Überwachung und Telemetrie (Erstellen Real-World Cloud-Apps mit Azure)
von Rick Anderson, Tom Dykstra
Download Fix It Project oder E-Book herunterladen
Das E-Book Building Real World Cloud Apps with Azure basiert auf einer Präsentation, die von Scott Guthrie entwickelt wurde. Es werden 13 Muster und Methoden erläutert, die Ihnen helfen können, Web-Apps für die Cloud erfolgreich zu entwickeln. Informationen zum E-Book finden Sie im ersten Kapitel.
Viele Menschen verlassen sich darauf, dass Kunden sie darüber informieren, wenn ihre Anwendung ausgefallen ist. Dies ist nicht wirklich eine bewährte Methode, und zwar nicht in der Cloud. Es gibt keine Garantie für schnelle Benachrichtigungen, und wenn Sie benachrichtigt werden, erhalten Sie oft minimale oder irreführende Daten über das Geschehen. Mit guten Telemetrie- und Protokollierungssystemen können Sie wissen, was mit Ihrer App vor sich geht, und wenn etwas schief geht, finden Sie es sofort heraus und haben hilfreiche Informationen zur Problembehandlung.
Kaufen oder Mieten einer Telemetrielösung
Hinweis
Dieser Artikel wurde geschrieben, bevor Application Insights veröffentlicht wurde. Application Insights ist der bevorzugte Ansatz für Telemetrielösungen in Azure. Weitere Informationen finden Sie unter Einrichten von Application Insights für Ihre ASP.NET Website .
Eines der Dinge, die an der Cloudumgebung großartig sind, ist, dass es wirklich einfach ist, ihren Weg zum Sieg zu kaufen oder zu mieten. Telemetrie ist ein Beispiel. Ohne viel Aufwand können Sie ein wirklich gutes Telemetriesystem sehr kostengünstig in Betrieb nehmen. Es gibt eine Reihe großartiger Partner, die in Azure integriert werden, und einige von ihnen verfügen über kostenlose Tarife , sodass Sie grundlegende Telemetriedaten umsonst erhalten können. Hier sind nur einige der derzeit in Azure verfügbaren:
Microsoft System Center umfasst auch Überwachungsfeatures.
Wir gehen schnell durch die Einrichtung von New Relic, um zu zeigen, wie einfach es sein kann, ein Telemetriesystem zu verwenden.
Registrieren Sie sich im Azure-Verwaltungsportal für den Dienst. Klicken Sie auf Neu, und klicken Sie dann auf Speichern. Das Dialogfeld Add-On auswählen wird angezeigt. Scrollen Sie nach unten, und klicken Sie auf Neues Relikt.

Klicken Sie auf den Pfeil nach rechts, und wählen Sie die gewünschte Dienstebene aus. Für diese Demo verwenden wir den kostenlosen Tarif.
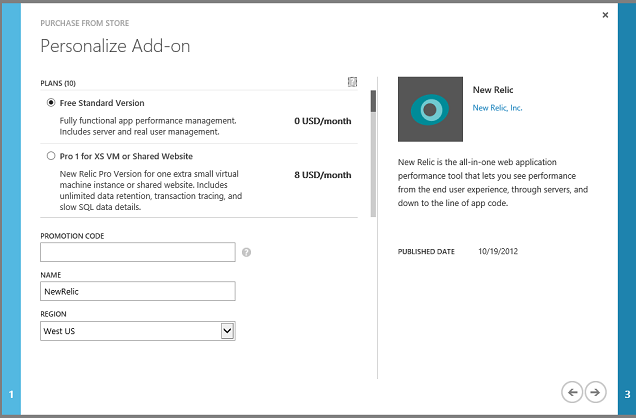
Klicken Sie auf den Pfeil nach rechts, bestätigen Sie den "Kauf", und New Relic wird jetzt als Add-On im Portal angezeigt.
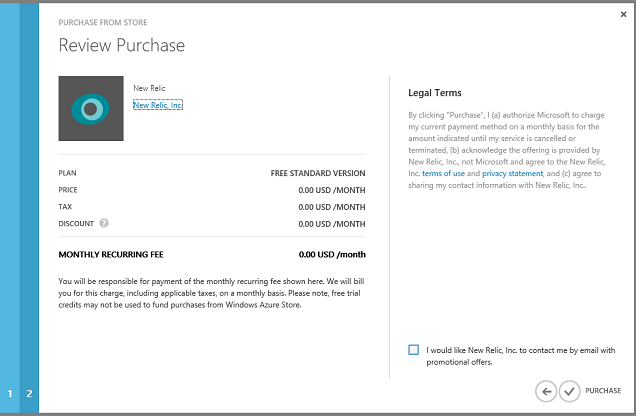
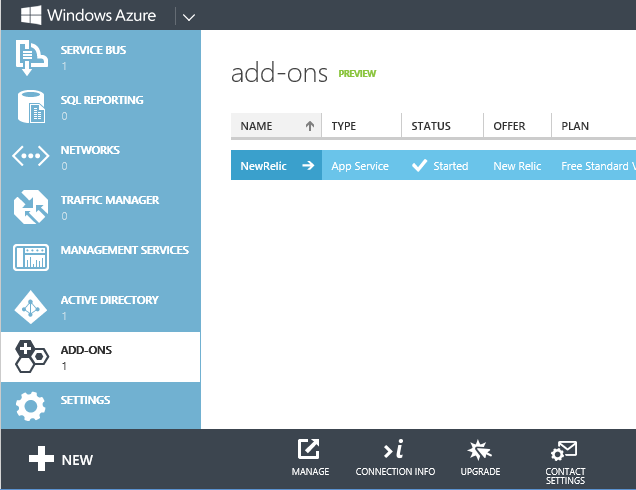
Klicken Sie auf Verbindungsinformationen, und kopieren Sie den Lizenzschlüssel.
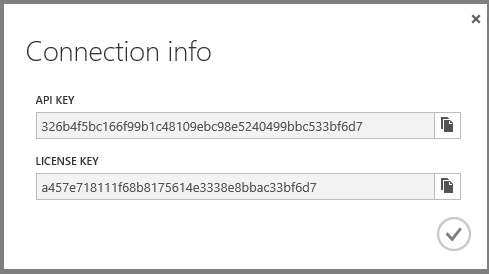
Wechseln Sie im Portal zur Registerkarte Konfigurieren für Ihre Web-App, legen Sie Die Leistungsüberwachung auf Add-On fest, und legen Sie die Dropdownliste Add-On auswählen auf New Relic fest. Klicken Sie anschließend auf Speichern.
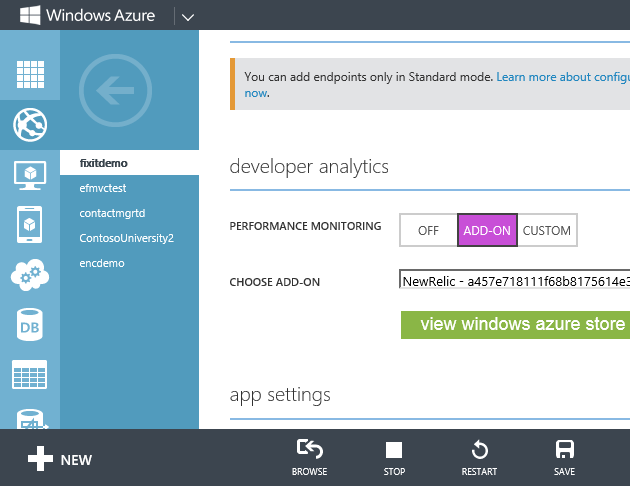
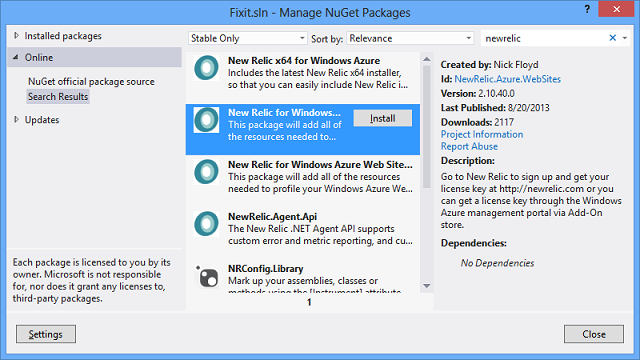
Installieren Sie in Visual Studio das New Relic NuGet-Paket in Ihrer App.
Stellen Sie die App in Azure bereit, und beginnen Sie mit der Verwendung. Erstellen Sie einige Fix It-Aufgaben, um eine Aktivität für New Relic bereitzustellen, die überwacht werden soll.
Wechseln Sie dann zurück zur Seite Neues Relikt auf der Registerkarte Add-Ons des Portals, und klicken Sie auf Verwalten. Das Portal sendet Sie zum New Relic-Verwaltungsportal, wobei Sie das einmalige Anmelden für die Authentifizierung verwenden, sodass Sie Ihre Anmeldeinformationen nicht erneut eingeben müssen. Die Seite Übersicht enthält eine Vielzahl von Leistungsstatistiken. (Klicken Sie auf das Bild, um die Übersichtsseite in voller Größe anzuzeigen.)

Hier sind nur einige der Statistiken, die Sie sehen können:
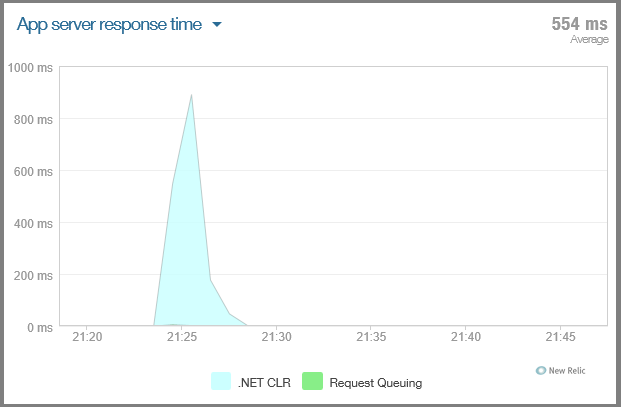
Durchschnittliche Antwortzeit zu unterschiedlichen Tageszeiten.
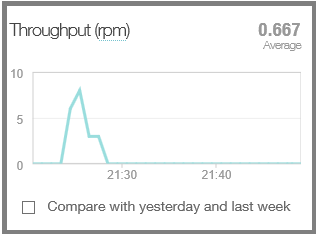
Durchsatzraten (in Anforderungen pro Minute) zu unterschiedlichen Tageszeiten.
Server-CPU-Zeit, die für die Verarbeitung unterschiedlicher HTTP-Anforderungen aufgewendet wurde.
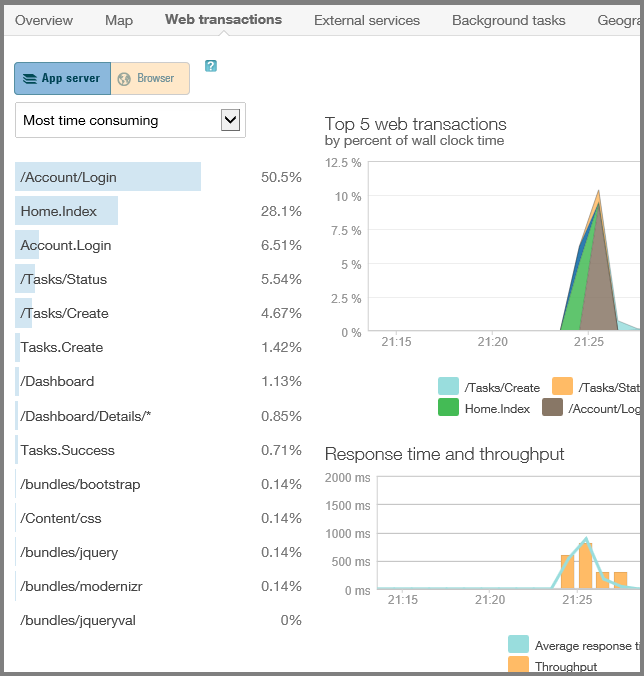
CPU-Zeit, die in verschiedenen Teilen des Anwendungscodes aufgewendet wird:
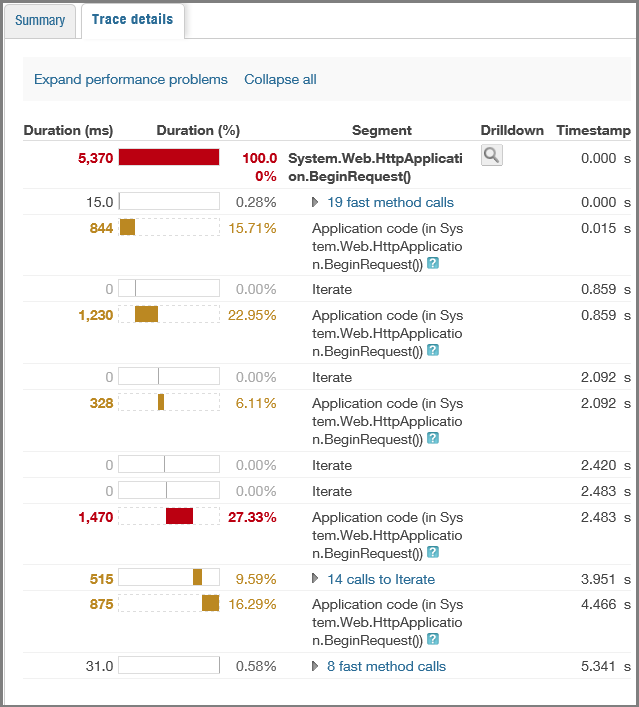
Historische Leistungsstatistiken.
