Verwenden von strukturiertem Apache Spark-Streaming mit Apache Kafka und Azure Cosmos DB
Erfahren Sie, wie Sie strukturiertesApache Spark-Streaming verwenden, um Daten aus Apache Kafka in Azure HDInsight zu lesen und dann in Azure Cosmos DB zu speichern.
Azure Cosmos DB ist eine global verteilte Datenbank mit Unterstützung mehrerer Modelle. In diesem Beispiel wird ein Azure Cosmos DB for NoSQL-Datenbankmodell verwendet. Weitere Informationen finden Sie im Dokument Willkommen bei Azure Cosmos DB.
Strukturiertes Spark-Streaming ist eine auf Spark SQL basierende Stream-Verarbeitungs-Engine. Sie können damit Streamingberechnungen genauso wie Batchberechnung auf statischen Daten ausdrücken. Weitere Informationen zu strukturiertem Streaming finden Sie unter Structured Streaming Programming Guide (Programmierhandbuch zu strukturiertem Streaming) auf Apache.org.
Wichtig
In diesem Beispiel wird Spark 2.4 auf HDInsight 4.0 verwendet.
Mit den in diesem Dokument beschriebenen Schritten wird eine Azure-Ressourcengruppe erstellt, die jeweils einen Spark- und einen Kafka-Cluster in HDInsight beinhaltet. Die Cluster befinden sich innerhalb eines virtuellen Azure-Netzwerks, wodurch Spark- und Kafka-Cluster direkt miteinander kommunizieren können.
Denken Sie nach dem Ausführen der Schritte in diesem Dokument daran, die Cluster zu löschen, um das Anfallen von Gebühren zu verhindern.
Erstellen von Clustern
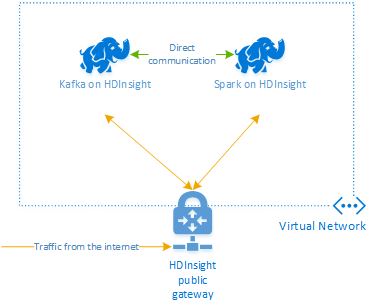
Apache Kafka in HDInsight ermöglicht keinen Zugriff auf die Kafka-Broker über das öffentliche Internet. Komponenten, die mit Kafka kommunizieren, müssen sich jeweils im selben virtuellen Azure-Netzwerk befinden wie die Knoten im Kafka-Cluster. Für dieses Beispiel sind die Kafka- und Spark-Cluster in einem virtuellen Azure-Netzwerk angeordnet. Im folgenden Diagramm ist dargestellt, wie der Kommunikationsfluss zwischen den Clustern abläuft:
Hinweis
Der Kafka-Dienst ist auf die Kommunikation innerhalb des virtuellen Netzwerks beschränkt. Auf andere Dienste auf dem Cluster, wie z.B. SSH und Ambari, kann über das Internet zugegriffen werden. Weitere Informationen zu den öffentlichen Ports, die für HDInsight verfügbar sind, finden Sie unter Von HDInsight verwendete Ports und URIs.
Es ist zwar möglich, ein virtuelles Azure-Netzwerk, einen Kafka-Cluster und einen Spark-Cluster manuell zu erstellen, aber mit einer Azure Resource Manager-Vorlage ist dies erheblich einfacher. Führen Sie die folgenden Schritte aus, um ein virtuelles Azure-Netzwerk, Kafka- und Spark-Cluster für Ihr Azure-Abonnement bereitzustellen.
Verwenden Sie die folgende Schaltfläche, um sich bei Azure anzumelden, und öffnen Sie die Vorlage im Azure-Portal.

Die Azure Resource Manager-Vorlage befindet sich im GitHub-Repository für dieses Projekt (https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb).
Diese Vorlage erstellt die folgenden Ressourcen:
Ein Kafka-auf-HDInsight-4.0-Cluster.
Ein Spark-auf-HDInsight-4.0-Cluster.
Ein Azure Virtual Network, das die HDInsight-Cluster enthält. Das von der Vorlage erstellte virtuelle Netzwerk verwendet den 10.0.0.0/16-Adressraum.
Eine Azure Cosmos DB for NoSQL-Datenbank.
Wichtig
Das in diesem Beispiel verwendete Notebook für strukturiertes Streaming benötigt Spark auf HDInsight 4.0. Bei Verwendung einer früheren Version von Spark auf HDInsight erhalten Sie Fehlermeldungen, wenn Sie das Notebook verwenden.
Verwenden Sie die folgenden Informationen, um die Einträge auf dem Abschnitt Benutzerdefinierte Bereitstellung aufzufüllen:
Eigenschaft Wert Subscription Wählen Sie Ihr Azure-Abonnement. Resource group Erstellen Sie eine Gruppe, oder wählen Sie eine vorhandene Gruppe aus. Diese Gruppe enthält den HDInsight-Cluster. Azure Cosmos DB-Kontoname Dieser Wert wird als Name für das Azure Cosmos DB-Konto verwendet. Der Name darf nur Kleinbuchstaben, Zahlen und den Bindestrich (-) enthalten. Sie muss zwischen drei und 31 Zeichen lang sein. Basisclustername Dieser Wert wird als Basisname für Spark- und Kafka-Cluster verwendet. Wenn Sie beispielsweise myhdi eingeben, werden ein Spark-Cluster mit dem Namen spark-myhdi und ein Kafka-Cluster mit dem Namen kafka-myhdi erstellt. Clusterversion Die HDInsight-Clusterversion. Dieses Beispiel wird mit HDInsight 4.0 getestet und funktioniert möglicherweise nicht mit anderen Clustern. Benutzername für Clusteranmeldung Der Administratorbenutzername für die Spark- und Kafka-Cluster. Kennwort für Clusteranmeldung Das Administratorbenutzerkennwort für die Spark- und Kafka-Cluster. SSH-Benutzername SSH-Benutzer, der für die Spark- und Kafka-Cluster erstellt wird. SSH-Kennwort Kennwort für den SSH-Benutzer für die Spark- und Kafka-Cluster. 
Lesen Sie die Geschäftsbedingungen, und wählen Sie anschließend die Option Ich stimme den oben genannten Geschäftsbedingungen zu.
Wählen Sie abschließend Kaufen aus. Das Erstellen des Clusters, des virtuellen Netzwerks und des Azure Cosmos DB-Kontos kann bis zu 45 Minuten dauern.
Erstellen der Azure Cosmos DB-Datenbank und -Sammlung
Das in diesem Dokument verwendete Projekt speichert Daten in Azure Cosmos DB. Bevor Sie den Code ausführen, müssen Sie zuerst eine Datenbank und Sammlung in Ihrer Azure Cosmos DB-Instanz erstellen. Sie müssen auch den Dokumentendpunkt abrufen und den Schlüssel, der zum Authentifizieren von Anforderungen an Azure Cosmos DB verwendet wird.
Hierfür bietet sich die Azure CLI an. Das folgende Skript erstellt eine Datenbank namens kafkadata und eine Sammlung mit dem Namen kafkacollection. Anschließend gibt sie den primären Schlüssel zurück.
#!/bin/bash
# Replace 'myresourcegroup' with the name of your resource group
resourceGroupName='myresourcegroup'
# Replace 'mycosmosaccount' with the name of your Azure Cosmos DB account name
name='mycosmosaccount'
# WARNING: If you change the databaseName or collectionName
# then you must update the values in the Jupyter Notebook
databaseName='kafkadata'
collectionName='kafkacollection'
# Create the database
az cosmosdb sql database create --account-name $name --name $databaseName --resource-group $resourceGroupName
# Create the collection
az cosmosdb sql container create --account-name $name --database-name $databaseName --name $collectionName --partition-key-path "/my/path" --resource-group $resourceGroupName
# Get the endpoint
az cosmosdb show --name $name --resource-group $resourceGroupName --query documentEndpoint
# Get the primary key
az cosmosdb keys list --name $name --resource-group $resourceGroupName --type keys
Dokumentendpunkt und Primärschlüsselinformationen entsprechen folgendem Text:
# endpoint
"https://mycosmosaccount.documents.azure.com:443/"
# key
"YqPXw3RP7TsJoBF5imkYR0QNA02IrreNAlkrUMkL8EW94YHs41bktBhIgWq4pqj6HCGYijQKMRkCTsSaKUO2pw=="
Wichtig
Speichern Sie den Endpunkt und die Schlüsselwerte, da sie in den Jupyter Notebooks benötigt werden.
Abrufen der Notebooks
Den Code für das in diesem Dokument beschriebene Beispiel finden Sie unter https://github.com/Azure-Samples/hdinsight-spark-scala-kafka-cosmosdb.
Hochladen der Notebooks
Befolgen Sie die folgenden Schritte, um die Notebooks aus dem Projekt auf Ihr Spark auf HDInsight-Cluster hochzuladen:
Verbinden Sie in Ihrem Webbrowser das Jupyter Notebook mit Ihrem Spark-Cluster. Ersetzen Sie in der folgenden URL
CLUSTERNAMEdurch den Namen Ihres Spark-Clusters:https://CLUSTERNAME.azurehdinsight.net/jupyterGeben Sie bei Aufforderung den Clusterbenutzernamen (Administrator) und das Kennwort ein, den bzw. das Sie beim Erstellen des Clusters verwendet haben.
Klicken Sie oben rechts auf der Seite auf die Schaltfläche Hochladen, um die Datei Stream-taxi-data-to-kafka.ipynb auf den Cluster hochzuladen. Wählen Sie Öffnen, um das Hochladen zu starten.
Suchen Sie in der Liste der Notebooks nach dem Eintrag Stream-taxi-data-to-kafka.ipynb, und klicken Sie auf die Schaltfläche Hochladen neben dem Eintrag.
Wiederholen Sie die Schritte 1–3, um das Notebook Stream-data-from-Kafka-to-Cosmos-DB.ipynb zu laden.
Laden von Taxidaten in Kafka
Nachdem die Dateien hochgeladen wurden, wählen Sie den Eintrag Stream-taxi-data-to-kafka.ipynb, um das Notebook zu öffnen. Befolgen Sie die Schritte im Notebook, um Daten in Kafka zu laden.
Verarbeiten von Taxidaten mithilfe von strukturiertem Spark-Streaming
Wählen Sie auf der Startseite Jupyter Notebook den Eintrag Stream-data-from-Kafka-to-Cosmos-DB.ipynb aus. Befolgen Sie die Schritte im Notebook, um Daten mithilfe des strukturierten Spark-Streamings aus Kafka in Azure Cosmos DB zu streamen.
Nächste Schritte
Nachdem Sie jetzt wissen, wie Sie strukturiertes Apache Spark-Streaming verwenden, finden Sie in den folgenden Dokumenten weitere Informationen zum Arbeiten mit Apache Spark, Apache Kafka und Azure Cosmos DB: