Analysieren der Leistung in Azure AI Search
In diesem Artikel werden die Tools, Verhaltensweisen und Ansätze zum Analysieren der Abfrage- und Indizierungsleistung in Azure AI Search beschrieben.
Entwickeln von Baselinewerten
Bei jeder großen Implementierung ist es wichtig, einen Benchmarkleistungstest für Ihren Azure AI Search-Dienst zu durchführen, bevor Sie ihn in der Produktionsumgebung einsetzen. Sie sollten sowohl die erwartete Auslastung der Suchabfrage als auch die erwarteten Datenerfassungsworkloads testen (führen Sie beide Workloads nach Möglichkeit gleichzeitig aus). Benchmarkzahlen helfen dabei, die richtige Suchebene, die Dienstkonfiguration und die erwartete Abfragelatenz zu ermitteln.
Zur Erarbeitung von Benchmarks empfehlen wir das Tool azure-search-performance-testing (GitHub).
Testen Sie die Dienstkonfigurationen eines Replikats und einer Partition, um die Auswirkungen einer verteilten Dienstarchitektur zu isolieren.
Hinweis
Für die Tarife vom Typ „Storage Optimized“ (L1 und L2) sollten Sie einen geringeren Abfragedurchsatz und eine höhere Latenz als für die Tarife vom Typ „Standard“ erwarten.
Verwenden der Ressourcenprotokollierung
Das wichtigste Diagnosetool, das einem Administrator zur Verfügung steht, ist die Ressourcenprotokollierung. Die Ressourcenprotokollierung ist die Sammlung von Betriebsdaten und Metriken zu Ihrem Suchdienst. Die Diagnoseprotokollierung wird über Azure Monitor aktiviert. Mit der Verwendung von Azure Monitor und dem Speichern von Daten sind Kosten verbunden. Wenn Sie sie aber für Ihren Dienst aktivieren, kann dies bei der Untersuchung von Leistungsproblemen äußerst nützlich sein.
Die folgende Abbildung zeigt die Ereigniskette in einer Abfrageanforderung und -antwort. Latenz kann überall auftreten, unabhängig davon, ob während einer Netzwerkübertragung, einer Verarbeitung von Inhalten auf der App-Dienstebene oder in einem Suchdienst. Ein wichtiger Vorteil der Diagnoseprotokollierung ist, dass Aktivitäten aus Sicht des Suchdiensts protokolliert werden. Das bedeutet, dass Sie mithilfe des Protokolls bestimmen können, ob Leistungseinbußen auf Probleme mit der Abfrage oder Indizierung oder auf eine andere Fehlerquelle zurückgehen.
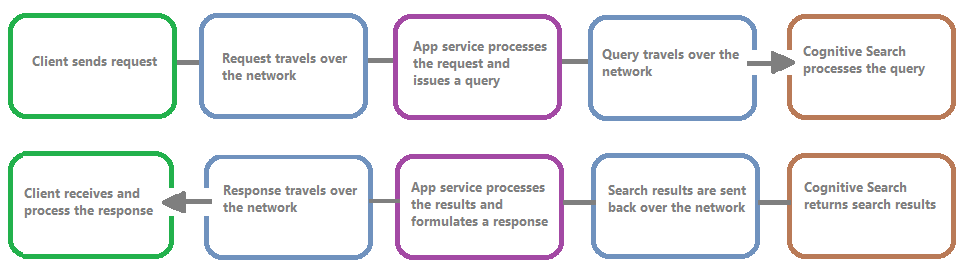
Die Ressourcenprotokollierung bietet Ihnen Optionen zum Speichern protokollierter Informationen. Es wird empfohlen, Log Analytics zu verwenden, damit Sie erweiterte Kusto-Abfragen für die Daten ausführen können, um viele Fragen zur Nutzung und Leistung zu beantworten.
Auf den Portalseiten ihres Suchdiensts können Sie die Protokollierung über Diagnoseeinstellungen aktivieren und dann Kusto-Abfragen für Log Analytics ausstellen, indem Sie Protokolle auswählen. Weitere Informationen finden Sie unter Sammeln und Analysieren von Protokolldaten.