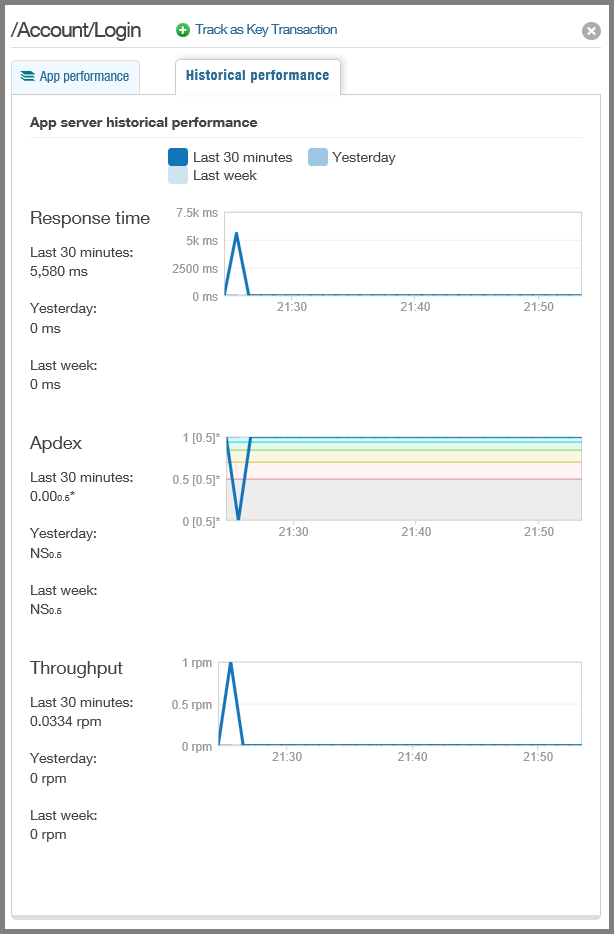
Aufrufe von externen Diensten wie dem Blobdienst und Statistiken darüber, wie zuverlässig und reaktionsfähig der Dienst war.
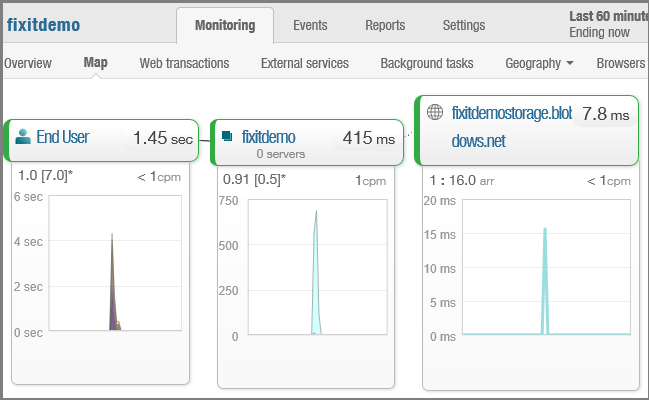
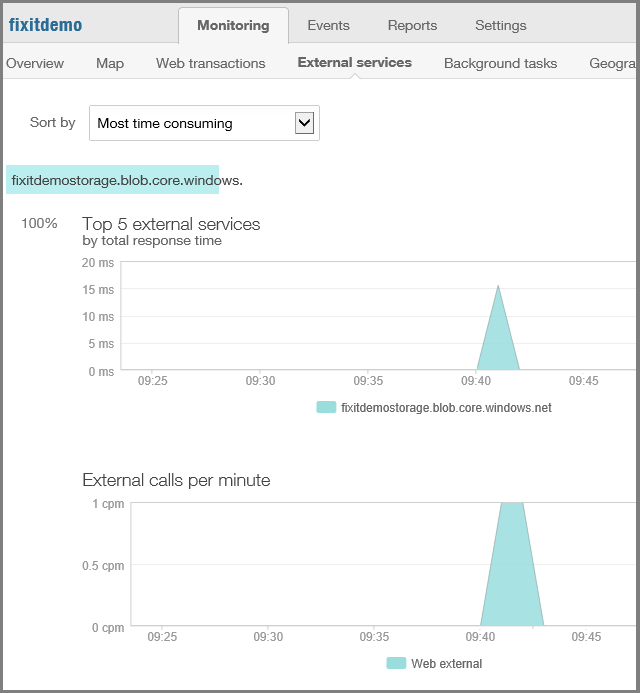
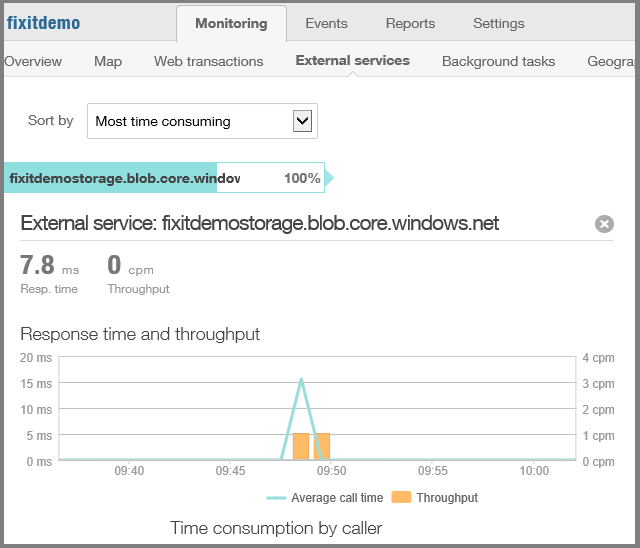
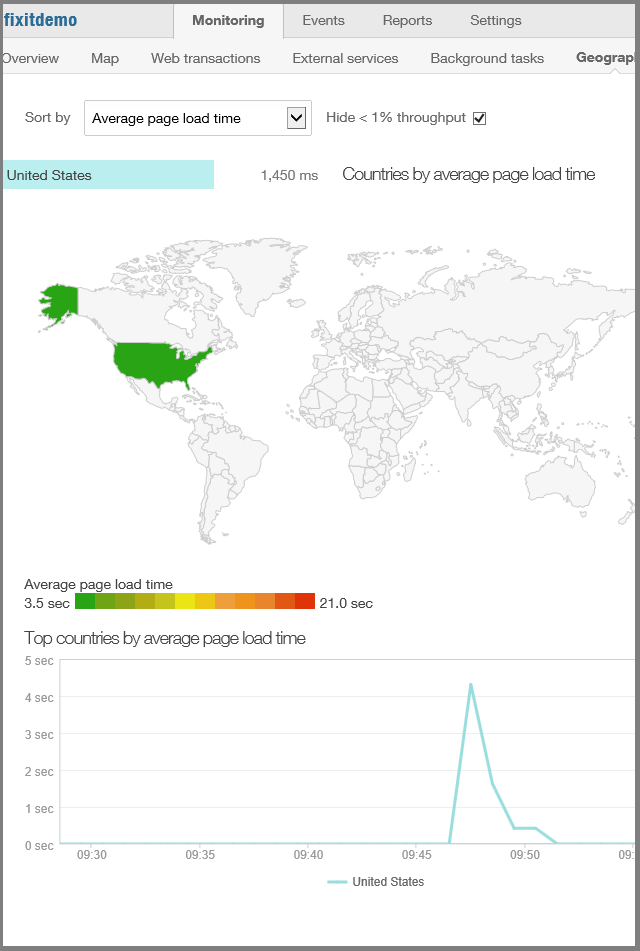
Informationen darüber, wo in der Welt oder wo in den USA Web-App-Datenverkehr stammt.
