sichten auf das zentrale Data Warehouse oder über eine Virtualisierungsschicht mithilfe von Features wie Sichten in Azure oder Visualisierungsprodukten von Microsoft-Partnern erreicht. Durch diesen Ansatz wird die Notwendigkeit zusätzlicher Speicher- und Aggregationsverarbeitung minimiert oder aufgehoben und die Gesamtanzahl zu migrierender Datenbankobjekte reduziert.
Dieser Ansatz bietet einen weiteren potenziellen Vorteil. Durch Implementierung der Aggregations- und Joinlogik innerhalb einer Virtualisierungsschicht und die Darstellung externer Berichtstools über eine virtualisierte Sicht wird die zum Erstellen dieser Sichten erforderliche Verarbeitung per Push an das Data Warehouse übertragen. Dies ist in der Regel der beste Ort zum Ausführen von Joins, Aggregationen und anderen verwandten Vorgängen für große Datenvolumen.
Folgende Gründe sprechen für die Wahl einer virtuellen Data Mart-Implementierung anstelle eines physischen Data Marts:
Mehr Agilität: Virtuelle Data Marts können einfacher geändert werden als physische Tabellen und die zugehörigen ETL-Prozesse.
Geringere Gesamtkosten: In einer virtualisierten Implementierung sind weniger Datenspeicher und Datenkopien erforderlich.
Keine zu migrierenden ETL-Aufträge und vereinfachte Data-Warehouse-Architektur in einer virtualisierten Umgebung.
Leistung: Bisher waren zwar physische Data Marts leistungsfähiger, aber jetzt werden durch Virtualisierungsprodukte intelligente Zwischenspeicherungsverfahren implementiert, um dies auszugleichen.
Datenmigration aus Teradata
Verstehen Ihrer Daten
Ein Teil der Migrationsplanung besteht darin, sich einen Überblick über das zu migrierende Datenvolumen zu verschaffen, da dadurch die Entscheidungen über den Migrationsansatz beeinflusst werden kann. Bestimmen Sie anhand von Systemmetadaten den physischen Speicherplatz, der von den „Rohdaten“ in den zu migrierenden Tabellen belegt wird. Mit „Rohdaten“ ist in diesem Zusammenhang der von den Datenzeilen in einer Tabelle belegte Platz ohne Mehrbedarf für Indizes und Komprimierung gemeint. Dies gilt insbesondere für die besonders große Faktentabellen, da diese in der Regel mehr als 95 % der Daten umfassen.
Sie können eine genaue Zahl für das Volumen der zu migrierenden Daten für eine bestimmte Tabelle ermitteln, indem Sie eine repräsentative Stichprobe der Daten – beispielsweise eine Million Zeilen – in eine nicht komprimierte, durch Trennzeichen getrennte Flatfile mit ASCII-Daten extrahieren. Anschließend ermitteln Sie anhand der Größe dieser Datei die durchschnittliche Menge der Rohdaten pro Tabellenzeile. Multiplizieren Sie schließlich diese durchschnittliche Menge mit der Gesamtanzahl der Zeilen in der ganzen Tabelle, um die Menge der Rohdaten für die Tabelle zu erhalten. Nutzen Sie diese Rohdatenmenge für Ihre Planung.
Überlegungen zur ETL-Migration
Erste Entscheidungen im Zusammenhang mit der ETL-Migration in der Teradata-Umgebung
Tipp
Planen Sie den Ansatz für die ETL-Migration vorab, und nutzen Sie dabei von Azure gebotene Möglichkeiten.
Zur ETL/ELT-Verarbeitung verwenden ältere Data Warehouses in Teradata ggf. benutzerdefinierte Skripts mit Teradata-Hilfsprogrammen wie BTEQ und Teradata Parallel Transporter (TPT) oder ETL-Tools von Drittanbietern wie Informatica oder Ab Initio. Mitunter wird in Data Warehouse-Datenbanken in Teradata-Umgebungen eine Kombination aus ETL- und ELT-Ansätzen verwendet, die im Laufe der Zeit weiterentwickelt wurde. Bei Planung einer Migration zu Azure Synapse geht es darum, die beste Möglichkeit zur Implementierung der erforderlichen ETL/ELT-Verarbeitungsschritte in der neuen Umgebung zu finden, mit der gleichzeitig die damit verbundenen Kosten und Risiken minimiert werden. Weitere Informationen zur ETL- und ELT-Verarbeitung finden Sie unter ELT- und ETL-Entwurfsansatz im Vergleich.
