Skalieren von Einzeldatenbankressourcen in Azure SQL-Datenbank
In diesem Artikel wird beschrieben, wie die für eine Azure SQL-Datenbank-Instanz im bereitgestellten Computetarif verfügbaren Compute- und Speicherressourcen skaliert werden können. Alternativ bietet die serverlose Computeebene automatische Computeskalierung und eine Abrechnung der genutzten Computekapazität pro Sekunde.
Nach dem Auswählen der Anzahl von virtuellen Kernen und DTUs können Sie eine einzelne Datenbank dynamisch und bedarfsgerecht zentral hoch- oder herunterskalieren. Hierzu können Sie Folgendes verwenden:
Wichtig
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Dateispeicherplatz in Azure SQL-Datenbank.
Hinweis
Microsoft Entra ID war zuvor als Azure Active Directory (Azure AD) bekannt.
Auswirkung
Zum Ändern der Dienstebene oder der Computegröße müssen hauptsächlich die folgenden Schritte ausgeführt werden:
Erstellen Sie eine neue Computeinstanz für die Datenbank.
Eine neue Computeinstanz wird mit der angeforderten Dienstebene und Computegröße erstellt. Bei einigen Kombinationen aus Änderungen der Dienstebene und der Computegröße muss in der neuen Computeinstanz ein Replikat der Datenbank erstellt werden. Dies umfasst das Kopieren von Daten und kann sich stark auf die Gesamtwartezeit auswirken. Die Datenbank bleibt unabhängig davon während dieses Schritts online, und Verbindungen werden weiterhin an die Datenbank in der ursprünglichen Computeinstanz weitergeleitet.
Leiten Sie die Verbindungen zu einer neuen Computeinstanz um.
Vorhandene Verbindungen zur Datenbank in der ursprünglichen Computeinstanz werden verworfen. Alle neuen Verbindungen werden mit der Datenbank in der neuen Computeinstanz hergestellt. Bei einigen Kombinationen von Dienstebenen- und Computegrößenänderungen werden Datenbankdateien während des Wechsels getrennt und neu angefügt. Der Wechsel kann zu einer kurzen Dienstunterbrechung führen, in der die Datenbank in der Regel für weniger als 30 Sekunden nicht verfügbar ist. Sollten zu dem Zeitpunkt, zu dem die Verbindungen getrennt werden, zeitintensive Transaktionen ausgeführt werden, kann dieser Schritt länger dauern, weil abgebrochene Transaktionen wiederhergestellt werden müssen. Mit der schnelleren Datenbankwiederherstellung können die Auswirkungen abgebrochener, zeitintensiver Transaktionen reduziert werden.
Wichtig
Während dieses Workflows gehen keine Daten verloren. Implementieren Sie unbedingt auch Wiederholungslogik in den Anwendungen und Komponenten, die Azure SQL-Datenbank verwenden, während die Dienstebene geändert wird.
Latency
Beim Ändern der Dienstebene, beim Skalieren der Computegröße einer Einzeldatenbank oder eines Pools für elastische Datenbanken, beim Verschieben einer Datenbank in einen/aus einem Pool für elastische Datenbanken oder beim Verschieben einer Datenbank zwischen Pools für elastische Datenbanken wird die geschätzte Wartezeit wie folgt parametrisiert:
| Latenz bei der Datenbankskalierung | Zu Singleton vom Typ „Basic“, Standard-Singleton (S0-S1) |
Zu Singleton vom Typ „Standard“ (S2-S12), Singleton vom Typ „Universell“, Elastische Pooldatenbank vom Typ „Basic“, Elastische Pooldatenbank vom Typ „Standard“ Elastische Pooldatenbank vom Typ „Universell“ |
Zu Singleton oder Pooldatenbank vom Typ „Premium“ Singleton oder Pooldatenbank vom Typ „Unternehmenskritisch“ |
Zu Singleton oder Pooldatenbank vom Typ „Hyperscale“ |
|---|---|---|---|---|
| Von Singleton vom Typ „Basic“, Standard-Singleton (S0-S1) |
• Konstante Zeitlatenz unabhängig vom verwendeten Speicherplatz. • In der Regel weniger als 5 Minuten. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
| Von Pooldatenbank vom Typ „Basic“, Singleton vom Typ „Standard“ (S2-S12), Pooldatenbank vom Typ „Standard“, Singleton oder Pooldatenbank vom Typ „Universell“ |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
• Bei Singletons: konstante Zeitlatenz unabhängig vom verwendeten Speicherplatz. • In der Regel weniger als 5 Minuten für Singletons. • Bei Pools für elastische Datenbanken: proportional zur Anzahl der Datenbanken. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
| Von Singleton oder Pooldatenbank vom Typ „Premium“, Singleton oder Pooldatenbank vom Typ „Unternehmenskritisch“ |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
• Latenz proportional zum verwendeten Datenbankspeicherplatz durch das Kopieren von Daten. • In der Regel weniger als 1 Minute/GB verwendeter Speicherplatz. |
| Von Singleton oder Pooldatenbank vom Typ „Hyperscale“ | N/V | Weitere Informationen zu unterstützten Szenarien und Einschränkungen finden Sie unter Umgekehrte Migration aus Hyperscale. | N/V | • Konstante Zeitlatenz unabhängig vom verwendeten Speicherplatz. • In der Regel weniger als 2 Minuten. |
Hinweis
- Darüber hinaus ist bei Datenbanken vom Typ „Standard (S2-S12)“ und „Universell“ die Wartezeit beim Verschieben einer Datenbank in einen/aus einem Pool für elastische Datenbanken oder zwischen Pools für elastische Datenbanken proportional zur Datenbankgröße, wenn für die Datenbank PFS-Speicher (Premium File Share, Premium-Dateifreigabe) verwendet wird.
- Wenn eine Datenbank in einen oder aus einem Pool für elastische Datenbanken verschoben wird, ist für die Wartezeit nur der Speicherplatz relevant, der von der Datenbank verwendet wird, nicht der verwendete Speicherplatz des Pools für elastische Datenbanken.
- Um zu ermitteln, ob eine Datenbank PFS-Speicher verwendet, führen Sie die folgende Abfrage im Kontext der Datenbank aus. Wenn der Wert in der Spalte „AccountType“
PremiumFileStorageoderPremiumFileStorage-ZRSlautet, verwendet die Datenbank PFS-Speicher.
SELECT s.file_id,
s.type_desc,
s.name,
FILEPROPERTYEX(s.name, 'AccountType') AS AccountType
FROM sys.database_files AS s
WHERE s.type_desc IN ('ROWS', 'LOG');
Hinweis
- Die zonenredundante Eigenschaft bleibt bei der Skalierung einer Singleton von der unternehmenskritischen auf die universelle Ebene standardmäßig unverändert.
- Die Latenz für den Skalierungsvorgang, wenn die Zonenredundanz für eine Singleton vom Typ „Universell“ geändert wird, ist proportional zur Datenbankgröße.
Tipp
Weitere Informationen zum Überwachen aktuell ausgeführter Vorgänge finden Sie unter: Verwalten von Vorgängen mit der SQL-REST-API, Verwalten von Vorgängen mithilfe der CLI, Überwachen von Vorgängen mit T-SQL und unter diesen beiden PowerShell-Befehlen: Get-AzSqlDatabaseActivity und Stop-AzSqlDatabaseActivity.
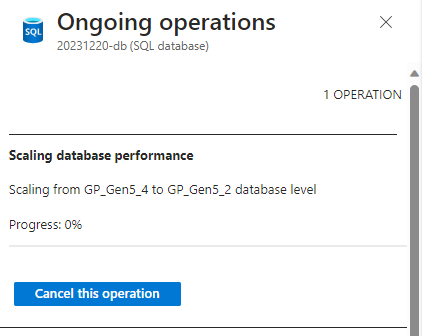
Überwachen oder Abbrechen von Skalierungsänderungen
Die Änderung einer Dienstebene oder der Vorgang zur Computeneuskalierung kann überwacht und abgebrochen werden.
Suchen Sie auf der Seite ÜBERSICHT der SQL-Datenbank nach dem Banner mit der Angabe, dass ein Skalierungsvorgang ausgeführt wird, und wählen Sie den Link Weitere Informationen für die laufende Bereitstellung aus.

Wählen Sie auf der Seite Laufende Vorgänge die Option Diesen Vorgang abbrechen aus.
Berechtigungen
Zum Skalieren von Datenbanken über Transact-SQL wird ALTER DATABASE verwendet. Damit eine Datenbank skaliert werden kann, muss eine Anmeldung entweder als Serveradministrator (erstellt bei der Bereitstellung des logischen Servers für Azure SQL-Datenbank), als Microsoft Entra-Administrator des Servers, als Mitglied der Datenbankrolle „dbmanager“ in master, als Mitglied der Datenbankrolle „db_owner“ in der aktuellen Datenbank oder als dbo der Datenbank erfolgen. Weitere Informationen finden Sie unter ALTER DATABASE.
Für die Skalierung von Datenbanken über das Azure-Portal, PowerShell, die Azure CLI oder REST-API sind Azure RBAC-Berechtigungen erforderlich, insbesondere die Azure RBAC-Rollen „Mitwirkender“, „SQL-DB-Mitwirkender“ oder „SQL Server-Mitwirkender“. Weitere Informationen finden Sie unter Azure RBAC: integrierte Rollen.
Weitere Überlegungen
- Wenn Sie ein Upgrade auf eine höhere Dienstebene oder Computegröße durchführen, wird die maximale Datenbankgröße nur erhöht, wenn Sie explizit eine höhere Maximalgröße angeben.
- Für das Downgrade einer Datenbank muss die verwendete Datenbankmenge kleiner als die maximal zulässige Größe der Zieldienstebene und der Zielcomputegröße sein.
- Bei einem Downgrade von der Dienstebene Premium zu Standard fallen zusätzliche Speicherkosten an, wenn (1) die maximale Größe der Datenbank von der Zielcomputegröße unterstützt wird und (2) die maximale Größe in der Zielcomputegröße die enthaltene Speichermenge überschreitet. Wenn z.B. eine P1-Datenbank mit einer maximalen Größe von 500GB auf S3 reduziert wird, fallen zusätzliche Speicherkosten an, da S3 eine maximale Größe von 1TB unterstützt und die enthaltene Speichermenge nur 250GB beträgt. Daher beträgt die zusätzliche Speichermenge 500 GB – 250 GB = 250 GB. Informationen zu den Preisen für zusätzlichen Speicherplatz siehe Preise für Azure SQL-Datenbank. Wenn die tatsächlich verwendete Speichermenge kleiner als die enthaltene Speichermenge ist, können Sie diese zusätzlichen Kosten vermeiden, indem Sie die maximale Datenbankgröße auf die enthaltene Menge reduzieren.
- Beim Upgrade einer Datenbank mit aktivierter Georeplikation führen Sie zuerst ein Upgrade der sekundären Datenbanken auf die gewünschte Dienstebene und die gewünschte Computegröße durch, bevor Sie ein Upgrade für die primäre Datenbank vornehmen (allgemeine Richtlinie für optimale Leistung). Wenn Sie ein Upgrade auf eine andere Edition durchführen möchten, muss zuerst die sekundäre Datenbank aktualisiert werden.
- Beim Downgrade einer Datenbank mit aktivierter Georeplikation führen Sie zuerst ein Downgrade der primären Datenbank auf die gewünschte Dienstebene und die gewünschte Computegröße durch, bevor Sie ein Downgrade für die sekundären Datenbanken vornehmen (allgemeine Richtlinie für optimale Leistung). Bei einem Downgrade auf eine andere Edition muss zuerst die primäre Datenbank herabgestuft werden.
- Die Angebote des Wiederherstellungsdiensts variieren für die verschiedenen Dienstebenen. Bei einem Downgrade auf den Tarif Basic ergibt sich ein kürzerer Aufbewahrungszeitraum für Sicherungen. Weitere Informationen finden Sie unter Azure SQL-Datenbanksicherungen.
- Die neuen Eigenschaften für die Datenbank werden erst angewendet, wenn die Änderungen abgeschlossen sind.
