Verschieben eines Azure Synapse Analytics-Arbeitsbereichs aus einer Region in eine andere
Dieser Artikel ist eine Schritt-für-Schritt-Anleitung, die zeigt, wie Sie einen Azure Synapse Analytics-Arbeitsbereich aus einer Azure-Region in eine andere verschieben.
Hinweis
Mit den Schritten in diesem Artikel wird der Arbeitsbereich nicht tatsächlich verschoben. Die Schritte zeigen Ihnen, wie Sie einen neuen Arbeitsbereich in einer neuen Region erstellen, indem Sie dedizierte SQL-Poolsicherungen und Artefakte von Azure Synapse Analytics aus der Quellregion verwenden.
Voraussetzungen
- Integrieren Sie den Azure Synapse-Arbeitsbereich der Quellregion in Azure DevOps oder GitHub. Weitere Informationen finden Sie unter Quellcodeverwaltung in Synapse Studio.
- Sorgen Sie dafür, dass Azure PowerShell- und Azure CLI-Module auf dem Server installiert werden, auf dem Skripts ausgeführt werden.
- Stellen Sie sicher, dass alle abhängigen Dienste, z. B. Azure Machine Learning, Azure Storage und Azure Private Link-Hubs, in der Zielregion neu erstellt oder in die Zielregion verschoben werden, wenn der Dienst eine Regionsverschiebung unterstützt.
- Verschieben von Azure Storage in eine andere Region. Weitere Informationen finden Sie unter Verschieben eines Azure Speicherkontos in eine andere Region.
- Stellen Sie sicher, dass der Name des dedizierten SQL-Pools und der Name des Apache Spark-Pools im Arbeitsbereich in der Quellregion und in dem in der Zielregion identisch sind.
Szenarien für eine Regionsverschiebung
- Neue Complianceanforderungen: Organisationen verlangen im Rahmen neuer Complianceanforderungen, dass Daten und Dienste in derselben Region platziert werden.
- Verfügbarkeit einer neuen Azure-Region: Szenarien, in denen eine neue Azure-Region verfügbar ist und Projekt- oder Geschäftsanforderungen zum Verschieben des Arbeitsbereichs und anderer Azure-Ressourcen in die neu verfügbare Azure-Region vorliegen.
- Falsche Region ausgewählt: Die falsche Region wurde ausgewählt, als die Azure-Ressourcen erstellt wurden.
Schritte zum Verschieben eines Azure Synapse-Arbeitsbereichs in eine andere Region
Das Verschieben eines Azure Synapse-Arbeitsbereichs aus einer Region in eine andere ist ein mehrstufiger Prozess. Die allgemeinen Schritte sind folgende:
- Erstellen Sie einen Azure Synapse-Arbeitsbereich in der Zielregion zusammen mit einem Spark-Pool mit denselben Konfigurationen wie im Arbeitsbereich der Quellregion.
- Stellen Sie den dedizierten SQL-Pool mithilfe von Wiederherstellungspunkten oder Geosicherungen in der Zielregion wieder her.
- Erstellen Sie alle erforderlichen Anmeldungen auf dem neuen logischen SQL Server neu.
- Erstellen Sie serverlose SQL-Pool- und Spark-Pooldatenbanken und -Objekte.
- Fügen Sie einen Azure DevOps-Dienstprinzipal zur Rolle „Synapse-Artefaktherausgeber“ der rollenbasierten Zugriffssteuerung (Role-Based Access Control, RBAC) von Azure Synapse hinzu, wenn Sie eine Azure DevOps-Releasepipeline zum Bereitstellen der Artefakte verwenden.
- Stellen Sie Codeartefakte (SQL-Skripts, Notebooks), verknüpfte Dienste, Pipelines, Datasets, Trigger für Spark-Auftragsdefinitionen und Anmeldeinformationen aus Azure DevOps-Releasepipelines im Azure Synapse-Arbeitsbereich in der Zielregion bereit.
- Fügen Sie Azure Synapse-RBAC-Rollen Microsoft Entra-Benutzer*innen oder -Gruppen hinzu. Gewähren Sie der systemseitig zugewiesenen verwalteten Identität (SA-MI) „Mitwirkender an Storage-Blob“-Zugriff auf Azure Storage und Azure Key Vault, wenn Sie sich mithilfe einer verwalteten Identität authentifizieren.
- Erteilen Sie erforderlichen Microsoft Entra-Benutzer*innen die Rollen „Storage Blob-Leser“ oder „Storage Blob-Mitwirkender“ für angefügten Standardspeicher oder für das Storage-Konto mit Daten, die mithilfe eines serverlosen SQL-Pools abgefragt werden sollen.
- Erstellen Sie die selbstgehostete Integrationslaufzeit (SHIR) neu.
- Laden Sie alle erforderlichen Bibliotheken und JAR-Dateien manuell in den Azure Synapse-Zielarbeitsbereich hoch.
- Erstellen Sie alle verwalteten privaten Endpunkte, wenn der Arbeitsbereich in einem verwalteten virtuellen Netzwerk bereitgestellt wird.