In den folgenden Abschnitten werden Migrationsoptionen erläutert und Empfehlungen für verschiedene Anwendungsfälle gegeben. In diesem Flussdiagramm wird ein Ansatz zusammengefasst:
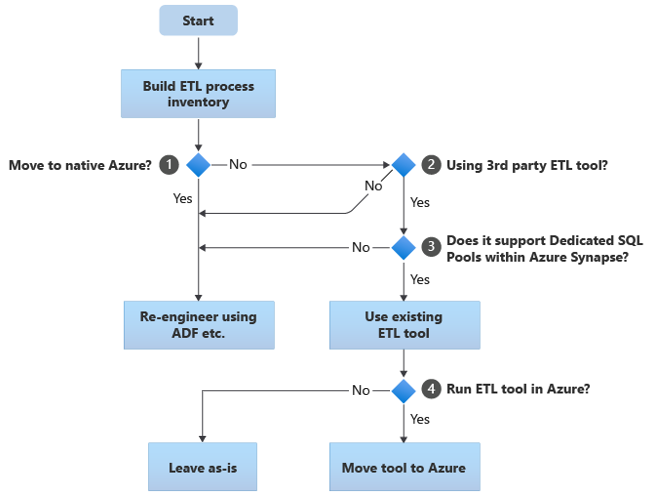
Der erste Schritt ist immer eine Bestandsaufnahme der ETL/ELT-Prozesse, die migriert werden müssen. Wie bei anderen Schritten ist es möglich, dass einige vorhandene Prozesse dank der standardmäßig „integrierten“ Azure-Features nicht migriert werden müssen. Zur Planung müssen Sie sich einen Überblick über den Umfang der durchzuführenden Migration verschaffen.
Im vorherigen Flussdiagramm bezieht sich Entscheidung 1 auf die allgemeine Entscheidung darüber, ob zu einer vollständig Azure-nativen Umgebung migriert werden soll. Bei Migration zu einer vollständig Azure-nativen Umgebung sollten Sie die ETL-Verarbeitung mithilfe von Pipelines und Aktivitäten in Azure Data Factory oder Azure Synapse-Pipelines einem Re-Engineering unterziehen. Wenn Sie nicht zu einer vollständig Azure-nativen Umgebung migrierten, muss im Rahmen der 2. Entscheidung ermittelt werden, ob bereits ein vorhandenes ETL-Tool eines Drittanbieters im Einsatz ist.
In der Teradata-Umgebung kann ein Teil oder die gesamte ETL-Verarbeitung durch benutzerdefinierte Skripts unter Verwendung Teradata-spezifischer Hilfsprogramme wie BTEQ und TPT erfolgen. In diesem Fall sollte Ihr Ansatz das Re-Engineering mithilfe von Data Factory vorsehen.
Tipp
Nutzen Sie Investitionen in vorhandene Tools von Drittanbietern, um Kosten und Risiken zu reduzieren.
Wenn bereits ein ETL-Tool eines Drittanbieters in Gebrauch ist und umfangreich in Qualifikationen investiert wurde oder dieses Tool in verschiedenen bestehenden Workflows und Zeitplänen eingesetzt wird, muss im Rahmen der 3. Entscheidung ermittelt werden, ob das Tool Azure Synapse als Zielumgebung effizient unterstützen kann. Im Idealfall enthält das Tool „native“ Connectors, die Azure-Funktionen wie PolyBase oder COPY INTO nutzen können, um ein effizientes Laden der Daten zu ermöglichen. Es gibt eine Möglichkeit zum Aufrufen eines externen Prozesses wie PolyBase oder COPY INTO und zum Übergeben der entsprechenden Parameter. Nutzen Sie in diesem Fall vorhandene Fertigkeiten und Workflows mit Azure Synapse als neuer Zielumgebung.
