Oktober 2019
Diese Features und Azure Databricks-Plattformverbesserungen wurden im Oktober 2019 veröffentlicht.
Hinweis
Releases werden gestaffelt. Ihr Azure Databricks-Konto wird möglicherweise erst eine Woche nach dem Datum der ersten Veröffentlichung aktualisiert.
Metrik zur Unterstützbarkeit in Azure Event Hubs verschoben
22. bis 29. Oktober 2019
Die Metrik zur Unterstützbarkeit, die es Azure Databricks ermöglicht, den Zustand des Clusters zu überwachen, wurde von Azure Blob Storage zu Event Hub-Endpunkten migriert. Dies ermöglicht Azure Databricks eine geringere Latenzzeit bei der Lösung von Kundenvorfällen. Für Arbeitsbereiche mit VNet-Einschleusung haben wir eine zusätzliche Regel zur Netzwerksicherheitsgruppe für den EventHubDienstendpunkt hinzugefügt. Details finden Sie in der Tabelle Netzwerksicherheitsgruppen-Regeln. Es besteht kein Handlungsbedarf für eine fortgesetzte Verfügbarkeit der Dienste.
Eine Liste der Metriken zur Unterstützbarkeit von Azure Databricks Event Hubs-Endpunkten nach Region finden Sie unter Metastore, Artefakt-Blob-Speicher, Systemtabellenspeicher, Log-Blob-Speicher und Event Hub-Endpunkt-IP-Adressen.
Der Passthrough für Azure Data Lake Storage-Anmeldeinformationen auf Standardclustern und in Scala ist jetzt allgemein verfügbar.
22. bis 29. Oktober 2019: Version 3.5
Passthrough für Anmeldeinformationen für Python, SQL und Scala auf Standardclustern mit Databricks Runtime 5.5 und höher sowie für SparkR auf Databricks Runtime 6.0 und höher ist allgemein verfügbar. Siehe Aktivieren des Passthroughs für Anmeldeinformationen in Azure Data Lake Storage für einen Standardcluster.
Allgemeine Verfügbarkeit von Databricks Runtime 6.1 für Genomics
22. Oktober 2019
Databricks Runtime 6.1 für Genomics ist allgemein verfügbar.
Allgemeine Verfügbarkeit von Databricks Runtime 6.1 für Machine Learning
22. Oktober 2019
Databricks Runtime 6.1 ML ist allgemein verfügbar. Es schließt Unterstützung für GPU-Cluster und Upgrades auf die folgenden Machine Learning-Bibliotheken ein:
- TensorFlow auf 1.14.0
- PyTorch auf 1.2.0
- Torchvision auf 0.4.0
- MLflow auf 1.3.0
Weitere Informationen finden Sie in den vollständigen Versionshinweisen zu Databricks Runtime 6.1 für ML (nicht unterstützt).
Für MLflow-API-Aufrufe gelten jetzt Ratenbeschränkungen.
22. bis 29. Oktober 2019: Version 3.5
Azure Databricks erzwingt eine Begrenzung der API-Datenübertragungsrate für MLflow-API-Aufrufe, um bei starker Auslastung eine hohe Dienstqualität sicherzustellen. Die Grenzwerte werden pro Konto festgelegt, um eine angemessene Nutzung und Hochverfügbarkeit für alle Organisationen sicherzustellen, die einen Arbeitsbereich gemeinsam nutzen.
Die MLflow-Clients mit automatischen Wiederholungen sind in MLflow 1.3.0 verfügbar und befinden sich in Databricks Runtime 6.1 für ML (nicht unterstützt). Wir empfehlen allen Kunden, zur aktuellen MLflow-Clientversion zu wechseln.
Weitere Informationen finden Sie unter Experiment-API.
Instanzpools für schnelle Clusterstarts allgemein verfügbar
22. bis 29. Oktober 2019: Version 3.5
Das Azure Databricks-Feature, das das Anfügen eines Clusters an einen vordefinierten Leerlaufinstanzpool unterstützt, ist jetzt allgemein verfügbar.
Solange sich Instanzen im Pool im Leerlauf befinden, werden in Azure Databricks keine DBU-Stunden berechnet. Abrechnung des Instanzenanbieters gilt. Siehe Preise.
Ausführliche Informationen finden Sie unter Poolkonfigurationsreferenz.
Databricks Runtime 6.1 GA
16. Oktober 2019
Databricks Runtime 6.1 bietet mehrere Verbesserungen für Delta Lake:
- Einfaches Konvertieren von Tabellen in das Delta Lake-Format
- Python-APIs für Delta-Tabellen (Public Preview)
- Dynamische Dateibereinigung (Dynamic File Pruning, DFP) ist standardmäßig aktiviert
Databricks Runtime 6.1 hebt auch mehrere Einschränkungen beim Passthrough für Anmeldeinformationen auf
Hinweis
Ab Version 6.1 unterstützt Databricks Runtime nur CPU-Cluster. Wenn Sie GPU-Cluster verwenden möchten, müssen Sie Databricks Runtime ML verwenden.
Weitere Informationen finden Sie in den vollständigen Versionshinweisen zu Databricks Runtime 6.1 (nicht unterstützt).
Allgemeine Verfügbarkeit von Databricks Runtime 6.0 für Genomics
16. Oktober 2019
Databricks Runtime für Genomics (Databricks Runtime Genomics) ist eine Variante von Databricks Runtime, die für die Arbeit mit Genomdaten und biomedizinischen Daten optimiert ist. Ab Version 6.0 ist Databricks Runtime für Genomics allgemein verfügbar.
Die Möglichkeit, einen Azure Databricks-Arbeitsbereich im eigenen virtuellen Netzwerk bereitzustellen (auch bekannt als VNet-Einschleusung), ist allgemein verfügbar.
9. Oktober 2019
Wir freuen uns, bekanntgeben zu können, dass die Möglichkeit einen Azure Databricks-Arbeitsbereich in Ihrem eigenen virtuellen Netzwerk zu implementieren, auch bekannt als VNet-Einschleusung, nun allgemein verfügbar ist. Diese Option ist für diejenigen unter Ihnen gedacht, die eine Netzwerkanpassung benötigen und daher nicht das Standard-VNet verwenden möchten, das bei der standardmäßigen Bereitstellung eines Azure Databricks-Arbeitsbereichs erstellt wird. Die VNET-Einschleusung gibt Ihnen folgende Möglichkeiten:
- Sicheres Verbinden von Azure Databricks mit anderen Azure-Diensten (z.B. Azure Storage) über Dienstendpunkte.
- Verbinden mit lokalen Datenquellen zur Verwendung mit Azure Databricks unter Verwendung von benutzerdefinierten Routen
- Verbinden von Azure Databricks mit einem virtuellen Netzwerkgerät, um den ausgehenden Datenverkehr zu untersuchen und anhand von Zulassungs- und Ablehnungsregeln Maßnahmen zu ergreifen.
- Konfigurieren von Azure Databricks zur Verwendung eines benutzerdefinierten DNS.
- Konfigurieren von Netzwerksicherheitsgruppen-Regeln (NSG-Regeln), um Einschränkungen für ausgehenden Datenverkehr zu definieren
- Bereitstellen von Azure Databricks-Clustern in Ihrem vorhandenen virtuellen Netzwerk.
Durch die Bereitstellung von Azure Databricks in Ihrem eigenen virtuellen Netzwerk können Sie auch die Vorteile flexibler CIDR-Bereiche nutzen (an einer beliebigen Stelle zwischen /16-/24 für das virtuelle Netzwerk und bis zu /26 für die Subnetze).
Die Konfiguration mithilfe der Azure-Portal-Benutzeroberfläche ist schnell und einfach: Wenn Sie einen Arbeitsbereich erstellen, wählen Sie einfach Deploy Azure Databricks workspace in your Virtual Network (Azure Databricks-Arbeitsbereich in Ihrem virtuellen Netzwerk bereitstellen) aus, wählen Ihr virtuelles Netzwerk und geben CIDR-Bereiche für zwei Subnetze an. Azure Databricks aktualisiert das virtuelle Netzwerk mit den zwei neuen Subnetzen und Netzwerksicherheitsgruppen, erlaubt Zugriff für den eingehenden und ausgehenden Subnetzverkehr, und stellt den Arbeitsbereich für das aktualisierte virtuelle Netzwerk bereit.
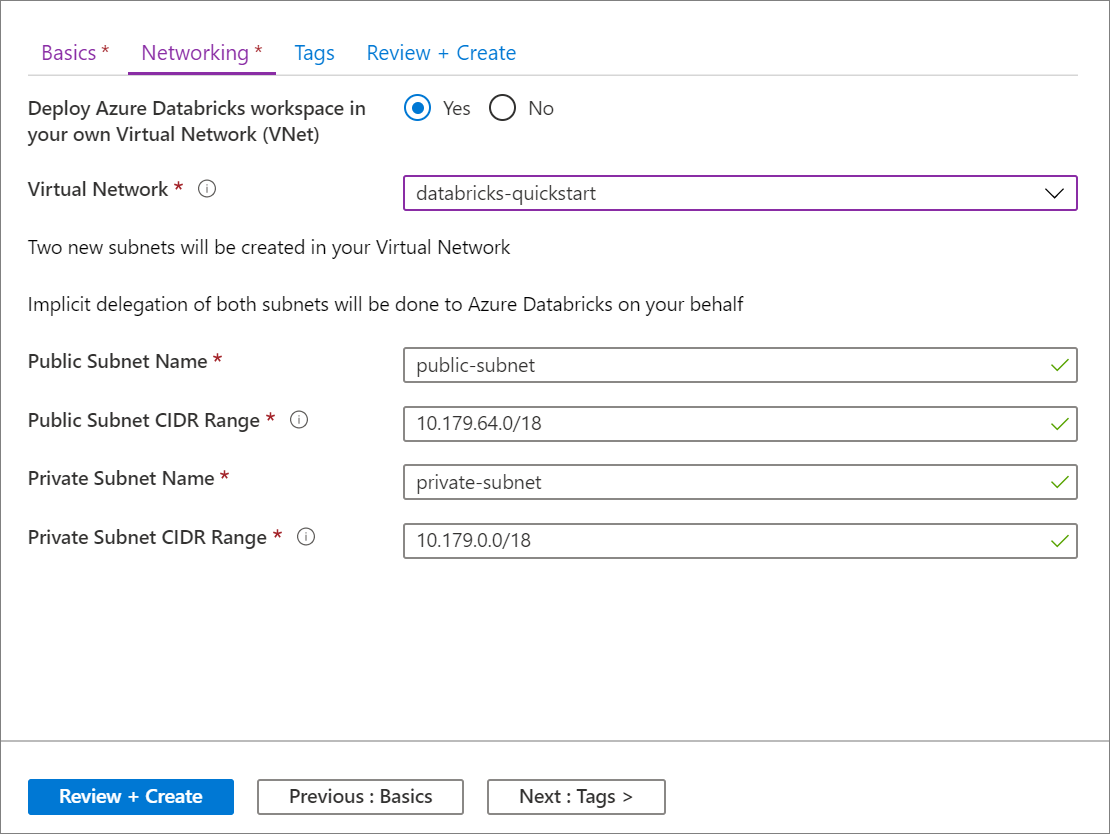
Wenn Sie das virtuelle Netzwerk für die VNet-Einschleusung lieber selbst konfigurieren möchten, z. B. wenn Sie vorhandene Subnetze verwenden, vorhandene Netzwerksicherheitsgruppen nutzen oder eigene Sicherheitsregeln erstellen möchten, können Sie die von Azure Databricks bereitgestellten ARM-Vorlagen anstelle der Portal-Benutzeroberfläche verwenden.