- Testen Sie den neuen Arbeitsbereich in der Zielregion, und aktualisieren Sie alle DNS-Einträge, die auf den Arbeitsbereich der Quellregion verweisen.
- Wenn im Quellarbeitsbereich eine Verbindung mit einem privaten Endpunkt erstellt wurde, erstellen Sie eine im Arbeitsbereich der Zielregion.
- Sie können den Arbeitsbereich in der Quellregion löschen, nachdem Sie ihn gründlich getestet haben, und alle Verbindungen an den Arbeitsbereich der Zielregion umleiten.
Vorbereiten
Schritt 1: Erstellen eines Azure Synapse-Arbeitsbereichs in einer Zielregion
In diesem Abschnitt erstellen Sie den Azure Synapse-Arbeitsbereich mithilfe der Azure PowerShell, der Azure CLI und des Azure-Portals. Sie erstellen eine Ressourcengruppe zusammen mit einem Azure Data Lake Storage Gen2-Konto, das als Standardspeicher für den Arbeitsbereich als Teil des PowerShell-Skripts und des CLI-Skripts verwendet wird. Wenn Sie den Bereitstellungsprozess automatisieren möchten, rufen Sie diese PowerShell- oder CLI-Skripts über die DevOps-Releasepipeline auf.
Azure-Portal
Um einen Arbeitsbereich über das Azure-Portal zu erstellen, führen Sie die Schritte im Schnellstart: Erstellen eines Synapse-Arbeitsbereichs aus.
Azure PowerShell
Mit dem folgenden Skript werden die Ressourcengruppe und der Azure Synapse-Arbeitsbereich erstellt, indem die Cmdlets „New-AzResourceGroup“ und „New-AzSynapseWorkspace“ verwendet werden.
Erstellen einer Ressourcengruppe
$storageAccountName= "<YourDefaultStorageAccountName>"
$resourceGroupName="<YourResourceGroupName>"
$regionName="<YourTargetRegionName>"
$containerName="<YourFileSystemName>" # This is the file system name
$workspaceName="<YourTargetRegionWorkspaceName>"
$sourcRegionWSName="<Your source region workspace name>"
$sourceRegionRGName="<YourSourceRegionResourceGroupName>"
$sqlUserName="<SQLUserName>"
$sqlPassword="<SQLStrongPassword>"
$sqlPoolName ="<YourTargetSQLPoolName>" #Both Source and target workspace SQL pool name will be same
$sparkPoolName ="<YourTargetWorkspaceSparkPoolName>"
$sparkVersion="2.4"
New-AzResourceGroup -Name $resourceGroupName -Location $regionName
Erstellen eines Data Lake Storage Gen2-Kontos
#If the Storage account is already created, then you can skip this step.
New-AzStorageAccount -ResourceGroupName $resourceGroupName `
-Name $storageAccountName `
-Location $regionName `
-SkuName Standard_LRS `
-Kind StorageV2 `
-EnableHierarchicalNamespace $true
Erstellen eines Azure Synapse-Arbeitsbereichs
$password = ConvertTo-SecureString $sqlPassword -AsPlainText -Force
$creds = New-Object System.Management.Automation.PSCredential ($sqlUserName, $password)
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds
Wenn Sie den Arbeitsbereich mit einem verwalteten Virtual Network erstellen möchten, fügen Sie dem Skript den zusätzlichen Parameter „ManagedVirtualNetwork“ hinzu. Weitere Informationen zu den verfügbaren Optionen finden Sie unter Konfiguration verwalteter virtueller Netzwerke.
#Creating a managed virtual network configuration
$config = New-AzSynapseManagedVirtualNetworkConfig -PreventDataExfiltration -AllowedAadTenantIdsForLinking ContosoTenantId
#Creating an Azure Synapse workspace
New-AzSynapseWorkspace -ResourceGroupName $resourceGroupName `
-Name $workspaceName -Location $regionName `
-DefaultDataLakeStorageAccountName $storageAccountName `
-DefaultDataLakeStorageFilesystem $containerName `
-SqlAdministratorLoginCredential $creds `
-ManagedVirtualNetwork $config
Azure CLI
Dieses Azure CLI-Skript erstellt eine Ressourcengruppe, ein Data Lake Storage Gen2-Konto und ein Dateisystem. Anschließend erstellt es den Azure Synapse-Arbeitsbereich.
Erstellen einer Ressourcengruppe
az group create --name $resourceGroupName --location $regionName
Erstellen eines Data Lake Storage Gen2-Kontos
Das folgende Skript erstellt ein Speicherkonto und einen Container.
# Checking if name is not used only then creates it.
$StorageAccountNameAvailable=(az storage account check-name --name $storageAccountName --subscription $subscriptionId | ConvertFrom-Json).nameAvailable
if($StorageAccountNameAvailable)
{
Write-Host "Storage account Name is available to be used...creating storage account"
#Creating a Data Lake Storage Gen2 account
$storgeAccountProvisionStatus=az storage account create `
--name $storageAccountName `
--resource-group $resourceGroupName `
--location $regionName `
--sku Standard_GRS `
--kind StorageV2 `
--enable-hierarchical-namespace $true
($storgeAccountProvisionStatus| ConvertFrom-Json).provisioningState
}
else
{
Write-Host "Storage account Name is NOT available to be used...use another name -- exiting the script..."
EXIT
}
#Creating a container in a Data Lake Storage Gen2 account
$key=(az storage account keys list -g $resourceGroupName -n $storageAccountName|ConvertFrom-Json)[0].value
$fileShareStatus=(az storage share create --account-name $storageAccountName --name $containerName --account-key $key)
if(($fileShareStatus|ConvertFrom-Json).created -eq "True")
{
Write-Host f"Successfully created the fileshare - '$containerName'"
}
Erstellen eines Azure Synapse-Arbeitsbereichs
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $containerName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName
Um ein verwaltetes virtuelles Netzwerk zu aktivieren, schließen Sie den Parameter --enable-managed-virtual-network in das vorherige Skript ein. Weitere Optionen finden Sie unter Arbeitsbereich: Verwaltetes virtuelles Netzwerk.
az synapse workspace create `
--name $workspaceName `
--resource-group $resourceGroupName `
--storage-account $storageAccountName `
--file-system $FileShareName `
--sql-admin-login-user $sqlUserName `
--sql-admin-login-password $sqlPassword `
--location $regionName `
--enable-managed-virtual-network true `
--allowed-tenant-ids "Contoso"
Schritt 2: Erstellen einer Firewallregel für den Azure Synapse-Arbeitsbereich
Nachdem der Arbeitsbereich erstellt wurde, fügen Sie die Firewallregeln für den Arbeitsbereich hinzu. Beschränken Sie die IP-Adressen auf einen bestimmten Bereich. Sie können eine Firewallregel aus dem Azure-Portal oder mithilfe der PowerShell oder CLI hinzufügen.
Azure-Portal
Wählen Sie die Firewalloptionen aus, und fügen Sie den IP-Adressbereich hinzu, wie im folgenden Screenshot gezeigt.
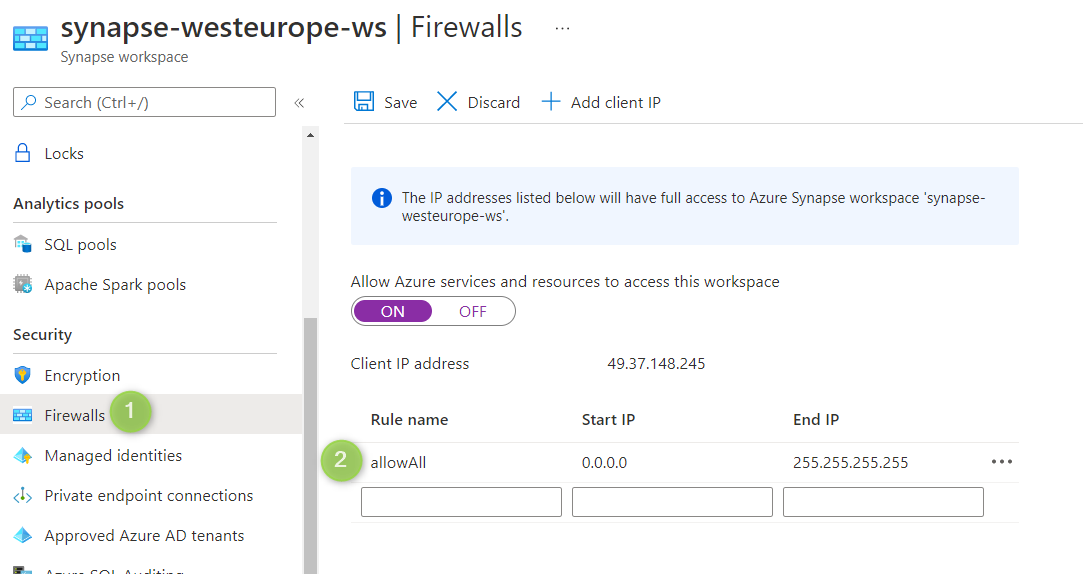
Azure PowerShell
Führen Sie die folgenden PowerShell-Befehle aus, um Firewallregeln hinzuzufügen, indem Sie die Start- und End-IP-Adressen angeben. Aktualisieren Sie den IP-Adressbereich nach Ihren Anforderungen.
$WorkspaceWeb = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Web
$WorkspaceDev = (Get-AzSynapseWorkspace -Name $workspaceName -ResourceGroupName $resourceGroup).ConnectivityEndpoints.Dev
# Adding firewall rules
$FirewallParams = @{
WorkspaceName = $workspaceName
Name = 'Allow Client IP'
ResourceGroupName = $resourceGroup
StartIpAddress = "0.0.0.0"
EndIpAddress = "255.255.255.255"
}
New-AzSynapseFirewallRule @FirewallParams
Führen Sie das folgende Skript aus, um die SQL-Kontrolleinstellungen für eine verwaltete Identität im Arbeitsbereich zu aktualisieren:
Set-AzSynapseManagedIdentitySqlControlSetting -WorkspaceName $workspaceName -Enabled $true
Azure CLI
az synapse workspace firewall-rule create --name allowAll --workspace-name $workspaceName `
--resource-group $resourceGroupName --start-ip-address 0.0.0.0 --end-ip-address 255.255.255.255
Führen Sie das folgende Skript aus, um die SQL-Kontrolleinstellungen für eine verwaltete Identität im Arbeitsbereich zu aktualisieren:
az synapse workspace managed-identity grant-sql-access `
--workspace-name $workspaceName --resource-group $resourceGroupName
Schritt 3: Erstellen eines Apache Spark-Pools
Erstellen Sie den Spark-Pool mit derselben Konfiguration, die im Arbeitsbereich der Quellregion verwendet wird.
Azure-Portal
Informationen zum Erstellen eines Spark-Pools über das Azure-Portal finden Sie im Schnellstart: Erstellen eines neuen serverlosen Apache Spark-Pools mithilfe des Azure-Portals.
Sie können den Spark-Pool auch über Synapse Studio erstellen, indem Sie die Schritte im Schnellstart: Erstellen eines serverlosen Apache Spark-Pools mithilfe von Synapse Studio befolgen.
Azure PowerShell
Das folgende Skript erstellt einen Spark-Pool mit zwei Workern und einem Treiberknoten bei einer kleinen Clustergröße mit 4 Kernen und 32 GB RAM. Aktualisieren Sie die Werte so, dass sie mit ihrem Spark-Pool im Arbeitsbereich der Quellregion übereinstimmen.
#Creating a Spark pool with 3 nodes (2 worker + 1 driver) and a small cluster size with 4 cores and 32 GB RAM.
New-AzSynapseSparkPool `
-WorkspaceName $workspaceName `
-Name $sparkPoolName `
-NodeCount 3 `
-SparkVersion $sparkVersion `
-NodeSize Small
Azure CLI
az synapse spark pool create --name $sparkPoolName --workspace-name $workspaceName --resource-group $resourceGroupName `
--spark-version $sparkVersion --node-count 3 --node-size small
Move
Schritt 4: Wiederherstellen eines dedizierten SQL-Pools
Wiederherstellen aus georedundanten Sicherungen
Informationen zum Wiederherstellen der dedizierten SQL-Pools aus einer Geosicherung mithilfe des Azure-Portals und der PowerShell finden Sie unter Geowiederherstellung eines dedizierten SQL-Pools in Azure Synapse Analytics.
Wiederherstellen mithilfe von Wiederherstellungspunkten aus dem dedizierten SQL-Pool im Arbeitsbereich der Quellregion
Stellen Sie den dedizierten SQL-Pool mithilfe des Wiederherstellungspunkts des dedizierten SQL-Pools im Arbeitsbereich der Quellregion im Arbeitsbereich der Zielregion wieder her. Sie können das Azure-Portal, Synapse Studio oder PowerShell verwenden, um aus Wiederherstellungspunkten wiederherzustellen. Wenn auf die Quellregion nicht zugegriffen werden kann, können Sie nicht mit dieser Option wiederherstellen.
Synapse Studio
In Synapse Studio können Sie den dedizierten SQL-Pool mithilfe von Wiederherstellungspunkten aus jedem Arbeitsbereich im Abonnement wiederherstellen. Wählen Sie beim Erstellen des dedizierten SQL-Pools unter Zusätzliche Einstellungen die Option Wiederherstellungspunkt aus, und wählen Sie den Arbeitsbereich aus, wie im folgenden Screenshot gezeigt. Wenn Sie einen benutzerdefinierten Wiederherstellungspunkt erstellt haben, verwenden Sie ihn, um den SQL-Pool wiederherzustellen. Andernfalls können Sie den letzten automatischen Wiederherstellungspunkt auswählen.
