Dezentralisierung der Workflow-Logik und Verteilung der Verantwortlichkeiten auf andere Komponenten innerhalb eines Systems.
Kontext und Problem
Eine Cloud-basierte Anwendung ist oft in mehrere kleine Dienste unterteilt, die zusammenarbeiten, um einen Geschäftsvorgang durchgängig zu verarbeiten. Selbst ein einziger Vorgang (innerhalb einer Transaktion) kann zu mehreren Punkt-zu-Punkt-Aufrufen zwischen allen Diensten führen. Im Idealfall sollten diese Dienste lose gekoppelt sein. Es ist eine Herausforderung, einen verteilten, effizienten und skalierbaren Arbeitsablauf zu entwickeln, da er oft eine komplexe Kommunikation zwischen den Diensten beinhaltet.
Ein gängiges Muster für die Kommunikation ist die Verwendung eines zentralisierten Dienstes oder eines Orchestrators. Eingehende Anfragen fließen durch den Orchestrator, der Vorgänge an die jeweiligen Dienste delegiert. Jeder Dienst erledigt nur seine Aufgabe und ist sich des gesamten Arbeitsablaufs nicht bewusst.
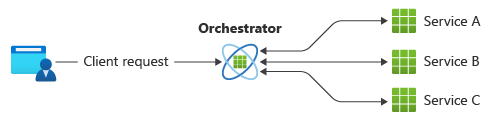
Das Orchestrator-Muster wird in der Regel als benutzerdefinierte Software implementiert und verfügt über Fachwissen über die Zuständigkeiten dieser Dienste. Ein Vorteil ist, dass der Orchestrator den Status einer Transaktion auf der Grundlage der Ergebnisse der einzelnen von den nachgelagerten Diensten durchgeführten Operationen konsolidieren kann.
Allerdings gibt es auch einige Nachteile. Das Hinzufügen oder Entfernen von Diensten kann zu einer Unterbrechung der bestehenden Logik führen, da Sie Teile des Kommunikationspfads neu verdrahten müssen. Diese Abhängigkeit macht die Orchestrator-Implementierung komplex und schwer zu pflegen. Der Orchestrator kann sich negativ auf die Zuverlässigkeit des Workloads auswirken. Unter Last kann es zu Leistungsengpässen kommen und zum Single Point of Failure werden. Außerdem kann es zu kaskadenartigen Ausfällen bei den nachgelagerten Diensten kommen.
Lösung
Delegieren Sie die Logik der Transaktionsverarbeitung an die Dienste. Lassen Sie jeden Dienst über den Kommunikations-Workflow für einen Geschäftsvorgang entscheiden und sich daran beteiligen.
Das Muster ist eine Möglichkeit, die Abhängigkeit von kundenspezifischer Software zu minimieren, indem der Kommunikationsworkflow zentralisiert wird. Die Komponenten implementieren eine gemeinsame Logik, da sie den Arbeitsablauf untereinander choreographieren, ohne direkt miteinander zu kommunizieren.
Eine gängige Methode zur Implementierung der Choreografie ist die Verwendung eines Nachrichtenmaklers, der Anfragen puffert, bis nachgelagerte Komponenten sie anfordern und verarbeiten. Die Abbildung zeigt die Bearbeitung von Anfragen durch ein Publisher-Subscriber-Modell.
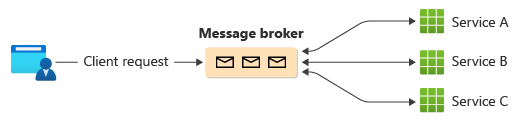
Die Anfragen eines Kunden werden in einem Message Broker als Nachrichten in eine Warteschlange gestellt.
Die Dienste oder der Abonnent fragen den Broker ab, um festzustellen, ob sie diese Nachricht auf der Grundlage ihrer implementierten Geschäftslogik verarbeiten können. Der Broker kann auch Nachrichten an Abonnenten weiterleiten, die an dieser Nachricht interessiert sind.
