Herangehensweise für Machine Learning-Vorgänge
Machine Learning-Vorgänge bestehen aus Prinzipien und bewährten Methoden zur Organisierung und Standardisierung der Entwicklung, Bereitstellung und Wartung von Machine Learning-Modellen auf skalierbare Weise.
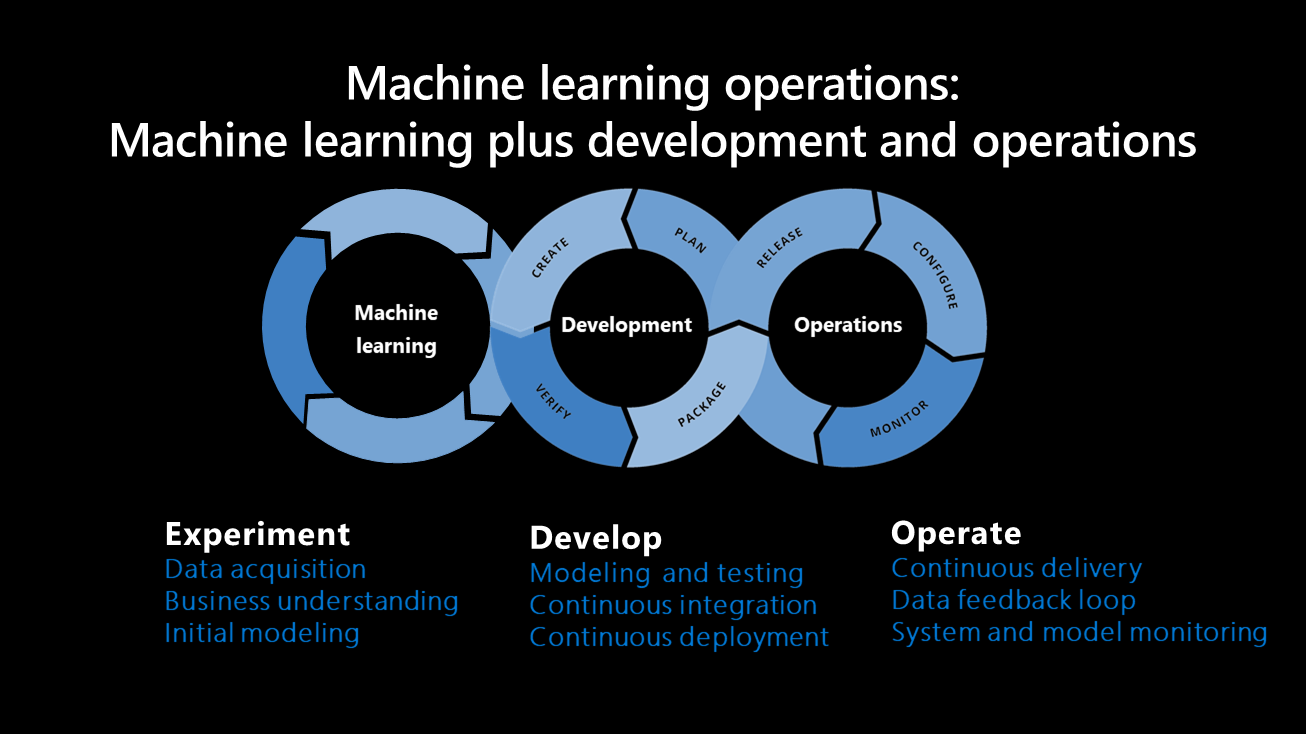
Die Hauptkomponenten der Entwicklung eines Machine Learning-Systems werden im Folgenden beschrieben:
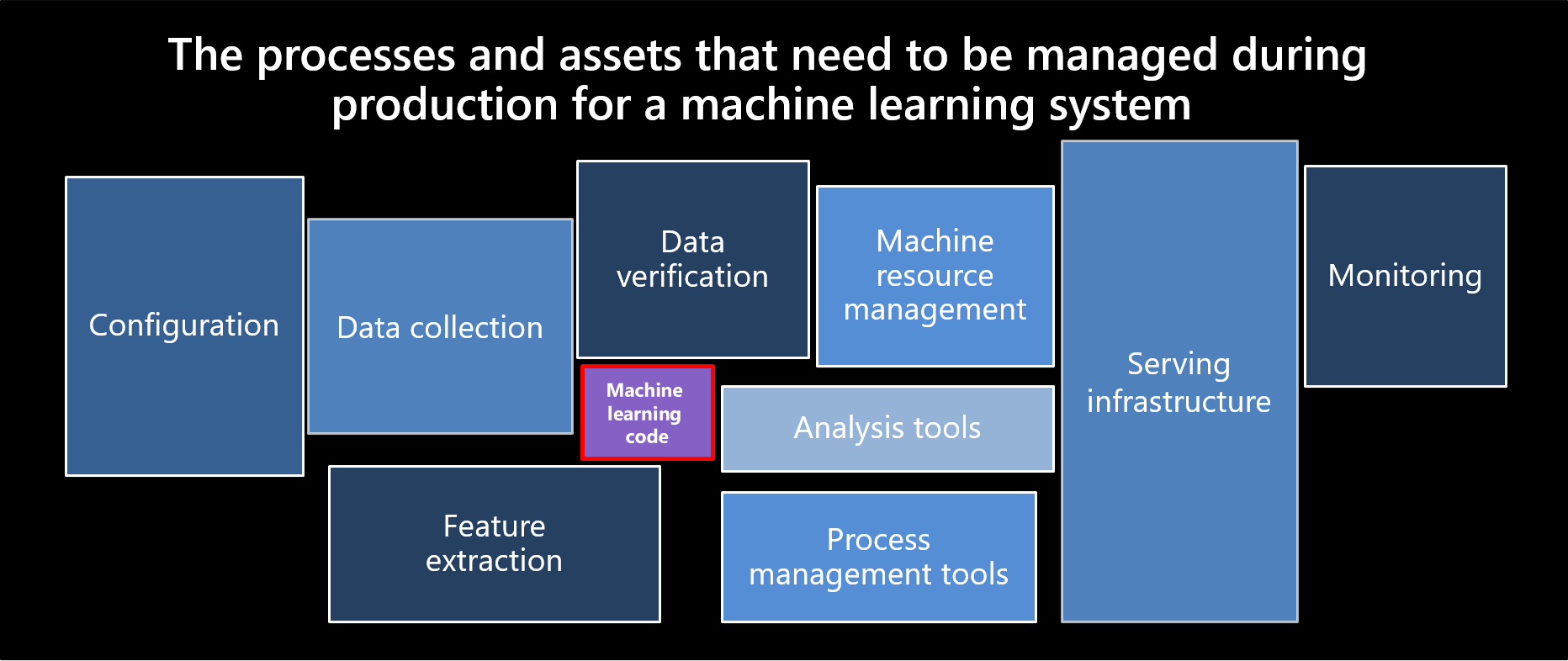
Sculley, et al. 2015. Versteckte technische Schulden in Machine Learning-Systemen. Proceedings of the 28th International Conference on Neural Information Processing Systems, Volume 2 (NIPS 2015).
Machine Learning-Vorgänge im Vergleich zu Entwicklungsvorgängen
Währen Entwicklungsvorgänge (DevOps) sich auf Machine Learning-Vorgänge auswirken, unterscheiden sich ihre Prozesse. Neben DevOps-Praktiken befassen sich Machine Learning-Vorgänge mit den folgenden Konzepten, die nicht in DevOps behandelt werden:
Datenversionsverwaltung: Es muss eine Versionsverwaltung für Code und Datasets vorliegen, da sich das Schema und die tatsächlichen Daten im Laufe der Zeit ändern können. Dies ermöglicht die Reproduktion von Daten, macht die Daten für andere Teammitglieder sichtbar und unterstützt die Überprüfung von Anwendungsfällen.
Modellnachverfolgung: Modellartefakte werden häufig in einer Modellregistrierung gespeichert, die Speicher-, Versionsverwaltungs- und Kennzeichnungsfunktionen identifizieren sollten. Diese Registrierungen müssen den Quellcode, dessen Parameter und die entsprechenden Daten zum Trainieren des Modells identifizieren. All das gibt an, wo das Modell erstellt wurde.
Digitales Überwachungsprotokoll: Beim Arbeiten mit Code und Daten müssen alle Änderungen aufgezeichnet werden.
Generalisierung: Modelle unterscheiden sich hinsichtlich der Wiederverwendung von Code, da Modelle anhand der Eingabedaten oder des Szenarios angepasst werden müssen. Möglicherweise müssen Sie das Modell an neue Daten anpassen, um es für ein neues Szenario zu verwenden.
Neutrainieren von Modellen: Die Modellleistung kann mit der Zeit abnehmen. Es ist wichtig, dass Modelle neu trainiert werden, damit sie nützlich bleiben.
Ansätze für Machine Learning-Vorgänge
Data Scientists in einer Organisation wenden ein breites Spektrum von Erfahrung, Reife, Kenntnissen und Tools an, um mit Machine Learning-Vorgängen zu experimentieren. Da es wichtig ist, möglichst viele Teilnehmer zur Einführung von KI zu ermutigen, ist ein Konsens dazu, wie alle Organisationen an Machine Learning-Vorgänge herangehen sollten, weder wahrscheinlich noch wünschenswert. In Anbetracht dieser Vielfalt besteht ein klarer Ausgangspunkt für Ihre Organisation darin, zu verstehen, wie ihre Größe und Ressourcen sich auf ihre Herangehensweise für Machine Learning-Vorgänge auswirkt.
Die Größe und Reife eines Unternehmens geben an, ob Data Science-Teams oder Einzelpersonen mit eindeutigen Rollen für den Machine Learning-Lebenszyklus zuständig sind und die einzelnen Phasen leiten. Die folgenden Ansätze für den Lebenszyklus sind in jedem Szenario gängig:
Zentralisierter Ansatz
Data Science-Teams überwachen den Machine Learning-Lebenszyklus in kleinen Unternehmen wahrscheinlich mit wenigen Ressourcen und Experten. Dieses Team wendet seine technischen Fachkenntnisse an, um Daten zu bereinigen und zu aggregieren, Modelle zu entwickeln und bereitzustellen und bereitgestellte Modelle zu überwachen und zu warten.