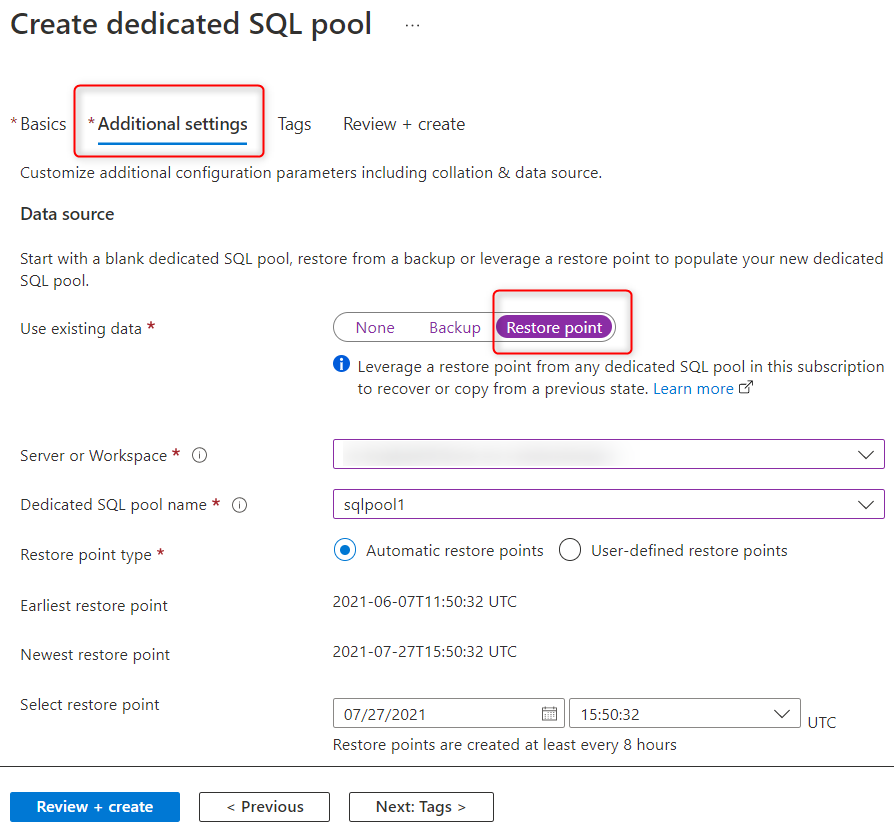
Azure PowerShell
Führen Sie das folgende PowerShell-Skript aus, um den Arbeitsbereich wiederherzustellen. Dieses Skript verwendet den letzten Wiederherstellungspunkt aus dem dedizierten SQL-Pool des Quellarbeitsbereichs, um den SQL im Zielarbeitsbereich wiederherzustellen. Aktualisieren Sie vor dem Ausführen des Skripts die Leistungsstufe von DW100c auf den erforderlichen Wert.
Wichtig
Der Name des dedizierten SQL-Pools sollte in beiden Arbeitsbereichen identisch sein.
Abrufen der Wiederherstellungspunkte:
$restorePoint=Get-AzSynapseSqlPoolRestorePoint -WorkspaceName $sourceRegionWSName -Name $sqlPoolName|Sort-Object -Property RestorePointCreationDate -Descending `
| SELECT RestorePointCreationDate -ExpandProperty RestorePointCreationDate -First 1
Wandeln Sie die SQL Pool-Ressourcen-ID von Azure Synapse in eine SQL Datenbank-ID um, da der Befehl derzeit nur die SQL Datenbank-ID akzeptiert.
Beispiel: /subscriptions/<SubscriptionId>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Sql/servers/<WorkspaceName>/databases/<DatabaseName>
$pool = Get-AzSynapseSqlPool -ResourceGroupName $sourceRegionRGName -WorkspaceName $sourcRegionWSName -Name $sqlPoolName
$databaseId = $pool.Id `
-replace "Microsoft.Synapse", "Microsoft.Sql" `
-replace "workspaces", "servers" `
-replace "sqlPools", "databases"
$restoredPool = Restore-AzSynapseSqlPool -FromRestorePoint `
-RestorePoint $restorePoint `
-TargetSqlPoolName $sqlPoolName `
-ResourceGroupName $resourceGroupName `
-WorkspaceName $workspaceName `
-ResourceId $databaseId `
-PerformanceLevel DW100c -AsJob
Im Folgenden wird der Status des Wiederherstellungsvorgangs nachverfolgt:
Get-Job | Where-Object Command -In ("Restore-AzSynapseSqlPool") | `
Select-Object Id,Command,JobStateInfo,PSBeginTime,PSEndTime,PSJobTypeName,Error |Format-Table
Nachdem der dedizierte SQL-Pool wiederhergestellt wurde, erstellen Sie alle SQL-Anmeldungen in Azure Synapse. Um alle Anmeldungen zu erstellen, führen Sie die Schritte unter Anmeldung erstellen aus.
Schritt 5: Erstellen eines serverlosen SQL-Pools, einer Spark-Pool-Datenbank und von Objekten
Sie können serverlose SQL-Pooldatenbanken und Spark-Pools nicht sichern und wiederherstellen. Als mögliche Problemumgehung haben Sie eventuell folgende Möglichkeiten:
- Erstellen von Notebooks und SQL-Skripts, die über den Code verfügen, um alle erforderlichen Spark-Pools, serverlosen SQL-Pooldatenbanken, Tabellen, Rollen und Benutzer mit allen Rollenzuweisungen neu zu erstellen. Einchecken dieser Artefakte in Azure DevOps oder GitHub.
- Wenn der Name des Speicherkontos geändert wird, stellen Sie sicher, dass die Codeartefakte auf den richtigen Speicherkontonamen verweisen.
- Erstellen von Pipelines, die diese Codeartefakte in einer bestimmten Abfolge aufrufen. Wenn diese Pipelines im Arbeitsbereich der Zielregion ausgeführt werden, werden die Spark SQL-Datenbanken, serverlosen SQL-Pooldatenbanken, externen Datenquellen, Ansichten, Rollen und Benutzer sowie Berechtigungen im Arbeitsbereich der Zielregion erstellt.
- Wenn Sie den Arbeitsbereich der Quellregion in Azure DevOps integrieren, werden diese Codeartefakte Teil des Repositorys. Später können Sie diese Codeartefakte im Arbeitsbereich der Zielregion bereitstellen, indem Sie die DevOps-Releasepipeline verwenden, wie in Schritt 6 erwähnt.
- Lösen Sie diese Pipelines manuell im Arbeitsbereich der Zielregion aus.
Schritt 6: Bereitstellen von Artefakten und Pipelines mithilfe von CI/CD
Um zu erfahren, wie Sie einen Azure Synapse-Arbeitsbereich in Azure DevOps oder GitHub integrieren und die Artefakte in einem Arbeitsbereich der Zielregion bereitstellen, führen Sie die Schritte unter Continuous Integration und Continuous Delivery (CI/CD) für einen Azure Synapse-Arbeitsbereich aus.
Nachdem der Arbeitsbereich in Azure DevOps integriert wurde, gibt es einen Branch mit dem Namen „workspace_publish“. Dieser Branch enthält die Arbeitsbereichsvorlage, die Definitionen für die Artefakte wie Notebooks, SQL-Skripts, Datasets, verknüpfte Dienste, Pipelines, Trigger und Spark-Auftragsdefinitionen enthält.
Dieser Screenshot aus dem Azure DevOps-Repository zeigt die Vorlagendateien des Arbeitsbereichs für die Artefakte und anderen Komponenten.
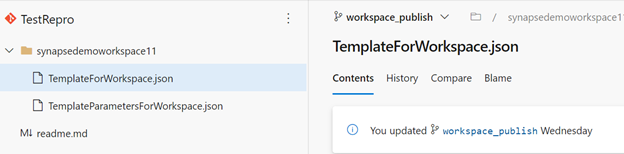
Sie können die Arbeitsbereichsvorlage verwenden, um Artefakte und Pipelines in einem Arbeitsbereich bereitzustellen, indem Sie die Azure DevOps-Releasepipeline verwenden, wie im folgenden Screenshot gezeigt.
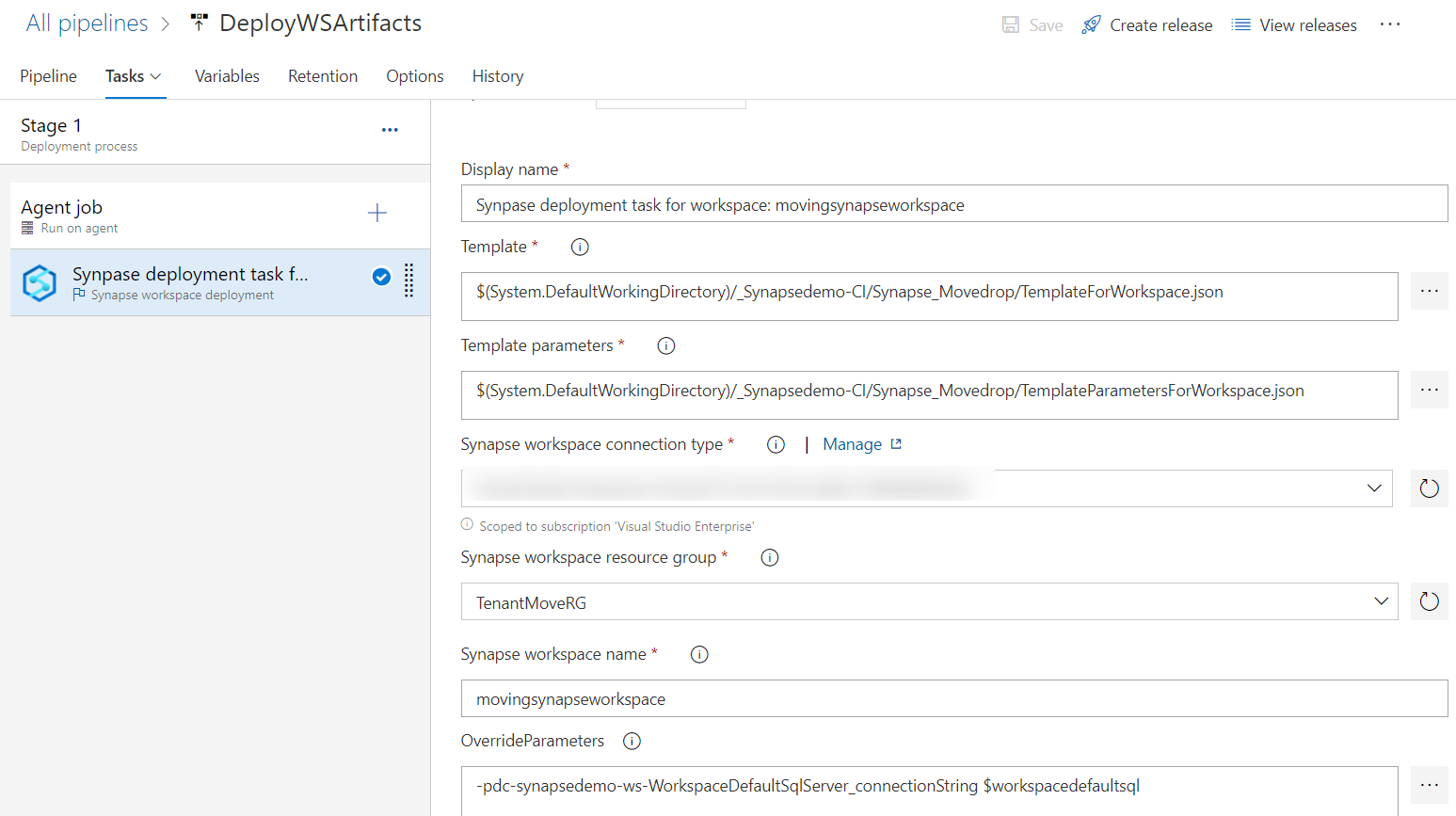
Wenn der Arbeitsbereich nicht in GitHub oder Azure DevOps integriert ist, müssen Sie benutzerdefinierte PowerShell- oder Azure CLI-Skripts manuell neu erstellen oder schreiben, um alle Artefakte, Pipelines, verknüpften Dienste, Anmeldeinformationen, Trigger und Spark-Definitionen im Arbeitsbereich der Zielregion bereitzustellen.
Hinweis
Bei diesem Prozess müssen Sie die Pipelines und Codeartefakte ständig aktualisieren, damit alle Änderungen, die an Spark- und serverlosen SQL-Pools, Objekten und Rollen in den Arbeitsbereichen der Quellregion vorgenommen werden, enthalten sind.
Schritt 7: Erstellen einer freigegebenen Integration Runtime
Um eine SHIR zu erstellen, führen Sie die Schritte unter Erstellen und Konfigurieren einer selbstgehosteten Integration Runtime aus.
Schritt 8: Zuweisen einer Azure-Rolle zu einer verwalteten Identität
Weisen Sie der verwalteten Identität des neuen Arbeitsbereichs Storage Blob Contributor-Zugriff auf das standardmäßig angefügten Data Lake Storage Gen2-Konto zu. Weisen Sie außerdem Zugriff auf andere Speicherkonten zu, bei denen SA-MI für die Authentifizierung verwendet wird. Weisen Sie Microsoft Entra-Benutzer*innen und -Gruppen für alle erforderlichen Speicherkonten Storage Blob Contributor- oder Storage Blob Reader-Zugriff zu.
Azure-Portal
Führen Sie die Schritte unter Erteilen von Berechtigungen für die verwaltete Identität des Arbeitsbereichs aus, um der verwalteten Identität des Arbeitsbereichs die Rolle „Mitwirkender an Storage-Blobdaten“ zuzuweisen.
Azure PowerShell
Weisen Sie der verwalteten Identität des Arbeitsbereichs die Rolle „Mitwirkender an Storage-Blobdaten“ zu.
Hinzufügen des Mitwirkenden für Storage Blob-Daten zu der vom Arbeitsbereich verwalteten Identität im Speicherkonto. Bei der Ausführung von New-AzRoleAssignment kommt es zu einem Fehler mit der Fehlermeldung Exception of type 'Microsoft.Rest.Azure.CloudException' was thrown., jedoch werden die erforderlichen Berechtigungen im Speicherkonto erstellt.
$workSpaceIdentityObjectID= (Get-AzSynapseWorkspace -ResourceGroupName $resourceGroupName -Name $workspaceName).Identity.PrincipalId
$scope = "/subscriptions/$($subscriptionId)/resourceGroups/$($resourceGroupName)/providers/Microsoft.Storage/storageAccounts/$($storageAccountName)"
$roleAssignedforManagedIdentity=New-AzRoleAssignment -ObjectId $workSpaceIdentityObjectID `
-RoleDefinitionName "Storage Blob Data Contributor" `
-Scope $scope -ErrorAction SilentlyContinue
Azure CLI
Rufen Sie den Rollennamen, die Ressourcen-ID und die Prinzipal-ID für die verwaltete Arbeitsbereichsidentität ab, und fügen Sie dann die Azure-Rolle Mitwirkender an Storage Blob-Daten zur SA-MI hinzu.
# Getting Role name
$roleName =az role definition list --query "[?contains(roleName, 'Storage Blob Data Contributor')].{roleName:roleName}" --output tsv
#Getting resource id for storage account
$scope= (az storage account show --name $storageAccountName|ConvertFrom-Json).id
#Getting principal ID for workspace managed identity
$workSpaceIdentityObjectID=(az synapse workspace show --name $workspaceName --resource-group $resourceGroupName|ConvertFrom-Json).Identity.PrincipalId
# Adding Storage Blob Data Contributor Azure role to SA-MI
az role assignment create --assignee $workSpaceIdentityObjectID `
--role $roleName `
--scope $scope
Schritt 9: Zuweisen von RBAC-Rollen von Azure Synapse
Fügen Sie alle Benutzer, die Zugriff auf den Zielarbeitsbereich benötigen, mit separaten Rollen und Berechtigungen hinzu. Mit dem folgenden PowerShell- und CLI-Skript wird der Rolle „Synapse-Administrator“ im Arbeitsbereich der Zielregion ein/e Microsoft Entra-Benutzer*in hinzugefügt.
Informationen zum Abrufen aller RBAC-Rollennamen von Azure Synapse finden Sie unter RBAC-Rollen von Azure Synapse.
Synapse Studio
Um RBAC-Zuweisungen von Azure Synapse aus Synapse Studio hinzuzufügen oder zu löschen, führen Sie die Schritte unter Verwalten von RBAC-Rollenzuweisungen von Azure Synapse in Synapse Studio aus.
Azure PowerShell
Das folgende PowerShell-Skript fügt die Rollenzuweisung „Synapse-Administrator“ einem bzw. einer Microsoft Entra-Benutzer*in oder einer Microsoft Entra-Gruppe hinzu. Sie können „-RoleDefinitionId“ anstelle von „-RoleDefinitionName“ mit dem folgenden Befehl verwenden, um die Benutzer dem Arbeitsbereich hinzuzufügen:
New-AzSynapseRoleAssignment `
-WorkspaceName $workspaceName `
-RoleDefinitionName "Synapse Administrator" `
-ObjectId 1c02d2a6-ed3d-46ec-b578-6f36da5819c6
Get-AzSynapseRoleAssignment -WorkspaceName $workspaceName
Zum Abrufen der ObjectIds und RoleIds im Arbeitsbereich der Quellregion führen Sie den Befehl Get-AzSynapseRoleAssignment aus. Weisen Sie dieselben RBAC-Rollen von Azure Synapse Microsoft Entra-Benutzer*innen oder -Gruppen im Arbeitsbereich der Zielregion zu.
Anstatt -ObjectId als Parameter zu verwenden, können Sie auch -SignInName verwenden, indem Sie die E-Mail-Adresse oder den Benutzerprinzipalnamen des Benutzers angeben. Weitere Informationen zu den verfügbaren Optionen finden Sie unter Azure Synapse RBAC – PowerShell-Cmdlet.
Azure CLI
Rufen Sie die Objekt-ID des Benutzers bzw. der Benutzerin ab, und weisen Sie dem bzw. der Microsoft Entra-Benutzer*in die erforderlichen Azure Synapse-RBAC-Berechtigungen zu. Sie können für den --assignee-Parameter die E-Mail-Adresse des Benutzers (username@contoso.com) angeben.
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Administrator" --assignee adasdasdd42-0000-000-xxx-xxxxxxx
az synapse role assignment create `
--workspace-name $workspaceName `
--role "Synapse Contributor" --assignee "user1@contoso.com"
Weitere Informationen zu den verfügbaren Optionen finden Sie unter Azure Synapse RBAC – CLI.
Schritt 10: Hochladen von Arbeitsbereichspaketen
Laden Sie alle erforderlichen Arbeitsbereichspakete in den neuen Arbeitsbereich hoch. Informationen zum Automatisieren des Uploadvorgangs für die Arbeitsbereichspakete finden Sie in der Microsoft Azure Synapse Analytics-Artefakte-Clientbibliothek.
Schritt 11: Berechtigungen
Führen Sie zum Einrichten der Zugriffssteuerung für den Azure Synapse-Arbeitsbereich der Zielregion die Schritte unter Einrichten der Zugriffssteuerung für Ihren Azure Synapse-Arbeitsbereich aus.
Schritt 12: Erstellen verwalteter privater Endpunkte
Informationen zum erneuten Erstellen der verwalteten privaten Endpunkte aus dem Arbeitsbereich der Quellregion in Ihrem Arbeitsbereich der Zielregion finden Sie unter Erstellen eines verwalteten privaten Endpunkts für Ihre Datenquelle.
Verwerfen
Falls Sie den Arbeitsbereich der Zielregion verwerfen möchten, löschen Sie den Arbeitsbereich der Zielregion. Gehen Sie dazu von Ihrem Dashboard im Portal zur Ressourcengruppe, wählen Sie den Arbeitsbereich aus und wählen Sie oben auf der Seite der Ressourcengruppe Löschen.
Bereinigen
Um die Änderungen zu bestätigen und die Verschiebung des Arbeitsbereichs abzuschließen, löschen Sie den Arbeitsbereich der Quellregion, nachdem Sie den Arbeitsbereich in der Zielregion getestet haben. Wechseln Sie dazu von Ihrem Dashboard im Portal zu der Ressourcengruppe, die den Arbeitsbereich der Quellregion enthält, wählen Sie den Arbeitsbereich aus, und wählen Sie oben auf der Seite der Ressourcengruppe „Löschen“ aus.
Nächste Schritte
- Erfahren Sie mehr über Verwaltete virtuelle Netzwerke in Azure Synapse.
- Erfahren Sie mehr über Verwaltete private Endpunkte in Azure Synapse.
- Erfahren Sie mehr über das Herstellen einer Verbindung mit Arbeitsbereichsressourcen über ein eingeschränktes Netzwerk.