- Wenn beim Ändern der Dienstebene Daten kopiert werden müssen, um eine Datenbank zu skalieren (siehe Wartezeit), und während der Skalierung eine hohe Ressourcenauslastung besteht, kann die Skalierung mehr Zeit erfordern. Bei der beschleunigten Datenbankwiederherstellung (Accelerated Database Recovery, ADR) ist ein Rollback von Transaktionen mit langer Ausführungszeit kein wesentlicher Faktor für Verzögerungen. Eine hohe gleichzeitige Ressourcenauslastung kann jedoch bewirken, dass weniger Compute- und Speicherressourcen und weniger Netzwerkbandbreite für die Skalierung verfügbar sind, insbesondere bei geringeren Computegrößen.
Abrechnung
Die Abrechnung erfolgt für jede Stunde, in der eine Datenbank die höchste in dieser Stunde angewendete Dienstebene und Computegröße nutzt – unabhängig von der Nutzung und unabhängig davon, ob die Datenbank weniger als eine Stunde aktiv war. Wenn Sie beispielsweise eine Einzeldatenbank erstellen und diese fünf Minuten später löschen, wird Ihnen eine volle Datenbankstunde in Rechnung gestellt.
Ändern der Speichergröße
vCore-basiertes Kaufmodell
Speicher kann in Inkrementen von 1 GB bis zur maximalen Datenspeichergröße bereitgestellt werden. Die konfigurierbare Mindestdatenspeichergröße ist 1 GB. Informationen zur maximalen Größe der Datenspeicherung in den einzelnen Dienstzielen finden Sie auf den Dokumentationsseiten zu Ressourcenlimits unter Ressourcenlimits für Singletons mit dem auf virtuellen Kernen (V-Kernen) basierenden Kaufmodell sowie unter Ressourcengrenzwerte für Einzeldatenbanken, die das DTU-Kaufmodell verwenden: Azure SQL-Datenbank.
Datenspeicher für eine Einzeldatenbank kann durch Erhöhen oder Verringern der maximalen Größe über das Azure-Portal, Transact-SQL, PowerShell, die Azure CLI oder die REST-API bereitgestellt werden. Wenn der Wert für die maximale Größe in Bytes angegeben wird, muss er ein Vielfaches von 1 GB (1073741824 Bytes) sein.
Die Menge der Daten, die in den Datendateien einer Datenbank gespeichert werden kann, ist durch die konfigurierte maximale Größe des Datenspeichers begrenzt. Zusätzlich zu diesem Speicher fügt Azure SQL-Datenbank automatisch 30 Prozent mehr Speicher für das Transaktionsprotokoll hinzu. Der Preis für Speicher für eine Einzeldatenbank oder einen Pool für elastische Datenbanken errechnet sich aus der Summe des Datenspeichers und des Transaktionsprotokollspeichers multipliziert mit dem Speichereinheitenpreis für die Dienstebene. Wenn der Datenspeicher beispielsweise auf 10 GB festgelegt ist, beträgt der zusätzliche Transaktionsprotokollspeicher 10 GB * 30 % = 3 GB und der Gesamtbetrag des abrechnenden Speichers beträgt 10 GB + 3 GB = 13 GB.
Hinweis
Die maximale Größe der Transaktionsprotokolldatei wird automatisch verwaltet und kann in einigen Fällen größer als 30 % der maximalen Größe des Datenspeichers sein. Dadurch wird der Speicherpreis für die Datenbank nicht erhöht.
Azure SQL-Datenbank ordnet für die
tempdb-Datenbank automatisch 32 GB pro virtuellem Kern zu.tempdbbefindet sich in allen Dienstebenen auf einem lokalen SSD-Datenträger. Die Kosten fürtempdbsind im Preis für eine einzelne Datenbank oder einen Pool für elastische Datenbanken enthalten.Ausführliche Informationen zu den Speicherpreisen finden Sie unter Preise für Azure SQL-Datenbank .
Wichtig
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Dateispeicherplatz in Azure SQL-Datenbank.
DTU-basiertes Kaufmodell
- Der DTU-Preis für eine einzelne Datenbank enthält eine bestimmte Menge Speicher ohne zusätzliche Kosten. Zusätzlicher Speicher über die inbegriffene Speichermenge hinaus kann gegen zusätzliche Gebühren bis zur Obergrenze in Inkrementen von 250 GB bis zu 1 TB und dann in Inkrementen von 256 GB über 1 TB hinaus bereitgestellt werden. Informationen zu enthaltenen Speichermengen und Maximalgrößen finden Sie unter Einzeldatenbank: Speicher- und Computegrößen.
- Zusätzlicher Speicher für eine Einzeldatenbank kann durch Erhöhen der maximalen Größe über das Azure-Portal, Transact-SQL, PowerShell, die Azure CLI oder die REST-API bereitgestellt werden.
- Der Preis für zusätzlichen Speicher für eine Einzeldatenbank errechnet sich aus der Menge an zusätzlich bereitgestelltem Speicher multipliziert mit dem Einheitenpreis für zusätzlichen Speicher für die Dienstebene. Ausführliche Informationen zu den Preisen für zusätzlichen Speicherplatz finden Sie unter Preise für Azure SQL-Datenbank.
Wichtig
Unter bestimmten Umständen müssen Sie ggf. eine Datenbank verkleinern, um ungenutzten Speicherplatz freizugeben. Weitere Informationen finden Sie unter Verwalten von Dateispeicherplatz in Azure SQL-Datenbank.
Georeplizierte Datenbank
Zum Ändern der Datenbankgröße einer replizierten sekundären Datenbank ändern Sie die Größe der primären Datenbank. Diese Änderung wird dann auch in der sekundären Datenbank repliziert und implementiert.
Einschränkungen von P11 und P15, wenn die maximale Größe 1 TB übersteigt
In allen Regionen außer den folgenden ist im Premium-Tarif derzeit mehr als 1 TB Speicher verfügbar: China, Osten; China, Norden; Deutschland, Mitte; Deutschland, Nordosten. In diesen Regionen ist der Speicher im Tarif „Premium“ auf 1 TB begrenzt. Die folgenden Aspekte und Einschränkungen gelten für P11- und P15-Datenbanken mit einer maximalen Größe von mehr als 1 TB:
- Wenn die maximale Größe einer P11- oder P15-Datenbank jemals auf einen Wert über 1 TB festgelegt wurde, kann sie nur in einer P11- oder P15-Datenbank wiederhergestellt oder kopiert werden. Die Datenbank kann folglich auf eine andere Computegröße skaliert werden, sofern der zugewiesene Speicherplatz zum Zeitpunkt der Neuskalierung nicht die maximalen Grenzwerte der neuen Computegröße überschreitet.
- Für aktive Georeplikationsszenarien:
- Einrichten einer Georeplikationsbeziehung: Wenn es sich bei der primären Datenbank um eine P11- oder P15-Datenbank handelt, müssen auch sekundäre P11- oder P15-Datenbanken verwendet werden. Geringere Computegrößen werden als sekundäre Datenbanken abgelehnt, weil sie nicht mehr als 1 TB unterstützen können.
- Aktualisieren der primären Datenbank in einer Georeplikationsbeziehung: Die Änderung der maximalen Größe für eine primäre Datenbank in mehr als 1 TB löst die gleiche Änderung für die sekundäre Datenbank aus. Beide Upgrades müssen erfolgreich ausgeführt werden, damit die Änderung für die primäre Datenbank wirksam wird. Für die Option mit mehr als 1 TB gelten Regionseinschränkungen. Wenn sich die sekundäre Datenbank in einer Region befindet, die nicht mehr als 1 TB unterstützt, wird die primäre Datenbank nicht aktualisiert.
- Die Verwendung des Import/Export-Diensts zum Laden von P11-/P15-Datenbanken mit mehr als 1 TB wird nicht unterstützt. Verwenden Sie SqlPackage, um Daten zu importieren und zu exportieren.
Zugehöriger Inhalt
Allgemeine Ressourcengrenzwerte finden Sie unter Ressourcenlimits für Singletons mit dem auf virtuellen Kernen (V-Kernen) basierenden Kaufmodell und unter Ressourcengrenzwerte für Einzeldatenbanken, die das DTU-Kaufmodell verwenden: Azure SQL-Datenbank.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für