Der Team Data Science-Prozess (TDSP) ist eine flexible, iterative Data Science-Methodik, die Sie zur effizienten Bereitstellung von Predictive Analytics-Lösungen und KI-Anwendungen verwenden können. Der TDSP kann die Zusammenarbeit und das Lernen im Team mit Vorschlägen zur optimalen Zusammenarbeit von Teamrollen verbessern. Der TDSP umfasst bewährte Methoden und Strukturen von Microsoft und anderen branchenführenden Unternehmen, um Ihrem Team zu helfen, Data Science-Initiativen erfolgreich zu implementieren und das ganze Potenzial Ihres Analyseprogramms zu realisieren.
Dieser Artikel bietet eine Übersicht über den TDSP und seine Hauptkomponenten. Er enthält Anleitungen für die Implementierung des TDSP mit Microsoft-Tools und -Infrastruktur. Sie finden im Artikel auch Informationen zu ausführlicheren Ressourcen.
Hauptkomponenten des TDSP
Der TDSP umfasst die folgenden Hauptkomponenten:
- Eine Definition des Data Science-Lebenszyklus
- Eine standardisierte Projektstruktur
- Infrastruktur und Ressourcen, die für Data Science-Projekte empfohlen werden
- Tools und Hilfsprogramme, die für die Projektausführung empfohlen werden
Data Science-Lebenszyklus
Der TDSP stellt einen Lebenszyklus bereit, mit dem Sie die Entwicklung Ihrer Data Science-Projekte strukturieren können. Der Lebenszyklus beschreibt sämtliche Schritte für erfolgreiche Projekte.
Sie können den aufgabenbasierten TDSP mit anderen Data Science-Lebenszyklen kombinieren, z. B.dem Cross Industry Standard Process for Data Mining (CRISP-DM), dem Knowledge Discovery in Databases (KDD)-Prozess oder anderen, benutzerdefinierten Prozessen. Auf allgemeiner Ebene haben diese verschiedenen Methodiken viel gemeinsam.
Sie sollten diesen Lebenszyklus verwenden, wenn Sie an einem Data Science-Projekt arbeiten, das Teil einer intelligenten Anwendung ist. Intelligente Anwendungen stellen Machine-Learning- oder KI-Modelle für Predictive Analytics bereit. Sie können diesen Prozess auch für explorative Data Science-Projekte und improvisierte Analyseprojekte verwenden.
Der TDSP-Lebenszyklus besteht aus fünf Hauptphasen, die von Ihrem Team immer wieder wiederholt werden. Diese Phasen umfassen:
Dies ist eine visuelle Darstellung des TDSP-Lebenszyklus:
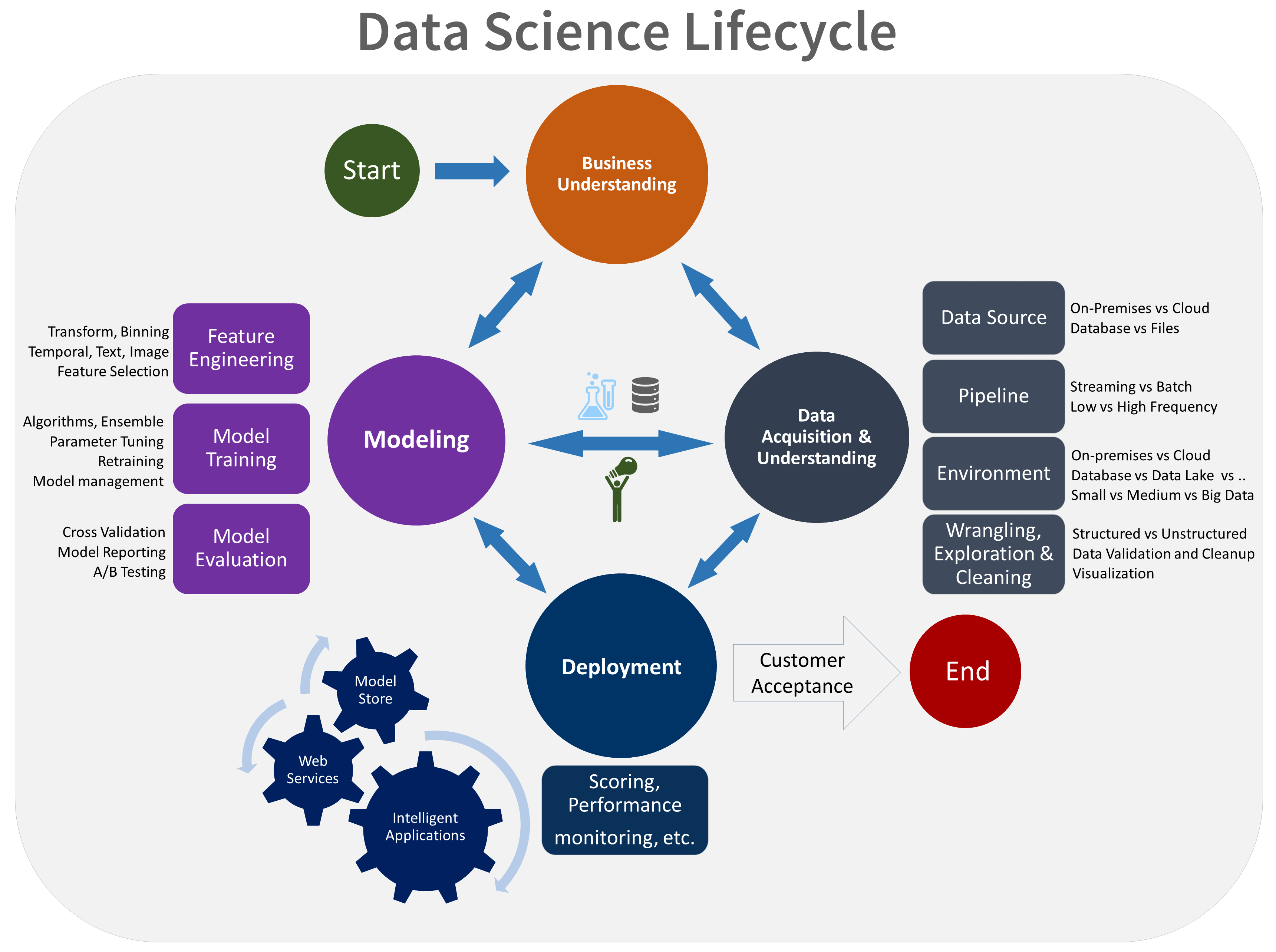
Informationen zu den Zielen, Aufgaben und Dokumentationsartefakten für jede Phase finden Sie unter Lebenszyklus des Team Data Science-Prozesses.
Diese Aufgaben und Artefakte sind Projektrollen zugeordnet, zum Beispiel:
- Lösungsarchitekt.
- Projektleiter.
- Data Engineer.
- Datenanalyst:
- Anwendungsentwickler.
- Projektleiter.
Das folgende Diagramm zeigt die Aufgaben (blau) und Artefakte (grün), die den einzelnen Phasen des Lebenszyklus (auf der horizontalen Achse) für diese Rollen (auf der vertikalen Achse) zugeordnet sind.

Standardisierte Projektstruktur
Ihr Team kann zur Organisation Ihrer Data Science-Ressourcen die Azure-Infrastruktur verwenden.
Azure Machine Learning unterstützt das Open-Source-MLflow-Modell. Wir empfehlen, für die Verwaltung von Data Science- und KI-Projekten MLflow zu verwenden. MLflow wurde für die Verwaltung des gesamten Machine Learning-Lebenszyklus entwickelt. Die Lösung trainiert und implementiert Modelle auf verschiedenen Plattformen, sodass Sie einen konsistenten Satz von Tools verwenden können – unabhängig von der Umgebung, in der Ihre Experimente ausgeführt werden. Sie können MLflow lokal auf Ihrem Computer, auf einem Remote-Computeziel, auf einem virtuellen Computer oder auf einer Machine Learning Compute-Instanz verwenden.
MLflow besitzt mehrere wichtige Funktionen:
Nachverfolgen von Experimenten: Mit MLflow können Sie Experimente nachverfolgen, einschließlich Parametern, Codeversionen, Metriken und Ausgabedateien. Mithilfe dieser Funktion können Sie verschiedene Ausführungen vergleichen und den Experimentierprozess effizient verwalten.
Paketcode: MLflow stellt ein standardisiertes Format zum Paketieren von Machine Learning-Code bereit, das Abhängigkeiten und Konfigurationen umfasst. Diese Paketierung vereinfacht das Reproduzieren von Ausführungen und Teilen von Code mit anderen Mitgliedern des Teams.
Verwalten von Modellen: MLflow stellt Funktionen zum Verwalten und Versionieren von Modellen bereit. Die Lösung unterstützt verschiedene Machine Learning-Frameworks, sodass Sie Modelle speichern, versionieren und bereitstellen können.
Bereitstellen von Modellen: MLflow integriert Funktionen für die Bereitstellung von Modellen, sodass Sie Modelle problemlos in verschiedenen Umgebungen bereitstellen können.
Registrieren von Modellen: Sie können den Lebenszyklus eines Modells verwalten, einschließlich Versionsverwaltung, Phasenübergängen und Anmerkungen. MLflow ist nützlich, um in einer Teamumgebung einen zentralen Modellspeicher zu warten.
Verwenden einer API und Benutzeroberfläche: In Azure ist MLflow in Machine Learning API Version 2 gebündelt, sodass Sie programmgesteuert mit dem System interagieren können. Sie können für die Interaktion mit einer Benutzeroberfläche das Azure-Portal verwenden.
MLflow soll die Machine Learning-Entwicklung vereinfachen und standardisieren, von der Experimentierung bis zur Bereitstellung.
Machine Learning ist in Git-Repositorys integriert, sodass Sie Git-kompatible Dienste verwenden können: GitHub, GitLab, Bitbucket, Azure DevOps oder einen anderen Git-kompatiblen Dienst. Zusätzlich zu den Ressourcen, die im Machine Learning bereits nachverfolgt werden, kann Ihr Team eine eigene Taxonomie innerhalb des Git-kompatiblen Diensts entwickeln, um weitere Projektinformationen zu speichern, z. B.:
- Dokumentation
- Projekt, z. B. der endgültige Projektbericht
- Datenbericht, z. B. Datenwörterbuch oder Berichte zur Datenqualität
- Modell, z. B. Beispielmodellberichte///
- Code
- Datenaufbereitung
- Modellentwicklung
- Operationalisierung, einschließlich Sicherheit und Compliance
Infrastruktur und Ressourcen
Der TDSP umfasst Empfehlungen zum Verwalten der geteilten Analyse- und Speicherinfrastruktur, z. B.:
- Clouddateisysteme zum Speichern von Datasets
- Datenbanken
- Big-Data-Cluster, z. B. SQL oder Spark
- Dienste für maschinelles Lernen
Sie können die Analyse- und Speicherinfrastruktur, in der unverarbeitete und verarbeitete Datasets gespeichert werden, in der Cloud oder lokal einrichten. Diese Infrastruktur ermöglicht reproduzierbare Analysen. Sie verhindert außerdem eine Duplizierung, was zu Inkonsistenzen und unnötigen Infrastrukturkosten führen kann. Die Infrastruktur enthält Tools für die Bereitstellung und Nachverfolgung der geteilten Ressourcen und ermöglicht allen Teammitgliedern die Herstellung einer sicheren Verbindung zu diesen Ressourcen. Projektmitglieder sollten außerdem eine konsistente Compute-Umgebung erstellen. Die einzelnen Teammitglieder können dann Experimente replizieren und überprüfen.
Im Folgenden finden Sie ein Beispiel für ein Team, das an mehreren Projekten arbeitet und verschiedene Analyseinfrastrukturkomponenten in der Cloud teilt:

Tools und Hilfsprogramme
In den meisten Organisationen stellt die Einführung von Prozessen eine Herausforderung dar. Die Infrastruktur stellt Tools für die Implementierung von TDSP und Lebenszyklusverwaltung bereit. Dies reduziert die Hürden und verbessert die Konsistenz der Einführung.
Mit Machine Learning können Data Scientists Open-Source-Tools als Teil von Data Science-Pipelines oder -Workflows anwenden. Microsoft verwendet verantwortungsvolle KI-Tools in Machine Learning. Dies hilft Microsoft, die Anforderungen seines Standards für verantwortungsvolle KI zu erfüllen.
Peer-geprüfte Referenzen
Der TDSP ist eine gut etablierte Methodik, die in Microsoft-Projekten verwendet wird und in Peer-geprüfter Literatur dokumentiert und untersucht wurde. Diese Referenzen bieten die Möglichkeit, TDSP-Funktionen und -Anwendungen zu untersuchen. Eine Liste mit Referenzen finden Sie auf der Seite mit einer Übersicht über den Lebenszyklus .