Versionieren und Nachverfolgen von Azure Machine Learning-Datasets
GILT FÜR: Python SDK azureml v1
Python SDK azureml v1
In diesem Artikel erfahren Sie, wie Sie Azure Machine Learning-Datasets für die Reproduzierbarkeit versionieren und nachverfolgen. Mithilfe einer Datasetversionierung können Sie den Zustand der Daten markieren, sodass Sie eine bestimmte Version des Datasets für zukünftige Experimente verwenden können.
Sie können Ihre Azure Machine Learning-Ressourcen in den folgenden typischen Szenarios versionieren:
- Wenn neue Daten für ein erneutes Training verfügbar sind
- Wenn Sie verschiedene Ansätze für Datenaufbereitung oder Feature Engineering anwenden
Voraussetzungen
Das Azure Machine Learning SDK für Python. Dieses SDK enthält das Paket azureml-datasets.
Ein Azure Machine Learning-Arbeitsbereich. Erstellen Sie einen neuen Arbeitsbereich, oder rufen Sie mit diesem Beispielcode einen vorhandenen Arbeitsbereich ab:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Registrieren und Abrufen von Datasetversionen
Sie können ein registriertes Dataset versionieren, wiederverwenden und in Experimenten und mit Kollegen teilen. Sie können mehrere Datasets unter dem gleichen Namen registrieren und eine bestimmte Version anhand des Namens und der Versionsnummer abrufen.
Registrieren einer Datasetversion
In diesem Beispielcode wird der create_new_version-Parameter des titanic_ds-Datasets auf True festgelegt, um eine neue Version dieses Datasets zu registrieren. Wenn im Arbeitsbereich kein vorhandenes titanic_ds-Dataset registriert ist, erstellt der Code ein neues Dataset mit dem Namen titanic_ds und legt dessen Version auf 1 fest.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Abrufen eines Datasets anhand des Namens
Die get_by_name()-Methode der Dataset-Klasse gibt standardmäßig die neueste Version des im Arbeitsbereich registrierten Datasets zurück.
Dieser Code gibt Version 1 des titanic_ds-Datasets zurück.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Best Practices für die Versionierung
Wenn Sie eine Datasetversion erstellen, erstellen Sie keine zusätzliche Kopie der Daten im Arbeitsbereich. Da Datasets auf die Daten in Ihrem Speicherdienst verweisen, verfügen Sie über eine einzelne zuverlässige Datenquelle, die von Ihrem Speicherdienst verwaltet wird.
Wichtig
Wenn die Daten, auf die vom Dataset verwiesen wird, überschrieben oder gelöscht werden, wird die Änderung beim Aufrufen einer bestimmten Version des Datasets nicht rückgängig gemacht.
Wenn Sie Daten aus einem Dataset laden, wird immer der aktuelle Dateninhalt geladen, auf den das Dataset verweist. Wenn Sie sicherstellen möchten, dass jede Datasetversion reproduzierbar ist, wird empfohlen, den Dateninhalt, auf den die Datasetversion verweist, nicht zu ändern. Wenn neue Daten eingehen, speichern Sie neue Datendateien in einem separaten Datenordner, und erstellen Sie dann eine neue Datasetversion, um Daten aus diesem neuen Ordner einzubinden.
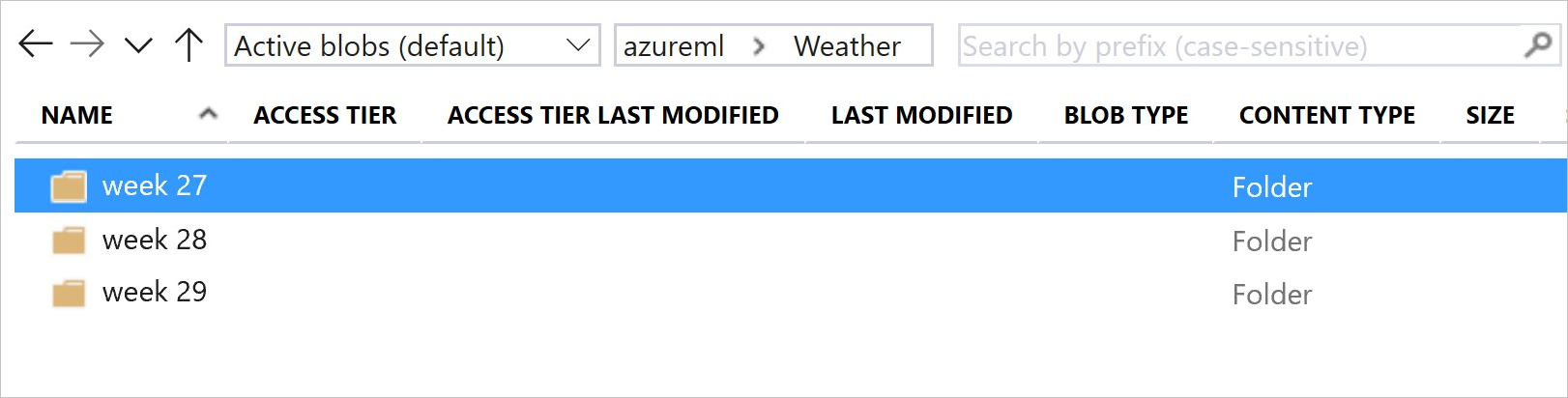
Die Abbildung und der Beispielcode zeigen die empfohlene Vorgehensweise zum Strukturieren Ihrer Datenordner und zum Erstellen von Datasetversionen, die auf diese Ordner verweisen:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Version eines ML-Pipelineausgabe-Datasets
Sie können ein Dataset als Eingabe und Ausgabe für jeden Schritt der ML-Pipeline verwenden. Wenn Sie Pipelines erneut ausführen, wird die Ausgabe der einzelnen Pipelineschritte als neue Datasetversion registriert.
Machine Learning-Pipelines füllen immer dann, wenn die Pipelines neu ausgeführt werden, die Ausgabe jedes Schritts in einen neuen Ordner. Die versionierten Ausgabedatasets werden dann reproduzierbar. Weitere Informationen finden Sie unter Datasets in Pipelines.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Nachverfolgen von Daten in Ihren Experimenten
Azure Machine Learning verfolgt Ihre Daten im gesamten Experiment als Eingabe- und Ausgabedatasets nach. In diesen Szenarios werden Ihre Daten als Eingabedataset nachverfolgt:
Beim Übermitteln des Experimentauftrags entweder über den
inputs- oderarguments-Parameter desScriptRunConfig-Objekts alsDatasetConsumptionConfig-ObjektWenn Ihr Skript bestimmte Methoden aufruft, z. B.
get_by_name()oderget_by_id(). Es wird der Name angezeigt, der dem Dataset bei der Registrierung im Arbeitsbereich zugewiesen wurde.
In diesen Szenarios werden Ihre Daten als Ausgabedataset nachverfolgt:
Übergeben Sie ein
OutputFileDatasetConfig-Objekt entweder über denoutputs- oderarguments-Parameter, wenn ein Experimentauftrag gesendet wird. MitOutputFileDatasetConfig-Objekten können Daten auch zwischen Pipelineschritten beibehalten werden. Weitere Informationen finden Sie unter Verschieben von Daten zwischen ML-Pipelineschritten (Python).Registrieren Sie ein Dataset in Ihrem Skript. Es wird der Name angezeigt, der dem Dataset bei der Registrierung im Arbeitsbereich zugewiesen wurde. In diesem Beispielcode ist
training_dsder angezeigte Name:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Übermitteln Sie einen untergeordneten Auftrag mit einem nicht registrierten Dataset im Skript. Dies führt zu einem anonymen gespeicherten Dataset.
Ablaufverfolgung von Datasets in Experimentaufträgen
Für jedes Machine Learning-Experiment können Sie die Eingabedatasets für das Job-Objekt des Experiments nachverfolgen. In diesem Beispielcode wird die get_details()-Methode verwendet, um die Eingabedatasets nachzuverfolgen, die bei der Ausführung des Experiments verwendet wurden:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
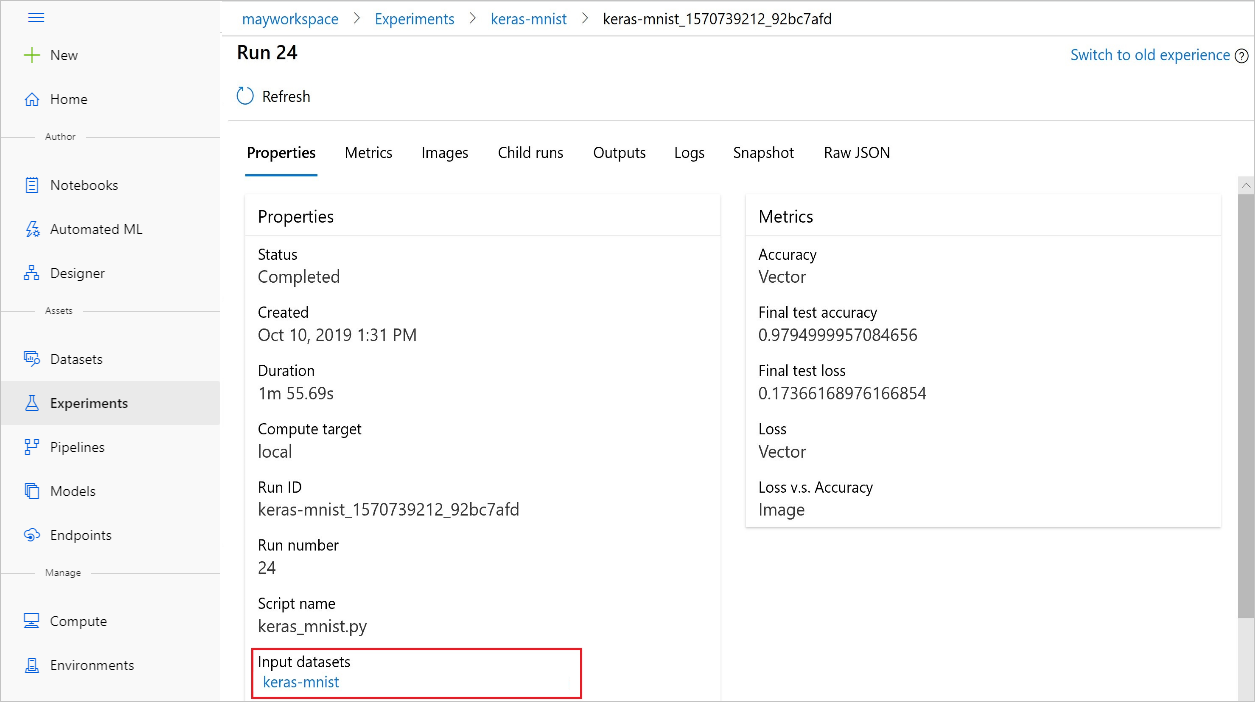
Die input_datasets aus den Experimenten können Sie auch mit dem Azure Machine Learning Studio suchen.
Dieser Screenshot zeigt, wo Sie das Eingabedataset eines Experiments im Azure Machine Learning Studio finden. Beginnen Sie in diesem Beispiel im Bereich Experimente, und öffnen Sie die Registerkarte Eigenschaften für eine bestimmte Ausführung Ihres Experiments, keras-mnist.
Mit diesem Code werden Modelle mit Datasets registriert:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
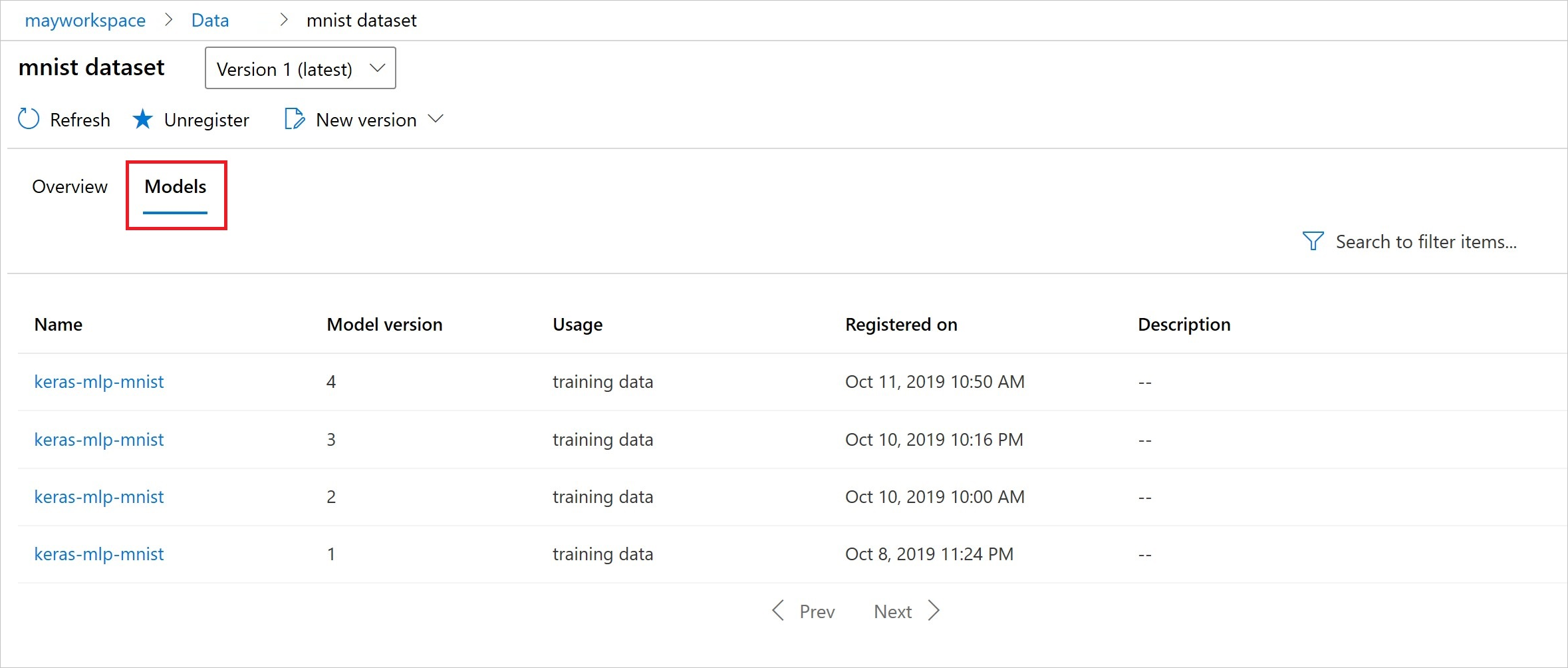
Nach der Registrierung können Sie die Liste der mit dem Dataset registrierten Modelle entweder mit Python oder im Studio einsehen.
Dieser Screenshot stammt aus dem Bereich Datasets unter Objekte. Wählen Sie das Dataset und dann die Registerkarte Modelle aus, um eine Liste der Modelle anzuzeigen, die mit dem Dataset registriert sind.