Sie können auch Berichte und Ereignisse einrichten. Sie können beispielsweise sagen, dass sie jedes Mal, wenn Fehler angezeigt werden, eine E-Mail senden, um das Supportpersonal auf das Problem hinzuweisen.
New Relic ist nur ein Beispiel für ein Telemetriesystem. Sie können all dies auch von anderen Diensten erhalten. Das Schöne an der Cloud ist, dass Sie ohne Code schreiben zu müssen und für minimale oder keine Kosten plötzlich viel mehr Informationen darüber erhalten können, wie Ihre Anwendung verwendet wird und was Ihre Kunden tatsächlich erleben.
Protokollieren für Erkenntnisse
Ein Telemetriepaket ist ein guter erster Schritt, aber Sie müssen trotzdem Ihren eigenen Code instrumentieren. Der Telemetriedienst informiert Sie, wenn ein Problem vorliegt, und informiert Sie darüber, was bei den Kunden auftritt, aber er gibt Ihnen möglicherweise nicht viele Einblicke in die Vorgänge in Ihrem Code.
Sie möchten nicht per Remotezugriff auf einen Produktionsserver zugreifen müssen, um zu sehen, was Ihre App tut. Dies kann praktisch sein, wenn Sie einen Server haben, aber was ist, wenn Sie auf Hunderte von Servern skaliert haben und nicht wissen, auf welche Server Sie remoteieren müssen? Ihre Protokollierung sollte genügend Informationen bereitstellen, die Sie nie auf Produktionsserver remoten müssen, um Probleme zu analysieren und zu debuggen. Sie sollten genügend Informationen protokollieren, damit Sie Probleme nur über die Protokolle isolieren können.
Produktion anmelden
Viele Menschen aktivieren die Ablaufverfolgung in der Produktion nur, wenn ein Problem vorliegt und sie debuggen möchten. Dies kann zu einer erheblichen Verzögerung zwischen dem Zeitpunkt, zu dem Sie ein Problem kennen, und dem Zeitpunkt führen, zu dem Sie nützliche Informationen zur Problembehandlung erhalten. Und die Informationen, die Sie erhalten, sind möglicherweise nicht hilfreich für zeitweilige Fehler.
Was wir in der Cloudumgebung empfehlen, in der Speicher günstig ist, ist, dass Sie sich immer in der Produktion anmelden lassen. Auf diese Weise haben Sie, wenn Fehler auftreten, bereits protokolliert, und Sie verfügen über Verlaufsdaten, die Ihnen helfen können, Probleme zu analysieren, die sich im Laufe der Zeit entwickeln oder regelmäßig zu unterschiedlichen Zeiten auftreten. Sie könnten einen Löschprozess automatisieren, um alte Protokolle zu löschen, aber möglicherweise ist es teurer, einen solchen Prozess einzurichten, als die Protokolle zu speichern.
Der zusätzliche Aufwand für die Protokollierung ist im Vergleich zu der Menge an Zeit und Geld für die Problembehandlung gering, die Sie sparen können, indem Sie alle informationen, die Sie benötigen, bereits verfügbar sind, wenn etwas schief geht. Wenn ihnen dann jemand sagt, dass er gestern abend gegen 8:00 Uhr einen zufälligen Fehler hatte, sich aber nicht an den Fehler erinnert, können Sie leicht herausfinden, was das Problem war.
Für weniger als 4 USD pro Monat können Sie 50 Gigabyte an Protokollen zur Hand halten, und die Auswirkungen der Protokollierung auf die Leistung sind trivial, solange Sie eines im Auge behalten: Um Leistungsengpässe zu vermeiden, stellen Sie sicher, dass Ihre Protokollierungsbibliothek asynchron ist.
Unterscheiden von Protokollen, die von Protokollen informieren, die eine Aktion erfordern
Protokolle sollen informieren (Ich möchte, dass Sie etwas wissen) oder ACT (Ich möchte, dass Sie etwas tun). Achten Sie darauf, nur ACT-Protokolle für Probleme zu schreiben, die tatsächlich eine Person oder einen automatisierten Prozess erfordern, um Maßnahmen zu ergreifen. Zu viele ACT-Protokolle verursachen Rauschen, was zu viel Arbeit erfordert, um alles zu durchsuchen, um echte Probleme zu finden. Wenn Ihre ACT-Protokolle automatisch eine Aktion auslösen, z. B. das Senden von E-Mails an Supportmitarbeiter, vermeiden Sie, dass Tausende solcher Aktionen durch ein einzelnes Problem ausgelöst werden.
In der .NET System.Diagnostics-Ablaufverfolgung können Protokolle fehler-, Warnungs-, Info- und Debug-/Ausführliche Ebene zugewiesen werden. Sie können ACT von INFORM-Protokollen unterscheiden, indem Sie die Fehlerebene für ACT-Protokolle reservieren und die niedrigeren Ebenen für INFORM-Protokolle verwenden.
