Entwerfen, um Fehler zu überleben (Erstellen Real-World Cloud-Apps mit Azure)
von Rick Anderson, Tom Dykstra
Download Fix It Project oder E-Book herunterladen
Das E-Book Building Real World Cloud Apps with Azure basiert auf einer Präsentation, die von Scott Guthrie entwickelt wurde. Es werden 13 Muster und Methoden erläutert, die Ihnen helfen können, Web-Apps für die Cloud erfolgreich zu entwickeln. Informationen zum E-Book finden Sie im ersten Kapitel.
Eines der Dinge, über die Sie beim Erstellen eines beliebigen Anwendungstyps nachdenken müssen, aber vor allem eines, das in der Cloud ausgeführt wird, wo viele Benutzer sie verwenden werden, ist das Entwerfen der App, sodass sie Fehler ordnungsgemäß behandeln und weiterhin so viel Wie möglich nutzen kann. Mit genügend Zeit werden in jeder Umgebung oder jedem Softwaresystem Einiges schief gehen. Wie Ihre App mit diesen Situationen umgeht, bestimmt, wie ihre Kunden verärgert werden und wie viel Zeit Sie zum Analysieren und Beheben von Problemen aufwenden müssen.
Fehlertypen
Es gibt zwei grundlegende Kategorien von Fehlern, die Sie unterschiedlich behandeln sollten:
- Vorübergehende Selbstheilungsfehler, z. B. zeitweilige Probleme mit der Netzwerkkonnektivität.
- Dauerhafte Fehler, die ein Eingreifen erfordern.
Bei vorübergehenden Fehlern können Sie eine Wiederholungsrichtlinie implementieren, um sicherzustellen, dass die App die meiste Zeit schnell und automatisch wiederhergestellt wird. Ihre Kunden bemerken möglicherweise eine etwas längere Reaktionszeit, andernfalls sind sie nicht betroffen. Im Kapitel Behandlung vorübergehender Fehler werden einige Möglichkeiten zum Behandeln dieser Fehler erläutert.
Bei dauerhaften Fehlern können Sie Überwachungs- und Protokollierungsfunktionen implementieren, die Sie umgehend benachrichtigt, wenn Probleme auftreten, und die die Analyse der Grundursachen erleichtern. Im Kapitel Überwachung und Telemetrie werden einige Möglichkeiten gezeigt, mit denen Sie diese Art von Fehlern auf dem Neuesten Erhalten können.
Fehlerbereich
Sie müssen auch über den Fehlerbereich nachdenken – unabhängig davon, ob ein einzelner Computer betroffen ist, ein ganzer Dienst wie SQL-Datenbank oder Speicher oder eine ganze Region.

Computerfehler
In Azure wird ein ausgefallener Server automatisch durch einen neuen ersetzt, und eine gut konzipierte Cloud-App wird automatisch und schnell nach dieser Art von Ausfall wiederhergestellt. Zuvor haben wir die Skalierbarkeitsvorteile einer zustandslosen Webebene hervorgehoben, und die einfache Wiederherstellung von einem ausgefallenen Server ist ein weiterer Vorteil der Zustandslosigkeit. Die einfache Wiederherstellung ist auch einer der Vorteile von PaaS-Features (Platform-as-a-Service), z. B. SQL-Datenbank und Azure App Service Web-Apps. Hardwarefehler sind selten, aber wenn sie auftreten, behandeln diese Dienste sie automatisch. Sie müssen nicht einmal Code schreiben, um Computerfehler zu behandeln, wenn Sie einen dieser Dienste verwenden.
