Was ist Azure Batch?
Mithilfe von Azure Batch können Sie umfangreiche auf Parallelverarbeitung ausgelegte HPC-Batchaufträge (High Performance Computing) effizient in Azure ausführen. Azure Batch erstellt und verwaltet einen Pool mit Computeknoten (virtuelle Computer), installiert die Anwendungen, die Sie ausführen möchten, und plant Aufträge für die Ausführung auf den Knoten. Es muss keine Cluster- oder Auftragsplanersoftware installiert, verwaltet oder skaliert werden. Stattdessen nutzen Sie Batch-APIs und -Tools, Befehlszeilenskripts oder das Azure-Portal, um Ihre Aufträge zu konfigurieren, zu verwalten und zu überwachen.
Entwickler können Batch als Plattformdienst verwenden, um SaaS-Anwendungen oder Client-Apps zu erstellen, für die große Mengen von Ausführungen erforderlich sind. Sie können mit Batch beispielsweise einen Dienst zum Ausführen einer Monte Carlo-Risikosimulation für ein Dienstleistungsunternehmen oder einen Dienst zum Verarbeiten einer großen Zahl von Bildern erstellen.
Es fallen keine zusätzlichen Gebühren für die Nutzung von Batch an. Sie zahlen nur für die genutzten zugrunde liegenden Ressourcen, z.B. virtuelle Computer, Speicher und Netzwerk.
Einen Vergleich zwischen Batch und anderen HPC-Lösungsoptionen in Azure finden Sie unter High Performance Computing (HPC) on Azure (High Performance Computing (HPC) in Azure).
Ausführen von parallelen Workloads
Batch funktioniert gut mit intrinsisch parallelen Workloads (auch als „hochgradig parallel“ bezeichnet). Diese Workloads enthalten Anwendungen, die unabhängig voneinander ausgeführt werden und bei denen jede Instanz einen Teil der Arbeit erledigt. Wenn die Anwendungen ausgeführt werden, greifen sie ggf. auf einige gemeinsame Daten zu, aber sie kommunizieren nicht mit anderen Instanzen der Anwendung. Intrinsisch parallele Workloads können daher in großem Umfang ausgeführt werden. Dies richtet sich nach der Menge von Computeressourcen, die für die gleichzeitige Ausführung von Anwendungen verfügbar sind.
Hier sind einige Beispiele für intrinsisch parallele Workloads angegeben, die Sie in Batch einbinden können:
- Modellierung von Finanzrisiken mit Monte Carlo-Simulationen
- VFX- und 3D-Bildrendering
- Bildanalyse und -verarbeitung
- Medientranscodierung
- Analyse genetischer Sequenzen
- Optische Zeichenerkennung (OCR)
- Datenerfassung-/verarbeitung und ETL-Vorgänge
- Softwaretestausführung
Sie können Batch auch verwenden, um eng gekoppelte Workloads auszuführen, bei denen die von Ihnen ausgeführten Anwendungen miteinander kommunizieren müssen und nicht unabhängig ausgeführt werden. Für eng gekoppelte Anwendungen wird normalerweise die MPI-API (Message Passing Interface) verwendet. Sie können Ihre eng gekoppelten Workloads mit Batch per Microsoft-MPI oder Intel-MPI ausführen. Verbessern Sie die Anwendungsleistung mit speziellen HPC-Maßnahmen und GPU-optimierten VM-Größen.
Hier sind einige Beispiele für eng gekoppelte Workloads angegeben:
- FE-Analyse
- Strömungssimulation
- KI-Training mit mehreren Knoten
Viele eng gekoppelte Aufträge können mit Batch parallel ausgeführt werden. Sie können beispielsweise mehrere Simulationen für einen Fall durchführen, in dem eine Flüssigkeit durch ein Rohr mit wechselnden Durchmessern fließt.
Zusätzliche Batch-Funktionen
Batch unterstützt größere Mengen von Renderingworkloads mit Renderingtools wie beispielsweise Autodesk Maya, 3ds Max, Arnold und V-Ray.
Sie können Batch-Aufträge auch im Rahmen eines größeren Azure-Workflows zum Transformieren von Daten ausführen, der mit Tools wie Azure Data Factory verwaltet wird.
Funktionsweise
Ein häufiges Szenario für Batch ist das horizontale Hochskalieren von intrinsisch parallelen Arbeitsschritten, z.B. das Rendern von Bildern für 3D-Szenen, in einem Pool mit Computeknoten. Dieser Pool kann als Ihre „Renderfarm“ dienen, mit der für den Renderauftrag Dutzende, Hunderte oder sogar Tausende von Kernen bereitgestellt werden.
Im folgenden Diagramm sind die Schritte eines gängigen Batch-Workflows dargestellt, bei dem eine Clientanwendung oder ein gehosteter Dienst Batch zum Ausführen einer parallelen Workload verwendet.