Drosselungsverhalten
Drosselung tritt auf, wenn der Suchdienst voll ausgelastet ist. Zu einer Drosselung kann es während einer Abfrage oder einer Indizierung kommen. Auf Clientseite führt ein API-Aufruf zu einer 503-HTTP-Antwort, wenn er gedrosselt wurde. Während der Indizierung besteht auch die Möglichkeit, eine 207-HTTP-Antwort zu erhalten, die angibt, dass mindestens ein Element nicht indiziert werden konnte. Dieser Fehler zeigt an, dass sich der Suchdienst der Kapazität nähert.
Versuchen Sie als Faustregel, die Menge der Drosselung und aller Muster zu quantifizieren. Wenn beispielsweise eine von 500.000 Suchabfragen gedrosselt wird, erfordert dies möglicherweise keine weitere Untersuchung. Wenn jedoch ein großer Prozentsatz der Abfragen über einen bestimmten Zeitraum gedrosselt wird, ist dies ein ernstes Problem. Die Betrachtung der Drosselung über einen bestimmten Zeitraum hilft auch dabei, Zeiträume zu identifizieren, in denen eine Drosselung wahrscheinlicher ist. Zudem können Sie so entscheiden, wie Sie diese am besten berücksichtigen.
Eine einfache Lösung für die meisten Drosselungsprobleme besteht darin, dem Suchdienst mehr Ressourcen zur Verfügung zu stellen (typischerweise Replikate für abfragebasierte Drosselung oder Partitionen für indizierungsbasierte Drosselung). Das Erhöhen von Replikaten oder Partitionen verursacht jedoch zusätzliche Kosten, weshalb es wichtig ist, den Grund zu kennen, warum die Drosselung überhaupt auftritt. Die Untersuchung der Ursachen für eine Drosselung wird in den nächsten Abschnitten erläutert.
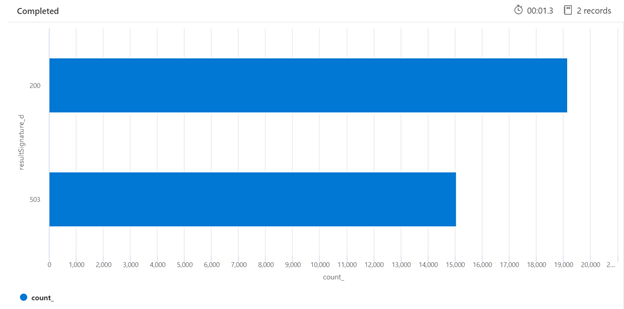
Im Folgenden finden Sie ein Beispiel für eine Kusto-Abfrage, die die Aufschlüsselung der HTTP-Antworten des ausgelasteten Suchdiensts identifizieren kann. Über einen Zeitraum von 7 Tagen zeigt das gerenderte Balkendiagramm an, dass ein relativ großer Prozentsatz der Suchabfragen gedrosselt wurde, im Vergleich zur Anzahl der erfolgreichen (200) Antworten.
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
Durch die Untersuchung der Drosselung über einen bestimmten Zeitraum lassen sich die Zeiten ermitteln, in denen die Drosselung möglicherweise häufiger auftritt. Im folgenden Beispiel wird ein Zeitreihendiagramm verwendet, um die Anzahl der gedrosselten Abfragen darzustellen, die innerhalb eines festgelegten Zeitraums aufgetreten sind. In diesem Fall entsprachen die gedrosselten Abfragen den Zeiten, in denen das Leistungsbenchmarking durchgeführt wurde.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart

Messen einzelner Abfragen
In einigen Fällen kann es hilfreich sein, die Leistung einzelner Abfragen zu testen. Dazu muss ersichtlich sein, wie lange der Suchdienst für die Bearbeitung benötigt und wie lange die Roundtripanforderung hin vom Client und zurück zum Client dauert. Die Diagnoseprotokolle könnten verwendet werden, um einzelne Vorgänge nachzuschlagen, aber es wäre vielleicht einfacher, dies alles über einen REST-Client zu tun.
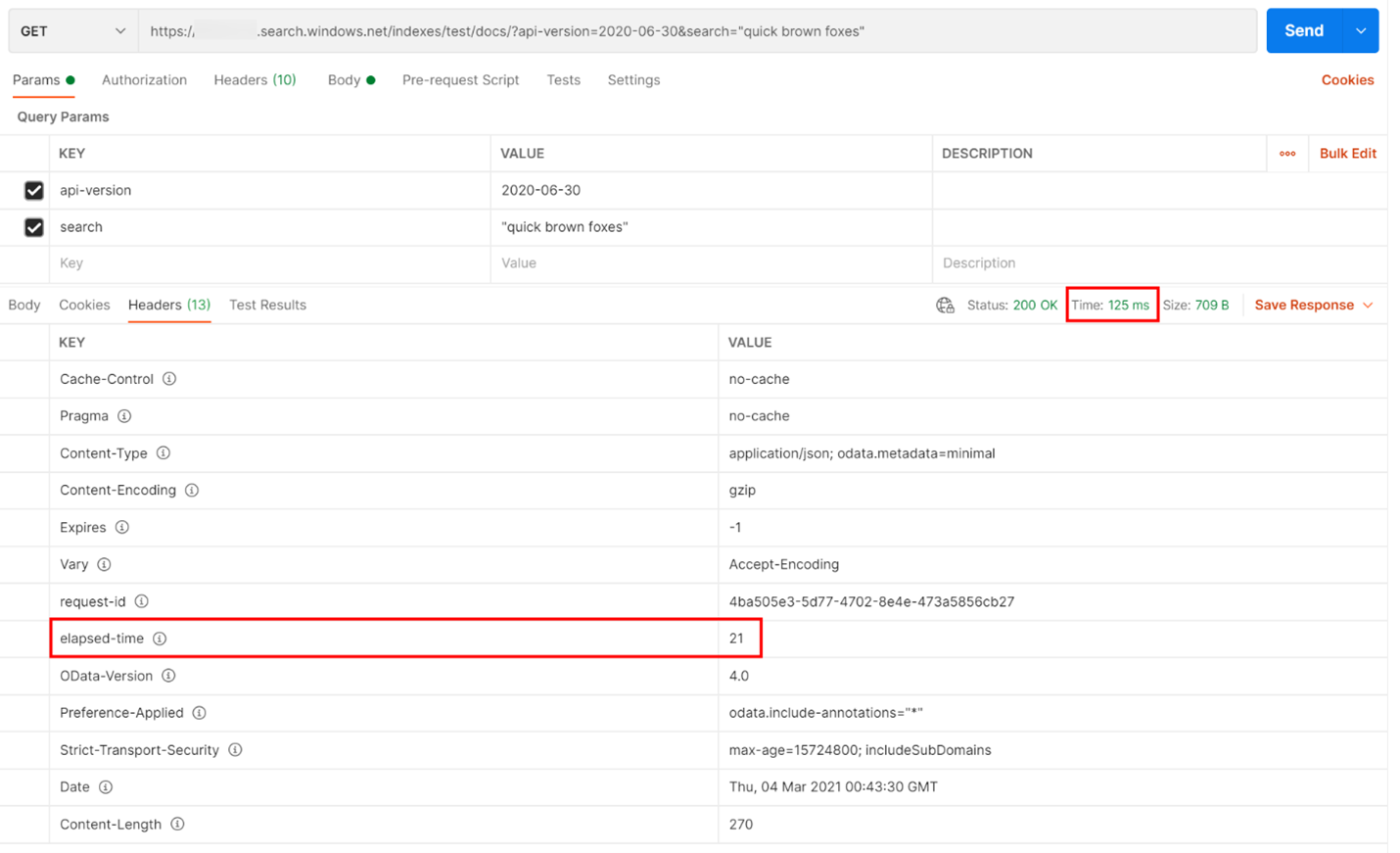
Im folgenden Beispiel wurde eine REST-basierte Suchabfrage ausgeführt. Azure AI Search schließt in jeder Antwort die Anzahl von Millisekunden ein, die zum Abschließen der Abfrage benötigt wird (sichtbar auf der Registerkarte „Header“ in „verstrichene Zeit“). Neben dem Status oben in der Antwort finden Sie die Roundtripdauer, in diesem Fall 418 Millisekunden (ms). Im Ergebnisabschnitt wurde die Registerkarte „Header“ ausgewählt. Anhand dieser beiden Werte, die in der Abbildung unten mit einem roten Kästchen hervorgehoben sind, lässt sich erkennen, dass der Suchdienst 21 Millisekunden für die Suchabfrage benötigte und die gesamte Roundtripanforderung des Clients 125 Millisekunden in Anspruch nahm. Durch Subtraktion dieser beiden Zahlen können wir feststellen, dass die Übertragung der Suchabfrage an den Suchdienst und die Rückübertragung der Suchergebnisse an den Client 104 ms länger dauerte.
