Schnellstart: Transformieren von Daten mithilfe von Mapping Data Flow
In dieser Schnellstartanleitung wird Azure Synapse Analytics verwendet, um eine Pipeline zu erstellen, die Daten unter Verwendung eines Zuordnungsdatenflusses von einer ADLS Gen2-Quelle (Azure Data Lake Storage Gen2) in eine ADLS Gen2-Senke transformiert. Das Konfigurationsmuster in dieser Schnellstartanleitung kann beim Transformieren von Daten per Zuordnungsdatenfluss erweitert werden.
Diese Schnellstartanleitung umfasst folgende Schritte:
- Erstellen einer Pipeline mit einer Datenflussaktivität in Azure Synapse Analytics
- Erstellen einer Mapping Data Flow-Funktion mit vier Transformationen
- Ausführen eines Testlaufs für die Pipeline
- Überwachen einer Datenflussaktivität
Voraussetzungen
Azure-Abonnement: Wenn Sie über kein Azure-Abonnement verfügen, können Sie ein kostenloses Azure-Konto erstellen, bevor Sie beginnen.
Azure Synapse-Arbeitsbereich: Befolgen Sie zum Erstellen eines Synapse-Arbeitsbereichs mithilfe des Azure-Portals die Anweisungen unter Schnellstart: Erstellen eines Synapse-Arbeitsbereichs.
Azure-Speicherkonto: Hier wird ADLS-Speicher als Quelldatenspeicher und Senkendatenspeicher verwendet. Wenn Sie kein Speicherkonto besitzen, finden Sie unter Informationen zu Azure-Speicherkonten Schritte zum Erstellen eines solchen Kontos.
Die Datei, die in diesem Tutorial transformiert wird, ist „MoviesDB.csv“, die sich hier befindet. Zum Abrufen der Datei aus GitHub kopieren Sie den Inhalt in einen Text-Editor Ihrer Wahl, und speichern Sie ihn lokal als CSV-Datei. Wenn Sie die Datei in Ihr Speicherkonto hochladen möchten, finden Sie Informationen dazu unter Hochladen von Blobs mit dem Azure-Portal. In den Beispielen wird auf einen Container mit dem Namen „sample-data“ verwiesen.
Navigieren zu Synapse Studio
Nachdem Ihr Azure Synapse-Arbeitsbereich erstellt wurde, haben Sie zwei Möglichkeiten zum Öffnen von Synapse Studio:
- Öffnen Sie Ihren Synapse-Arbeitsbereich im Azure-Portal. Wählen Sie auf der Karte „Synapse Studio öffnen“ unter Erste Schritte die Option Öffnen aus.
- Öffnen Sie Azure Synapse Analytics, und melden Sie sich bei Ihrem Arbeitsbereich an.
In dieser Schnellstartanleitung wird der Arbeitsbereich „adftest2020“ als Beispiel verwendet. Sie werden automatisch zur Startseite von Synapse Studio weitergeleitet.
Erstellen einer Pipeline mit einer Datenflussaktivität
Eine Pipeline enthält den logischen Ablauf für die Ausführung einer Aktivitätenmenge. In diesem Abschnitt wird eine Pipeline mit einer Datenflussaktivität erstellt.
Navigieren Sie zur Registerkarte Integrieren. Wählen Sie neben dem Header „Pipelines“ das Pluszeichen und anschließend „Pipeline“ aus.
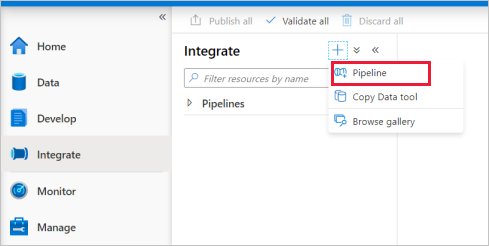
Geben Sie auf der Einstellungsseite Eigenschaften der Pipeline unter Name die Zeichenfolge TransformMovies ein.
