Data Science mit Ubuntu Data Science Virtual Machine in Azure
In dieser exemplarischen Vorgehensweise erfahren Sie, wie Sie mit Ubuntu Data Science Virtual Machine (DSVM) typische Data Science-Aufgaben erledigen können. Bei Ubuntu DSVM handelt es sich um das Image eines virtuelles Computers, das unter Azure verfügbar ist und eine vorinstallierte Sammlung von Tools enthält, die häufig für Datenanalysen und maschinelles Lernen verwendet werden. Die wichtigsten Softwarekomponenten werden unter Bereitstellen von Ubuntu Data Science Virtual Machine einzeln aufgeführt. Das DSVM-Image erleichtert Ihnen den Start, und für den Data Science-Vorgang sind nur wenige Minuten erforderlich, ohne dass die Tools einzeln installiert und konfiguriert werden müssen. Die DSVM kann bei Bedarf problemlos hochskaliert werden, und Sie können sie beenden, wenn Sie nicht verwendet wird. Die DSVM-Ressource ist also sowohl flexibel als auch kosteneffizient.
In dieser exemplarischen Vorgehensweise analysieren wir das spambase-Dataset. Spambase ist eine Sammlung von E-Mails, die als „Spam“ oder „Ham“ (kein Spam) gekennzeichnet sind. Spambase enthält außerdem einige Statistiken zum Inhalt der E-Mails. Diese Statistiken werden später in der exemplarischen Vorgehensweise erläutert.
Voraussetzungen
Bevor Sie eine Linux DSVM verwenden können, müssen die folgenden Voraussetzungen erfüllt sein:
Azure-Abonnement. Erstellen Sie ein kostenloses Azure-Konto, um ein Azure-Abonnement zu erhalten.
Ubuntu Data Science Virtual Machine. Informationen zur Bereitstellung des virtuellen Computers finden Sie unter Bereitstellen von Ubuntu Data Science Virtual Machine.
X2Go-Installation auf dem Computer mit einer geöffneten XFCE-Sitzung. Weitere Informationen finden Sie unter Installieren und Konfigurieren des X2Go-Clients.
Herunterladen des Datasets „spambase“
Das Dataset spambase umfasst eine relativ kleine Sammlung von Daten, die 4.601 Beispiele enthält. Die Größe des Datasets bietet eine praktische Möglichkeit, einige der wichtigsten Funktionen von DSVM zu demonstrieren, da es die Ressourcenanforderungen gering hält.
Hinweis
Diese exemplarische Vorgehensweise wurde mit einer Linux DSVM der Größe D2 v2 erstellt. Sie können eine DSVM dieser Größe verwenden, um die in dieser exemplarischen Vorgehensweise gezeigten Verfahren nachzuvollziehen.
Wenn Sie mehr Speicherplatz benötigen, können Sie zusätzliche Datenträger erstellen und an Ihre DSVM anfügen. Für diese Datenträger wird persistenter Azure-Speicher verwendet, sodass die Daten auch dann beibehalten werden, wenn der Server aufgrund einer Größenänderung neu bereitgestellt oder heruntergefahren wird. Um einen Datenträger hinzuzufügen und an Ihre DSVM anzufügen, führen Sie die Schritte unter Hinzufügen eines Datenträgers zu einer Linux-VM aus. Für diese Schritte zum Hinzufügen eines Datenträgers wird die Azure CLI verwendet, die bereits auf der DSVM installiert ist. Sie können die Schritte vollständig über die DSVM selbst ausführen. Eine weitere Option zum Vergrößern des Speichers ist die Verwendung von Azure Files.
Öffnen Sie zum Herunterladen der Daten ein Terminalfenster, und führen Sie dann diesen Befehl aus:
wget --no-check-certificate https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/spambase.data
Die heruntergeladene Datei weist keine Headerzeile auf. Erstellen wir eine weitere Datei mit einem Header. Führen Sie diesen Befehl aus, um eine Datei mit den entsprechenden Headern zu erstellen:
echo 'word_freq_make, word_freq_address, word_freq_all, word_freq_3d,word_freq_our, word_freq_over, word_freq_remove, word_freq_internet,word_freq_order, word_freq_mail, word_freq_receive, word_freq_will,word_freq_people, word_freq_report, word_freq_addresses, word_freq_free,word_freq_business, word_freq_email, word_freq_you, word_freq_credit,word_freq_your, word_freq_font, word_freq_000, word_freq_money,word_freq_hp, word_freq_hpl, word_freq_george, word_freq_650, word_freq_lab,word_freq_labs, word_freq_telnet, word_freq_857, word_freq_data,word_freq_415, word_freq_85, word_freq_technology, word_freq_1999,word_freq_parts, word_freq_pm, word_freq_direct, word_freq_cs, word_freq_meeting,word_freq_original, word_freq_project, word_freq_re, word_freq_edu,word_freq_table, word_freq_conference, char_freq_semicolon, char_freq_leftParen,char_freq_leftBracket, char_freq_exclamation, char_freq_dollar, char_freq_pound, capital_run_length_average,capital_run_length_longest, capital_run_length_total, spam' > headers
Verketten Sie die beiden Dateien dann:
cat spambase.data >> headers
mv headers spambaseHeaders.data
Das Dataset enthält mehrere Arten von Statistiken für jede E-Mail:
- In Spalten wie word_freq_WORD wird der Prozentsatz der Wörter in der E-Mail angegeben, die mit WORD übereinstimmen. Beispiel: Wenn word_freq_make den Wert 1 hat, lauteten 1 % aller Wörter in der E-Mail make.
- In Spalten wie char_freq_CHAR wird der Prozentsatz aller Zeichen in der E-Mail angegeben, die CHAR lauten.
- capital_run_length_longest ist die längste Sequenz von Großbuchstaben.
- capital_run_length_average ist die durchschnittliche Länge aller Sequenzen von Großbuchstaben.
- capital_run_length_total ist die Gesamtlänge aller Sequenzen von Großbuchstaben.
- spam gibt an, ob die E-Mail als Spam eingestuft wurde (1 = Spam, 0 = kein Spam).
Untersuchen des Datasets mithilfe von R Open
Wir untersuchen nun die Daten und führen einige einfache Machine Learning-Schritte mit R aus. Auf der DSVM ist CRAN R vorinstalliert.
Um Kopien der Codebeispiele zu erhalten, die in dieser exemplarischen Vorgehensweise verwendet werden, klonen Sie das Repository „Azure-Machine-Learning-Data-Science“ mit Git. Git ist auf der DSVM vorinstalliert. Führen Sie an der git-Befehlszeile Folgendes aus:
git clone https://github.com/Azure/Azure-MachineLearning-DataScience.git
Öffnen Sie ein Terminalfenster, und starten Sie eine neue R-Sitzung in der interaktiven R-Konsole. So importieren Sie die Daten und richten die Umgebung ein:
data <- read.csv("spambaseHeaders.data")
set.seed(123)
Zusammenfassende Statistiken zu jeder Spalte erhalten Sie wie folgt:
summary(data)
Eine andere Ansicht der Daten:
str(data)
Diese Ansicht zeigt den Typ der einzelnen Variablen und die ersten Werte im Dataset.
Die Spalte spam wurde als ganze Zahl gelesen, aber es ist eigentlich eine Kategorievariable (oder ein Faktor). So legen Sie den Typ fest
data$spam <- as.factor(data$spam)
Verwenden Sie zum Durchführen einiger Untersuchungsanalysen das Paket ggplot2. Hierbei handelt es sich um eine beliebte Graphbibliothek für R, die auf der DSVM vorinstalliert ist. Basierend auf den weiter oben dargestellten Zusammenfassungsdaten verfügen wir über zusammenfassende Statistiken zur Häufigkeit des Ausrufezeichens. Wir zeigen diese Häufigkeiten hier an, indem wir die folgenden Befehle ausführen:
library(ggplot2)
ggplot(data) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
Da die Nullleiste das Plotergebnis verzerrt, beseitigen wir sie:
email_with_exclamation = data[data$char_freq_exclamation > 0, ]
ggplot(email_with_exclamation) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
Ein nicht trivialer Dichtewert größer als 1 sieht interessant aus. Wir sehen uns nur diese Daten an:
ggplot(data[data$char_freq_exclamation > 1, ]) + geom_histogram(aes(x=char_freq_exclamation), binwidth=0.25)
Dann unterteilen wir nach „Spam“ im Vergleich zu „Ham“:
ggplot(data[data$char_freq_exclamation > 1, ], aes(x=char_freq_exclamation)) +
geom_density(lty=3) +
geom_density(aes(fill=spam, colour=spam), alpha=0.55) +
xlab("spam") +
ggtitle("Distribution of spam \nby frequency of !") +
labs(fill="spam", y="Density")
Diese Beispiele sollten Ihnen dabei helfen, ähnliche Plots zu erstellen und Daten in den anderen Spalten zu untersuchen.