Diese Technik hilft Ihnen, Netzwerklatenzen von anderen Faktoren zu isolieren, die sich auf die Abfrageleistung auswirken.
Abfrageraten
Ein möglicher Grund für die Drosselung von Anforderungen durch Ihren Suchdienst ist die schieren Anzahl von Abfragen, bei denen das Volume als Abfragen pro Sekunde (QPS) oder Abfragen pro Minute (QPM) erfasst wird. Wenn Ihr Suchdienst mehr QPS empfängt, dauert es in der Regel immer länger, um auf diese Abfragen zu antworten, bis er nicht mehr mithalten kann und eine drosselnde 503-HTTP-Antwort zurücksendet.
Die folgende Kusto-Abfrage zeigt die in QPM gemessene Abfragemenge zusammen mit der durchschnittlichen Dauer einer Abfrage in Millisekunden (AvgDurationMS) und der durchschnittlichen Anzahl von Dokumenten (AvgDocCountReturned), die jeweils zurückgegeben werden.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart

Tipp
Um die Daten hinter diesem Diagramm anzuzeigen, entfernen Sie die Zeile | render timechart, und starten Sie dann die Abfrage erneut.
Auswirkungen der Indizierung auf Abfragen
Ein wichtiger Faktor, der bei der Betrachtung der Leistung zu berücksichtigen ist, besteht darin, dass die Indizierung dieselben Ressourcen verwendet wie die Suchabfragen. Wenn Sie eine große Menge an Inhalten indizieren, können Sie davon ausgehen, dass die Latenz steigt, wenn der Dienst versucht, beide Workloads zu bewältigen.
Wenn Abfragen langsamer ausgeführt werden, sehen Sie sich den Zeitpunkt der Indizierungsaktivität an, um zu sehen, ob er mit der Verschlechterung der Abfrageleistung zusammenfällt. Zum Beispiel könnte ein Indexer einen täglichen oder stündlichen Auftrag ausführen, der mit der verminderten Leistung der Suchabfragen korreliert.
Dieser Abschnitt enthält eine Reihe von Abfragen, mit denen Sie die Such- und Indizierungsraten visualisieren können. In diesen Beispielen wird der Zeitbereich in der Abfrage festgelegt. Achten Sie beim Ausführen der Abfragen in Azure-Portal auf In Abfrage festlegen.