Ziehen Sie im Bereich Aktivitäten unter Verschieben und transformieren das Element Datenfluss auf die Pipelinecanvas.
Wählen Sie im Popupelement Datenfluss hinzufügen Folgendes aus: Neuen Datenfluss erstellen>Datenfluss aus. Klicken Sie nach Abschluss des Vorgangs auf OK.
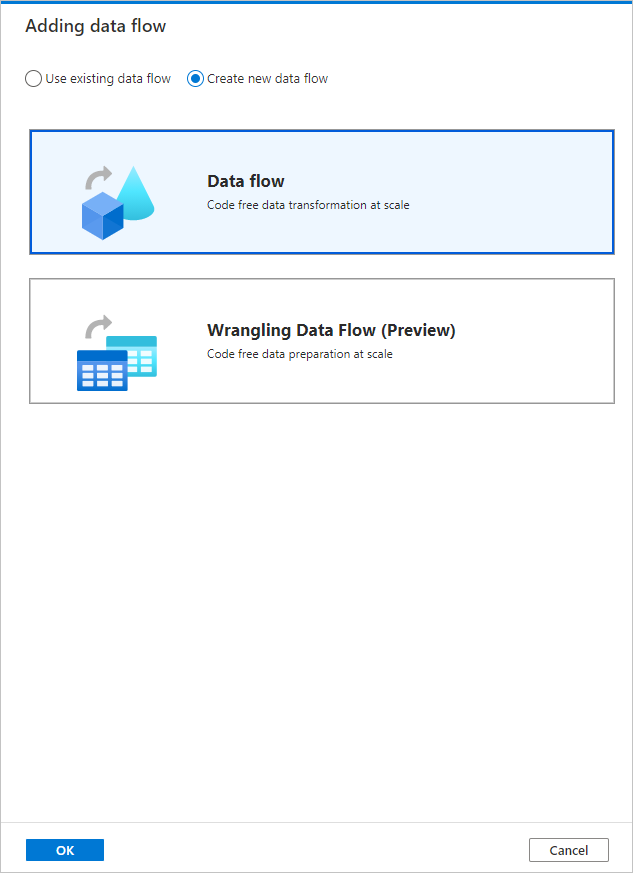
Geben Sie Ihrem Datenfluss auf der Seite Eigenschaften den Namen TransformMovies.
Erstellen von Transformationslogik auf der Datenflusscanvas
Sobald Sie den Datenfluss erstellen, werden Sie automatisch zur Datenflusscanvas geführt. In diesem Schritt wird ein Datenfluss erstellt, der anhand der Datei „MoviesDB.csv“ aus dem ADLS-Speicher die durchschnittliche Bewertung von Komödien von 1910 bis 2000 aggregiert. Anschließend schreiben Sie diese Datei zurück in den ADLS-Speicher.
Schieben Sie oberhalb der Datenflusscanvas den Schieberegler Datenfluss debuggen auf „Ein“. Der Debugmodus ermöglicht das interaktive Testen von Transformationslogik mit einem aktiven Spark-Cluster. Die Aufwärmphase von Datenflussclustern dauert 5 bis 7 Minuten. Den Benutzern wird empfohlen, zuerst den Debugmodus zu aktivieren, wenn sie die Entwicklung eines Datenflusses planen. Weitere Informationen finden Sie unter Debugmodus.
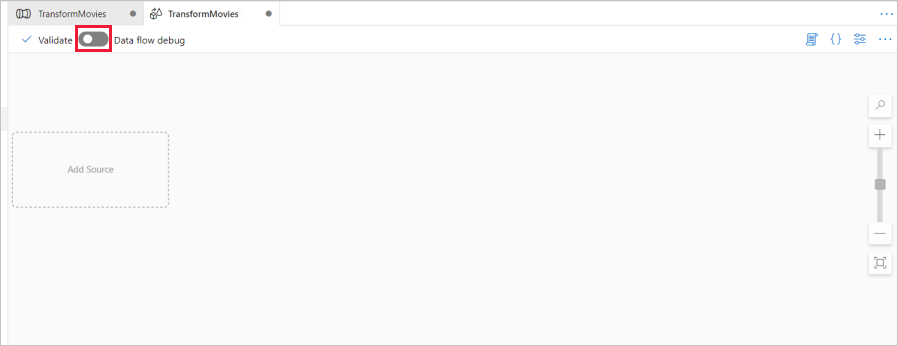
Fügen Sie auf der Datenflusscanvas eine Quelle hinzu, indem Sie auf das Feld Quelle hinzufügen klicken.