Hinweis
Wenn Sie die Vorschauversion der VNET-Einschleusung benutzt haben, müssen Sie ihren Vorschauarbeitsbereich vor dem 31. Januar 2020 auf die allgemein verfügbare Version aktualisieren, um weiterhin Support zu erhalten.
Weitere Informationen finden Sie unter Bereitstellen von Azure Databricks in Ihrem virtuellen Azure-Netzwerk (VNET-Einschleusung) und Verbinden Ihres Azure Databricks-Arbeitsbereichs in Ihrem lokalen Netzwerk.
Azure Databricks-Benutzer, die keine Administratoren sind, können Benutzer- und Gruppennamen sowie IDs mithilfe der SCIM-API lesen.
8. bis 15. Oktober 2019: Version 3.4
Benutzer, die keine Administratoren sind, können jetzt die Gruppen-API-Endpunkte „Benutzer abrufen“ und „Gruppen abrufen“ aufrufen, um Lesezugriff auf die Anzeigenamen und IDs von Benutzern und Gruppen zu erhalten. Alle anderen SCIM-API-Vorgänge erfordern weiterhin Administratorzugriff.
Arbeitsbereichs-API gibt Notebook- und Ordnerobjekt-IDs zurück
8. bis 15. Oktober 2019: Version 3.4
Die Endpunkte get-status und list der Arbeitsbereich-API geben jetzt Notebook- und Ordnerobjekt-IDs zurück, so dass Sie in anderen API-Aufrufen auf diese Objekte verweisen können.
Databricks Runtime 6.0 ML GA
4. Oktober 2019
Databricks Runtime 6.0 ML enthält die folgenden Updates:
- MLflow
- Eine neue Spark-Datenquelle für MLflow-Experimente bietet jetzt eine Standard-API zum Laden von MLflow-Experimentlaufdaten.
- MLflow-Java-Client hinzugefügt
- MLflow wird jetzt als Bibliothek der obersten Ebene heraufgestuft
- Allgemeine Verfügbarkeit von Hyperopt: Wichtige Verbesserungen seit der öffentlichen Vorschau umfassen die Unterstützung der MLflow-Protokollierung für Spark-Worker, die richtige Verarbeitung von PySpark-Broadcastvariablen sowie einen neuen Leitfaden zur Modellauswahl mit Hyperopt.
- Horovod- und MLflow-Bibliotheken und Anaconda-Verteilung wurden aktualisiert.
Hinweis
In dieser Version werden nur CPU-Cluster unterstützt.
Weitere Informationen finden Sie in den vollständigen Versionshinweisen zu Databricks Runtime 6.0 für ML (nicht unterstützt).
Neue Regionen: „Brasilien, Süden“ und „Frankreich, Mitte“
1\. Oktober 2019
Azure Databricks ist jetzt in „Brasilien, Süden“ (São Paulo, Bundesstaat) und „Frankreich, Mitte“ (Paris) verfügbar.
Databricks Runtime 6.0 GA
1\. Oktober 2019
Databricks Runtime 6.0 bietet viele Bibliotheksupgrades und neue Features, einschließlich:
- Neue Scala- und Java-APIs für Delta Lake DML-Befehle sowie die Hilfsprogrammbefehle „vacuum“ und „history“.
- Erweiterter DBFS FUSE-Client für schnellere und zuverlässigere Lese- und Schreibvorgänge während des Modelltrainings.
- Unterstützung für mehrere matplotlib-Plots pro Notebookzelle.
- Update auf Python 3.7, sowie Updates für numpy, pandas, matplotlib und andere Bibliotheken.
- Ende des Python 2-Supports.
Hinweis
In dieser Version werden nur CPU-Cluster unterstützt.
Weitere Informationen finden Sie in den vollständigen Versionshinweisen zu Databricks Runtime 6.0 (nicht unterstützt).