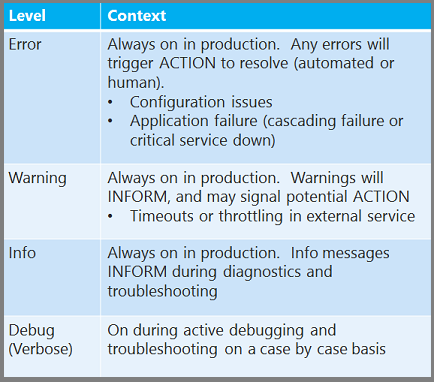
Konfigurieren von Protokollierungsebenen zur Laufzeit
Obwohl es sich lohnt, die Protokollierung in der Produktion immer aktiviert zu haben, besteht eine weitere bewährte Methode darin, ein Protokollierungsframework zu implementieren, mit dem Sie zur Laufzeit die Detailebene anpassen können, die Sie protokollieren, ohne Ihre Anwendung erneut bereitzustellen oder neu zu starten. Wenn Sie beispielsweise die Ablaufverfolgungsfunktion in System.Diagnostics verwenden, können Sie Fehler-, Warnungs-, Info- und Debug-/Ausführliche Protokolle erstellen. Es wird empfohlen, Fehler-, Warnungs- und Infoprotokolle immer in der Produktion zu protokollieren, und Sie sollten die Debug-/Ausführliche Protokollierung dynamisch für die Problembehandlung von Fall zu Fall hinzufügen können.
Web-Apps in Azure App Service verfügen über integrierte Unterstützung für das Schreiben von System.Diagnostics Protokollen in das Dateisystem, in den Tabellenspeicher oder in blob storage. Sie können für jedes Speicherziel unterschiedliche Protokollierungsebenen auswählen, und Sie können den Protokolliergrad im direkten Betrieb ändern, ohne Die Anwendung neu zu starten. Die Blob Storage-Unterstützung erleichtert die Ausführung von HDInsight-Analyseaufträgen in Ihren Anwendungsprotokollen, da HDInsight die direkte Arbeit mit Blob Storage versteht.
Protokollieren von Ausnahmen
Setzen Sie nicht einfach eine Ausnahme. ToString() in Ihrem Protokollierungscode. Dadurch werden kontextbezogene Informationen weg. Bei SQL-Fehlern wird die SQL-Fehlernummer weg. Schließen Sie für alle Ausnahmen Kontextinformationen, die Ausnahme selbst und innere Ausnahmen ein, um sicherzustellen, dass Sie alles bereitstellen, was für die Problembehandlung erforderlich ist. Kontextinformationen können z. B. den Servernamen, einen Transaktionsbezeichner und einen Benutzernamen enthalten (aber nicht das Kennwort oder geheimnisse!).
Wenn Sie sich darauf verlassen, dass jeder Entwickler bei der Ausnahmeprotokollierung das Richtige tut, werden einige davon nicht ausgeführt. Um sicherzustellen, dass dies jedes Mal richtig ausgeführt wird, erstellen Sie die Ausnahmebehandlung direkt in Ihre Protokollierungsschnittstelle: Übergeben Sie das Ausnahmeobjekt selbst an die Protokollierungsklasse, und protokollieren Sie die Ausnahmedaten ordnungsgemäß in der Protokollierungsklasse.
Protokollieren von Aufrufen von Diensten
Es wird dringend empfohlen, jedes Mal, wenn Ihre App einen Dienst aufruft, ein Protokoll zu schreiben, unabhängig davon, ob es sich um eine Datenbank, eine REST-API oder einen externen Dienst handelt. Fügen Sie in Ihre Protokolle nicht nur einen Hinweis auf Erfolg oder Fehler ein, sondern auch, wie lange jede Anforderung gedauert hat. In der Cloudumgebung treten häufig Probleme im Zusammenhang mit Verlangsamungen und nicht mit vollständigen Ausfällen auf. Etwas, das normalerweise 10 Millisekunden dauert, kann plötzlich eine Sekunde dauern. Wenn Ihnen jemand mitteilt, dass Ihre App langsam ist, möchten Sie new Relic oder den telemetrischen Dienst, den Sie haben, ansehen und deren Erfahrung überprüfen können, und dann möchten Sie in der Lage sein, nach Ihren eigenen Protokollen zu suchen, um die Details darüber zu erfahren, warum sie langsam ist.
Verwenden einer ILogger-Schnittstelle
Beim Erstellen einer Produktionsanwendung wird empfohlen, eine einfache ILogger-Schnittstelle zu erstellen und einige Methoden darin zu verwenden. Dies erleichtert es, die Protokollierungsimplementierung später zu ändern und nicht ihren gesamten Code durchlaufen zu müssen, um dies zu tun. Wir können die System.Diagnostics.Trace -Klasse in der gesamten Fix It-App verwenden, aber stattdessen verwenden wir sie im Cover in einer Protokollierungsklasse, die ILogger implementiert, und wir führen ILogger-Methodenaufrufe in der gesamten App durch.
Auf diese Weise können Sie, wenn Sie Ihre Protokollierung jemals reicher machen möchten, durch einen beliebigen Protokollierungsmechanismus ersetzen System.Diagnostics.Trace . Wenn Ihre App z. B. wächst, können Sie entscheiden, dass Sie ein umfassenderes Protokollierungspaket wie NLog oder Enterprise Library Logging Application Block verwenden möchten. (Log4Net ist ein weiteres beliebtes Protokollierungsframework, aber es führt keine asynchrone Protokollierung durch.)
Ein möglicher Grund für die Verwendung eines Frameworks wie NLog ist die Vereinfachung der Aufteilung der Protokollierungsausgabe in separate Datenspeicher mit hohem Und Hohem Wert. Dies hilft Ihnen, große Mengen von INFORM-Daten effizient zu speichern, für die Sie keine schnellen Abfragen ausführen müssen, während der schnelle Zugriff auf ACT-Daten beibehalten wird.
Semantische Protokollierung
Eine relativ neue Methode zur Protokollierung, die nützlichere Diagnoseinformationen erzeugen kann, finden Sie unter Semantische Protokollierungsanwendungsblock (SLAB) der Unternehmensbibliothek. SLAB verwendet die Ereignisablaufverfolgung für Windows (ETW) und EventSource-Unterstützung in .NET 4.5, um es Ihnen zu ermöglichen, strukturiertere und abfragbare Protokolle zu erstellen. Sie definieren eine andere Methode für jeden Ereignistyp, den Sie protokollieren, wodurch Sie die von Ihnen geschriebenen Informationen anpassen können. Um beispielsweise einen SQL-Datenbank Fehler zu protokollieren, können Sie eine LogSQLDatabaseError -Methode aufrufen. Für diese Art von Ausnahme wissen Sie, dass eine wichtige Information die Fehlernummer ist. Daher können Sie einen Fehlernummerparameter in die Methodensignatur einschließen und die Fehlernummer als separates Feld im protokolldatensatz aufzeichnen, den Sie schreiben. Da sich die Zahl in einem separaten Feld befindet, können Sie einfacher und zuverlässiger Berichte basierend auf SQL-Fehlernummern abrufen, als wenn Sie die Fehlernummer einfach in eine Meldungszeichenfolge verketten würden.