Ein Vorteil dieser Methode besteht darin, dass das Modell schnell in die Produktion übergeht, jedoch steigen die Kosten aufgrund der spezialisierten Fachkenntnisse, über die das Data Science-Team verfügen muss. Die Qualität leidet darunter, wenn diese erforderlichen Fachkenntnisse nicht vorliegen.
Dezentralisierter Ansatz
Einzelpersonen mit spezialisierten Rollen sind wahrscheinlich für den Machine Learning-Lebenszyklus in Unternehmen mit dedizierten Betriebsteams verantwortlich und überwachen diese. Sobald ein Anwendungsfall genehmigt wird, wird ein Machine Learning-Experte zugewiesen, um den aktuellen Zustand und den erforderlichen Arbeitsaufwand zu bewerten, um das Modell auf ein Format zu erweitern, das unterstützt werden kann.
Der Data Scientist muss Informationen zu den folgenden Fragen erörtern:
- Wer ist der Geschäftsinhaber?
- Wie wird das Modell genutzt?
- Welcher Grad an Dienstverfügbarkeit ist erforderlich?
- Wie wird das Modell neu trainiert?
- Wie oft wird das Modell neu trainiert?
- Wer legt die Bedingungen für die Höherstufung des Modells fest?
- Wie vertraulich ist der Anwendungsfall, und kann der Code freigegeben werden?
- Wie werden das Modell und der Code zukünftig bearbeitet?
- Inwiefern ist das aktuelle Experiment wiederverwendbar?
- Liegen hilfreiche Projektworkflows vor?
- Wie viel Arbeitsaufwand ist erforderlich, um das Modell in die Produktion zu bringen?
Als Nächstes entwirft ein Machine Learning-Designer den Workflow und schätzt den erforderlichen Arbeitsaufwand. Eine bewährte Methode besteht darin, Data Scientists in die Erstellung des Workflows miteinzubeziehen. Diese Zeit stellt eine wichtige Möglichkeit dar, sie mit dem endgültigen Repository vertraut zu machen, da Data Scientists häufig in der Zukunft am Anwendungsfall arbeiten.
Profit für Unternehmen durch Machine Learning-Vorgänge
Machine Learning-Vorgänge verbinden herkömmliche Entwicklungsvorgänge, Datenvorgänge und Data Science/KI. Das Verständnis, wie Machine Learning-Vorgänge Ihrem Unternehmen zugutekommen, unterstützt Sie bei Ihrer KI-Journey.
Die Integration von Machine Learning-Vorgängen mit Ihrem Unternehmen kann die folgenden Vorteile bieten:
Die Unternehmensmodellverwaltung optimiert und automatisiert den Lebenszyklus für die Modellentwicklung, das Training, die Bereitstellung und die Operationalisierung. Dadurch können Unternehmen flexibel handeln und auf wiederholbare und verwaltete Weise auf sofortige Anforderungen und Unternehmensänderungen reagieren.
Mithilfe der Modellversionsverwaltung und Datenrealisierung können Unternehmen iterierte und versionierte Modelle generieren, um die Nuancen der Daten oder des bestimmten Anwendungsfalls anzupassen. Dies bietet Flexibilität und Agilität für die Reaktion auf Unternehmensherausforderungen und -änderungen.
Wenn Organisationen ihre Modelle überwachen und verwalten, können sie schnell auf bedeutende Änderungen der Daten oder des Szenarios reagieren. Ein implementiertes Modell kann beispielsweise aufgrund von externen Faktoren oder Änderungen an den zugrunde liegenden Daten extreme Datendrifts aufweisen. Dadurch würden vorherige Modelle unbrauchbar werden, und das aktuelle Modell muss schnellstmöglich neu trainiert werden. Die Genauigkeit und Leistung von Machine Learning-Modellen muss überwacht werden. Dadurch werden Projektbeteiligte gewarnt, wenn sich Änderungen auf die Zuverlässigkeit und Leistung des Modells auswirken, was schnell zu neuem Training und zur Bereitstellung führt.
Angewandte Prozesse der Machine Learning-Vorgänge unterstützen Geschäftsergebnisse, indem schnelle Überprüfungen, Konformität, Governance und die Zugriffssteuerung für den gesamten Entwicklungslebenszyklus ermöglicht werden. Die Modellgenerierung, Datennutzung und Einhaltung gesetzlicher Bestimmungen ist transparent, da Änderungen im Unternehmen stattfinden.
Nächste Schritte
Die KI Business School von Microsoft ist eine Ressource, in der KI erläutert wird. Sie umfasst einen ganzheitlichen Ansatz für die Implementierung, Informationen zu Abhängigkeiten, die über die Technologie hinausgehen, sowie das Fördern langfristiger geschäftlicher Auswirkungen.
Weitere Informationen finden Sie im Artikel zum Prozess für Machine Learning-Vorgänge.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für