Wenn Sie ein vorhandenes ETL-Tool eines Drittanbieters weiterhin einsetzen möchten, sollten Sie es in der Azure-Umgebung (statt auf einem vorhandenen lokalen ETL-Server) ausführen und Azure Data Factory für die gesamte Orchestrierung der bestehenden Workflows nutzen. Dies hat vor allem den Vorteil, dass weniger Daten aus Azure heruntergeladen, verarbeitet und anschließend wieder in Azure hochgeladen werden müssen. Bei der 4. Entscheidung geht es also darum, ob das vorhandene Tool unverändert weiterverwendet oder zur Nutzung von Kosten-, Leistungs- und Skalierbarkeitsvorteilen in die Azure-Umgebung migriert werden soll.
Re-Engineering bereits vorhandener Teradata-spezifischer Skripts
Wenn ein Teil oder die gesamte vorhandene ETL/ELT-Verarbeitung des Teradata-Warehouse über benutzerdefinierte Skripts erfolgt, die Teradata-spezifische Hilfsprogramme wie BTEQ, MLOAD oder TPT einsetzen, müssen diese Skripts für die neue Azure Synapse-Umgebung umprogrammiert werden. Wenn ETL-Prozesse mit gespeicherten Prozeduren in Teradata implementiert wurden, müssen auch diese umprogrammiert werden.
Tipp
Der Bestand der zu migrierenden ETL-Aufgaben sollte Skripts und gespeicherte Prozeduren enthalten.
Einige Elemente des ETL-Prozesses können ohne großen Aufwand migriert werden, z. B. durch einfaches Massenladen von Daten in eine Stagingtabelle aus einer externen Datei. Eventuell ist es sogar möglich, diese Teile des Prozesses zu automatisieren, indem beispielsweise PolyBase anstelle von Fast Load oder MLOAD verwendet wird. Wenn es sich bei den exportierten Dateien um Parquet-Dateien handelt, können Sie einen nativen Parquet-Reader verwenden, der eine schnellere Option als PolyBase darstellt. Bei anderen Teilen des Prozesses, die beliebig komplexe SQL- und/oder andere gespeicherte Prozeduren enthalten, nimmt das Re-Engineering mehr Zeit in Anspruch.
Eine Möglichkeit, Teradata SQL auf Kompatibilität mit Azure Synapse zu testen, besteht darin, einige repräsentative SQL-Anweisungen in den Teradata-Protokollen zu erfassen, diesen Abfragen EXPLAIN voranzustellen und dann – unter der Annahme eines gleichartigen migrierten Datenmodells in Azure Synapse – diese EXPLAIN-Anweisungen in Azure Synapse auszuführen. Bei nicht kompatiblem SQL-Code wird ein Fehler verursacht, wobei der Umfang der Umprogrammierung anhand der Fehlerinformationen bestimmt wird.
Microsoft-Partner bieten Tools und Dienste zum Migrieren von Teradata SQL und gespeicherten Prozeduren in Azure Synapse.
Verwenden von ETL-Tools von Drittanbietern
Wie im vorherigen Abschnitt beschrieben, wird das vorhandene Data Warehouse-Legacysystem bereits von ETL-Produkten von Drittanbietern aufgefüllt und verwaltet. Eine Liste der Microsoft-Partner für Datenintegration für Azure Synapse finden Sie unter Partner für die Datenintegration.
Laden von Daten aus Teradata
Auswahlmöglichkeiten beim Laden von Daten aus Teradata
Tipp
Mithilfe von Tools von Drittanbietern lässt sich der Migrationsprozess vereinfachen und automatisieren und somit das Risiko verringern.
Bei der Migration von Daten aus einem Teradata-Data Warehouse müssen einige grundlegende Fragen im Zusammenhang mit dem Laden von Daten geklärt werden. So muss beispielsweise entschieden werden, wie die Daten physisch aus der vorhandenen lokalen Teradata-Umgebung in Azure Synapse in der Cloud verschoben und welche Tools zum Übertragen und Laden verwendet werden sollen. Beantworten Sie die folgenden Fragen, die in den nächsten Abschnitten erörtert werden.
Sollen die Daten in Dateien extrahiert oder direkt über eine Netzwerkverbindung verschoben werden?
Soll der Prozess über das Quellsystem oder die Azure-Zielumgebung orchestriert werden?
Welche Tools werden zum Automatisieren und Verwalten des Prozesses verwendet?
Werden Daten mittels Dateien oder einer Netzwerkverbindung übertragen?
Tipp
Verschaffen Sie sich einen Überblick über die zu migrierenden Datenvolumen und die verfügbare Netzwerkbandbreite, da diese Faktoren bestimmen, welcher Migrationsansatz befolgt werden kann.
Nachdem die zu migrierenden Datenbanktabellen in Azure Synapse erstellt wurden, können Sie die Daten, mit denen diese Tabellen aufgefüllt werden, aus dem Teradata-Legacysystem in die neue Umgebung verschieben. Dabei gibt es grundsätzlich zwei Ansätze:
Dateiextraktion: Extrahieren Sie die Daten aus den Teradata-Tabellen in Flatfiles, normalerweise im CSV-Format, über BTEQ, Fast Export oder Teradata Parallel Transporter (TPT). Dabei sollte nach Möglichkeit TPT verwendet werden, da diese Option den effizientesten Datendurchsatz bietet.
Bei diesem Ansatz wird Speicherplatz zum Speichern der extrahierten Datendateien benötigt. Dabei kann sich der Speicherplatz lokal in der Teradata-Quelldatenbank (sofern genügend Speicher verfügbar ist) oder remote in Azure Blob Storage befinden. Die beste Leistung wird erreicht, wenn eine Datei lokal geschrieben wird, da dadurch das Netzwerk umgangen wird.
Zur Minimierung der Speicher- und Netzwerkübertragungsanforderungen hat es sich bewährt, die extrahierten Datendateien mit einem Hilfsprogramm wie gzip zu komprimieren.
Nach dem Extrahieren können die Flatfiles entweder (zusammen mit der Azure Synapse-Zielinstanz) in Azure Blob Storage verschoben oder mit PolyBase oder COPY INTO direkt in Azure Synapse geladen werden. Welche Methode zum physischen Verschieben von Daten aus lokalem Speicher in die Azure-Cloudumgebung verwendet wird, hängt von der Datenmenge und verfügbaren Netzwerkbandbreite ab.
Microsoft bietet verschiedene Optionen zum Verschieben großer Datenmengen: so z. B. AzCopy zum Verschieben von Dateien über das Netzwerk in Azure Storage, Azure ExpressRoute zum Verschieben von Massendaten über eine private Netzwerkverbindung und Azure Data Box zum Verschieben von Dateien auf ein physisches Speichergerät, das dann zum Laden an ein Azure-Rechenzentrum versendet wird. Weitere Informationen finden Sie unter Datenübertragung.
Direktes Extrahieren und Laden über das Netzwerk: Die Azure-Zielumgebung sendet (in der Regel über einen SQL-Befehl) eine Anforderung zum Extrahieren von Daten an das Teradata-Legacysystem, um die Daten zu extrahieren. Die Ergebnisse werden über das Netzwerk gesendet und direkt in Azure Synapse geladen, ohne dass die Daten in Zwischendateien gespeichert werden müssen. Der begrenzende Faktor in diesem Szenario ist normalerweise die Bandbreite der Netzwerkverbindung zwischen Teradata-Datenbank und Azure-Umgebung. Bei sehr großen Datenmengen ist dieser Ansatz möglicherweise nicht praktikabel.
Es gibt auch einen Hybridansatz mit beiden Methoden. Sie können beispielsweise den Ansatz der direkten Netzwerkextraktion für kleinere Dimensionstabellen und Stichproben größerer Faktentabellen zum schnellen Bereitstellen einer Testumgebung in Azure Synapse befolgen. Für umfangreiche historische Faktentabellen können Sie den Ansatz der Dateiextraktion und -übertragung mit Azure Data Box wählen.