Anmelden in der Fix It-App
Die ILogger-Schnittstelle
Hier ist die ILogger-Schnittstelle in der Fix It-App.
public interface ILogger
{
void Information(string message);
void Information(string fmt, params object[] vars);
void Information(Exception exception, string fmt, params object[] vars);
void Warning(string message);
void Warning(string fmt, params object[] vars);
void Warning(Exception exception, string fmt, params object[] vars);
void Error(string message);
void Error(string fmt, params object[] vars);
void Error(Exception exception, string fmt, params object[] vars);
void TraceApi(string componentName, string method, TimeSpan timespan);
void TraceApi(string componentName, string method, TimeSpan timespan, string properties);
void TraceApi(string componentName, string method, TimeSpan timespan, string fmt, params object[] vars);
}
Mit diesen Methoden können Sie Protokolle auf den gleichen vier Ebenen schreiben, die von System.Diagnostics unterstützt werden. Die TraceApi-Methoden dienen zum Protokollieren externer Dienstaufrufe mit Informationen zur Latenz. Sie können auch eine Reihe von Methoden für die Debug-/Ausführlich-Ebene hinzufügen.
Die Logger-Implementierung der ILogger-Schnittstelle
Die Implementierung der Schnittstelle ist sehr einfach. Es ruft im Grunde nur die Standardmäßigen System.Diagnostics-Methoden auf. Der folgende Codeausschnitt zeigt alle drei Information-Methoden und jeweils eine der anderen Methoden.
public class Logger : ILogger
{
public void Information(string message)
{
Trace.TraceInformation(message);
}
public void Information(string fmt, params object[] vars)
{
Trace.TraceInformation(fmt, vars);
}
public void Information(Exception exception, string fmt, params object[] vars)
{
var msg = String.Format(fmt, vars);
Trace.TraceInformation(string.Format(fmt, vars) + ";Exception Details={0}", exception.ToString());
}
public void Warning(string message)
{
Trace.TraceWarning(message);
}
public void Error(string message)
{
Trace.TraceError(message);
}
public void TraceApi(string componentName, string method, TimeSpan timespan, string properties)
{
string message = String.Concat("component:", componentName, ";method:", method, ";timespan:", timespan.ToString(), ";properties:", properties);
Trace.TraceInformation(message);
}
}
Aufrufen der ILogger-Methoden
Jedes Mal, wenn Code in der Fix It-App eine Ausnahme abfängt, ruft er eine ILogger-Methode auf, um die Ausnahmedetails zu protokollieren. Und bei jedem Aufruf der Datenbank, des Blobdiensts oder einer REST-API wird vor dem Aufruf eine Stoppuhr gestartet, die Stoppuhr beendet, wenn der Dienst zurückgegeben wird, und die verstrichene Zeit zusammen mit Informationen zu Erfolg oder Fehler protokolliert.
Beachten Sie, dass die Protokollmeldung den Klassennamen und den Methodennamen enthält. Es empfiehlt sich, sicherzustellen, dass Protokollmeldungen erkennen, welcher Teil des Anwendungscodes sie geschrieben hat.
public class FixItTaskRepository : IFixItTaskRepository
{
private MyFixItContext db = new MyFixItContext();
private ILogger log = null;
public FixItTaskRepository(ILogger logger)
{
log = logger;
}
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Jetzt können Sie für jedes Mal, wenn die Fix It-App einen Aufruf von SQL-Datenbank durchgeführt hat, den Aufruf, die Methode, die sie aufgerufen hat, und genau sehen, wie viel Zeit er gedauert hat.
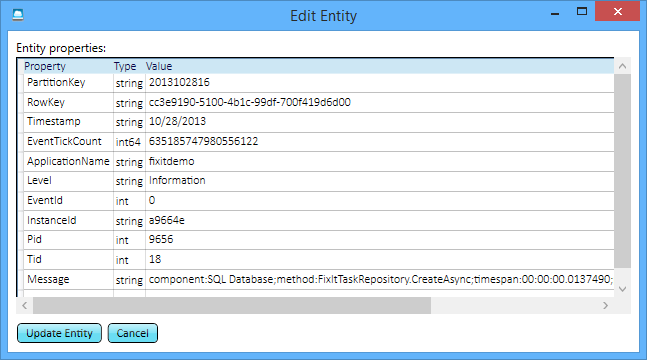
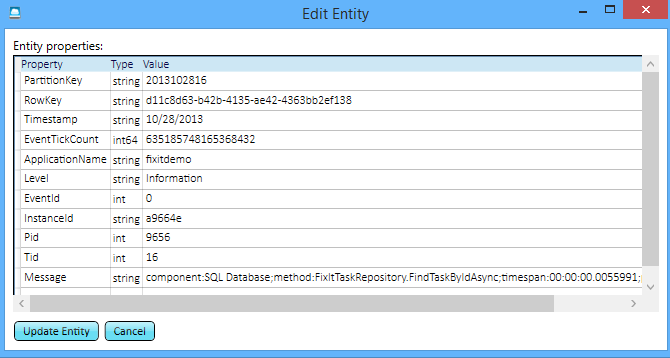
Wenn Sie die Protokolle durchsuchen, sehen Sie, dass die Dauer der Datenbankaufrufe variabel ist. Diese Informationen können nützlich sein: Da die App all dies protokolliert, können Sie verlaufsbezogene Trends in der Leistung des Datenbankdiensts im Laufe der Zeit analysieren. Für instance kann ein Dienst die meiste Zeit schnell sein, aber Anforderungen können fehlschlagen oder Antworten zu bestimmten Tageszeiten verlangsamen.
Sie können dasselbe für den Blobdienst tun: Jedes Mal, wenn die App eine neue Datei hochlädt, gibt es ein Protokoll, und Sie können genau sehen, wie lange das Hochladen der einzelnen Dateien gedauert hat.
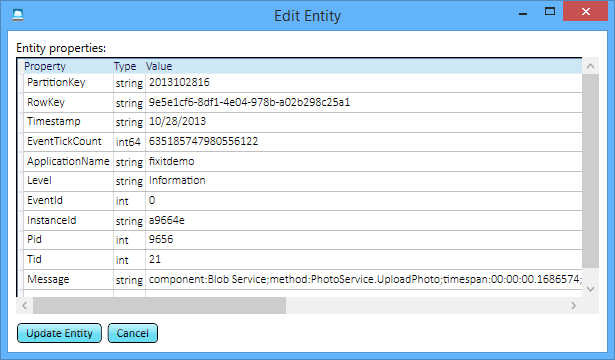
Es sind nur ein paar zusätzliche Codezeilen, die Sie jedes Mal schreiben können, wenn Sie einen Dienst aufrufen, und wenn jetzt jemand sagt, dass ein Problem aufgetreten ist, wissen Sie genau, was das Problem war, ob es sich um einen Fehler handelte oder sogar, wenn es nur langsam war. Sie können die Ursache des Problems ermitteln, ohne eine Remoteverbindung zu einem Server zu erstellen oder die Protokollierung zu aktivieren, nachdem der Fehler aufgetreten ist, und hoffen, ihn erneut zu erstellen.
Abhängigkeitsinjektion in der Fix It-App
Sie fragen sich vielleicht, wie der Repositorykonstruktor im obigen Beispiel die Implementierung der Protokollierungsschnittstelle abruft:
public class FixItTaskRepository : IFixItTaskRepository
{
private MyFixItContext db = new MyFixItContext();
private ILogger log = null;
public FixItTaskRepository(ILogger logger)
{
log = logger;
}
Um die Schnittstelle mit der Implementierung zu verknüpfen, verwendet die App Dependency Injection (DI) mit AutoFac. Di ermöglicht es Ihnen, ein Objekt basierend auf einer Schnittstelle an vielen Stellen im gesamten Code zu verwenden und müssen nur an einer Stelle die Implementierung angeben, die verwendet wird, wenn die Schnittstelle instanziiert wird. Dies erleichtert das Ändern der Implementierung: Sie können z. B. die System.Diagnostics-Protokollierung durch eine NLog-Protokollierung ersetzen. Für automatisierte Tests möchten Sie möglicherweise eine Modellversion der Protokollierung ersetzen.
Die Fix It-Anwendung verwendet DI in allen Repositorys und allen Controllern. Die Konstruktoren der Controllerklassen erhalten eine ITaskRepository-Schnittstelle auf die gleiche Weise, wie das Repository eine Protokollierungsschnittstelle abruft:
public class DashboardController : Controller
{
private IFixItTaskRepository fixItRepository = null;
public DashboardController(IFixItTaskRepository repository)
{
fixItRepository = repository;
}
Die App verwendet die AutoFac DI-Bibliothek, um taskRepository - und Logger-Instanzen für diese Konstruktoren automatisch bereitzustellen.
public class DependenciesConfig
{
public static void RegisterDependencies()
{
var builder = new ContainerBuilder();
builder.RegisterControllers(typeof(MvcApplication).Assembly);
builder.RegisterType<Logger>().As<ILogger>().SingleInstance();
builder.RegisterType<FixItTaskRepository>().As<IFixItTaskRepository>();
builder.RegisterType<PhotoService>().As<IPhotoService>().SingleInstance();
builder.RegisterType<FixItQueueManager>().As<IFixItQueueManager>();
var container = builder.Build();
DependencyResolver.SetResolver(new AutofacDependencyResolver(container));
}
}
Dieser Code besagt, dass überall dort, wo ein Konstruktor eine ILogger-Schnittstelle benötigt, eine instance der Logger-Klasse übergeben und immer dann, wenn er eine IFixItTaskRepository-Schnittstelle benötigt, eine instance der FixItTaskRepository-Klasse übergeben.
AutoFac ist eines von vielen Frameworks für die Abhängigkeitsinjektion, die Sie verwenden können. Ein weiterer beliebter ist Unity, das von Microsoft Patterns and Practices empfohlen und unterstützt wird.
Integrierte Protokollierungsunterstützung in Azure
Azure unterstützt die folgenden Arten der Protokollierung für Web-Apps in Azure App Service:
- System.Diagnostics-Ablaufverfolgung (Sie können die System.Diagnostics-Ablaufverfolgung aktivieren und deaktivieren und Stufen während des Vorgangs festlegen, ohne den Standort neu zu starten).
- Windows-Ereignisse.
- IIS-Protokolle (HTTP/FREB).
Azure unterstützt die folgenden Arten der Anmeldung in Cloud Services:
- System.Diagnostics-Ablaufverfolgung.
- Leistungsindikatoren.
- Windows-Ereignisse.
- IIS-Protokolle (HTTP/FREB).
- Benutzerdefinierte Verzeichnisüberwachung.
Die Fix It-App verwendet die System.Diagnostics-Ablaufverfolgung. Zum Aktivieren der System.Diagnostics-Protokollierung in einer Web-App müssen Sie lediglich einen Schalter im Portal umlegen oder die REST-API aufrufen. Klicken Sie im Portal auf die Registerkarte Konfiguration für Ihren Standort, und scrollen Sie nach unten, um den Abschnitt Anwendungsdiagnose anzuzeigen. Sie können die Protokollierung aktivieren oder deaktivieren und den gewünschten Protokollierungsgrad auswählen. Sie können die Protokolle von Azure in das Dateisystem oder in ein Speicherkonto schreiben lassen.
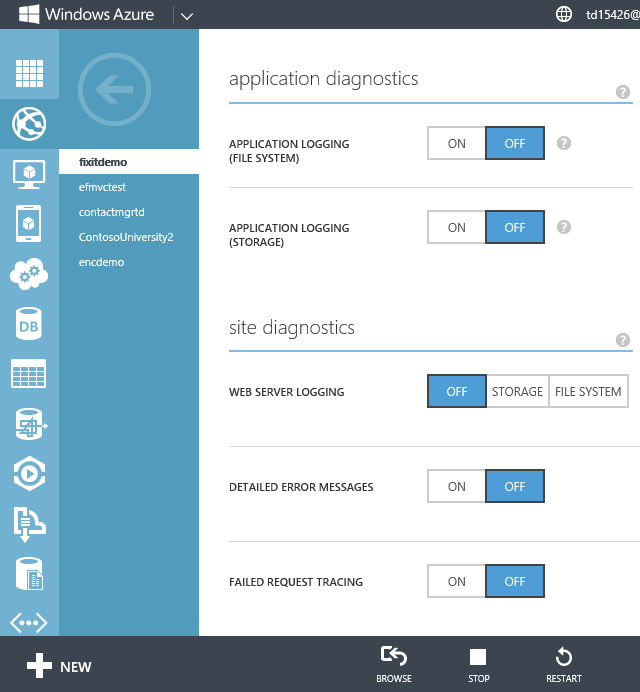
Nachdem Sie die Protokollierung in Azure aktiviert haben, werden Protokolle im Visual Studio-Ausgabefenster angezeigt, während sie erstellt werden.
