Verwenden der Apache Ambari-Hive-Ansicht mit Apache Hadoop in HDInsight
In diesem Artikel wird das folgende Thema erläutert: Ausführen von Apache Hive-Abfragen mithilfe der Ambari-Hive-Ansicht. In der Hive-Ansicht können Sie Hive-Abfragen direkt in Ihrem Webbrowser erstellen, optimieren und ausführen.
Voraussetzungen
Einen Hadoop-Cluster in HDInsight. Weitere Informationen finden Sie unter Erste Schritte mit HDInsight unter Linux.
Ausführen einer Hive-Abfrage
Wählen Sie im Azure-Portal Ihren Cluster aus. Anweisungen dazu finden Sie unter Auflisten und Anzeigen von Clustern. Der Cluster wird in einer neuen Portalansicht geöffnet.
Wählen Sie aus Clusterdashboards die Option Ambari-Ansichten aus. Wenn Sie aufgefordert werden, sich zu authentifizieren, verwenden Sie den Kontonamen und das Kennwort der Clusteranmeldung (standardmäßig
admin), die Sie bei der Erstellung des Clusters angegeben haben. Sie können auch zuhttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsin Ihrem Browser navigieren, wobeiCLUSTERNAMEder Name Ihres Clusters ist.Wählen Sie aus der Liste der Ansichten die Hive-Ansicht aus.
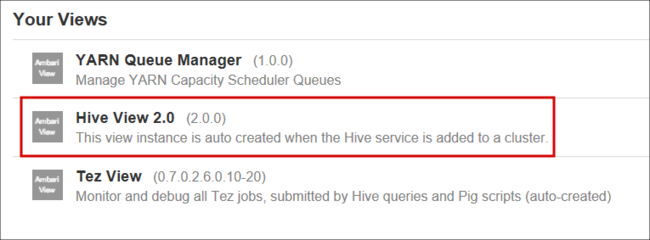
Die Seite „Hive-Ansicht“ ähnelt der folgenden Abbildung:
Kopieren Sie folgende HiveQL-Anweisungen aus der Registerkarte Query (Abfrage) in das Arbeitsblatt:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Diese Anweisungen führen die folgenden Aktionen aus:
-Anweisung. BESCHREIBUNG DROP TABLE Löscht Tabelle und Datendatei, falls die Tabelle bereits existiert. CREATE EXTERNAL TABLE Erstellt eine neue „externe“ Tabelle in Hive. Externe Tabellen speichern nur die Tabellendefinition in Hive. Die Daten verbleiben an ihrem ursprünglichen Speicherort. ROW FORMAT Gibt an, wie die Daten formatiert werden. In diesem Fall werden die Felder in den einzelnen Protokollen durch Leerzeichen getrennt. STORED AS TEXTFILE LOCATION Zeigt den Speicherort für die Daten an, und dass sie als Text gespeichert sind. SELECT Wählt die Anzahl aller Zeilen aus, bei denen die Spalte t4 den Wert [ERROR] enthält. Wichtig
Belassen Sie die Auswahl der Database (Datenbank) bei default (Standard). Die Beispiele in diesem Dokument verwenden die Standarddatenbank, die in HDInsight enthalten ist.
Wählen Sie zum Starten der Abfrage Execute (Ausführen) unter dem Arbeitsblatt aus. Die Schaltfläche wird nun orange angezeigt, und der Text ändert sich in Stop (Beenden).
Nach Abschluss der Abfrage werden in der Registerkarte Results (Ergebnisse) die Ergebnisse des Vorgangs angezeigt. Der folgende Text ist das Ergebnis der Abfrage:
loglevel count [ERROR] 3Sie können auf der Registerkarte LOG die vom Auftrag erstellten Protokollinformationen anzeigen.
Tipp
Laden Sie die Ergebnisse aus dem Dropdown-Dialogfeld Aktionen unter der Registerkarte Ergebnisse herunter oder speichern Sie sie.
Visuelle Erläuterung
Klicken Sie auf die Registerkarte Visual Explain (Visuelle Erläuterung) unter dem Arbeitsblatt, um eine Visualisierung des Abfrageplans anzuzeigen.
Die Ansicht Visuelle Erläuterung der Abfrage kann das Verständnis des Ablaufs komplexer Abfragen erleichtern.
Tez-Benutzeroberfläche
Klicken Sie auf die Registerkarte Tez UI unter dem Arbeitsblatt, um die Tez-Benutzeroberfläche für die Abfrage anzuzeigen.
Wichtig
Tez wird nicht für die Auflösung aller Abfragen verwendet. Viele Abfragen können ohne Tez aufgelöst werden.
Auftragsverlauf anzeigen
Die Registerkarte Jobs (Aufträge) zeigt einen Verlauf der Hive-Abfragen an.
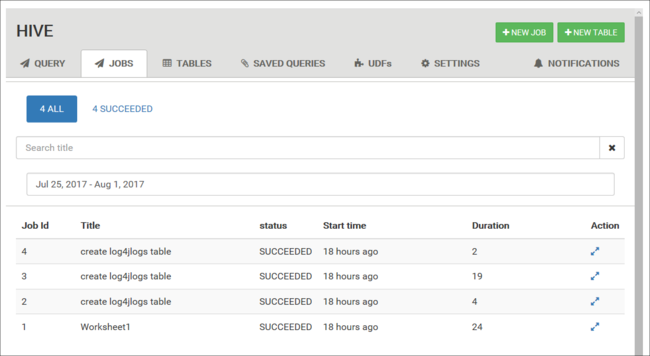
Datenbanktabellen
Sie können die Registerkarte Tables (Tabellen) verwenden, um innerhalb einer Hive-Datenbank mit Tabellen zu arbeiten.
Gespeicherte Abfragen
In der Registerkarte Query können Sie optional auch Abfragen speichern. Nachdem Sie eine Abfrage gespeichert haben, können Sie diese von der Registerkarte Saved Queries aus wiederverwenden.
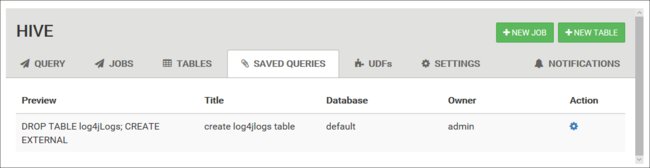
Tipp
Gespeicherte Abfragen werden im Standard-Clusterspeicher gespeichert. Sie finden die gespeicherten Abfragen im Pfad /user/<username>/hive/scripts. Diese werden als Textdateien vom Typ .hql gespeichert.
Wenn Sie den Cluster löschen, den Speicher jedoch beibehalten, können Sie die Abfragen mit einem Hilfsprogramm wie Azure Storage-Explorer oder Data Lake Storage-Explorer (aus dem Azure-Portal) abrufen.
Benutzerdefinierte Funktionen
Sie können Hive über benutzerdefinierte Funktionen (UDF) erweitern. Mit einer UDF-Datei können Sie Funktionen oder Logik implementieren, die sich nicht einfach in HiveQL modellieren lässt.
Deklarieren und speichern Sie eine Gruppe von UDFs mit der Registerkarte UDF ganz oben in der Hive-Ansicht. Diese UDFs können im Abfrage-Editor verwendet werden.
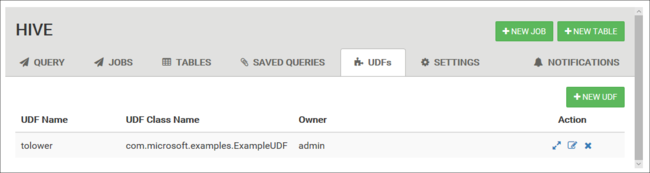
Am unteren Rand des Abfrage-Editors wird die Schaltfläche UDFs einfügen angezeigt. Durch diesen Eintrag wird eine Dropdownliste mit den UDFs angezeigt, die in der Hive-Ansicht definiert sind. Durch das Auswählen einer UDF werden Ihrer Abfrage HiveQL-Anweisungen hinzugefügt, um die UDF zu aktivieren.
Beispielsweise können Sie eine UDF mit den folgenden Eigenschaften definieren:
Ressourcenname: myudfs
Ressourcenpfad: /myudfs.jar
UDF-Name: myawesomeudf
UDF-Klassenname: com.myudfs.Awesome
Mit der Schaltfläche Insert udfs wird ein Eintrag mit dem Namen myudfs angezeigt, der über eine weitere Dropdownliste für jede UDF verfügt, die für diese Ressource definiert ist. In diesem Fall ist das myawesomeudf. Wenn Sie diesen Eintrag auswählen, wird am Anfang der Abfrage Folgendes hinzugefügt:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Sie können die UDF dann in Ihrer Abfrage verwenden. Beispiel: SELECT myawesomeudf(name) FROM people;.
Weitere Informationen zur Verwendung von UDFs mit Hive unter HDInsight finden Sie in den folgenden Artikeln:
- Verwenden von Python mit Apache Hive und Apache Pig in Azure HDInsight
- Verwenden einer benutzerdefinierten Java-Funktion mit Apache Hive in HDInsight
Hive-Einstellungen
Sie können verschiedene Hive-Einstellungen ändern, z.B. die Ausführungs-Engine für Hive von Tez (Standard) in MapReduce.
Nächste Schritte
Allgemeine Informationen zu Hive in HDInsight: