Tutorial: Erstellen einer Apache Spark-Machine Learning-Anwendung in Azure HDInsight
In diesem Tutorial lernen Sie, wie Sie mit Jupyter Notebook eine Apache Spark-Machine Learning-Anwendung für Azure HDInsight erstellen.
MLlib ist die anpassungsfähige Bibliothek für maschinelles Lernen von Spark, die aus gängigen Lernalgorithmen und Hilfsprogrammen besteht. (Klassifizierung, Regression, Clustering, kombiniertes Filtern und Verringerung der Dimensionalität. Auch zugrunde liegende Optimierungsprimitive.)
In diesem Tutorial lernen Sie Folgendes:
- Entwickeln einer Apache Spark-Machine Learning-Anwendung
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Weitere Informationen finden Sie unter Erstellen eines Apache Spark-Clusters.
Kenntnisse im Umgang mit Jupyter Notebooks mit Spark in HDInsight. Weitere Informationen finden Sie unter Tutorial: Laden von Daten und Ausführen von Abfragen auf einem Apache Spark-Cluster in Azure HDInsight.
Grundlegendes zum Dataset
Für die Anwendung werden die HVAC.csv-Beispieldaten genutzt, die standardmäßig auf allen Clustern verfügbar sind. Die Datei befindet sich unter \HdiSamples\HdiSamples\SensorSampleData\hvac. Die Daten zeigen die Zieltemperatur und die Ist-Temperatur von Gebäuden an, in denen HVAC-Systeme installiert sind. Die Spalte System enthält die System-ID und die Spalte SystemAge eine Angabe in Jahren, wie lange das HVAC-System im Gebäude bereits verwendet wird. Sie können anhand der Zieltemperatur, der jeweiligen System-ID und des Systemalters vorhersagen, ob ein Gebäude wärmer oder kälter wird.

Entwickeln einer Spark-Machine Learning-Anwendung mit Spark MLlib
In dieser Anwendung verwenden wir eine ML-Pipeline von Spark, um eine Dokumentklassifizierung durchzuführen. ML-Pipelines bieten eine einheitliche Gruppe allgemeiner APIs, die auf Datenrahmen aufbauen. Mit diesen Datenrahmen können Benutzer praktische Pipelines für maschinelles Lernen erstellen und optimieren. In der Pipeline teilen Sie das Dokument in Wörter auf, konvertieren die Wörter in einen numerischen Featurevektor und erstellen dann mit den Featurevektoren und Beschriftungen ein Vorhersagemodell. Führen Sie die folgenden Schritte aus, um die Anwendung zu erstellen.
Erstellen Sie eine Jupyter Notebook-Instanz mit dem PySpark-Kernel. Anweisungen hierzu finden Sie unter Erstellen einer Jupyter Notebook-Datei.
Importieren Sie die Typen, die für dieses Szenario benötigt werden. Fügen Sie den folgenden Codeausschnitt in eine leere Zelle ein, und drücken Sie UMSCHALT+EINGABETASTE.
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer from pyspark.sql import Row import os import sys from pyspark.sql.types import * from pyspark.mllib.classification import LogisticRegressionWithLBFGS from pyspark.mllib.regression import LabeledPoint from numpy import arrayLasen Sie die Daten (hvac.csv), analysieren Sie sie, und verwenden Sie sie zum Trainieren des Modells.
# Define a type called LabelDocument LabeledDocument = Row("BuildingID", "SystemInfo", "label") # Define a function that parses the raw CSV file and returns an object of type LabeledDocument def parseDocument(line): values = [str(x) for x in line.split(',')] if (values[3] > values[2]): hot = 1.0 else: hot = 0.0 textValue = str(values[4]) + " " + str(values[5]) return LabeledDocument((values[6]), textValue, hot) # Load the raw HVAC.csv file, parse it using the function data = sc.textFile("/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") documents = data.filter(lambda s: "Date" not in s).map(parseDocument) training = documents.toDF()Im Codeausschnitt definieren Sie eine Funktion, die die Ist-Temperatur mit der Zieltemperatur vergleicht. Wenn die Ist-Temperatur höher ist, wird angegeben, dass es in dem Gebäude zu warm ist (Wert 1,0). Andernfalls wird angegeben, dass es im Gebäude zu kalt ist (Wert 0.0).
Konfigurieren Sie die Spark-Pipeline für maschinelles Lernen, die drei Phasen umfasst:
tokenizer,hashingTFundlr.tokenizer = Tokenizer(inputCol="SystemInfo", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.01) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])Weitere Informationen zur Pipeline und ihrer Funktionsweise finden Sie unter Apache Spark machine learning pipeline (Apache Spark-Machine Learning-Pipeline).
Passen Sie die Pipeline an das Schulungsdokument an.
model = pipeline.fit(training)Überprüfen Sie das Schulungsdokument, um Ihre Fortschritte in Bezug auf die Anwendung zu ermitteln.
training.show()Die Ausgabe sieht in etwa wie folgt aus:
+----------+----------+-----+ |BuildingID|SystemInfo|label| +----------+----------+-----+ | 4| 13 20| 0.0| | 17| 3 20| 0.0| | 18| 17 20| 1.0| | 15| 2 23| 0.0| | 3| 16 9| 1.0| | 4| 13 28| 0.0| | 2| 12 24| 0.0| | 16| 20 26| 1.0| | 9| 16 9| 1.0| | 12| 6 5| 0.0| | 15| 10 17| 1.0| | 7| 2 11| 0.0| | 15| 14 2| 1.0| | 6| 3 2| 0.0| | 20| 19 22| 0.0| | 8| 19 11| 0.0| | 6| 15 7| 0.0| | 13| 12 5| 0.0| | 4| 8 22| 0.0| | 7| 17 5| 0.0| +----------+----------+-----+Vergleichen Sie die Ausgabe mit der CSV-Rohdatei. Die erste Zeile der CSV-Datei enthält beispielsweise folgende Daten:

Beachten Sie, dass die Ist-Temperatur unterhalb der Zieltemperatur liegt. Im Gebäude ist es also zu kalt. Der Wert label in der ersten Zeile lautet daher 0,0, was bedeutet, dass es im Gebäude nicht zu warm ist.
Bereiten Sie ein Dataset vor, für das das Schulungsmodell ausgeführt werden kann. Dazu übergeben Sie eine System-ID und ein Systemalter (in der Trainingsausgabe als SystemInfo bezeichnet). Mit dem Modell wird dann vorhergesagt, ob es im Gebäude mit der jeweiligen System-ID und dem Systemalter wärmer (1,0) oder kälter (0,0) wird.
# SystemInfo here is a combination of system ID followed by system age Document = Row("id", "SystemInfo") test = sc.parallelize([("1L", "20 25"), ("2L", "4 15"), ("3L", "16 9"), ("4L", "9 22"), ("5L", "17 10"), ("6L", "7 22")]) \ .map(lambda x: Document(*x)).toDF()Treffen Sie als Letztes die Vorhersagen für die Testdaten.
# Make predictions on test documents and print columns of interest prediction = model.transform(test) selected = prediction.select("SystemInfo", "prediction", "probability") for row in selected.collect(): print (row)Die Ausgabe sieht in etwa wie folgt aus:
Row(SystemInfo=u'20 25', prediction=1.0, probability=DenseVector([0.4999, 0.5001])) Row(SystemInfo=u'4 15', prediction=0.0, probability=DenseVector([0.5016, 0.4984])) Row(SystemInfo=u'16 9', prediction=1.0, probability=DenseVector([0.4785, 0.5215])) Row(SystemInfo=u'9 22', prediction=1.0, probability=DenseVector([0.4549, 0.5451])) Row(SystemInfo=u'17 10', prediction=1.0, probability=DenseVector([0.4925, 0.5075])) Row(SystemInfo=u'7 22', prediction=0.0, probability=DenseVector([0.5015, 0.4985]))Beachten Sie die erste Zeile in der Vorhersage. Für ein HVAC-System mit der ID 20 und einem Systemalter von 25 Jahren ist das Gebäude warm (Vorhersage=1,0). Der erste Wert für DenseVector (0.49999) entspricht der Vorhersage 0,0, und der zweite Wert (0.5001) entspricht der Vorhersage 1,0. Obwohl der zweite Wert in der Ausgabe nur unwesentlich höher ist, zeigt das Modell prediction=1.0an.
Fahren Sie das Notebook herunter, um die Ressourcen freizugeben. Wählen Sie hierzu im Menü Datei des Notebooks die Option Schließen und Anhalten aus. Mit dieser Aktion wird das Notebook heruntergefahren und geschlossen.
Verwenden der Anaconda-scikit-learn-Bibliothek für Spark-Machine Learning
Apache Spark-Cluster in HDInsight enthalten Anaconda-Bibliotheken. Dazu gehört auch die scikit-learn-Bibliothek für Machine Learning. Außerdem enthält die Bibliothek verschiedene Datasets, mit denen Sie Beispielanwendungen direkt über eine Jupyter Notebook-Instanz erstellen können. Beispiele zur Verwendung der scikit-learn-Bibliothek finden Sie unter https://scikit-learn.org/stable/auto_examples/index.html.
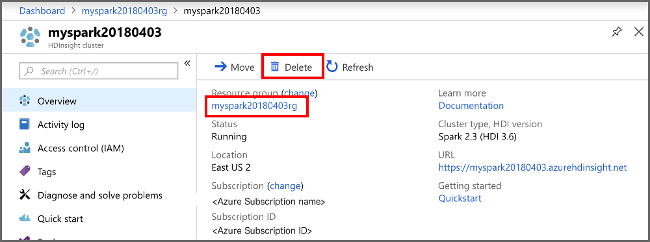
Bereinigen von Ressourcen
Wenn Sie diese Anwendung nicht mehr benötigen, gehen Sie wie folgt vor, um den erstellten Cluster zu löschen:
Melden Sie sich beim Azure-Portal an.
Geben Sie oben im Suchfeld den Suchbegriff HDInsight ein.
Wählen Sie unter Dienste die Option HDInsight-Cluster aus.
Klicken Sie in der daraufhin angezeigten Liste mit den HDInsight-Clustern neben dem Cluster, den Sie für dieses Tutorial erstellt haben, auf die Auslassungspunkte ( ... ).
Klicken Sie auf Löschen. Wählen Sie Ja aus.
Nächste Schritte
In diesem Tutorial haben Sie gelernt, wie Sie mit Jupyter Notebook eine Apache Spark-Machine Learning-Anwendung für Azure HDInsight erstellen. Im nächsten Tutorial erfahren Sie, wie Sie IntelliJ IDEA für Spark-Aufträge verwenden.