Geben Sie der Quelle den Namen MoviesDB. Klicken Sie auf Neu, um ein neues Quelldataset zu erstellen.
Wählen Sie Azure Data Lake Storage Gen2 aus. Klicken Sie auf „Weiter“.

Wählen Sie DelimitedText aus. Klicken Sie auf „Weiter“.
Geben Sie dem Dataset den Namen MoviesDB. Wählen Sie in der Dropdownliste für den verknüpften Dienst die Option Neu aus.
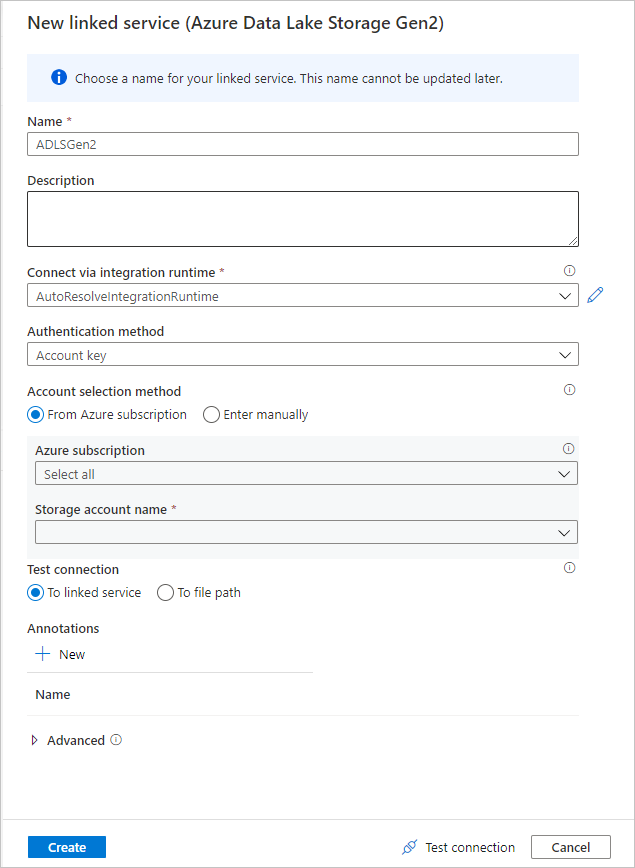
Geben Sie im Erstellungsbildschirm für verknüpfte Dienste dem verknüpften ADLS Gen2-Dienst den Namen ADLSGen2, und geben Sie Ihre Authentifizierungsmethode an. Dann geben Sie Ihre Verbindungsanmeldeinformationen ein. In dieser Schnellstartanleitung wird „Kontoschlüssel“ verwendet, um eine Verbindung mit dem Speicherkonto herzustellen. Sie können auf Verbindung testen klicken, um zu überprüfen, ob Ihre Anmeldeinformationen korrekt eingegeben wurden. Klicken Sie auf Erstellen, nachdem der Vorgang abgeschlossen wurde.