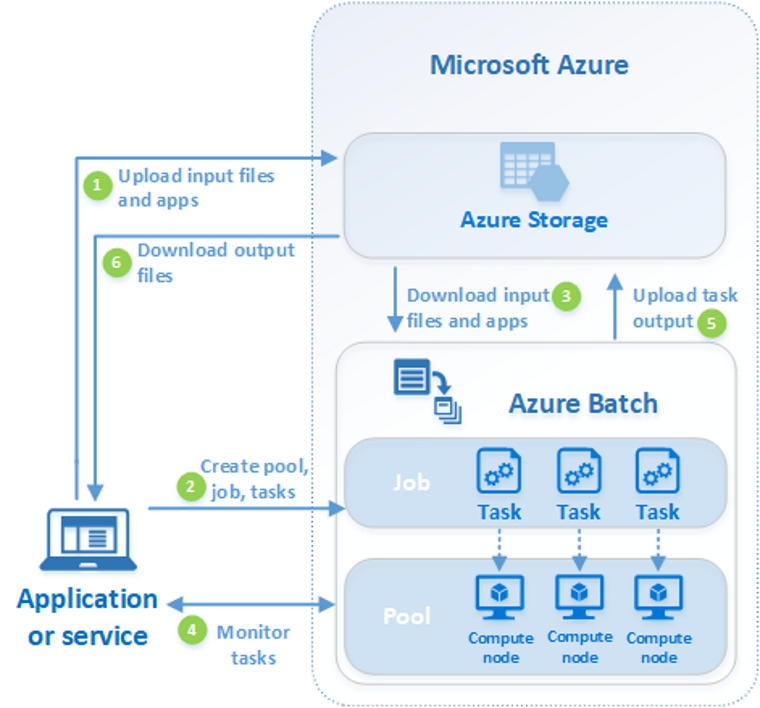
| Schritt | BESCHREIBUNG |
|---|---|
| 1. Laden Sie Eingabedateien und die Anwendungen hoch, um diese Dateien in Ihrem Azure Storage-Konto zu verarbeiten. | Bei den Eingabedateien kann es sich um alle Daten handeln, die von Ihrer Anwendung verarbeitet werden, z.B. Daten für Finanzmodelle oder zu transcodierende Videodateien. Die Anwendungsdateien können Skripts oder Anwendungen enthalten, mit denen die Daten verarbeitet werden, z.B. einen Medien-Transcoder. |
| 2. Erstellen Sie einen Batch-Pool mit Computeknoten in Ihrem Batch-Konto, einen Auftrag zum Ausführen der Workload im Pool und Tasks im Auftrag. | Computeknoten sind die VMs, mit denen Ihre Tasks ausgeführt werden. Geben Sie Eigenschaften für Ihren Pool an, beispielsweise die Anzahl und Größe der Knoten, ein Windows- oder Linux-VM-Image und eine Anwendung, die installiert werden soll, wenn die Knoten dem Pool beitreten. Verwalten Sie die Kosten und die Größe des Pools, indem Sie Azure Spot-VMs verwenden oder die Anzahl der Knoten bei Änderungen der Arbeitslast automatisch skalieren. Wenn Sie einem Auftrag Aufgaben hinzufügen, plant der Batch-Dienst die Aufgaben automatisch für die Ausführung auf den Computeknoten im Pool ein. Jede Aufgabe verwendet die Anwendung, die Sie hochgeladen haben, zum Verarbeiten der Eingabedateien. |
| 3. Herunterladen von Eingabedateien und der Anwendungen in Batch | Vor dem Ausführen der einzelnen Tasks können die Eingabedaten, die verarbeitet werden, auf den zugewiesenen Knoten heruntergeladen werden. Wenn die Anwendung nicht bereits auf den Poolknoten installiert ist, kann sie stattdessen hier heruntergeladen werden. Nachdem die Downloads aus Azure Storage abgeschlossen sind, wird die Aufgabe auf dem zugewiesenen Knoten ausgeführt. |
| 4. Überwachen der Aufgabenausführung | Fragen Sie während der Ausführung der Aufgaben Batch ab, um den Fortschritt des Auftrags und seiner Aufgaben zu überwachen. Ihre Clientanwendung oder Ihr Dienst kommuniziert mit dem Batch-Dienst über HTTPS. Da Sie unter Umständen Tausende von Aufgaben auf Tausenden von Computeknoten überwachen müssen, empfiehlt es sich, den Batch-Dienst möglichst effizient abzufragen. |
| 5. Hochladen der Aufgabenausgabe | Nach Abschluss der Aufgaben können die Ergebnisdaten in Azure Storage hochgeladen werden. Sie können Dateien auch direkt aus dem Dateisystem auf einem Computeknoten abrufen. |
| 6. Herunterladen der Ausgabedateien | Wenn bei der Überwachung erkannt wird, dass die Aufgaben Ihres Auftrags abgeschlossen wurden, kann Ihre Clientanwendung bzw. der Dienst die Ausgabedaten zur weiteren Verarbeitung herunterladen. |
Beachten Sie, dass der oben beschriebene Workflow nur eine Möglichkeit zur Verwendung von Batch ist und es noch viele weitere Features und Optionen gibt. Beispielsweise können Sie auf jedem Computeknoten mehrere Aufgaben parallel ausführen. Alternativ können Sie Tasks für die Vorbereitung und den Abschluss von Aufträgen verwenden, um die Knoten für Ihre Aufträge vorzubereiten, und führen Sie anschließend die Bereinigung durch.
Eine Übersicht über Features wie Pools, Knoten, Aufträge und Tasks finden Sie unter Workflow des Batch-Diensts und Ressourcen. Siehe auch die aktuellen Batchdienstupdates.
Data Residency in der Region
Azure Batch speichert Kundendaten in der Region, in der sie bereitgestellt werden, und verschiebt sie nicht aus dieser Region.
Nächste Schritte
Steigen Sie mit einer der folgenden Schnellstartanleitungen in Azure Batch ein: