Juli 2018
Diese Features und Azure Databricks-Plattformverbesserungen wurden im Juli 2018 veröffentlicht.
Bibliotheks-API unterstützt Python-Wheel-Dateien
31. Juli bis 7. August 2018: Version 2.77
Sie können jetzt mit der Bibliotheken-API Wheel-Bibliotheken installieren. Wenn Sie eine Wheelbibliothek in einem Cluster installieren, auf dem Databricks Runtime 4.2 oder höher ausgeführt wird, sind alle in der setup.py-Datei der Bibliothek angegebenen Abhängigkeiten enthalten. Wenn Sie eine Wheelbibliothek in einem Cluster installieren, auf dem Databricks Runtime 4.1 oder niedriger ausgeführt wird, wird die Datei der PYTHONPATH-Variablen hinzugefügt, ohne die Abhängigkeiten zu installieren.
Export von IPython-Notebooks
31. Juli bis 7. August 2018: Version 2.77
Wenn Sie ein Azure Databricks-Notebook in das IPython Notebook-Format exportieren, sind die Ergebnisse jetzt im Export enthalten.
Von Azure Key Vault unterstützte Geheimnisbereiche
19. bis 24. Juli 2018: Version 2.76
Geheimnisse unterstützen jetzt von einem Azure Key Vault unterstützte Bereiche. Nachdem Sie den Bereich erstellt haben, können Sie auf alle Geheimnisse im entsprechenden Key Vault aus diesem Bereich zugreifen. Weitere Informationen finden Sie unter Erstellen eines von Azure Key Vault unterstützten Geheimnisbereichs
Hinweis
Der von Azure Key Vault unterstützte Geheimnisbereich ist eine schreibgeschützte Schnittstelle zum Key Vault. Um Geheimnisse in Azure Key Vault zu verwalten, müssen Sie die Azure-REST-API SetSecret oder die Benutzeroberfläche des Azure-Portals verwenden.
Premium-Arbeitsbereiche als Testversion
20. bis 24. Juli 2018: Version 2.76
Azure Databricks bietet jetzt Testversionen für Premium-Arbeitsbereiche an. Während einer 14-tägigen Testversion erhalten Sie Zugriff auf kostenlose Azure Databricks DBUs. Weitere Informationen finden Sie unter Erstellen eines Arbeitsbereichs.
Cluster-Modus und Cluster mit hoher Parallelität
19. bis 24. Juli 2018: Version 2.76
Die Option Clustertyp beim Erstellen eines Clusters wurde in Clustermodus umbenannt. Die Option Serverloser Pool wurde durch den Clustermodus Hohe Parallelität ersetzt. Cluster mit hoher Parallelität sind für eine effiziente Ressourcenverwendung, Isolierung, Sicherheit und die beste Leistung bei der gemeinsamen Nutzung durch mehrere gleichzeitig aktive Benutzer optimiert. Ein Cluster mit hoher Parallelität unterstützt ausschließlich SQL, Python und R. Cluster mit hoher Parallelität bieten alle Vorteile serverloser Pools und ermöglichen gleichzeitig Flexibilität bei der Spark- und Ressourcenkonfiguration. Weitere Informationen finden Sie unter Cluster mit hoher Parallelität.
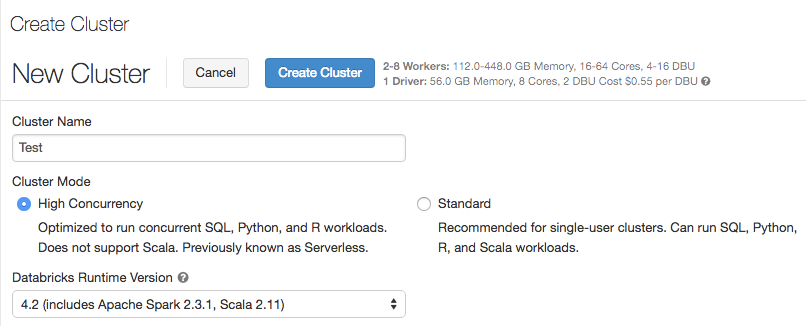
Zugriffssteuerung für Tabellen
19. bis 24. Juli 2018: Version 2.76
Das Kontrollkästchen „Zugriffssteuerung für Tabellen“ ist nur für Cluster mit hoher Parallelität verfügbar.

Nicht verfügbare Clusterknotentypen sind abgeblendet
3. bis 10. Juli 2018: Version 2.75
Clusterknotentypen, die für Ihr Abonnement und Ihre Region nicht verfügbar sind, sind jetzt ausgegraut, und können beim Erstellen eines Clusters nicht ausgewählt werden.
Unterstützung für R Markdown
3. bis 10. Juli 2018: Version 2.75
Azure Databricks R-Notebooks können in das R Markdown-Format exportiert werden, und R Markdown-Dokumente können als Azure Databricks-Notebooks importiert werden.
Überarbeitung der Startseite, Datenimport jetzt durch Drag & Drop von Dateien
3. bis 10. Juli 2018: Version 2.75
Die neue Homepage bietet eine übersichtlichere, einfachere Oberfläche mit Links zu einem verbesserten Erste-Schritte-Tutorial und der Möglichkeit, Dateien per Drag & Drop zu importieren. Weitere Informationen finden Sie unter Erkunden und Erstellen von Tabellen in DBFS.
Widget-Standardverhalten
3. bis 10. Juli 2018: Version 2.75
Das Standardausführungsverhalten, wenn ein neuer Wert für ein Widget ausgewählt wird, ist jetzt Keine Aktion ausführen. Wenn Sie ein komplettes Notebook oder nur wertbezogene Befehle erneut ausführen möchten, wenn Sie einen Widget-Wert ändern, müssen Sie die Widget-Einstellungen aktualisieren. Siehe Konfigurieren von Widget-Einstellungen.
Benutzeroberfläche für die Tabellenerstellung
3. bis 10. Juli 2018: Version 2.75
Wenn Sie eine Tabelle in der Benutzeroberfläche erstellen, wählen Sie jetzt auf der Seite Daten die Option Daten hinzufügen.
![]()
Weitere Informationen finden Sie unter Erkunden und Erstellen von Tabellen in DBFS.
Mehrzeiliger JSON-Datenimport
3. bis 10. Juli 2018: Version 2.75
Sie können beim Erstellen von Tabellen jetzt mehrzeilige JSON-Dateien importieren. Zuvor mussten JSON-Datendateien auf eine Zeile vereinfacht werden. Weitere Informationen finden Sie unter Erkunden und Erstellen von Tabellen in DBFS.