Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung mit Apache Spark in HDInsight
In diesem Artikel erfahren Sie, wie Sie Jupyter Notebook mit den benutzerdefinierten Kerneln PySpark (für Python) und Apache Spark (für Scala) mit Spark Magic installieren. Anschließend können Sie das Notebook mit einem HDInsight-Cluster verbinden.
Es gibt vier wichtige Schritte zum Installieren von Jupyter und Herstellen einer Verbindung mit Apache Spark in HDInsight.
- Konfigurieren Sie den Spark-Cluster.
- Installieren Sie Jupyter Notebook.
- Installieren Sie die PySpark- und Spark-Kernel mit Spark Magic.
- Konfigurieren Sie Spark Magic für den Zugriff auf den Spark-Cluster in HDInsight.
Weitere Informationen zu den benutzerdefinierten Kernels und Spark Magic finden Sie unter Verfügbare Kernels für Jupyter-Notebooks mit Apache Spark-Linux-Clustern in HDInsight.
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Eine Anleitung finden Sie unter Erstellen von Apache Spark-Clustern in Azure HDInsight. Das lokale Notebook wird mit dem HDInsight-Cluster verbunden.
Kenntnisse im Umgang mit Jupyter Notebooks mit Spark in HDInsight.
Installieren von Jupyter Notebook auf Ihrem Computer
Installieren Sie Python, bevor Sie Jupyter Notebooks installieren. Die Anaconda-Distribution installiert sowohl Python als auch Jupyter Notebook.
Laden Sie das Anaconda-Installationsprogramm für Ihre Plattform herunter, und führen Sie das Setup aus. Stellen Sie sicher, dass während der Ausführung des Setup-Assistenten die Option für das Hinzufügen von Anaconda zu Ihrer PATH-Variablen aktiviert ist. Siehe auch Installieren von Jupyter mit Anaconda.
Installieren von SparkMagic
Geben Sie den Befehl
pip install sparkmagic==0.13.1ein, um Spark Magic für HDInsight-Cluster der Version 3.6 und 4.0 zu installieren. Weitere Informationen finden Sie in der SparkMagic-Dokumentation.Führen Sie den folgenden Befehl aus, um sicherzustellen, dass
ipywidgetsordnungsgemäß installiert ist:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Installieren der PySpark- und Spark-Kernel
Ermitteln Sie mithilfe des folgenden Befehls, wo
sparkmagicinstalliert ist:pip show sparkmagicÄndern Sie dann das Arbeitsverzeichnis in den Speicherort, den Sie mit dem obigen Befehl ermittelt haben.
Geben Sie im neuen Arbeitsverzeichnis einen oder mehrere der unten aufgeführten Befehle ein, um die gewünschten Kernel zu installieren:
Kernel Get-Help Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelOptional. Geben Sie den folgenden Befehl ein, um die Servererweiterung zu aktivieren:
jupyter serverextension enable --py sparkmagic
Konfigurieren von Spark Magic zum Herstellen der Verbindung mit dem Spark-Cluster in HDInsight
In diesem Abschnitt lernen Sie, SparkMagic nach der Installation zu konfigurieren, um eine Verbindung mit einem Apache Spark-Cluster herzustellen.
Starten Sie die Python-Shell mit dem folgenden Befehl:
pythonDie Konfigurationsinformationen für Jupyter werden in der Regel im Basisverzeichnis des Benutzers gespeichert. Geben Sie den folgenden Befehl ein, um das Basisverzeichnis zu ermitteln, und erstellen Sie den Ordner .sparkmagic. Der vollständige Pfad wird ausgegeben.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()Erstellen Sie im Ordner
.sparkmagicdie Datei config.json, und fügen Sie den folgenden JSON-Codeausschnitt darin ein.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Nehmen Sie die folgenden Änderungen an der Datei vor:
Vorlagenwert Neuer Wert {BENUTZERNAME} Clusteranmeldung, Standardwert: admin.{CLUSTER-DNS-NAME} Clustername {BASE64-CODIERTES-KENNWORT} Ein Base64-codiertes Kennwort für Ihr eigentliches Kennwort. Sie können unter https://www.url-encode-decode.com/base64-encode-decode/ ein Base64-Kennwort generieren. "livy_server_heartbeat_timeout_seconds": 60Behalten Sie den Wert bei, wenn Sie sparkmagic 0.12.7verwenden (Cluster der Versionen 3.5 und 3.6). Wenn Siesparkmagic 0.2.3verwenden (Cluster der Version 3.4), ersetzen Sie den Wert durch"should_heartbeat": true.Eine vollständige Beispieldatei finden Sie im Beispiel für „config.json“.