Jeder abonnierte Dienst führt die in der Nachricht angegebene Operation aus und antwortet dem Makler mit Erfolg oder Misserfolg der Operation.
Bei Erfolg kann der Dienst eine Nachricht zurück in dieselbe oder eine andere Nachrichtenwarteschlange schieben, so dass ein anderer Dienst den Arbeitsablauf bei Bedarf fortsetzen kann. Schlägt der Vorgang fehl, arbeitet der Message Broker mit anderen Diensten zusammen, um diesen Vorgang oder die gesamte Transaktion zu kompensieren.
Probleme und Überlegungen
Das Dezentralisieren des Orchestrators kann beim Verwalten des Workflows Probleme verursachen.
Die Übergabe von Fehlern kann eine Herausforderung sein. Die Komponenten einer Anwendung können atomare Aufgaben ausführen, aber sie können dennoch eine gewisse Abhängigkeit aufweisen. Der Ausfall einer Komponente kann sich auf andere Komponenten auswirken, was zu Verzögerungen bei der Fertigstellung des gesamten Auftrags führen kann.
Die Implementierung von mit kompensierenden Transaktionen kann zu einer komplizierten Handhabung von Fehlern führen.
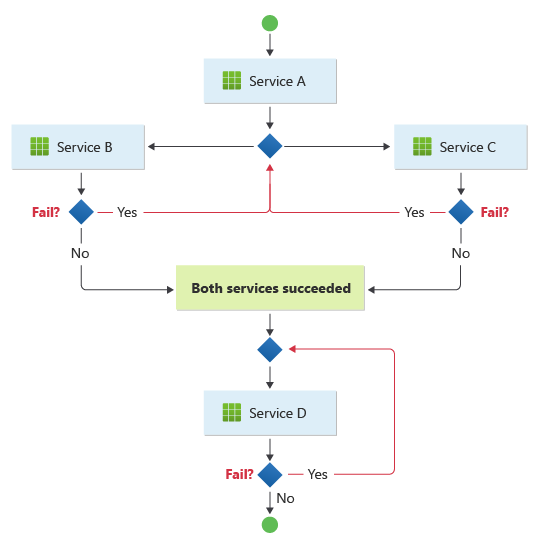
Das Muster eignet sich für einen Workflow, bei dem unabhängige Geschäftsvorgänge parallel verarbeitet werden. Der Arbeitsablauf kann kompliziert werden, wenn die Choreografie in einer Abfolge stattfinden muss. So kann beispielsweise der Dienst D seinen Betrieb erst dann aufnehmen, wenn die Dienste B und C ihren Betrieb erfolgreich abgeschlossen haben.
Das Muster wird zu einer Herausforderung, wenn die Zahl der Dienste schnell wächst. Aufgrund der hohen Anzahl unabhängiger, beweglicher Teile wird der Workflow zwischen Diensten tendenziell komplex. Außerdem wird die verteilte Ablaufverfolgung schwierig.
In einem von einem Orchestrator geleiteten Design kann die zentrale Komponente teilweise teilnehmen und die Ausfallsicherheitslogik an eine andere Komponente delegieren, die transiente, nicht-transiente und Timeout-Fehler konsequent wiederholt. Mit der Auflösung des Orchestrators im Choreografiemuster sollten die nachgelagerten Komponenten diese Resilienzaufgaben nicht übernehmen. Diese müssen nach wie vor vom Resiliency Handler behandelt werden. Nun müssen die nachgelagerten Komponenten aber direkt mit dem Resiliency Handler kommunizieren, was die Punkt-zu-Punkt-Kommunikation erhöht.
Verwendung dieses Musters
Verwenden Sie dieses Muster in folgenden Fällen:
Die nachgelagerten Komponenten behandeln atomare Operationen unabhängig voneinander. Betrachten Sie es als einen „Fire-and-Forget“-Mechanismus. Eine Komponente ist für eine Aufgabe zuständig, die nicht aktiv verwaltet werden muss. Wenn die Aufgabe abgeschlossen ist, sendet sie eine Benachrichtigung an die anderen Komponenten.
Es ist zu erwarten, dass die Komponenten häufig aktualisiert und ersetzt werden. Das Muster ermöglicht es, die Anwendung mit weniger Aufwand und minimaler Unterbrechung der bestehenden Dienste zu ändern.
Das Muster eignet sich hervorragend für serverlose Architekturen, die für einfache Arbeitsabläufe geeignet sind. Die Komponenten können kurzlebig und ereignisgesteuert sein. Wenn ein Ereignis eintritt, werden die Komponenten in Gang gesetzt, führen ihre Aufgaben aus und werden wieder entfernt, sobald die Aufgabe abgeschlossen ist.
Es gibt einen Leistungsengpass, der durch den zentralen Orchestrator verursacht wird.
Dieses Muster ist in folgenden Fällen möglicherweise nicht geeignet:
Die Anwendung ist komplex und erfordert eine zentrale Komponente, die die gemeinsame Logik handhabt, um die nachgeschalteten Komponenten schlank zu halten.
Es gibt Situationen, in denen eine Punkt-zu-Punkt-Kommunikation zwischen den Komponenten unumgänglich ist.
Sie müssen alle Vorgänge, die von nachgelagerten Komponenten abgewickelt werden, mit Hilfe von Geschäftslogik konsolidieren.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Choreographie-Muster im Design seiner Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Azure Well-Architected Framework-Säulen behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Operational Excellence unterstützt die Workloadqualität durch standardisierte Prozesse und Teamzusammenhalt. | Da die verteilten Komponenten in diesem Muster autonom und austauschbar sind, können Sie die Workload mit weniger Gesamtänderungen am System ändern. - OE:04 Tools und Prozesse |
| Die Leistungseffizienz hilft Ihrer Workload, Anforderungen effizient durch Optimierungen in Skalierung, Daten und Code zu erfüllen. | Dieses Muster bietet eine Alternative, wenn Leistungsengpässe in einer zentralisierten Orchestrierungstopologie auftreten. - PE:02 Kapazitätsplanung - PE:05 Skalierung und Partitionierung |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
Dieses Beispiel zeigt das Choreographiemuster, indem eine ereignisgesteuerte, cloudnative Workload erstellt wird, die Funktionen zusammen mit Microservices ausführt. Wenn ein Kunde ein Paket zum Versand anfordert, weist die Workload eine Drohne zu. Sobald das Paket für die Abholung durch die geplante Drohne bereit ist, wird der Lieferprozess gestartet. Die Workload verarbeitet die Lieferung während des Transports, bis sie den Status „Versendet“ erhält.
Dieses Beispiel ist eine Umgestaltung der Drone Delivery-Implementierung, die das Orchestratormuster durch das Choreographiemuster ersetzt.
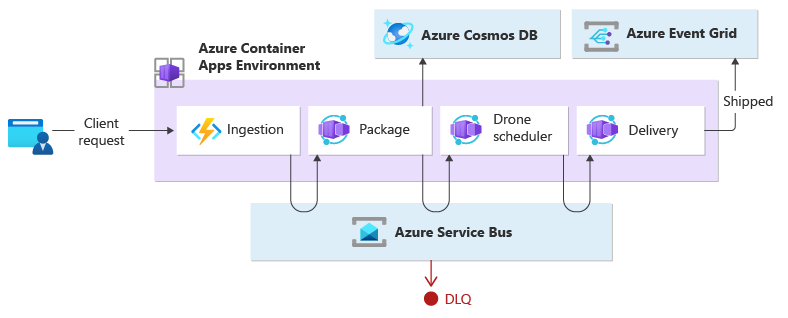
Der Ingestion-Dienst bearbeitet Client-Anfragen und wandelt sie in Nachrichten um, die auch die Zustellungsdaten enthalten. Geschäftstransaktionen werden nach dem Verbrauch dieser neuen Nachrichten initiiert.
Ein einziger Geschäftsvorgang eines Kunden erfordert drei verschiedene Geschäftsvorgänge:
- Erstellen oder Aktualisieren eines Pakets
- Beauftragen Sie eine Drohne mit der Zustellung des Pakets
- Erledigen Sie die Zustellung, die aus der Überprüfung und eventuellen Sensibilisierung bei der Auslieferung besteht.
Drei Microservices führen die Geschäftsabwicklung durch: die Dienste Package, Drone Scheduler und Delivery. Anstelle eines zentralen Orchestrators kommunizieren die Dienste untereinander über Messaging. Jeder Dienst wäre dafür verantwortlich, im Voraus ein Protokoll zu implementieren, das den Geschäftsworkflow dezentral koordiniert.
Design
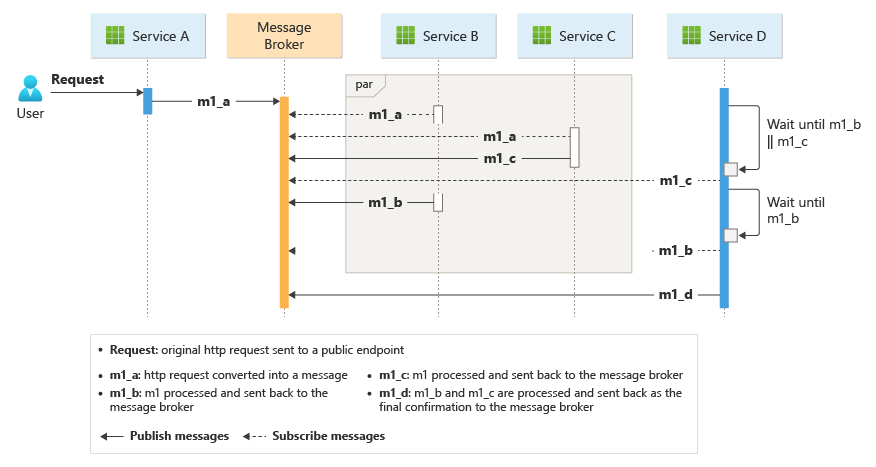
Die Geschäftstransaktion wird in einer Sequenz über mehrere Hops verarbeitet. Die verschiedenen Hops nutzen einen einzelnen Nachrichtenbus gemeinsam für alle Geschäftsdienste.
Wenn ein Client eine Übermittlungsanforderung über einen HTTP-Endpunkt sendet, empfängt der Ingestion-Dienst diese Anforderung, konvertiert sie in eine Nachricht und veröffentlicht die Nachricht dann im freigegebenen Nachrichtenbus. Die abonnierten Geschäftsdienste werden neue Nachrichten nutzen, die dem Bus hinzugefügt wurden. Wenn die Nachricht empfangen wird, können die Unternehmensdienste den Vorgang mit Erfolg oder Fehler beenden, oder für die Anforderung kann ein Timeout auftreten. Bei erfolgreicher Ausführung antworten die Dienste auf den Bus mit dem Statuscode „OK“, lösen eine neue Vorgangsnachricht aus und senden sie an den Nachrichtenbus. Wenn ein Ausfall oder eine Zeitüberschreitung auftritt, meldet der Dienst den Ausfall, indem er den Ursachencode an den Nachrichtenbus sendet. Außerdem wird die Nachricht in eine Warteschlange für unzustellbare Briefe aufgenommen. Nachrichten, die innerhalb einer entsprechenden und angemessenen Zeitspanne nicht empfangen oder verarbeitet werden konnten, werden auch in die Warteschlange für unzustellbare Nachrichten verschoben.
Beim Entwurf werden mehrere Nachrichtenbusse verwendet, um die gesamte Geschäftstransaktion zu verarbeiten. Microsoft Azure Service Bus und Microsoft Azure Event Grid wurden zusammengestellt, um die Messagingdienstplattform für dieses Design bereitzustellen. Die Workload wird auf Azure Container Apps bereitgestellt, die Azure-Funktionen für Ingestion hosten, und auf Apps, die ereignisgesteuerte Verarbeitung nutzen, die die Geschäftslogik ausführt.
Das Design sorgt dafür, dass die Choreographie in einer Sequenz stattfindet. Ein einzelner Azure Service Bus-Namespace enthält ein Thema mit zwei Abonnements und einer sitzungsabhängigen Warteschlange. Der Ingestion-Dienst veröffentlicht Nachrichten im Thema. Die Dienste Package und Drone Scheduler abonnieren das Thema und veröffentlichen Nachrichten, die den Erfolg an die Warteschlange kommunizieren. Das Einbeziehen eines allgemeinen Sitzungsbezeichners, der einer GUID zugeordnet ist, ermöglicht die geordnete Verarbeitung unbegrenzter Sequenzen verwandter Nachrichten. Der Delivery-Dienst wartet auf zwei verwandte Nachrichten pro Transaktion. Die erste Nachricht zeigt an, dass das Paket zugestellt werden kann, und die zweite signalisiert, dass eine Drohne geplant ist.
Dieses Design verwendet Azure Service Bus, um hochwertige Nachrichten zu verarbeiten, die während des gesamten Zustellprozesses nicht verloren gehen oder dupliziert werden dürfen. Wenn das Paket zugestellt ist, wird auch die Änderung des Status in Azure Event Grid veröffentlicht. In diesem Design hat der Absender des Ereignisses keine Erwartung daran, wie die Statusänderung verarbeitet wird. Nachgelagerte Organisationsdienste, die nicht Teil dieses Entwurfs sind, könnten diesen Ereignistyp abhören und darauf reagieren, indem sie eine bestimmte Geschäftszwecklogik ausführen (z. B. den Status der versendeten Bestellung per E-Mail an den Benutzer senden).
Wenn Sie dies in einem anderen Computedienst bereitstellen möchten, z. B. AKS, könnte der Anwendungsbaustein Pub/Sub-Muster mit zwei Containern im selben Pod implementiert werden. Ein Container führt Ambassador aus, der mit Ihrem bevorzugten Nachrichtenbus interagiert, während der andere die Geschäftslogik ausführt. Der Ansatz mit zwei Containern im gleichen Pod verbessert die Leistung und Skalierbarkeit. Der Botschafter und der Unternehmensdienst nutzen dasselbe Netzwerk, was eine geringe Latenz und einen hohen Durchsatz ermöglicht.
Um kaskadierende Wiederholungsvorgänge zu vermeiden, die zu mehrfachem Aufwand führen könnten, sollten Geschäftsdienste inakzeptable Nachrichten sofort melden. Solchen Nachrichten können bekannte Ursachencodes oder definierte Anwendungscodes angehängt werden, sodass sie in eine Warteschlange für unzustellbare Nachrichten verschoben werden können. Denken Sie über die Verwaltung von Konsistenzproblemen durch Implementieren von Saga aus nachgeschalteten Diensten nach. Beispielsweise kann ein anderer Dienst unzustellbare Nachrichten nur für Wartungszwecke verarbeiten, indem eine Entschädigung, eine Wiederholung oder eine Pivot-Transaktion ausgeführt wird.
Die Unternehmensdienste sind idempotent, um sicherzustellen, dass Wiederholungsvorgänge nicht zu doppelten Ressourcen führen. Beispielsweise verwendet der Package-Dienst Upsertvorgänge, um dem Datenspeicher Daten hinzuzufügen.
Zugehörige Ressourcen
Beachten Sie diese Muster in Ihrem Entwurf für die Choreographie.
Modularisieren Sie den Unternehmensdienst mithilfe des Botschafterentwurfsmusters.
Implementieren Sie ein warteschlangenbasiertes Lastenausgleichsmuster, um Spitzen der Arbeitsauslastung zu bewältigen.
Verwenden Sie asynchrones verteiltes Messaging über das Herausgeber-Abonnent-Muster.
Verwenden Sie kompensierende Transaktionen, um eine Reihe erfolgreicher Vorgänge rückgängig zu machen, falls bei einem oder mehreren verwandten Vorgängen Fehler auftreten.
Informationen zum Verwenden eines Nachrichtenbrokers in einer Messaginginfrastruktur finden Sie unter Asynchrone Messagingoptionen in Azure.