In diesem Artikel werden die Muster und Implementierungen beschrieben, die beim Erstellen der Cloudtransformationslösung für ein Bankingsystem in Azure durch das CSE-Team (Entwicklerteam für die kommerzielle Software) verwendet wurden.
Aufbau
Saga-Architektur
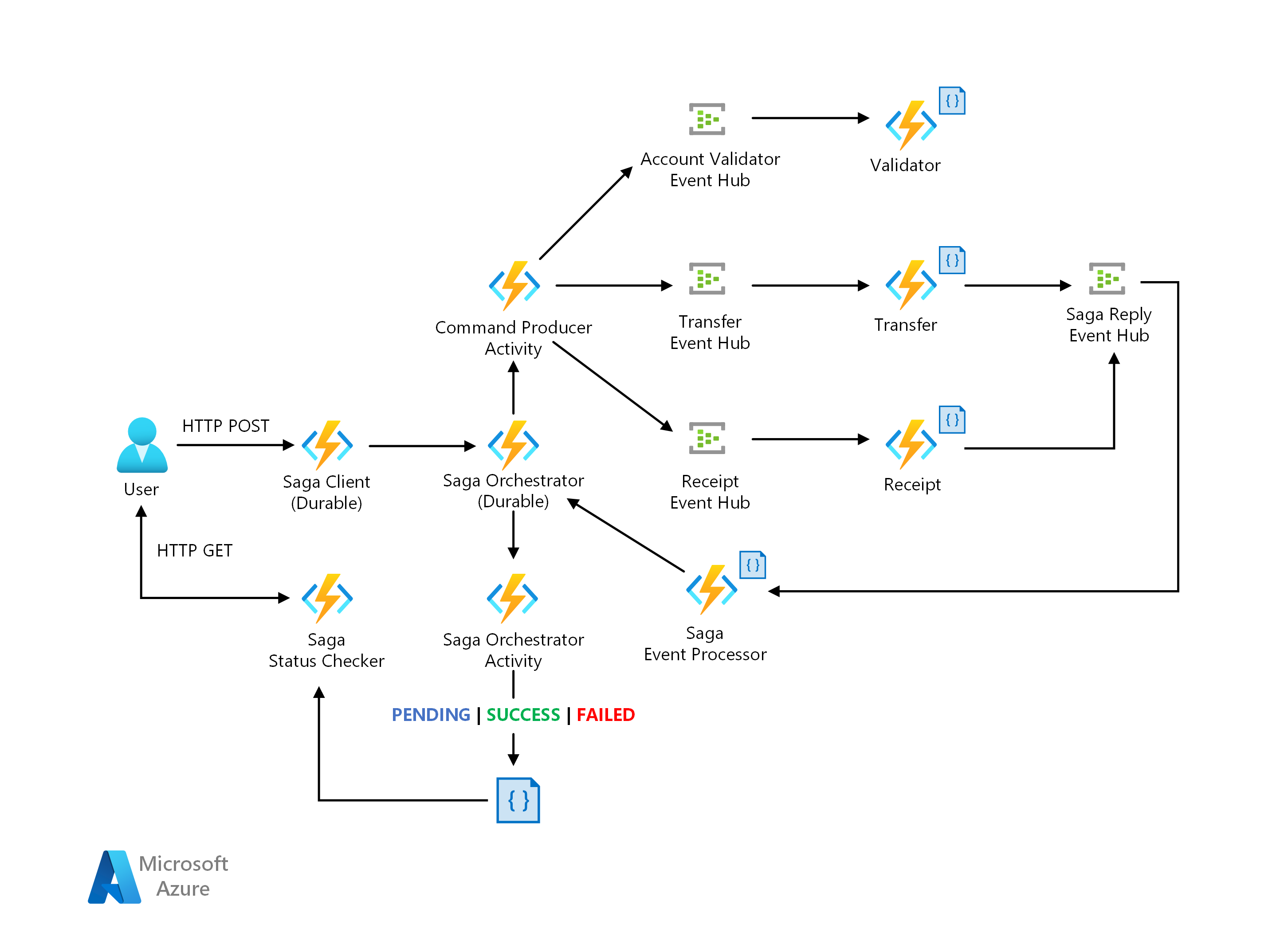
Laden Sie eine Visio-Datei dieser Architektur herunter.
Datenfluss
Die Contoso Bank verfügt über eine lokale Implementierung eines orchestrierungsbasierten Saga-Entwurfs. Bei ihrer Implementierung ist der Orchestrator ein endlicher Automat (Finite State Machine, FSM). Das CSE-Team erkannte die folgenden Herausforderungen im Architekturentwurf:
Der Implementierungsaufwand und die Komplexität des zustandsbehafteten Orchestrators für die Verwaltung von Zuständen, Timeouts und Neustarts in Fehlerszenarien
Mechanismen für Einblicke zum Nachverfolgen der Saga-Workflowstatus pro Transaktionsanforderung.
Als Lösung wird die Implementierung eines Saga-Musters über einen Orchestrierungsansatz vorgeschlagen, für den eine serverlose Architektur in Azure verwendet wird. Dabei werden die Herausforderungen wie folgt gelöst:
Azure Functions für die Implementierung von Saga-Teilnehmern
Azure Durable Functions für die Orchestrierung für das Workflow-Programmiermodell und die Zustandsverwaltung
Azure Event Hubs als Datenstreamingplattform
Azure Cosmos DB als Datenbankdienst zum Speichern von Datenmodellen
Weitere Informationen finden Sie unter Muster: Saga auf Microservices.io.
Saga-Muster
Saga ist ein Muster, das sich für die Verwaltung verteilter Transaktionen eignet und häufig bei Finanzdienstleistungen angewandt wird. Es wurde ein neues Szenario entwickelt, in dem Vorgänge auf Anwendungen und Datenbanken verteilt werden. In diesem neuen Szenario benötigen Kunden eine neue Architektur und einen neuen Implementierungsentwurf, um die Datenkonsistenz bei Finanztransaktionen sicherzustellen.
Der herkömmliche Ansatz anhand der Merkmale Atomizität, Konsistenz, Isolation und Dauerhaftigkeit (Atomicity, Consistency, Isolation, Durability, ACID) ist nicht mehr geeignet. Dies liegt daran, dass die Daten der Vorgänge sich jetzt über isolierte Datenbanken erstrecken. Die Verwendung eines Saga-Musters löst dieses Problem, indem ein Workflow über eine nachrichtengesteuerte Sequenz von lokalen Transaktionen koordiniert wird, um die Datenkonsistenz sicherzustellen.
KEDA-Architektur
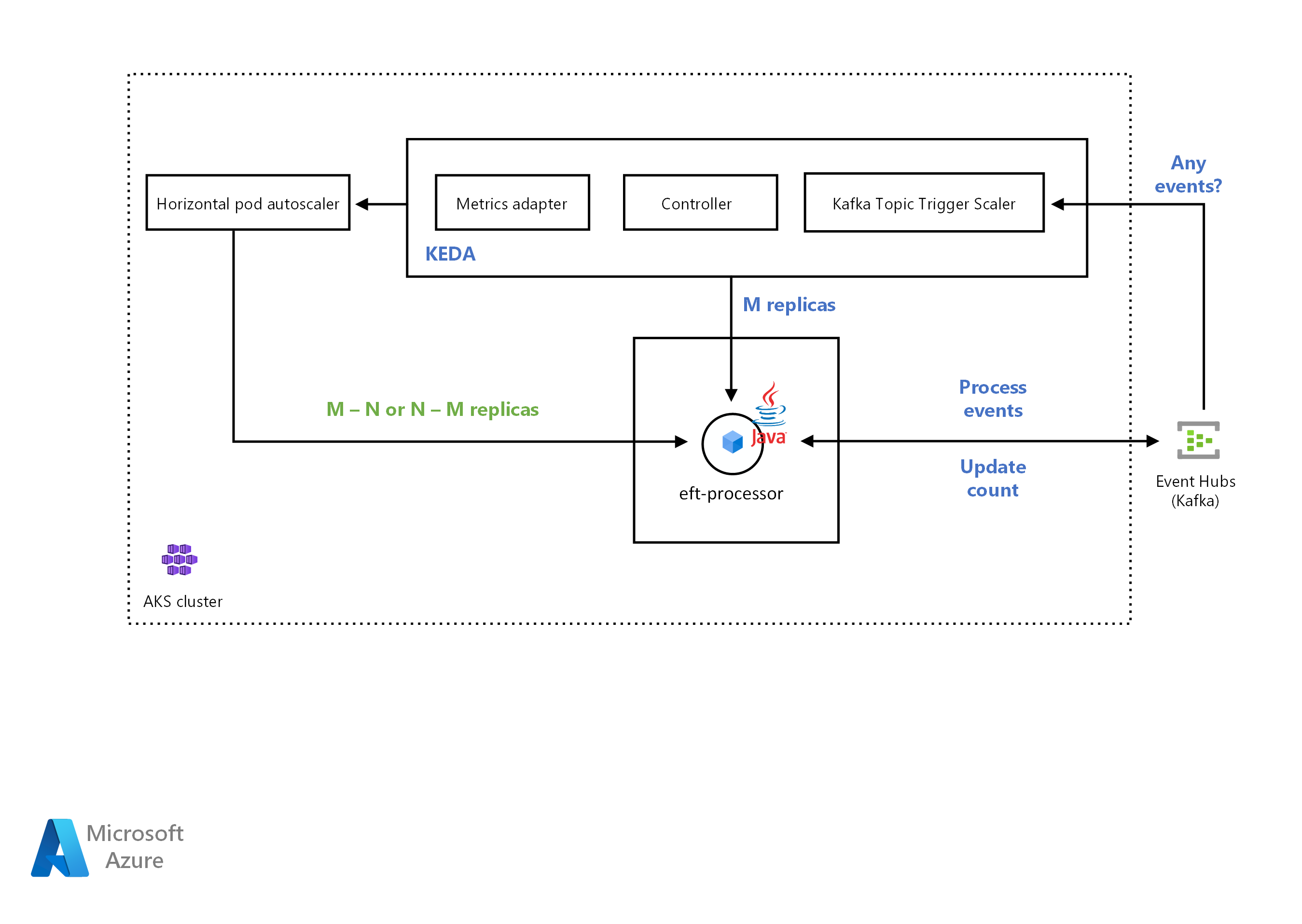
Laden Sie eine Visio-Datei dieser Architektur herunter.
Weitere Informationen zur KEDA-Skalierung finden Sie in den folgenden KEDA-Dokumenten:
Azure Event Hubs-Trigger: Kompatibilität zum Lesen des Azure Blob Storage-URI für Java-Anwendungen. Dabei wird das Ereignisprozessorhost-SDK verwendet, mit dem Java-Consumer skaliert werden können, die AMQP-Protokollmeldungen (Advance Message Queueing Protocol) von Event Hubs lesen. Früher funktionierte der Event Hubs-Scaler nur mit Azure Functions.
Apache Kafka-Thementrigger: Unterstützung für die einfache SASL_SSL-Authentifizierung, sodass Java-Consumer skaliert werden können, die Kafka-Protokollmeldungen von Event Hubs lesen.
Workflow
Das CSE-Team stellte die Anwendung im AKS-Cluster (Azure Kubernetes Service) bereit. Die Lösung sollte die Anwendung basierend auf der Anzahl eingehender Nachrichten automatisch aufskalieren. Das CSE-Team verwendete einen Kafka-Scaler, um zu ermitteln, ob die Lösung die Anwendungsbereitstellung aktivieren oder deaktivieren soll. Der Kafka-Scaler gibt auch benutzerdefinierte Metriken für eine bestimmte Ereignisquelle aus. Die Ereignisquelle in diesem Beispiel ist ein Azure Event Hub.
Wenn die Anzahl der Nachrichten im Azure-Event-Hub einen Schwellenwert überschreitet, löst KEDA eine Skalierung der Pods aus und erhöht die Anzahl der von der Anwendung verarbeiteten Nachrichten. Die automatische Herunterskalierung der Pods erfolgt, wenn die Anzahl der Nachrichten in der Ereignisquelle unter den Schwellenwert fällt.
Das CSE-Team verwendete dazu den Apache Kafka-Thementrigger. Er ermöglicht der Lösung die Skalierung des EFT-Prozessordiensts, wenn der Prozess die maximale Anzahl von Nachrichten in einem Zeitintervall überschreitet.
KEDA mit Java-Unterstützung
KEDA (Kubernetes Event-Driven Autoscaler) legt fest, wie die Lösung die Container innerhalb von Kubernetes skalieren soll. Die Entscheidung basiert auf der Anzahl der Ereignisse, die verarbeitet werden müssen. KEDA verfügt über verschiedene Typen von Skalierungen, unterstützt mehrere Workloadtypen sowie Azure Functions und ist herstellerunabhängig. Ein funktionierendes Beispiel finden Sie unter Automatisches Skalieren von Java-Anwendungen mit KEDA und Azure Event Hubs.