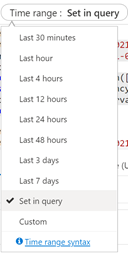
Durchschnittliche Abfragelatenz
In der folgenden Abfrage wird eine Intervallgröße von 1 Minute verwendet, um die durchschnittliche Latenz bei Suchabfragen anzuzeigen. Im Diagramm sehen Sie, dass die durchschnittliche Latenz bis 17:45 Uhr niedrig war und bis 17:53 Uhr gedauert hat.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
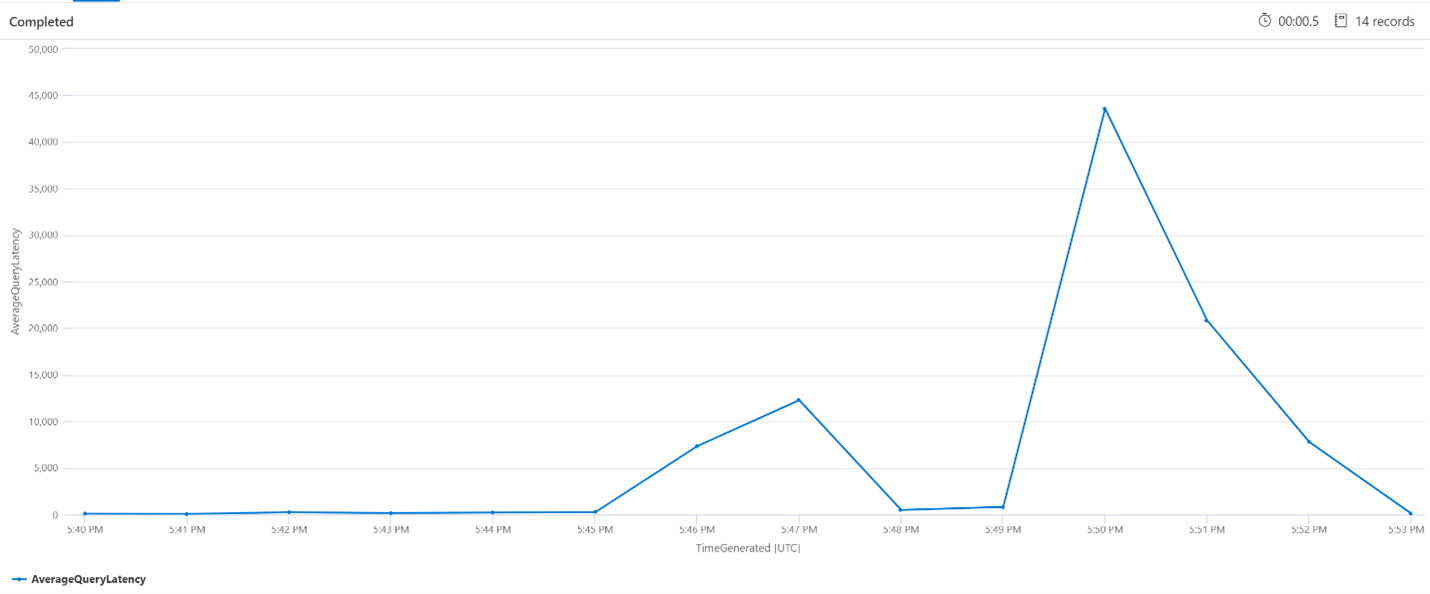
Durchschnittliche Abfragen pro Minute (QPM)
Die folgende Abfrage untersucht die durchschnittliche Anzahl von Abfragen pro Minute, um sicherzustellen, dass es keine Spitzenzahl bei Suchanforderungen gab, die möglicherweise die Latenz beeinflusst haben. Aus dem Diagramm ist ersichtlich, dass es eine gewisse Varianz gibt, aber Nichts, was auf eine Spitze bei der Anforderungsanzahl hindeutet.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
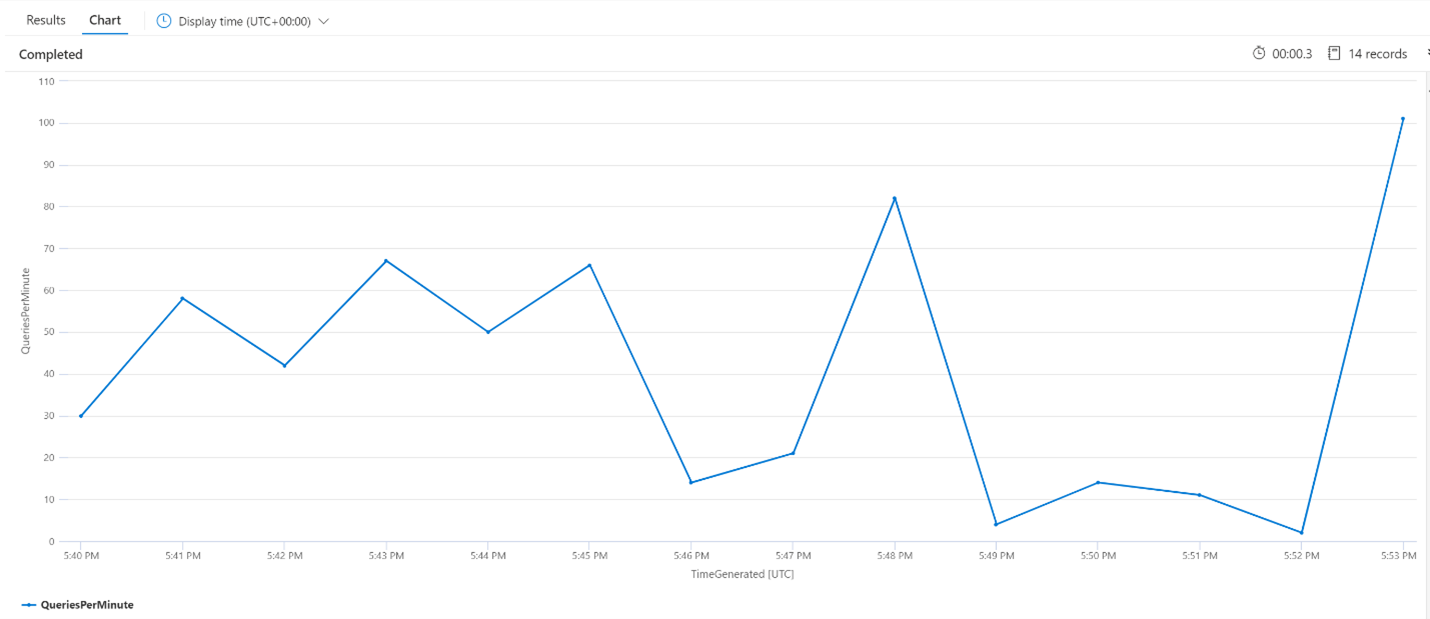
Indizierungsvorgänge pro Minute (OPM)
Hier sehen wir uns die Anzahl der Indizierungsvorgänge pro Minute an. Das Diagramm zeigt, dass die Indizierung einer großen Datenmenge um 17:42 Uhr begann und um 17:50 Uhr endete. Diese Indizierung begann 3 Minuten, bevor es Latenzen bei den Suchabfragen gab, und endete 3 Minuten, bevor die Suchabfragen keine Latenzen mehr aufwiesen.
Aus diesem Einblick ist ersichtlich, dass es etwa 3 Minuten dauerte, bis der Suchdienst durch die Indizierung so stark ausgelastet war, dass es begann sich auf die Latenz der Suchabfrage auszuwirken. Wir können auch sehen, dass es nach Abschluss der Indizierung weitere 3 Minuten dauerte, bis der Suchdienst alle Arbeiten aus dem neu indizierten Inhalt abgeschlossen hatte, bis die Abfragelatenz aufgelöst werden konnte.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Hintergrunddienstverarbeitung
Regelmäßige Spitzen bei der Abfrage- oder Indizierungslatenz sind nicht ungewöhnlich. Spitzen können als Reaktion auf die Indizierung oder hohe Abfrageraten auftreten, aber auch während Zusammenführungsvorgängen. Suchindizes werden in Blöcken Shards gespeichert. In regelmäßigen Abständen führt das System kleinere Shards zu großen Shards zusammen, um die Leistung des Diensts zu optimieren. Bei dieser Zusammenführung werden auch Dokumente bereinigt, die zuvor zum Löschen aus dem Index markiert wurden, wodurch wieder mehr Speicherplatz zur Verfügung steht.
Das Zusammenführen von Shards ist zwar schnell, aber auch ressourcenintensiv. Daher kann dadurch die Leistung des Diensts beeinträchtigt werden. Wenn Sie kurze Brüche der Abfragelatenz feststellen und diese Brüche mit den letzten Änderungen an indizierten Inhalten übereinstimmen, können Sie davon ausgehen, dass die Latenz auf Shard-Zusammenführungsvorgänge zurückzuführen ist.
Nächste Schritte
Die folgenden Artikel enthalten Informationen zur Analyse der Leistung des Diensts.
- Leistungstipps
- Auswählen eines Tarifs für die kognitive Azure-Suche
- Verwalten der Kapazität
- Case Study: Use Cognitive Search to Support Complex AI Scenarios (Fallstudie: Verwenden von Cognitive Search zur Unterstützung komplexer KI-Szenarien)