Tipp
Takte werden gesendet, um sicherzustellen, dass bei Sitzungen keine Verluste auftreten. Wenn ein Computer in den Ruhezustand versetzt oder heruntergefahren wird, wird der Takt nicht gesendet, und die Sitzung wird bereinigt. Für Cluster der Version 3.4 gilt: Wenn Sie dieses Verhalten deaktivieren möchten, können Sie die Livy-Konfiguration
livy.server.interactive.heartbeat.timeoutüber die Ambari-Benutzeroberfläche auf0festlegen. Für Cluster der Version 3.5 gilt: Wenn Sie die obige 3.5-Konfiguration nicht festlegen, wird die Sitzung nicht gelöscht.Starten Sie Jupyter. Geben Sie in der Eingabeaufforderung folgenden Befehl ein:
jupyter notebookStellen Sie sicher, dass Sie die verfügbare Spark Magic-Version mit den Kerneln verwenden können. Führen Sie die folgenden Schritte aus.
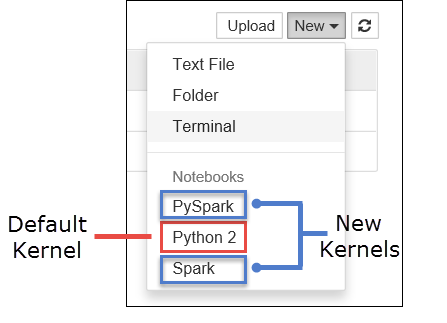
a. Erstellen Sie ein neues Notebook. Wählen Sie in der rechten Ecke Neu aus. Daraufhin sollten der Python 2- oder Python 3-Standardkernel und die von Ihnen installierten Kernel angezeigt werden. Die tatsächlichen Werte variieren je nach Ihren Installationsentscheidungen. Wählen Sie PySpark aus.
Wichtig
Überprüfen Sie Ihre Shell nach der Auswahl von Neu auf Fehler. Wenn der Fehler
TypeError: __init__() got an unexpected keyword argument 'io_loop'angezeigt wird, ist möglicherweise ein bekanntes Problem mit bestimmten Versionen von Tornado aufgetreten. Wenn dies der Fall ist, beenden Sie den Kernel, und stufen Sie anschließend die Tornado-Installation mit dem folgenden Befehl herab:pip install tornado==4.5.3.b. Führen Sie den folgenden Codeausschnitt aus.
%%sql SELECT * FROM hivesampletable LIMIT 5Wenn Sie die Ausgabe erfolgreich abrufen können, wird Ihre Verbindung zu dem HDInsight-Cluster getestet.
Wenn Sie die Notebookkonfiguration für die Verbindung mit einem anderen Cluster aktualisieren möchten, aktualisieren Sie die Datei „config.json“ mit einem neuen Satz von Werten, wie in Schritt 3 oben dargestellt.
Warum sollte ich Jupyter auf meinem Computer installieren?
Gründe, um Jupyter auf dem Computer zu installieren und mit einem Apache Spark-Cluster in HDInsight zu verbinden:
- Es bietet Ihnen die Möglichkeit, Ihre Notebooks lokal zu erstellen, Ihre Anwendung in einem Cluster während dessen Betriebs zu testen und die Notebooks dann in den Cluster hochzuladen. Sie können die Notebooks entweder mithilfe des im Cluster ausgeführten Jupyter Notebooks hochladen, oder sie in dem Speicherkonto, das dem Cluster zugeordnet ist, im Ordner
/HdiNotebooksspeichern. Weitere Informationen zum Speichern von Notebooks im Cluster finden Sie unter Wo werden die Notebooks gespeichert? - Wenn Notebooks lokal verfügbar sind, können Sie basierend auf den Anwendungsanforderungen Verbindungen mit unterschiedlichen Spark-Clustern herstellen.
- Sie können GitHub verwenden, um ein Quellcodeverwaltungssystem zu implementieren und Versionskontrolle für die Notebooks zu ermöglichen. Sie können auch eine Umgebung für Zusammenarbeit einrichten, in der mehrere Benutzer mit dem gleichen Notebook arbeiten können.
- Sie können mit Notebooks lokal ohne einen Cluster arbeiten. Sie benötigen einen Cluster nur zum Testen der Notebooks, nicht für das manuelle Verwalten von Notebooks oder einer Entwicklungsumgebung.
- Es ist möglicherweise einfacher, Ihre eigene lokale Entwicklungsumgebung zu konfigurieren, statt die Jupyter-Installation im Cluster zu konfigurieren. Sie können sämtliche Software nutzen, die Sie lokal installiert haben, ohne Remotecluster zu konfigurieren.
Warnung
Wenn Jupyter auf dem lokalen Computer installiert ist, können mehrere Benutzer gleichzeitig das gleiche Notebook im gleichen Spark-Cluster ausführen. In diesem Fall werden mehrere Livy-Sitzungen erstellt. Wenn ein Problem auftritt, das Sie debuggen möchten, ist es eine komplexe Aufgabe nachzuverfolgen, welche Livy-Sitzung welchem Benutzer gehört.