Trainieren und Testen eines Machine Learning-Modells
Wir trainieren eine Reihe von Machine Learning-Modellen, um die E-Mails im Dataset danach zu klassifizieren, ob es sich um „Spam“ oder „Ham“ handelt. In diesem Abschnitt trainieren wir ein Entscheidungsstrukturmodell und ein zufälliges Gesamtstrukturmodell. Anschließend testen wir die Genauigkeit der Vorhersagen.
Hinweis
Das Paket rpart (Recursive Partitioning and Regression Trees), das im folgenden Code verwendet wird, ist auf der DSVM bereits installiert.
Zuerst unterteilen wird das Dataset in Trainings- und Testsätze:
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
Anschließend erstellen wir eine Entscheidungsstruktur zum Klassifizieren der E-Mails:
require(rpart)
model.rpart <- rpart(spam ~ ., method = "class", data = trainSet)
plot(model.rpart)
text(model.rpart)
Das Ergebnis lautet wie folgt:
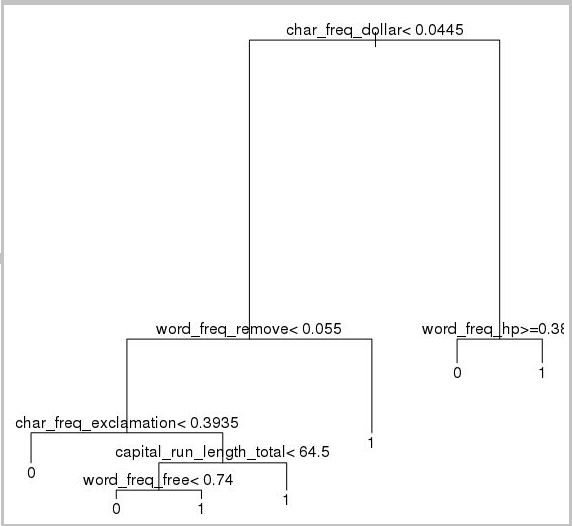
Verwenden Sie den folgenden Code, um die Leistung für den Trainingssatz zu ermitteln:
trainSetPred <- predict(model.rpart, newdata = trainSet, type = "class")
t <- table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
Gehen Sie wie folgt vor, um die Leistung für den Testsatz zu ermitteln:
testSetPred <- predict(model.rpart, newdata = testSet, type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
Wir probieren auch ein Modell mit einer zufälligen Gesamtstruktur aus. Mit zufälligen Gesamtstrukturen werden zahlreiche Entscheidungsstrukturen trainiert. Hierbei wird eine Klasse ausgegeben, bei der es sich um den Modus der Klassifizierungen aller einzelnen Entscheidungsstrukturen handelt. Dies ist ein leistungsfähigerer Machine Learning-Ansatz, da die Tendenz eines Entscheidungsbaummodells, für ein Trainingsdataset eine Überanpassung durchzuführen, korrigiert wird.
require(randomForest)
trainVars <- setdiff(colnames(data), 'spam')
model.rf <- randomForest(x=trainSet[, trainVars], y=trainSet$spam)
trainSetPred <- predict(model.rf, newdata = trainSet[, trainVars], type = "class")
table(`Actual Class` = trainSet$spam, `Predicted Class` = trainSetPred)
testSetPred <- predict(model.rf, newdata = testSet[, trainVars], type = "class")
t <- table(`Actual Class` = testSet$spam, `Predicted Class` = testSetPred)
accuracy <- sum(diag(t))/sum(t)
accuracy
Deep Learning-Tutorials und exemplarische Vorgehensweisen
Zusätzlich zu den frameworkbasierten Beispielen werden auch eine Reihe umfassender exemplarischer Vorgehensweisen bereitgestellt. Diese Vorgehensweisen helfen Ihnen, Ihre Entwicklung von Deep Learning-Anwendungen in Bereichen wie Bild- und Text-/Sprachenverständnis zu beschleunigen.
Betreiben neuronaler Netze in verschiedenen Frameworks: Diese umfassende exemplarische Vorgehensweise zeigt, wie Sie Code aus einem Framework zu einem anderen migrieren. Sie veranschaulicht auch, wie Sie das Modell und die Laufzeitleistung in verschiedenen Frameworks vergleichen.
Anleitung zum Erstellen einer End-to-End-Lösung zum Erkennen von Produkten in Bildern: Die Bilderkennung ist eine Technik, mit der Objekte innerhalb von Bildern lokalisiert und klassifiziert werden können. Die Technologie hat das Potenzial, in vielen realen Geschäftsbereichen enorme Vorteile zu bringen. Mit dieser Technik können Einzelhändler beispielsweise feststellen, welches Produkt ein Kunde dem Regal entnommen hat. Diese Informationen wiederum helfen Filialen bei der Verwaltung des Warenbestands.
Deep Learning for Audio: In diesem Tutorial wird gezeigt, wie Sie ein Deep Learning-Modell für die Erkennung von Audioereignissen für das Urban Sound Dataset trainieren. Das Tutorial bietet außerdem eine Übersicht darüber, wie mit Audiodaten gearbeitet wird.
Klassifizierung von Textdokumenten: In dieser exemplarischen Vorgehensweise wird gezeigt, wie zwei unterschiedliche Architekturen neuronaler Netze erstellt und trainiert werden: Hierarchical Attention Network und LSTM (Long Short Term Memory). Diese neuronalen Netzwerke verwenden zur Klassifizierung von Textdokumenten die Keras-API für Deep Learning. Keras ist ein Front-End für drei der am häufigsten verwendeten Deep Learning-Frameworks: Microsoft Cognitive Toolkit, TensorFlow und Theano.
Weitere Tools
In den restlichen Abschnitten wird gezeigt, wie Sie einige der Tools verwenden, die auf der Linux-DSVM installiert sind. Die folgenden Tools werden beschrieben:
- XGBoost
- Python
- JupyterHub
- Rattle
- PostgreSQL und SQuirrel SQL
- Azure Synapse Analytics (ehemals SQL DW)
XGBoost
XGBoost ermöglicht eine schnelle und präzise Boosted Tree-Implementierung.
require(xgboost)
data <- read.csv("spambaseHeaders.data")
set.seed(123)
rnd <- runif(dim(data)[1])
trainSet = subset(data, rnd <= 0.7)
testSet = subset(data, rnd > 0.7)
bst <- xgboost(data = data.matrix(trainSet[,0:57]), label = trainSet$spam, nthread = 2, nrounds = 2, objective = "binary:logistic")
pred <- predict(bst, data.matrix(testSet[, 0:57]))
accuracy <- 1.0 - mean(as.numeric(pred > 0.5) != testSet$spam)
print(paste("test accuracy = ", accuracy))
XGBoost kann einen Aufruf auch über Python oder eine Befehlszeile durchführen.
Python
Für die Python-Entwicklung wurden die Anaconda Python-Distributionen 3.5 und 2.7 auf der DSVM installiert.
Hinweis
Die Anaconda-Distribution enthält Conda. Mit Conda können Sie benutzerdefinierte Python-Umgebungen erstellen, in denen verschiedene Versionen oder Pakete installiert sind.
Wir lesen nun einen Teil des Datasets „spambase“ ein und klassifizieren die E-Mails mit Support Vector Machines in Scikit-learn:
import pandas
from sklearn import svm
data = pandas.read_csv("spambaseHeaders.data", sep = ',\s*')
X = data.ix[:, 0:57]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
Vorhersagen können Sie wie folgt erstellen:
clf.predict(X.ix[0:20, :])
Um zu zeigen, wie ein Azure Machine Learning-Endpunkt veröffentlicht werden kann, erstellen wir ein einfacheres Modell. Wir verwenden die drei Variablen, die wir verwendet haben, als wir das R-Modell zuvor veröffentlicht haben:
X = data[["char_freq_dollar", "word_freq_remove", "word_freq_hp"]]
y = data.ix[:, 57]
clf = svm.SVC()
clf.fit(X, y)
JupyterHub
Die Anaconda-Distribution auf der DSVM verfügt über ein Jupyter Notebook, eine plattformübergreifende Umgebung zum gemeinsamen Nutzen von Python-, R- oder Julia-Code und -Analysefunktionen. Auf Jupyter Notebook wird über JupyterHub zugegriffen. Sie melden sich mit Ihrem lokalen Linux-Benutzernamen und dem dazugehörigen Kennwort unter https://<DSVM-DNS-Name oder IP-Adresse>:8000/ an. Alle Konfigurationsdateien für JupyterHub befinden sich im Verzeichnis „/etc/jupyterhub“.
Hinweis
Um den Python-Paket-Manager (über den Befehl pip) aus einem Jupyter Notebook im aktuellen Kernel zu verwenden, verwenden Sie diesen Befehl in der Codezelle:
import sys
! {sys.executable} -m pip install numpy -y
Um das Conda-Installationsprogramm (über den Befehl conda) aus einem Jupyter Notebook im aktuellen Kernel zu verwenden, verwenden Sie diesen Befehl in einer Codezelle:
import sys
! {sys.prefix}/bin/conda install --yes --prefix {sys.prefix} numpy
Einige Beispielnotebooks sind auf der DSVM bereits installiert:
- Python-Beispielnotebooks:
- R-Beispielnotebook:
Hinweis
Die Julia-Sprache ist auch über die Befehlszeile auf der Linux DSVM verfügbar.
Rattle
Rattle (RAnalytical Tool To Learn Easily) ist ein grafisches R-Tool für Data Mining-Aufgaben. Rattle verfügt über eine intuitive Benutzeroberfläche, die Ihnen das Laden, Untersuchen und Transformieren von Daten und das Erstellen und Auswerten von Modellen erleichtert. Rattle: A Data Mining GUI for R (Rattle: Data Mining-GUI für R) enthält eine exemplarische Vorgehensweise zur Veranschaulichung der Features von Rattle.
Installieren und starten Sie Rattle, indem Sie diese Befehle ausführen:
if(!require("rattle")) install.packages("rattle")
require(rattle)
rattle()
Hinweis
Sie müssen Rattle nicht auf der DSVM installieren. Sie werden jedoch möglicherweise aufgefordert, zusätzliche Pakete zu installieren, wenn Rattle geöffnet wird.
Die Benutzeroberfläche von Rattle basiert auf Registerkarten. Die meisten Registerkarten entsprechen den Schritten unter Team Data Science-Prozess, z.B. das Laden oder Untersuchen von Daten. Der Data Science-Prozess verläuft von links nach rechts durch die Registerkarten. Die letzte Registerkarte enthält ein Protokoll mit den R-Befehlen, die von Rattle ausgeführt wurden.
Gehen Sie wie folgt vor, um das Dataset zu laden und zu konfigurieren:
- Wählen Sie die Registerkarte Data (Daten) aus, um die Datei zu laden.
- Wählen Sie im Auswahlbereich neben Filename (Dateiname) die Option spambaseHeaders.data aus.
- Um die Datei zu laden, wählen Sie Execute (Ausführen) aus. Es sollte eine Zusammenfassung jeder Spalte angezeigt werden, einschließlich des identifizierten Datentyps, ob es sich um eine Eingabe-, Ziel- oder andere Art von Variablen handelt, und der Anzahl der eindeutigen Werte.
- Rattle hat die Spalte spam richtig als Ziel identifiziert. Wählen Sie die Spalte spam aus, und legen Sie den Zieldatentyp dann auf Categoric (Kategorisch) fest.
Gehen Sie wie folgt vor, um die Daten zu untersuchen:
- Wählen Sie die Registerkarte Explore (Untersuchen).
- Um Informationen zu den Variablentypen und einige zusammenfassende Statistiken anzuzeigen, wählen Sie Zusammenfassung>Ausführen (Zusammenfassung > Ausführen) aus.
- Wählen Sie andere Optionen wie Describe (Beschreiben) oder Basics (Grundlagen) aus, um andere Arten von Statistiken zu jeder Variablen anzuzeigen.
Sie können die Registerkarte Explore (Untersuchen) auch verwenden, um aufschlussreiche Plots zu generieren. Gehen Sie wie folgt vor, um ein Histogramm mit den Daten zu plotten:
- Wählen Sie Distributions(Verteilungen).
- Wählen Sie für auf word_freq_remove und word_freq_you die Option Histogram (Histogramm) aus.
- Wählen Sie Execute(Ausführen). Beide Dichteplotergebnisse werden zusammen in einem Graphfenster angezeigt, und es wird deutlich, dass das Wort you in E-Mails viel häufiger als das Wort remove enthalten ist.
Die Plots vom Typ Correlation (Korrelation) sind ebenfalls interessant. So erstellen Sie einen Plot:
- Wählen Sie als Type (Typ) die Option Correlation (Korrelation) aus.
- Wählen Sie Execute(Ausführen).
- Rattle warnt Sie, dass maximal 40 Variablen verwendet werden sollten. Wählen Sie Yes (Ja), um das Plotergebnis anzuzeigen.
Einige interessante Korrelationen werden angezeigt: Beispielsweise korreliert technology stark mit HP und labs. Außerdem besteht eine starke Korrelation mit 650, da die Ortskennzahl der Anbieter des Datasets 650 lautet.
Die numerischen Werte für die Korrelationen zwischen Wörtern sind im Fenster Explore (Untersuchen) verfügbar. Es ist beispielsweise interessant, dass technology für your und money eine negative Korrelation aufweist.
Rattle kann das Dataset transformieren, um einige häufig auftretende Probleme zu behandeln. Beispielsweise können Sie Features neu skalieren, fehlende Werte zuordnen, Ausreißer verarbeiten und Variablen oder Beobachtungen mit fehlenden Daten entfernen. Außerdem kann Rattle Zuordnungsregeln zwischen Beobachtungen und Variablen identifizieren. Diese Registerkarten werden in dieser einführenden exemplarischen Vorgehensweise nicht behandelt.
Rattle kann auch Clusteranalysen ausführen. Wir schließen einige Features aus, damit die Ausgabe einfacher gelesen werden kann. Wählen Sie auf der Registerkarte Data (Daten) die Option Ignore (Ignorieren) neben allen Variablen aus, mit Ausnahme der folgenden zehn Elemente:
- word_freq_hp
- word_freq_technology
- word_freq_george
- word_freq_remove
- word_freq_your
- word_freq_dollar
- word_freq_money
- capital_run_length_longest
- word_freq_business
- spam
Kehren Sie auf die Registerkarte Cluster zurück. Wählen Sie KMeans aus, und legen Sie dann Number of clusters (Anzahl Cluster) auf 4 fest. Wählen Sie Execute(Ausführen). Die Ergebnisse werden im Ausgabefenster angezeigt. Ein Cluster weist eine hohe Häufigkeit für george und hp auf und ist vermutlich eine legitime geschäftliche E-Mail.
Gehen Sie wie folgt vor, um ein einfaches Machine Learning-Modell mit Entscheidungsstruktur zu erstellen:
- Wählen Sie die Registerkarte Model (Modell).
- Wählen Sie unter Type (Typ) die OptionTree (Struktur) aus.
- Wählen Sie die Option Execute (Ausführen), um den Baum im Ausgabefenster in Textform anzuzeigen.
- Wählen Sie die Schaltfläche Draw (Zeichnen), um eine grafische Version anzuzeigen. Die Entscheidungsstruktur weist eine starke Ähnlichkeit mit der Struktur auf, die wir zuvor mit „rpart“ abgerufen haben.
Ein hilfreiches Feature von Rattle ist die Möglichkeit, mehrere Machine Learning-Methoden auszuführen und schnell auszuwerten. Gehen Sie wie folgt vor:
- Wählen Sie als Type (Typ) die Option All (Alle) aus.
- Wählen Sie Execute(Ausführen).
- Wenn Rattle die Ausführung beendet hat, können Sie einen beliebigen Wert für Type (Typ) auswählen (etwa SVM) und die Ergebnisse anzeigen.
- Außerdem können Sie die Leistung der Modelle für den Validierungssatz mithilfe der Registerkarte Evaluate (Auswerten) vergleichen. In der Auswahl Error Matrix (Fehlermatrix) werden beispielsweise die Wahrheitsmatrix, der Gesamtfehler und der durchschnittliche Klassenfehler für jedes Modell des Validierungssatzes angezeigt. Sie können auch ROC-Kurven plotten, Empfindlichkeitsanalysen durchführen und andere Formen der Modellevaluierung nutzen.
Wählen Sie nach Abschluss der Modellerstellung die Registerkarte Log (Protokoll), um den R-Code anzuzeigen, der von Rattle während Ihrer Sitzung ausgeführt wurde. Sie können die Schaltfläche Export (Exportieren) wählen, um diese Daten zu speichern.
Hinweis
Die aktuelle Version von Rattle enthält einen Fehler. Um das Skript zu ändern oder es zum Wiederholen der Schritte zu einem späteren Zeitpunkt zu verwenden, müssen Sie vor Dieses Protokoll exportieren... im Text des Protokolls das Zeichen # einfügen.
PostgreSQL und SQuirrel SQL
Auf der DSVM ist PostgreSQL vorinstalliert. PostgreSQL ist eine anspruchsvolle relationale Open-Source-Datenbank. In diesem Abschnitt wird veranschaulicht, wie Sie das Dataset „spambase“ in PostgreSQL laden und dann abfragen.
Vor dem Laden der Daten müssen Sie Kennwortauthentifizierung über den localhost zulassen. Führen Sie an der Eingabeaufforderung Folgendes aus:
sudo gedit /var/lib/pgsql/data/pg_hba.conf
Unten in der Config-Datei sind mehrere Zeilen mit Informationen zu den zulässigen Verbindungen enthalten:
# "local" is only for Unix domain socket connections:
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 ident
# IPv6 local connections:
host all all ::1/128 ident
Ändern Sie die Zeile IPv4 local connections, um md5 anstelle von ident zu verwenden, damit die Anmeldung mit einem Benutzernamen und Kennwort möglich ist:
# IPv4 local connections:
host all all 127.0.0.1/32 md5
Starten Sie dann den PostgreSQL-Dienst neu:
sudo systemctl restart postgresql
Führen Sie zum Starten von psql (einem interaktiven Terminal für PostgreSQL) als integrierter postgres-Benutzer den folgenden Befehl aus:
sudo -u postgres psql
Erstellen Sie ein neues Benutzerkonto, indem Sie den Benutzernamen des Linux-Kontos verwenden, mit dem Sie sich angemeldet haben. Erstellen Sie ein Kennwort:
CREATE USER <username> WITH CREATEDB;
CREATE DATABASE <username>;
ALTER USER <username> password '<password>';
\quit
Melden Sie sich bei psql an:
psql
Importieren Sie die Daten in eine neue Datenbank:
CREATE DATABASE spam;
\c spam
CREATE TABLE data (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer);
\copy data FROM /home/<username>/spambase.data DELIMITER ',' CSV;
\quit
Wir sehen uns nun die Daten an und führen einige Abfragen mit SQuirrel SQL aus. Hierbei handelt es sich um ein grafisches Tool, mit dem Sie über einen JDBC-Treiber mit Datenbanken interagieren können.
Starten Sie SQuirrel SQL über das Menü Applications (Anwendungen), um zu beginnen. Richten Sie den Treiber ein:
- Wählen Sie Windows>View Drivers (Windows > Treiber anzeigen) aus.
- Klicken Sie mit der rechten Maustaste auf PostgreSQL, und wählen Sie die Option Modify Driver (Treiber ändern) aus.
- Wählen Sie Extra Class Path>Add (Zusätzlicher Klassenpfad > Hinzufügen) aus.
- Geben Sie unter File Name (Dateiname) die Angabe /usr/share/java/jdbcdrivers/postgresql-9.4.1208.jre6.jar ein.
- Wählen Sie Open(Öffnen).
- Wählen Sie List Drivers (Treiber auflisten) aus. Wählen Sie als Class Name (Klassenname) die Option org.postgresql.Driver aus, und wählen Sie dann OK aus.
Gehen Sie wie folgt vor, um die Verbindung mit dem lokalen Server einzurichten:
- Wählen Sie Windows>View Aliases (Windows > Aliase anzeigen) aus.
- Erstellen Sie über die Schaltfläche + einen neuen Alias. Geben Sie als Aliasnamen Spam database (Spamdatenbank) ein.
- Wählen Sie als Driver (Treiber) die Option PostgreSQL aus.
- Legen Sie die URL auf jdbc:postgresql://localhost/spam fest.
- Geben Sie Ihren Benutzernamen und Ihr Kennwort ein.
- Klicken Sie auf OK.
- Doppelklicken Sie zum Öffnen des Fensters Connection (Verbindung) auf den Alias Spam database.
- Wählen Sie Verbinden.
Führen Sie einige Abfragen aus:
- Wählen Sie die Registerkarte SQL (SQL).
- Geben Sie im Abfragefeld oben auf der Registerkarte SQL eine einfache Abfrage ein, z.B.
SELECT * from data;. - Drücken Sie STRG+EINGABETASTE, um die Abfrage auszuführen. Standardmäßig gibt SQuirrel SQL die ersten 100 Zeilen für die Abfrage zurück.
Es gibt noch viele weitere Abfragen, die Sie ausführen können, um diese Daten zu untersuchen. Wie unterscheidet sich die Häufigkeit des Worts make beispielsweise für „Spam“ und „Ham“?
SELECT avg(word_freq_make), spam from data group by spam;
Oder: Wie lauten die Merkmale von E-Mails, die häufig den Ausdruck 3d enthalten?
SELECT * from data order by word_freq_3d desc;
Die meisten E-Mails, die ein hohes Vorkommen von 3d aufweisen, sind offenbar Spam. Diese Informationen können für das Erstellen eines Vorhersagemodells zur Klassifizierung von E-Mails nützlich sein.
Wenn Sie einen Machine Learning-Vorgang mit Daten durchführen möchten, die in einer PostgreSQL-Datenbank gespeichert sind, können Sie auch MADlib verwenden.
Azure Synapse Analytics (ehemals SQL DW)
Azure Synapse Analytics ist eine cloudbasierte Datenbank für die horizontale Skalierung, mit der sehr große Datenvolumen verarbeitet werden können, und zwar sowohl relational als auch nicht relational. Weitere Informationen finden Sie unter Was ist Azure Synapse Analytics?.
Führen Sie an einer Eingabeaufforderung den folgenden Befehl aus, um eine Verbindung mit dem Data Warehouse herzustellen und die Tabelle zu erstellen:
sqlcmd -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -I
Führen Sie an der sqlcmd-Eingabeaufforderung den folgenden Befehl aus:
CREATE TABLE spam (word_freq_make real, word_freq_address real, word_freq_all real, word_freq_3d real,word_freq_our real, word_freq_over real, word_freq_remove real, word_freq_internet real,word_freq_order real, word_freq_mail real, word_freq_receive real, word_freq_will real,word_freq_people real, word_freq_report real, word_freq_addresses real, word_freq_free real,word_freq_business real, word_freq_email real, word_freq_you real, word_freq_credit real,word_freq_your real, word_freq_font real, word_freq_000 real, word_freq_money real,word_freq_hp real, word_freq_hpl real, word_freq_george real, word_freq_650 real, word_freq_lab real,word_freq_labs real, word_freq_telnet real, word_freq_857 real, word_freq_data real,word_freq_415 real, word_freq_85 real, word_freq_technology real, word_freq_1999 real,word_freq_parts real, word_freq_pm real, word_freq_direct real, word_freq_cs real, word_freq_meeting real,word_freq_original real, word_freq_project real, word_freq_re real, word_freq_edu real,word_freq_table real, word_freq_conference real, char_freq_semicolon real, char_freq_leftParen real,char_freq_leftBracket real, char_freq_exclamation real, char_freq_dollar real, char_freq_pound real, capital_run_length_average real, capital_run_length_longest real, capital_run_length_total real, spam integer) WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = ROUND_ROBIN);
GO
Kopieren Sie die Daten mit bcp:
bcp spam in spambaseHeaders.data -q -c -t ',' -S <server-name>.database.windows.net -d <database-name> -U <username> -P <password> -F 1 -r "\r\n"
Hinweis
Die Downloaddatei enthält Zeilenenden im Windows-Stil. Das bcp-Tool erwartet Zeilenenden im Unix-Stil. Verwenden Sie das Flag -r, um bcp zu informieren.
Führen Sie dann die Abfrage mit sqlcmd aus:
select top 10 spam, char_freq_dollar from spam;
GO
Sie können die Abfrage auch mithilfe von SQuirreL SQL ausführen. Führen Sie die Schritte ähnlich wie bei PostgreSQL mit dem SQL Server JDBC-Treiber aus. Der JDBC-Treiber befindet sich im Ordner „/usr/share/java/jdbcdrivers/sqljdbc42.jar“.