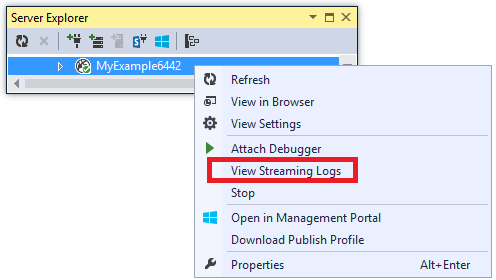
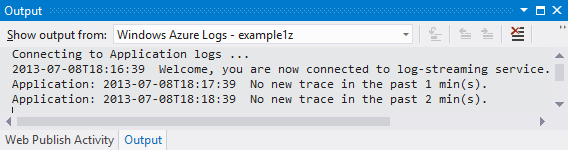
Sie können auch Protokolle in Ihr Speicherkonto schreiben lassen und sie mit jedem Tool anzeigen, das auf den Azure Storage-Tabellendienst zugreifen kann, z. B. Server Explorer in Visual Studio oder Azure Storage-Explorer.
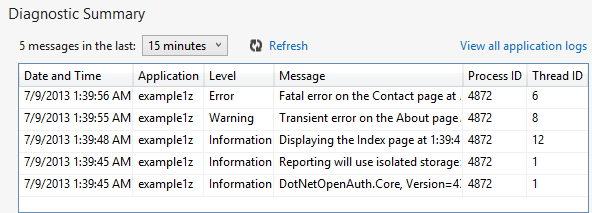
Zusammenfassung
Es ist wirklich einfach, ein sofort einsatzbereites Telemetriesystem zu implementieren, die Instrumentprotokollierung in Ihrem eigenen Code zu verwenden und die Protokollierung in Azure zu konfigurieren. Und wenn Sie Produktionsprobleme haben, hilft Ihnen die Kombination aus einem Telemetriesystem und benutzerdefinierten Protokollen, Probleme schnell zu beheben, bevor sie zu wichtigen Problemen für Ihre Kunden werden.
Im nächsten Kapitel erfahren Sie, wie Sie vorübergehende Fehler behandeln, damit sie nicht zu Produktionsproblemen werden, die Sie untersuchen müssen.
Ressourcen
Weitere Informationen finden Sie in den folgenden Ressourcen.
Dokumentation hauptsächlich zur Telemetrie:
- Microsoft-Muster und -Methoden: Azure-Leitfaden. Weitere Informationen finden Sie unter Instrumentierungs- und Telemetrieleitfaden, Leitfaden zur Dienstmessung, Überwachungsmuster für Integritätsendpunkte und Muster für die Laufzeitkonfigurierung.
- Penny Pinching in der Cloud: Aktivieren der New Relic-Leistungsüberwachung auf Azure-Websites.
- Bewährte Methoden für den Entwurf von Large-Scale Services in Azure Cloud Services. Whitepaper von Mark Simms und Michael Thomassy. Weitere Informationen finden Sie im Abschnitt Telemetrie und Diagnose.
- Entwicklung der nächsten Generation mit Application Insights. MSDN Magazine-Artikel.
Dokumentation hauptsächlich zur Protokollierung:
- Semantische Protokollierungsanwendungsblock (SLAB) Neil Mackenzie stellt den Fall für die semantische Protokollierung mit SLAB vor.
- Erstellen strukturierter und aussagekräftiger Protokolle mit semantischer Protokollierung. (Video) Julian Dominguez stellt den Fall für semantische Protokollierung mit SLAB vor.
- EF6 SQL-Protokollierung – Teil 1: Einfache Protokollierung. Arthur Vickers zeigt, wie Abfragen protokolliert werden, die von Entity Framework in EF 6 ausgeführt werden.
- Verbindungsresilienz und Befehlsinterception mit dem Entity Framework in einer ASP.NET MVC-Anwendung. Im vierten Teil einer neunteiligen Tutorialreihe wird gezeigt, wie Sie das EF 6-Befehlsinterception-Feature verwenden, um SQL-Befehle zu protokollieren, die von Entity Framework an die Datenbank gesendet werden.
- Verbessern der Protokollierung mithilfe von C# 5.0-Aufruferinfoattributen. Hier erfahren Sie, wie Sie den Namen der aufrufenden Methode einfach protokollieren, ohne sie hart in Literale zu codieren oder die Reflektion zu verwenden, um sie manuell abzurufen.
Dokumentation hauptsächlich zur Problembehandlung:
- Blog zur Azure-Problembehandlung & Debuggen.
- AzureTools: Das vom Azure-Entwicklersupportteam verwendete Diagnosehilfsprogramm. Stellt einen Downloadlink für ein Tool bereit, das auf einer Azure-VM zum Herunterladen und Ausführen einer Vielzahl von Diagnose- und Überwachungstools verwendet werden kann. Nützlich, wenn Sie ein Problem auf einer bestimmten VM diagnostizieren müssen.
- Problembehandlung für eine Web-App in Azure App Service mit Visual Studio. Ein schritt-für-Schritt-Tutorial für die ersten Schritte mit der System.Diagnostics-Ablaufverfolgung und dem Remotedebuggen.
Videos:
- FailSafe: Erstellen skalierbarer, resilienter Cloud Services. Neunteilige Serie von Ulrich Homann, Marc Mercuri und Mark Simms. Präsentiert allgemeine Konzepte und Architekturprinzipien auf sehr zugängliche und interessante Weise, mit Geschichten, die aus der Erfahrung des Microsoft Customer Advisory Teams (CAT) mit tatsächlichen Kunden stammen. In den Episoden 4 und 9 geht es um Überwachung und Telemetrie. Episode 9 enthält eine Übersicht über die Überwachungsdienste MetricsHub, AppDynamics, New Relic und PagerDuty.
- Building Big: Lessons learned from Azure customers ( Teil II) Mark Simms spricht über das Entwerfen für Fehler und die Instrumentierung alles. Ähnlich wie bei der Failsafe-Serie, geht aber in weitere Anleitungen ein.
Codebeispiel:
- Clouddienstgrundlagen in Azure. Beispielanwendung, die vom Microsoft Azure-Kundenberatungsteam erstellt wurde. Veranschaulicht sowohl Telemetrie- als auch Protokollierungsmethoden, wie in den folgenden Artikeln erläutert. Im Beispiel wird die Anwendungsprotokollierung mithilfe von NLog implementiert. Eine entsprechende Dokumentation finden Sie in der Reihe von vier TechNet-Wiki-Artikeln zu Telemetrie und Protokollierung.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für