Dienstfehler
Cloud-Apps verwenden in der Regel mehrere Dienste. Beispielsweise verwendet die Fix It-App den SQL-Datenbank-Dienst, den Speicherdienst, und die Web-App wird für Azure App Service bereitgestellt. Was macht Ihre App, wenn einer der Dienste, auf die Sie angewiesen sind, ausfällt? Bei einigen Dienstfehlern ist möglicherweise die freundliche Meldung "Sorry, versuchen Sie es später noch mal" die beste, die Sie tun können. Aber in vielen Szenarien können Sie es besser machen. Wenn Ihr Back-End-Datenspeicher beispielsweise ausgefallen ist, können Sie Benutzereingaben akzeptieren, "Ihre Anforderung wurde empfangen" anzeigen und die Eingabe an einem anderen Ort vorübergehend speichern. Wenn der von Ihnen benötigte Dienst dann wieder betriebsbereit ist, können Sie die Eingabe abrufen und verarbeiten.
Das Kapitel Warteschlangenorientiertes Arbeitsmuster zeigt eine Möglichkeit, dieses Szenario zu behandeln. Die Fix It-App speichert Aufgaben in SQL-Datenbank, muss jedoch nicht aufhören, zu arbeiten, wenn SQL-Datenbank ausgefallen ist. In diesem Kapitel erfahren Sie, wie Sie Benutzereingaben für eine Aufgabe in einer Warteschlange speichern und einen Workerprozess verwenden, um die Warteschlange zu lesen und die Aufgabe zu aktualisieren. Wenn SQL ausgefallen ist, ist die Möglichkeit, Fix It-Aufgaben zu erstellen, nicht betroffen. der Workerprozess kann warten und neue Aufgaben verarbeiten, wenn SQL-Datenbank verfügbar ist.
Regionsfehler
Ganze Regionen können fehlschlagen. Eine Naturkatastrophe kann ein Rechenzentrum zerstören, es könnte von einem Meteor abgeflacht werden, die Stammleitung in das Rechenzentrum könnte von einem Landwirt geschnitten werden, der eine Kuh mit einem Bagger begräbt usw. Was tun Sie, wenn Ihre App im betroffenen Rechenzentrum gehostet wird? Es ist möglich, Ihre App in Azure so einzurichten, dass sie in mehreren Regionen gleichzeitig ausgeführt wird, sodass Sie im Fall eines Notfalls in einer anderen Region weiter ausführen. Solche Fehler treten äußerst selten auf, und die meisten Apps springen nicht durch die Erforderlichen, um einen unterbrechungsfreien Dienst durch Solche Fehler zu gewährleisten. Im Abschnitt Ressourcen am Ende des Kapitels finden Sie Informationen dazu, wie Sie Ihre App auch bei einem Regionsfehler verfügbar halten.
Ein Ziel von Azure ist es, die Behandlung all dieser Arten von Fehlern erheblich zu vereinfachen. In den folgenden Kapiteln finden Sie einige Beispiele dafür.
SLAs
Personen häufig von Vereinbarungen zum Servicelevel (SLAs) in der Cloudumgebung hören. Im Grunde sind dies Versprechen, die Unternehmen machen, wie zuverlässig ihr Service ist. Eine SLA von 99,9 % bedeutet, dass Sie erwarten sollten, dass der Dienst in 99,9 % der Zeit ordnungsgemäß funktioniert. Dies ist ein recht typischer Wert für eine SLA und klingt nach einer sehr hohen Zahl, aber Sie wissen möglicherweise nicht, wie viel Ausfallzeit .1% tatsächlich beträgt. Hier sehen Sie eine Tabelle, die zeigt, wie viele Ausfallzeiten verschiedene SLA-Prozentsätze über ein Jahr, einen Monat und eine Woche betragen.
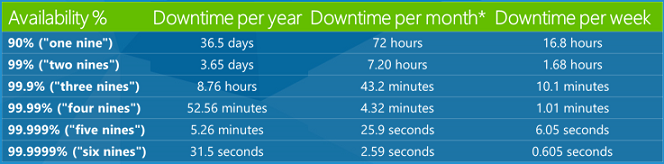
Eine SLA von 99,9 % bedeutet also, dass Ihr Dienst 8,76 Stunden pro Jahr oder 43,2 Minuten pro Monat ausfallen kann. Das ist mehr Ausfallzeiten, als die meisten Menschen erkennen. Als Entwickler möchten Sie sich also bewusst sein, dass eine bestimmte Anzahl von Ausfallzeiten möglich ist, und sie in einer anmutigen Weise behandeln. Irgendwann wird jemand Ihre App verwenden, und ein Dienst wird ausfallen, und Sie möchten die negativen Auswirkungen auf den Kunden minimieren.
Eine Sache, die Sie über eine SLA wissen sollten, ist, auf welchen Zeitrahmen sie sich bezieht: Wird die Uhr jede Woche, jeden Monat oder jedes Jahr zurückgesetzt? In Azure setzen wir die Uhr jeden Monat zurück, was für Sie besser ist als eine jährliche SLA, da eine jährliche SLA schlechte Monate ausblenden könnte, indem sie sie mit einer Reihe von guten Monaten ausgleichen.
Natürlich streben wir immer danach, besser zu sein als die SLA; normalerweise werden Sie viel weniger ausfallen. Das Versprechen ist: Wenn wir jemals länger als die maximale Ausfallzeit ausfallen, können Sie Geld zurückfordern. Der Betrag, den Sie zurückbekommen, würde Sie wahrscheinlich nicht vollständig für die geschäftlichen Auswirkungen der übermäßigen Ausfallzeiten entschädigen, aber dieser Aspekt der SLA fungiert als Durchsetzungsrichtlinie und lässt Sie wissen, dass wir es sehr ernst nehmen.
Zusammengesetzte SLAs
Eine wichtige Sache, die Sie beachten sollten, wenn Sie slAs betrachten, ist die Auswirkung der Verwendung mehrerer Dienste in einer App, wobei jeder Dienst eine separate SLA aufweist. Die Fix It-App verwendet beispielsweise Azure App Service Web-Apps, Azure Storage und SQL-Datenbank. Hier sind die SLA-Zahlen ab dem Datum, an dem dieses E-Book im Dezember 2013 geschrieben wird:
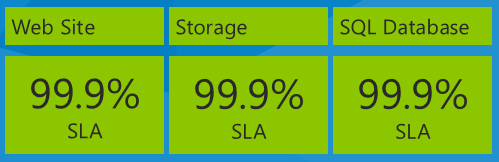
Was ist die maximale Ausfallzeit, die Sie basierend auf diesen Dienst-SLAs für die App erwarten würden? Sie könnten denken, dass Ihre Ausfallzeit dem schlechtesten SLA-Prozentsatz oder 99,9 % in diesem Fall entspricht. Das wäre richtig, wenn alle drei Dienste immer zur gleichen Zeit ausfallen, aber das ist nicht unbedingt das, was tatsächlich geschieht. Jeder Dienst kann zu unterschiedlichen Zeiten unabhängig ausfallen, sodass Sie die zusammengesetzte SLA berechnen müssen, indem Sie die einzelnen SLA-Zahlen multiplizieren.
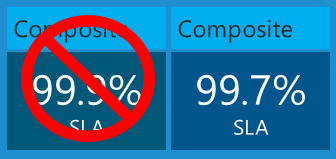
Ihre App kann also nicht nur 43,2 Minuten pro Monat, sondern das 3-Fache dieses Betrags sein, 108 Minuten pro Monat – und sich immer noch innerhalb der Azure-SLA-Grenzwerte befinden.
Dieses Problem ist nicht für Azure eindeutig. Wir bieten tatsächlich die besten Cloud-SLAs aller verfügbaren Clouddienste, und Sie haben ähnliche Probleme, wenn Sie die Clouddienste eines beliebigen Anbieters verwenden. Dies unterstreicht, wie wichtig es ist, darüber nachzudenken, wie Sie Ihre App entwerfen können, um die unvermeidlichen Dienstausfälle ordnungsgemäß zu behandeln, da sie häufig genug auftreten können, um Ihre Kunden oder Benutzer zu beeinträchtigen.
Cloud-SLAs im Vergleich zu betriebsbedingten Ausfallzeiten
Personen sagen manchmal: "In meiner Unternehmens-App habe ich diese Probleme nie." Wenn Sie fragen, wie viel Ausfallzeit pro Monat sie tatsächlich haben, sagen sie normalerweise: "Nun, es kommt gelegentlich vor." Und wenn Sie fragen, wie oft, geben sie zu: "Manchmal müssen wir einen neuen Server sichern oder installieren oder Software aktualisieren." Das gilt natürlich als Ausfallzeit. Die meisten Unternehmens-Apps, sofern sie nicht besonders unternehmenskritisch sind, sind tatsächlich länger als die von unseren Dienst-SLAs zulässige Zeit ausgefallen. Aber wenn es sich um Ihren Server und Ihre Infrastruktur handelt und Sie dafür verantwortlich sind und die Kontrolle darüber haben, neigen Sie dazu, weniger Angst vor Ausfallzeiten zu verspüren. In einer Cloudumgebung sind Sie von einer anderen Person abhängig und wissen nicht, was los ist, sodass Sie sich möglicherweise mehr Sorgen machen.
Wenn ein Unternehmen einen höheren Prozentsatz für die Betriebszeit erreicht als bei einer Cloud-SLA, gibt es viel mehr Geld für Hardware aus. Ein Clouddienst könnte dies tun, müsste aber viel mehr für seine Dienste in Rechnung stellen. Stattdessen nutzen Sie einen kostengünstigen Service und entwerfen Ihre Software so, dass die unvermeidlichen Fehler für Ihre Kunden minimale Störungen verursachen. Ihre Aufgabe als Cloud-App-Designer besteht nicht so sehr darin, Fehler zu vermeiden, als eine Katastrophe zu vermeiden, und Sie tun dies, indem Sie sich auf Software und nicht auf Hardware konzentrieren. Während Unternehmens-Apps versuchen, die mittlere Zeit zwischen Fehlern zu maximieren, versuchen Cloud-Apps, die mittlere Wiederherstellungszeit zu minimieren.
Nicht alle Clouddienste verfügen über SLAs
Beachten Sie auch, dass nicht jeder Clouddienst über eine SLA verfügt. Wenn Ihre App von einem Dienst ohne Betriebszeitgarantie abhängig ist, können Sie viel länger ausfallen, als Sie sich vielleicht vorstellen. Wenn Sie beispielsweise die Anmeldung bei Ihrer Website mit einem sozialen Anbieter wie Facebook oder Twitter aktivieren, wenden Sie sich an den Dienstanbieter, um herauszufinden, ob es eine SLA gibt, und Sie können feststellen, dass es keine gibt. Wenn der Authentifizierungsdienst jedoch ausfällt oder die Menge der Anforderungen, die Sie an ihn senden, nicht unterstützen kann, werden Ihre Kunden von Ihrer App ausgeschlossen. Sie können tage- oder länger ausfallen. Die Ersteller einer neuen App erwarteten Hunderte millionen Downloads und nahmen eine Abhängigkeit von der Facebook-Authentifizierung ein – sprachen aber nicht mit Facebook, bevor sie live gingen und entdeckten zu spät, dass es keine SLA für diesen Dienst gab.
Nicht alle Ausfallzeiten zählen für SLAs
Einige Clouddienste können den Dienst absichtlich verweigern, wenn Ihre App sie übermäßig verwendet. Dies wird als Drosselung bezeichnet. Wenn ein Dienst über eine SLA verfügt, sollten die Bedingungen angegeben werden, unter denen Sie möglicherweise gedrosselt werden, und Ihr App-Entwurf sollte diese Bedingungen vermeiden und entsprechend auf die Drosselung reagieren, falls dies geschieht. Wenn beispielsweise Anforderungen an einen Dienst starten fehlschlagen, wenn Sie eine bestimmte Anzahl pro Sekunde überschreiten, sollten Sie sicherstellen, dass automatische Wiederholungen nicht so schnell erfolgen, dass die Drosselung fortgesetzt wird. Weitere Informationen zur Drosselung finden Sie im Kapitel Behandlung vorübergehender Fehler.