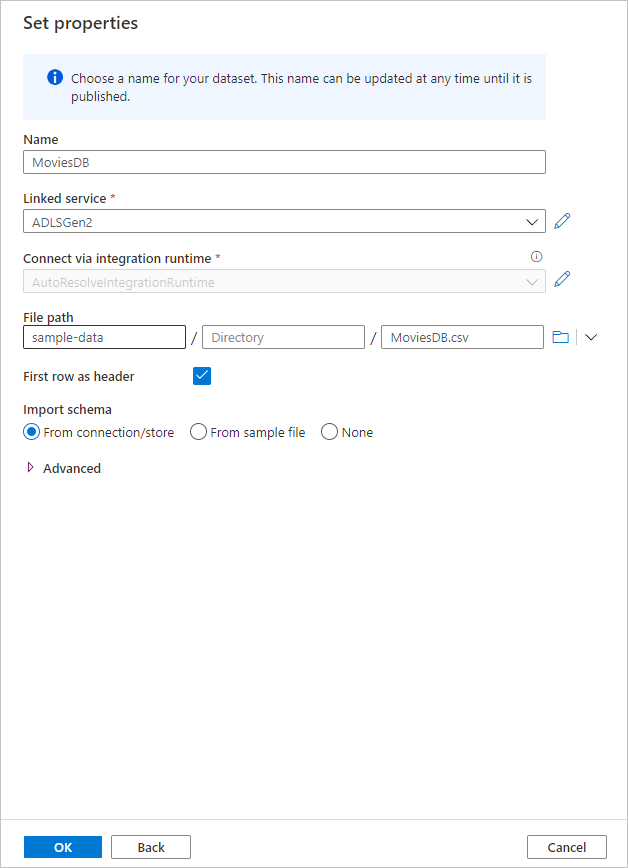
Wenn Sie sich wieder im Erstellungsbildschirm für das Dataset befinden, geben Sie im Feld Dateipfad den Speicherort Ihrer Datei ein. In dieser Schnellstartanleitung befindet sich die Datei „MoviesDB.csv“ im Container „sample-data“. Da die Datei Header enthält, aktivieren Sie das Kontrollkästchen Erste Zeile als Header. Wählen Sie Aus Verbindung/Speicher aus, um das Headerschema direkt aus der Datei in den Speicher zu importieren. Klicken Sie nach Abschluss des Vorgangs auf OK.
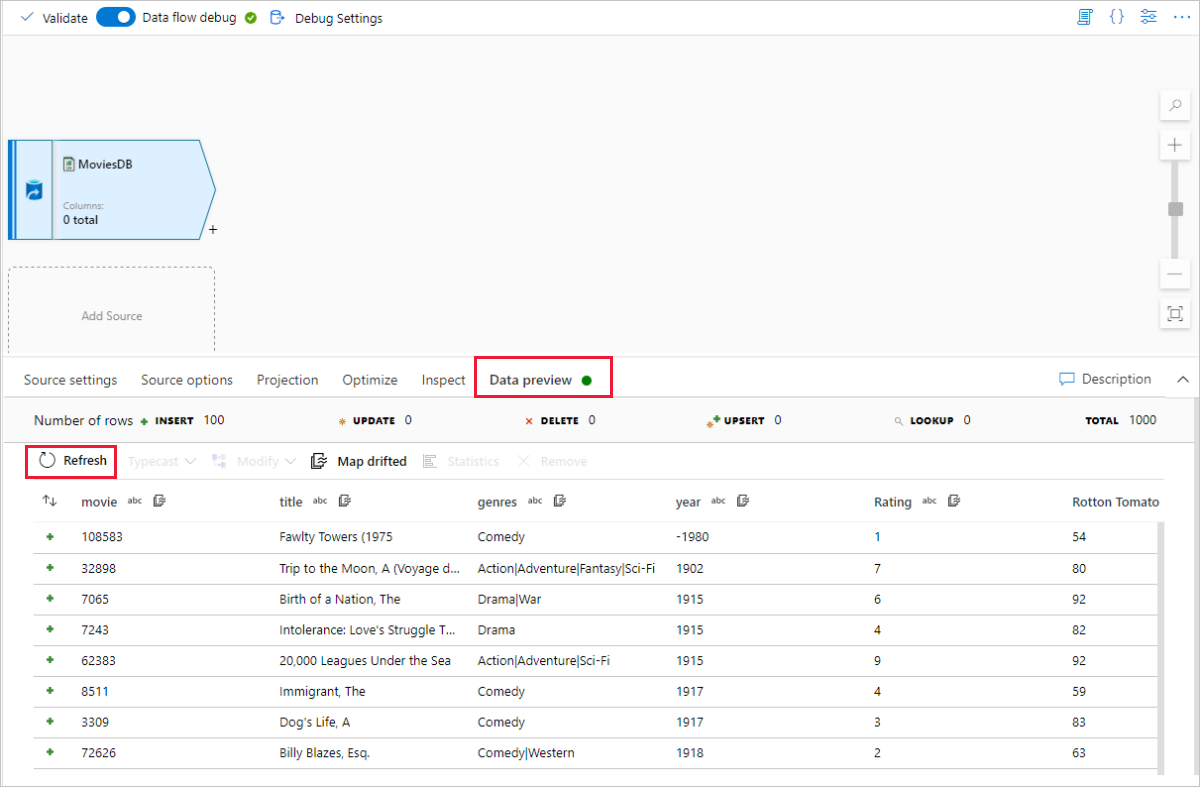
Wenn Ihr Debugcluster gestartet wurde, wechseln Sie zur Registerkarte Datenvorschau der Quelltransformation, und klicken Sie auf Aktualisieren, um eine Momentaufnahme der Daten zu erhalten. Mithilfe der Datenvorschau können Sie überprüfen, ob die Transformation ordnungsgemäß konfiguriert ist.
Klicken Sie auf der Datenflusscanvas neben dem Quellknoten auf das Pluszeichen, um eine neue Transformation hinzuzufügen. Als erste Transformation fügen Sie einen Filter hinzu.