Architektur für Auslastungstests
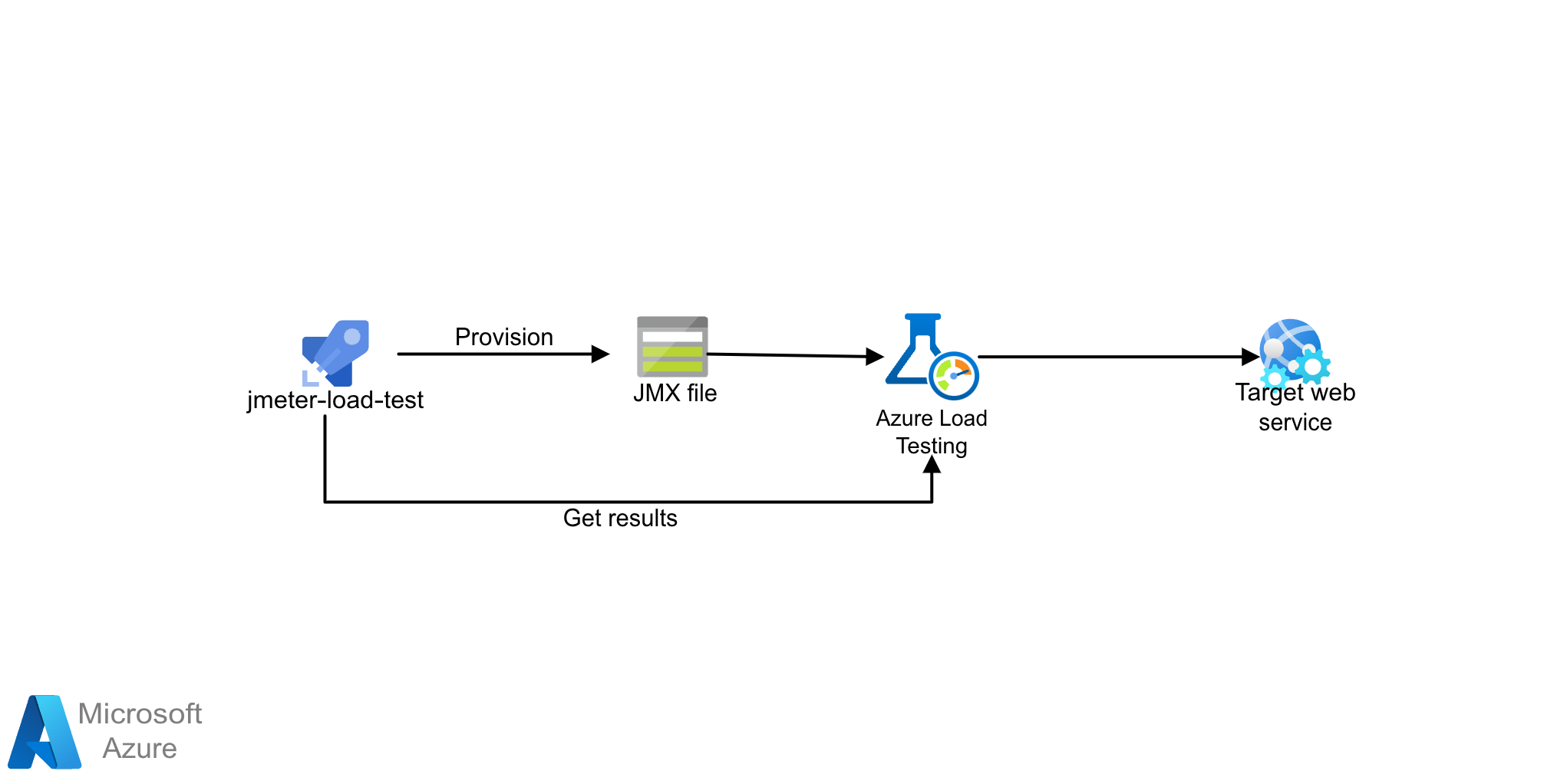
Laden Sie eine Visio-Datei dieser Architektur herunter.
Die Lösung verwendet Azure Load Testing mit JMeter (JMX)-Skripten. Azure Load Testing ist ein vollständig verwalteter Auslastungstestdienst, mit dem Sie eine hohe Auslastung generieren können. Der Dienst simuliert den Datenverkehr für Ihre Anwendungen, unabhängig davon, wo sie gehostet werden, und kann vorhandene JMeter-Skripte nutzen.
Workflow
Mit Azure Load Testing können Sie manuell Lasttests über das Azure-Portal oder Azure CLI erstellen. Alternativ können Sie auch eine CI/CD-Pipeline für die Integration mit Azure Load Testing konfigurieren. Auf diese Weise können Sie einen Lasttest automatisieren, um die Leistung und Stabilität Ihrer Anwendung als Teil Ihres CI/CD-Workflows kontinuierlich zu überprüfen.
- Verstehen Sie, wie Azure Lasttests funktionieren, indem Sie einen Lasttest erstellen und ausführen.
- Verwenden Sie neue oder vorhandene JMeter-Skripte und konfigurieren Sie Ihren CI/CD-Workflow für die Durchführung von Lasttests.
Szenariodetails
Dieses Szenario hilft Ihnen, Big-Picture-Muster und Implementierungen in der Bankenbranche besser zu verstehen, wenn Sie in die Cloud wechseln.
Nächste Schritte
Erfahren Sie mehr über die Komponententechnologien:
- Einführung in Azure Functions
- Was ist Durable Functions?
- Azure Event Hubs: Big Data-Streamingplattform und Ereigniserfassungsdienst
- Willkommen bei Azure Cosmos DB
Zugehörige Ressourcen
Siehe verwandte Architekturen: