Auslösen von Machine Learning-Pipelines
GILT FÜR: Python SDK azureml v1
Python SDK azureml v1
In diesem Artikel erfahren Sie, wie Sie programmgesteuert eine Pipeline für die Ausführung in Azure planen. Sie können einen Plan erstellen, der auf verstrichener Zeit oder auf Änderungen im Dateisystem beruht. Zeitbasierte Pläne können zum Erledigen von Routineaufgaben (z.B. Datendriftüberwachung) verwendet werden. Pläne auf Basis von Änderungen können für die Reaktion auf unregelmäßige bzw. unvorhersehbare Änderungen (z.B. Hochladen neuer Daten oder Bearbeiten alter Daten) verwendet werden. Nachdem Sie gelernt haben, wie Pläne erstellt werden, erfahren Sie, wie Sie diese abrufen und deaktivieren können. Schließlich erfahren Sie, wie Sie andere Azure-Dienste, Azure Logic App und Azure Data Factory zur Ausführung von Pipelines verwenden können. Eine Azure Logic App ermöglicht eine komplexere Logik oder ein komplexeres Verhalten für die Auslösung. Mit Azure Data Factory-Pipelines können Sie eine Machine Learning-Pipeline als Teil einer größeren Datenorchestrierung aufrufen.
Voraussetzungen
Ein Azure-Abonnement. Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen.
Eine Python-Umgebung, in der das Azure Machine Learning SDK für Python installiert ist. Weitere Informationen finden Sie unter Erstellen und Verwalten von wiederverwendbaren Umgebungen für Training und Bereitstellung mit Azure Machine Learning.
Ein Machine Learning-Arbeitsbereich mit einer veröffentlichten Pipeline. Sie können die Pipeline verwenden, die in Erstellen und Ausführen von Machine Learning-Pipelines mit dem Azure Machine Learning SDK erstellt wurde.
Auslösen von Pipelines mit dem Azure Machine Learning SDK für Python
Zum Planen einer Pipeline benötigen Sie einen Verweis auf Ihren Arbeitsbereich, den Bezeichner (ID) der veröffentlichten Pipeline und den Namen des Experiments, in dem Sie den Plan erstellen möchten. Diese Werte können Sie mithilfe des folgenden Codes abrufen:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Erstellen eines Zeitplans
Wenn eine Pipeline regelmäßig ausgeführt werden soll, erstellen Sie einen Plan. Ein Schedule verknüpft eine Pipeline, ein Experiment und einen Auslöser. Der Auslöser kann entweder vom Typ ScheduleRecurrence sein, der die Wartezeit zwischen den Aufträgen beschreibt, oder ein Datenspeicherpfad, der ein Verzeichnis angibt, das auf Änderungen überwacht werden soll. In beiden Fällen benötigen Sie die ID der Pipeline und den Namen des Experiments, in dem der Plan erstellt werden soll.
Importieren Sie am Anfang der Python-Datei die Klassen Schedule und ScheduleRecurrence:
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Erstellen eines zeitbasierten Plans
Der ScheduleRecurrence-Konstruktor verfügt über das erforderliche frequency-Argument, das einer der folgenden Zeichenfolgen entsprechen muss: „Minute“, „Stunde“, „Tag“, „Woche“ oder „Monat“. Außerdem wird ein ganzzahliges interval-Argument benötigt, das angibt, wie viele frequency-Einheiten zwischen den einzelnen Starts des Zeitplans verstreichen sollen. Optionale Argumente ermöglichen Ihnen eine genauere Angabe der Startzeiten, wie in der Dokumentation zum ScheduleRecurrence SDK ausführlich erläutert.
Erstellen Sie einen Schedule, der alle 15 Minuten einen Auftrag startet:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Erstellen eines änderungsbasierten Plans
Pipelines, die durch Dateiänderungen ausgelöst werden, sind möglicherweise effizienter als zeitbasierte Pläne. Wenn Sie vor dem Ändern einer Datei oder dem Hinzufügen einer neuen Datei zu einem Datenverzeichnis etwas unternehmen möchten, können Sie diese Datei vorverarbeiten. Sie können alle Änderungen an einem Datenspeicher oder Änderungen in einem bestimmten Verzeichnis des Datenspeichers überwachen. Wenn Sie ein bestimmtes Verzeichnis überwachen, lösen Änderungen in den Unterverzeichnissen dieses Verzeichnisses keinen Auftrag aus.
Hinweis
Änderungsbasierte Zeitpläne unterstützen nur die Überwachung von Azure Blob Storage.
Um einen Schedule zu erstellen, der auf Dateiänderungen reagiert, müssen Sie den datastore-Parameter im Aufruf auf Schedule.create festlegen. Zum Überwachen eines Ordners legen Sie das path_on_datastore-Argument fest.
Mit dem polling_interval-Argument können Sie das Intervall, in dem der Datenspeicher auf Änderungen geprüft wird, in Minuten angeben.
Wenn die Pipeline mit DataPathPipelineParameter erstellt wurde, können Sie durch Festlegen des data_path_parameter_name-Arguments diese Variable auf den Namen der geänderten Datei einstellen.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Optionale Argumente beim Erstellen eines Plans
Neben den zuvor beschriebenen Argumenten können Sie das status-Argument auf "Disabled" einstellen, um einen inaktiven Plan zu erstellen. Schließlich können Sie noch mit continue_on_step_failure einen booleschen Wert übergeben, der das standardmäßige Fehlerverhalten der Pipeline überschreibt.
Anzeigen der geplanten Pipelines
Navigieren Sie in Ihrem Webbrowser zu Azure Machine Learning. Wählen Sie im Navigationsbereich im Bereich Endpunkte den Eintrag Pipelineendpunkte aus. Dadurch gelangen Sie zu einer Liste der im Arbeitsbereich veröffentlichten Pipelines.
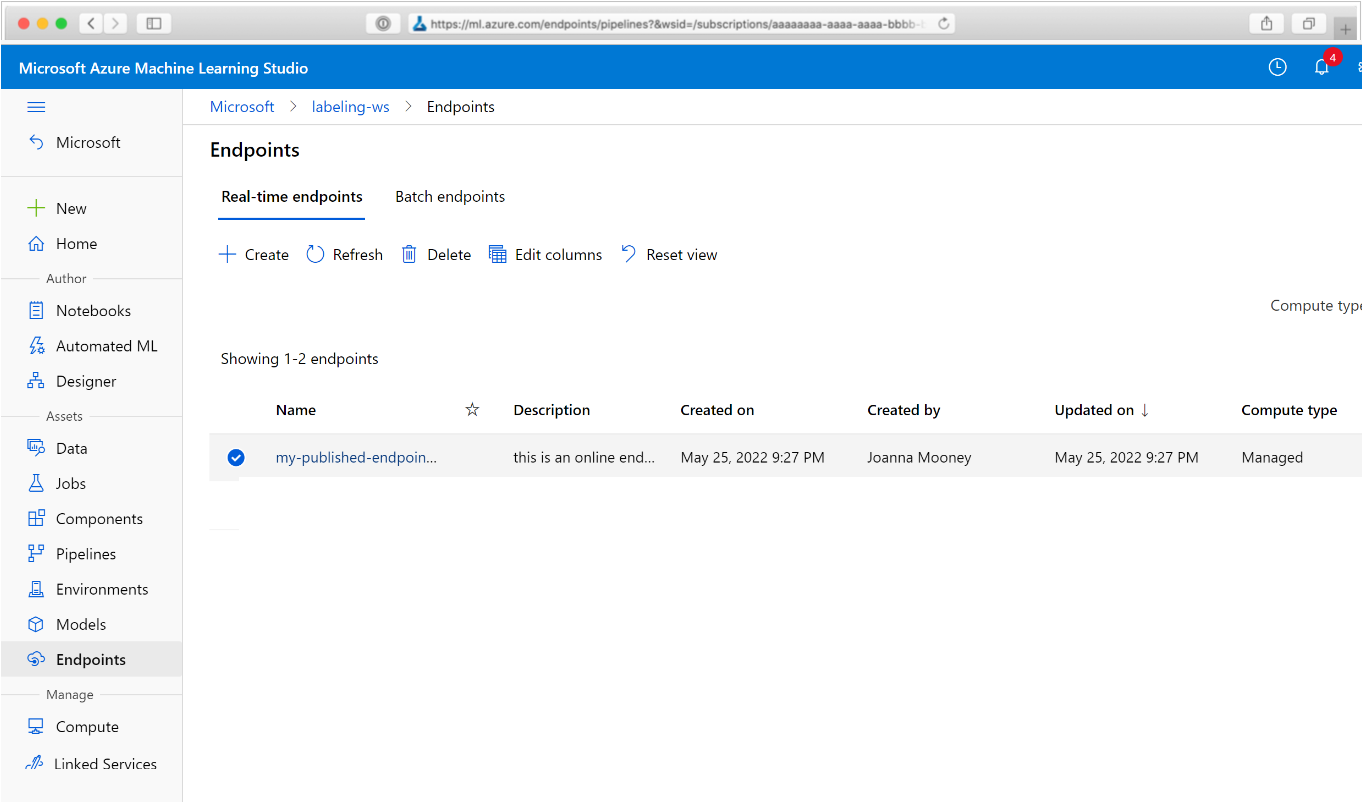
Auf dieser Seite können Sie Übersichtsinformationen wie Name, Beschreibung, Status usw. zu allen Pipelines im Arbeitsbereich anzeigen. Durch Klicken auf eine Pipeline erhalten Sie ausführlichere Informationen. Auf der Seite, die dann geöffnet wird, finden Sie weitere Details zu Ihrer Pipeline und können einzelne Aufträge genauer betrachten.
Deaktivieren der Pipeline
Wenn Sie über eine Pipeline verfügen, die zwar veröffentlicht, aber noch nicht geplant wurde, können Sie diese wie folgt deaktivieren:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Wenn die Pipeline bereits geplant ist, müssen Sie zuerst den Plan abbrechen. Rufen Sie die ID des Plans aus dem Portal ab, oder führen Sie folgenden Befehl aus:
ss = Schedule.list(ws)
for s in ss:
print(s)
Sobald Sie über die schedule_id des zu deaktivierenden Plans verfügen, führen Sie Folgendes aus:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Wenn Sie dann Schedule.list(ws) erneut ausführen, sollte eine leere Liste angezeigt werden.
Verwenden von Azure Logic Apps für komplexere Workflows
Komplexere Triggerregeln oder komplexeres Verhalten können mithilfe einer Azure-Logik-App erstellt werden.
Um eine Azure-Logik-App zum Auslösen einer Machine Learning-Pipeline zu verwenden, benötigen Sie den REST-Endpunkt für eine veröffentlichte Machine Learning-Pipeline. Erstellen und veröffentlichen Sie Ihre Pipeline. Suchen Sie anschließend mithilfe der Pipeline-ID den REST-Endpunkt Ihrer PublishedPipeline:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Erstellen Sie eine Logik-App in Azure
Erstellen Sie nun eine Azure Logic Apps-Instanz. Führen Sie nach der Bereitstellung Ihrer Logik-App die folgenden Schritte aus, um einen Trigger für Ihre Pipeline zu konfigurieren:
Erstellen Sie eine systemseitig zugewiesene verwaltete Identität, um der App Zugriff auf Ihren Azure Machine Learning-Arbeitsbereich zu gewähren.
Navigieren Sie zur Logik-App-Designer-Ansicht, und wählen Sie die Vorlage „Leere Logik-App“ aus.
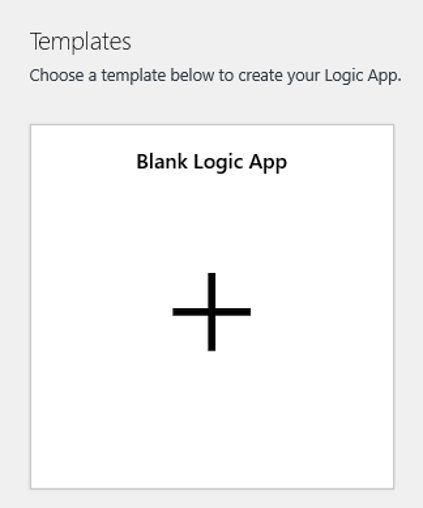
Suchen Sie im Designer nach Blob. Wählen Sie den Trigger Beim Hinzufügen oder Ändern eines Blobs (nur Eigenschaften) aus, und fügen Sie diesen Trigger Ihrer Logik-App hinzu.
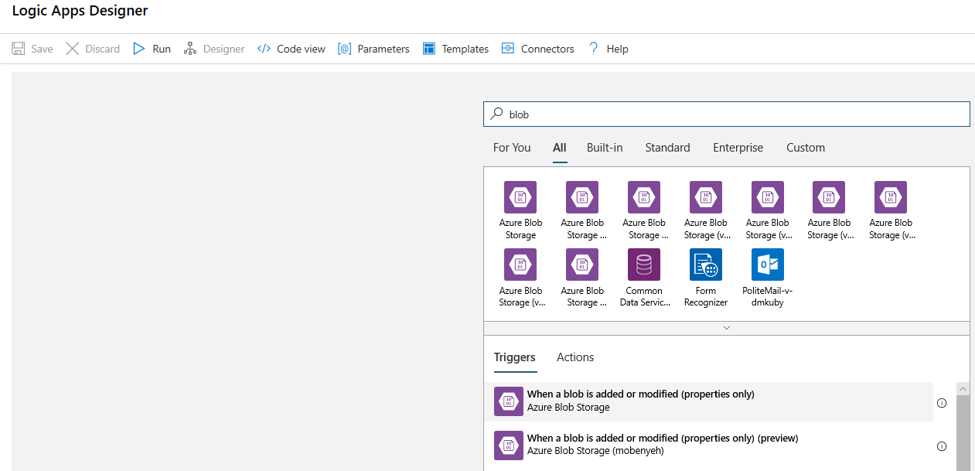
Geben Sie die Verbindungsinformationen für das Blob Storage-Konto ein, das Sie auf Ergänzungen oder Änderungen an Blobs überwachen möchten. Wählen Sie den zu überwachenden Container aus.
Wählen Sie ein für Sie geeignetes Intervall und eine Häufigkeit für den Abruf von Updates aus.
Hinweis
Mit diesem Auslöser wird der ausgewählte Container überwacht, jedoch keine Unterordner.
Fügen Sie eine HTTP-Aktion hinzu, die ausgeführt wird, wenn ein neues oder geändertes Blob erkannt wird. Wählen Sie + Neuer Schritt aus, suchen Sie nach der HTTP-Aktion, und wählen Sie sie aus.
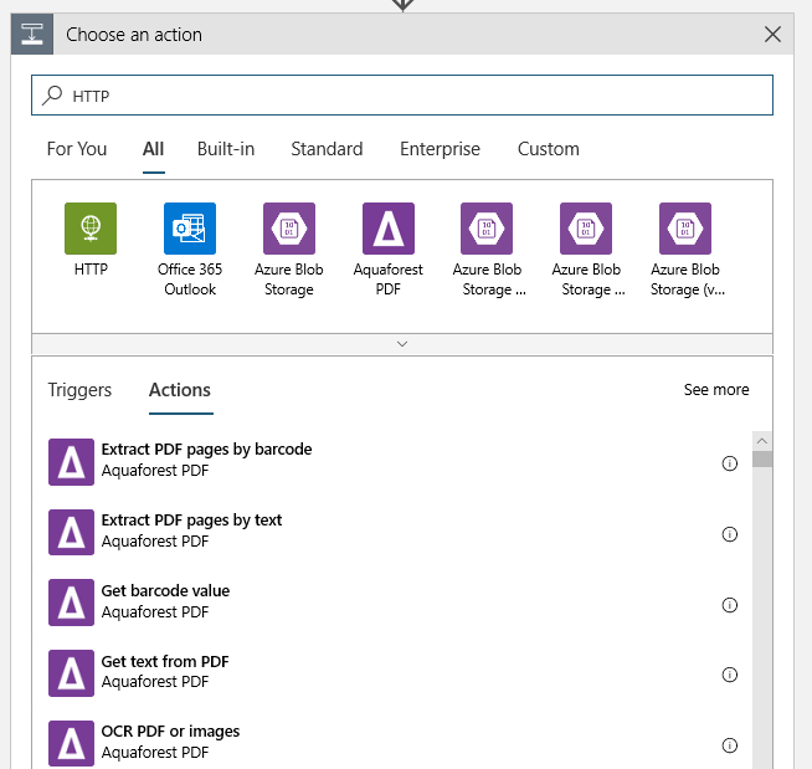
Konfigurieren Sie Ihre Aktion mit den folgenden Einstellungen:
| Einstellung | Wert |
|---|---|
| HTTP-Aktion | POST |
| URI | Der Endpunkt für die veröffentlichte Pipeline, den Sie als Voraussetzung festgelegt haben |
| Authentifizierungsmodus | Verwaltete Identität |
Richten Sie Ihren Zeitplan so ein, dass ggf. der Wert aller DataPath-Pipelineparameter festgelegt wird:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Verwenden Sie den
DataStoreName, den Sie Ihrem Arbeitsbereich als Voraussetzung hinzugefügt haben.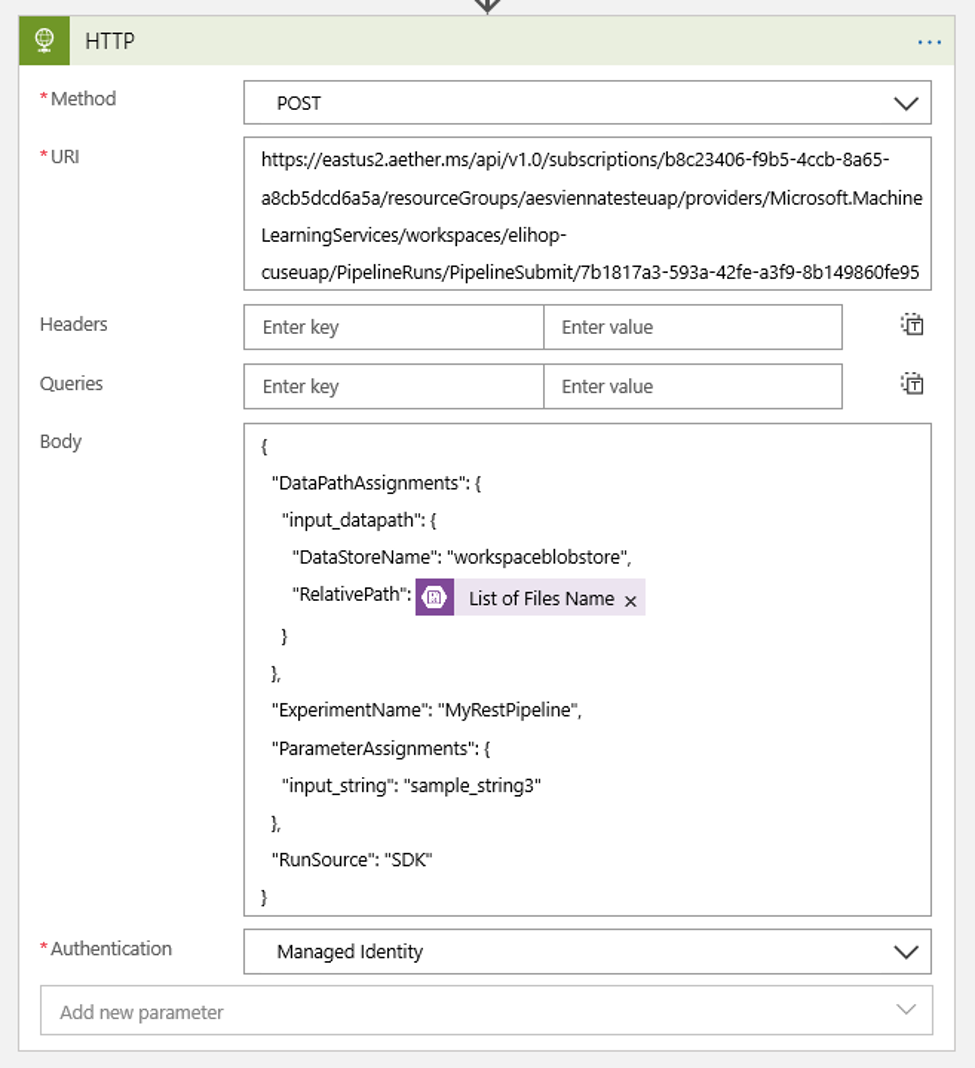
Wählen Sie Speichern aus. Der Zeitplan ist nun bereit.
Wichtig
Wenn Sie mit der rollenbasierten Zugriffssteuerung in Azure (Azure RBAC) den Zugriff auf Ihre Pipeline verwalten, legen Sie die Berechtigungen für Ihr Pipelineszenario fest (Training oder Bewertung).
Aufrufen von Machine Learning-Pipelines über Azure Data Factory
In einer Azure Data Factory-Pipeline führt die Aktivität Machine Learning-Pipelineausführung eine Azure Machine Learning-Pipeline aus. Sie finden diese Aktivität auf der Data Factory-Erstellungsseite unter der Kategorie Machine Learning:
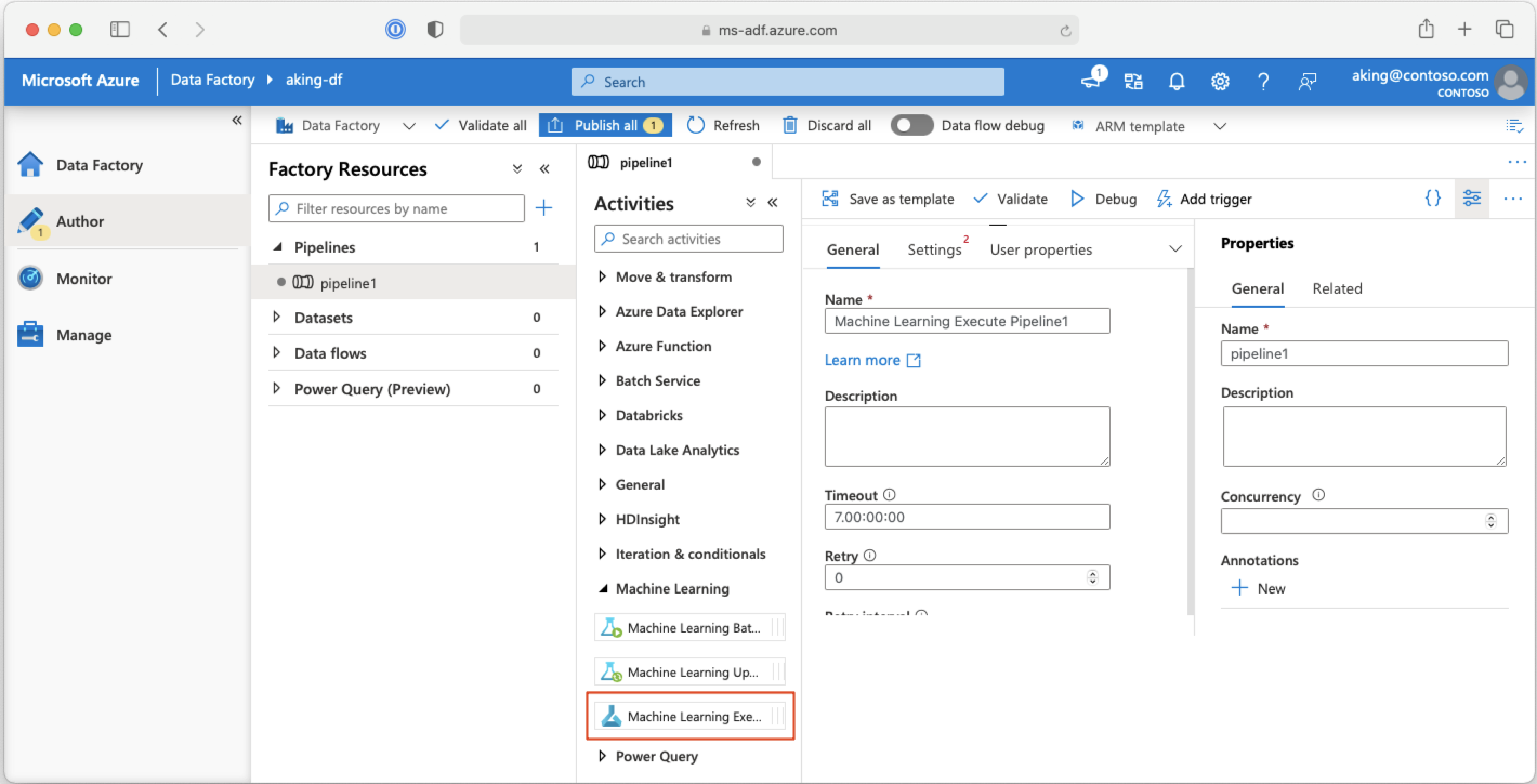
Nächste Schritte
In diesem Artikel haben Sie das Azure Machine Learning SDK für Python verwendet, um eine Pipeline auf zwei verschiedene Arten zu planen. Ein Plan wiederholt sich auf Basis der verstrichenen Uhrzeit. Die anderen geplanten Aufträge werden ausgeführt, wenn eine Datei in einem angegebenen Datastore oder in einem Verzeichnis in diesem Speicher geändert wird. Sie haben erfahren, wie Sie das Portal zum Untersuchen von Pipelines und einzelnen Aufträgen verwenden können. Sie haben gelernt, wie Sie einen Plan deaktivieren, damit die Pipeline nicht mehr ausgeführt wird. Schließlich haben Sie eine Azure-Logik-App erstellt, um eine Pipeline auszulösen.
Weitere Informationen finden Sie unter
- Weitere Informationen zu Pipelines
- Erfahren Sie mehr über das Erkunden von Azure Machine Learning mit Jupyter