Geben Sie der Filtertransformation den Namen FilterYears. Klicken Sie auf das Ausdrucksfeld neben Filtern nach, um den Ausdrucks-Generator zu öffnen. Hier geben Sie dann die Filterbedingung an.
Mit dem Datenfluss-Ausdrucks-Generator können Sie Ausdrücke interaktiv erstellen, die dann in verschiedenen Transformationen verwendet werden können. Ausdrücke können integrierte Funktionen, Spalten aus dem Eingabeschema und benutzerdefinierte Parameter enthalten. Weitere Informationen zum Erstellen von Ausdrücken finden Sie unter Mapping Data Flow: Ausdrucks-Generator.
In dieser Schnellstartanleitung soll nach Filmen aus dem Genre „Komödie“ gefiltert werden, die zwischen 1910 und 2000 erschienen sind. Da die Jahresangabe derzeit eine Zeichenfolge ist, müssen Sie sie mithilfe der Funktion
toInteger()in eine ganze Zahl konvertieren. Verwenden Sie die Operatoren für größer als oder gleich (>=) und kleiner als oder gleich (<=) für einen Vergleich mit den Literalwerten für die Jahre 1910 und 200. Verbinden Sie diese Ausdrücke mit dem&&(und) Operator. Der Ausdruck sieht wie folgt aus:toInteger(year) >= 1910 && toInteger(year) <= 2000Um zu ermitteln, welche Filme Komödien sind, können Sie mithilfe der Funktion
rlike()nach dem Muster „Comedy“ in der Spalte „genres“ suchen. Vereinigen Sie den Ausdruckrlikemit dem Jahresvergleich, um Folgendes zu erhalten:toInteger(year) >= 1910 && toInteger(year) <= 2000 && rlike(genres, 'Comedy')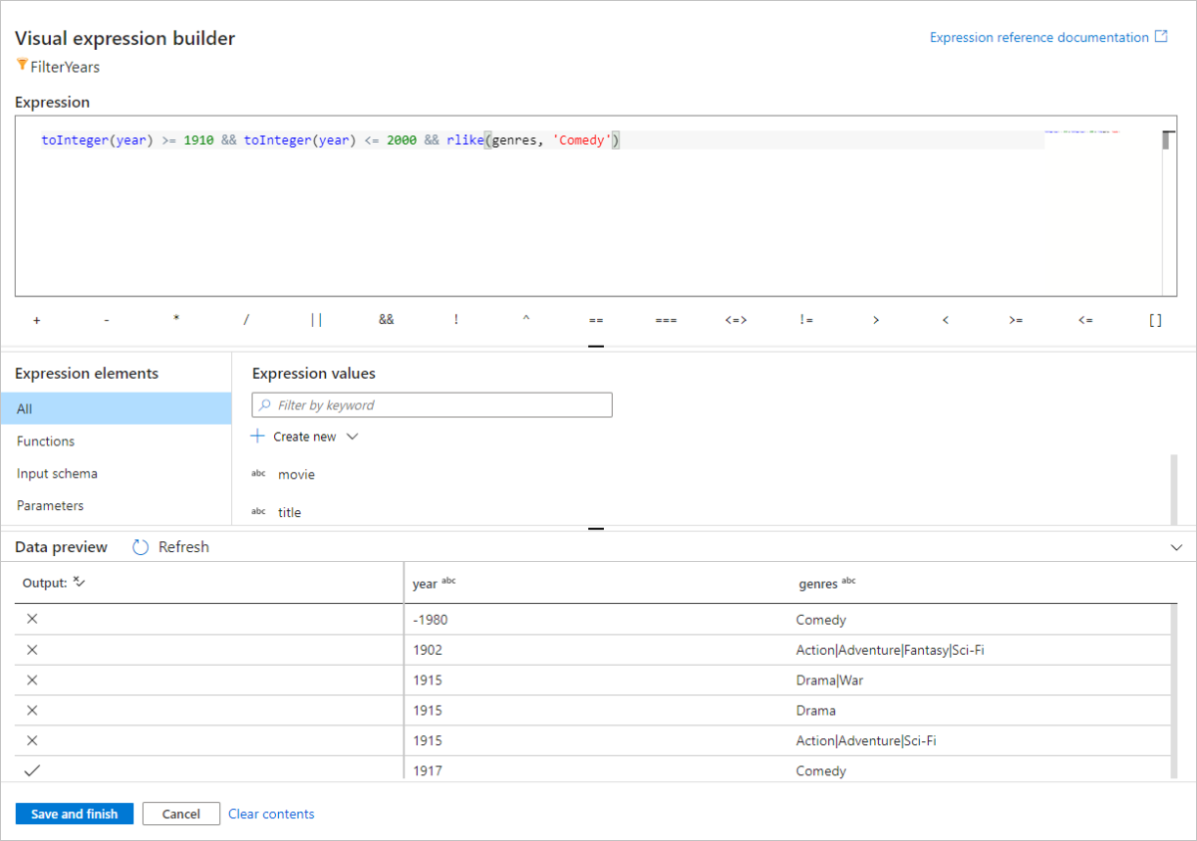
Wenn ein Debugcluster aktiv ist, können Sie die Logik überprüfen. Klicken Sie dazu auf Aktualisieren, um die Ausdrucksausgabe im Vergleich zu den verwendeten Eingaben anzuzeigen. Es gibt mehrere Möglichkeiten, wie Sie diese Logik mithilfe der Ausdruckssprache für Datenflüsse erzielen können.
Sobald Sie den Ausdruck fertiggestellt haben, klicken Sie auf Speichern und beenden.
Rufen Sie eine Datenvorschau ab, um zu überprüfen, ob der Filter ordnungsgemäß funktioniert.
Als nächste Transformation fügen Sie eine Aggregat-Transformation unter Schemamodifizierer hinzu.