Zusammenfassung
Dieses Kapitel hat versucht, Ihnen zu helfen, zu erkennen, warum eine echte Cloud-App entwickelt werden muss, um Fehler problemlos zu überstehen. Ab dem nächsten Kapitel werden die restlichen Muster in dieser Reihe ausführlicher zu einigen Strategien erläutert, die Sie dazu verwenden können:
- Verfügen Sie über eine gute Überwachung und Telemetrie, damit Sie schnell über Fehler erfahren, die ein Eingreifen erfordern, und Sie über ausreichende Informationen verfügen, um sie zu beheben.
- Behandeln Sie vorübergehende Fehler, indem Sie eine intelligente Wiederholungslogik implementieren, sodass Ihre App automatisch wiederhergestellt wird, wenn dies möglich ist, und wenn dies nicht der Fall ist.
- Verwenden Sie verteiltes Zwischenspeichern , um Durchsatz, Latenz und Verbindungsprobleme beim Datenbankzugriff zu minimieren.
- Implementieren Sie eine lose Kopplung über das warteschlangenorientierte Arbeitsmuster, damit Ihr App-Front-End weiterhin funktioniert, wenn das Back-End ausgefallen ist.
Ressourcen
Weitere Informationen finden Sie in den späteren Kapiteln in diesem E-Book und in den folgenden Ressourcen.
Dokumentation:
- Failsafe: Leitfaden für resiliente Cloudarchitekturen. Whitepaper von Marc Mercuri, Ulrich Homann und Andrew Townhill. Webseitenversion der FailSafe-Videoreihe.
- Bewährte Methoden für den Entwurf von Large-Scale Services in Azure Cloud Services. Whitepaper von Mark Simms und Michael Thomassy.
- Technische Anleitung für Azure Business Continuity. Whitepaper von Patrick Wickline und Jason Roth.
- Notfallwiederherstellung und Hochverfügbarkeit für Azure-Anwendungen. Whitepaper von Michael McKeown, Hanu Kommalapati und Jason Roth.
- Microsoft-Muster und -Methoden: Azure-Leitfaden. Weitere Informationen finden Sie unter Bereitstellungsleitfaden für mehrere Rechenzentren, Leitungsschaltermuster.
- Azure-Support: Vereinbarungen zum Servicelevel.
- Geschäftskontinuität in Azure SQL Datenbank. Dokumentation zu SQL-Datenbank Hochverfügbarkeits- und Notfallwiederherstellungsfeatures.
- Hochverfügbarkeit und Notfallwiederherstellung für SQL Server in Azure Virtual Machines.
Videos:
- FailSafe: Erstellen skalierbarer, resilienter Cloud Services. Neunteilige Serie von Ulrich Homann, Marc Mercuri und Mark Simms. Präsentiert hochrangige Konzepte und Architekturprinzipien auf sehr zugängliche und interessante Weise mit Geschichten, die aus der Erfahrung des Microsoft Customer Advisory Teams (CAT) mit tatsächlichen Kunden stammen. Die Episoden 1 und 8 gehen ausführlich auf die Gründe für das Entwerfen von Cloud-Apps ein, um Fehler zu überleben. Siehe auch die Nachbesprechung der Drosselung in Folge 2 ab 49:57 Uhr, die Diskussion über Fehlerpunkte und Fehlermodi in Folge 2 ab 56:05 Uhr und die Diskussion der Leistungsschalter in Folge 3 ab 40:55 Uhr.
- Building Big: Erfahrungen von Azure-Kunden – Teil II. Mark Simms spricht über das Entwerfen von Fehlern und instrumentieren alles. Ähnlich wie die Failsafe-Serie, geht aber in weitere Details ein.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für