Orchestrierung durch Teradata oder Azure?
Zum möglichst effizienten Laden von Daten wird empfohlen, beim Umstieg auf Azure Synapse das Extrahieren und Laden der Daten aus der Azure-Umgebung mithilfe von Azure Synapse Pipelines oder Azure Data Factory und mit entsprechenden Hilfsprogrammen wie PolyBase oder COPY INTO zu orchestrieren. Bei diesem Ansatz werden die Möglichkeiten von Azure genutzt, um wiederverwendbare Datenladepipelines einfach zu erstellen.
Weitere Vorteile dieses Ansatzes sind geringere Auswirkungen auf das Teradata-System während des Datenladeprozesses, da der Verwaltungs- und Ladeprozess in Azure erfolgt, sowie die Möglichkeit, den Prozess durch Verwendung metadatengesteuerter Pipelines zum Laden von Daten zu automatisieren.
Welche Tools können eingesetzt werden?
Die Aufgabe der Datentransformation und -verschiebung ist die Grundfunktion aller ETL-Produkte. Wenn in der vorhandenen Teradata-Umgebung bereits eines dieser Produkte im Einsatz ist, lässt sich die Datenmigration von Teradata zu Azure Synapse mithilfe eines vorhandenen ETL-Tools vereinfachen. Bei diesem Ansatz wird davon ausgegangen, dass das ETL-Tool Azure Synapse als Zielumgebung unterstützt. Weitere Informationen zu Tools, die Azure Synapse unterstützen, finden Sie unter Partner für die Datenintegration.
Wenn Sie ein ETL-Tool verwenden, sollten Sie dieses Tool in der Azure-Umgebung ausführen, um von Leistung, Skalierbarkeit und Kosten der Azure-Cloud zu profitieren und Ressourcen im Teradata-Rechenzentrum freizugeben. Ein weiterer Vorteil ist eine geringere Datenverschiebung zwischen der Cloud und lokalen Umgebungen.
Zusammenfassung
Zusammengefasst lauten unsere Empfehlungen für die Migration von Daten und zugehörigen ETL-Prozessen von Teradata zu Azure Synapse wie folgt:
Planen Sie im Vorfeld, um eine erfolgreiche Migration zu gewährleisten.
Verschaffen Sie sich einen umfassenden Überblick über die Daten und Prozesse, die so schnell wie möglich migriert werden müssen.
Verschaffen Sie sich anhand von Systemmetadaten und Protokolldateien einen umfassenden Überblick über die Nutzung von Daten und Prozessen. Verlassen Sie sich nicht auf die Dokumentation, da sie möglicherweise veraltet ist.
Verschaffen Sie sich einen Überblick über die zu migrierenden Datenmengen und die Netzwerkbandbreite zwischen dem lokalen Rechenzentrum und Azure-Cloudumgebungen.
Erwägen Sie den Einsatz einer Teradata-Instanz in einer Azure-VM als Ausgangspunkt zum Auslagern der Migration aus der alten Teradata-Legacyumgebung.
Nutzen Sie standardmäßig „integrierte“ Azure-Features, um den Migrationsaufwand zu minimieren.
Informieren Sie sich über die effizientesten Tools zum Extrahieren und Laden von Daten in Teradata- und Azure-Umgebungen. Verwenden Sie in den einzelnen Phasen des Prozesses die jeweils geeigneten Tools.
Verwenden Sie Azure-Lösungen wie Azure Synapse-Pipelines oder Azure Data Factory, um den Migrationsprozess zu orchestrieren und zu automatisieren und gleichzeitig die Auswirkungen auf das Teradata-System zu minimieren.
Nächste Schritte
Weitere Informationen zu Sicherheit, Zugriff und Vorgängen finden Sie im nächsten Artikel in dieser Reihe: Sicherheit, Zugriff und Vorgänge für Teradata-Migrationen.