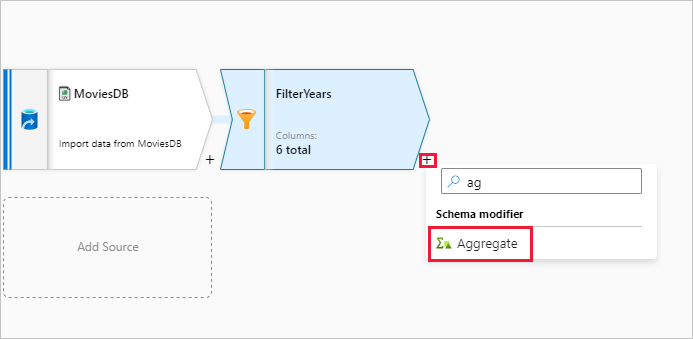
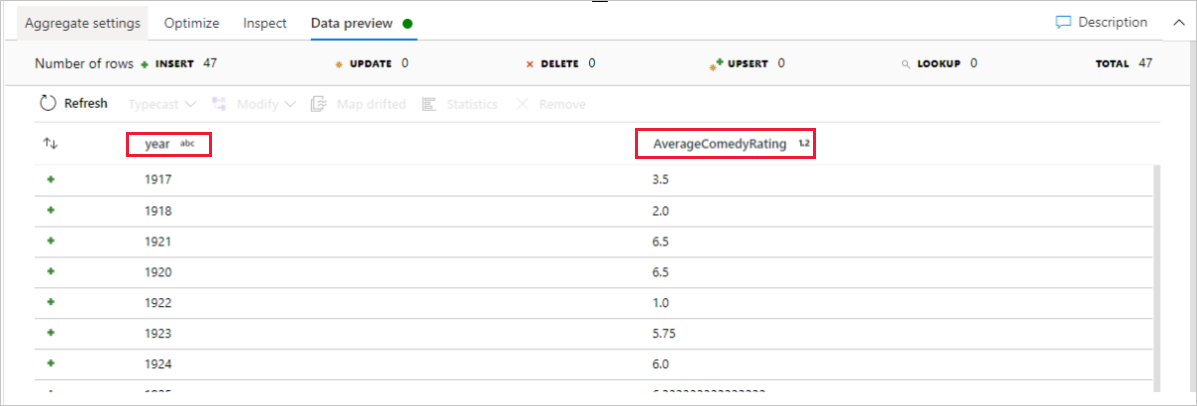
Geben Sie der Aggregattransformation den Namen AggregateComedyRatings. Wählen Sie auf der Registerkarte Gruppieren nach in der Dropdownliste die Option year aus, um die Aggregationen nach dem Jahr zu gruppieren, in dem der Film entstanden ist.

Wechseln Sie zur Registerkarte Aggregate. Geben Sie im linken Textfeld der Aggregatspalte den Namen AverageComedyRating. Klicken Sie auf das rechte Ausdrucksfeld, um den Aggregatausdruck über den Ausdrucks-Generator einzugeben.

Verwenden Sie die Aggregatfunktion
avg(), um den Durchschnitt der Spalte Rating zu erhalten. Da Rating eine Zeichenfolge ist undavg()eine numerische Eingabe benötigt, muss der Wert über die FunktiontoInteger()in eine Zahl konvertiert werden. Dieser Ausdruck sieht wie folgt aus:avg(toInteger(Rating))Klicken Sie anschließend auf Speichern und beenden.

Wechseln Sie zur Registerkarte Datenvorschau, um die Transformationsausgabe anzuzeigen. Es sind nur zwei Spalten vorhanden: year und AverageComedyRating.
Als Nächstes fügen Sie eine Transformation vom Typ Senke unter Ziel hinzu.
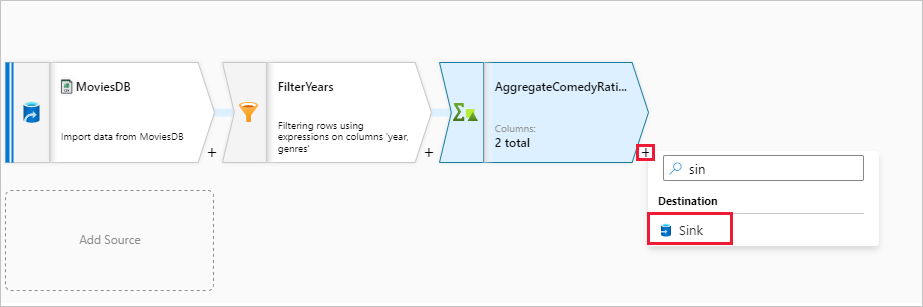
Geben Sie der Senke den Namen Sink. Klicken Sie auf Neu, um das Senkendataset zu erstellen.
Wählen Sie Azure Data Lake Storage Gen2 aus. Klicken Sie auf „Weiter“.
Wählen Sie DelimitedText aus. Klicken Sie auf „Weiter“.
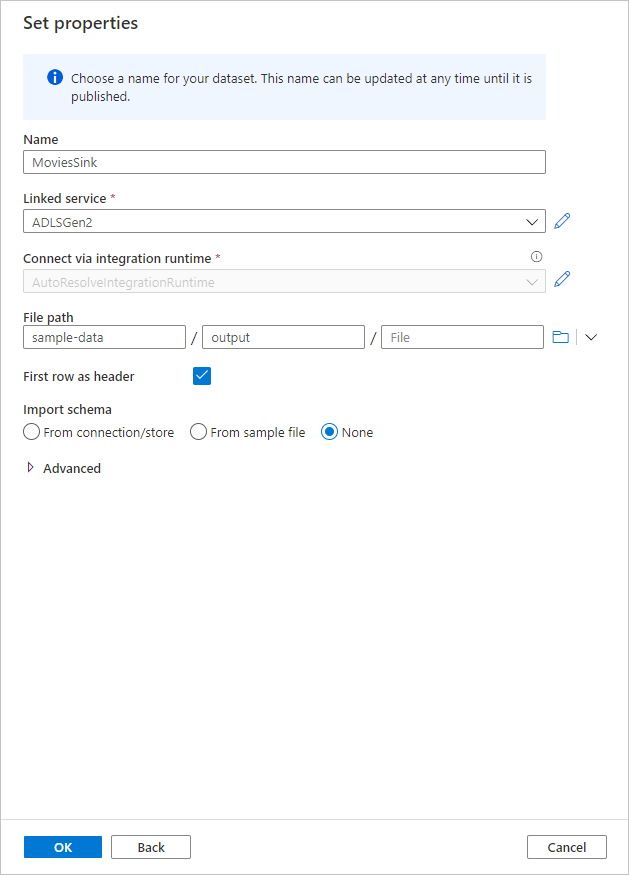
Geben Sie dem Senkendataset den Namen MoviesSink. Wählen Sie als verknüpften Dienst den verknüpften ADLS Gen2-Dienst aus, den Sie in Schritt 7 erstellt haben. Geben Sie einen Ausgabeordner ein, in den die Daten geschrieben werden sollen. In dieser Schnellstartanleitung wird in den Ordner „output“ im Container „sample-data“ geschrieben. Der Ordner muss nicht vorab vorhanden sein und kann dynamisch erstellt werden. Aktivieren Sie das Kontrollkästchen Erste Zeile als Header, und wählen Sie für Schema importieren die Option Kein aus. Klicken Sie nach Abschluss des Vorgangs auf OK.
Sie haben nun die Erstellung des Datenflusses beendet. Jetzt können Sie ihn in ihrer Pipeline ausführen.
Ausführen und Überwachen des Datenflusses
Sie können eine Pipeline vor der Veröffentlichung debuggen. In diesem Schritt lösen Sie eine Debugausführung der Datenflusspipeline aus. Während bei der Datenvorschau keine Daten geschrieben werden, werden bei einer Debugausführung Daten in das Senkenziel geschrieben.
Wechseln Sie zur Pipelinecanvas. Klicken Sie auf Debuggen, um eine Debugausführung auszulösen.
Für das Debuggen der Pipeline von Datenflussaktivitäten wird der aktive Debugcluster verwendet, doch dauert die Initialisierung dennoch mindestens eine Minute. Sie können den Fortschritt über die Registerkarte Ausgabe verfolgen. Wenn die Ausführung erfolgreich ist, klicken Sie auf das Brillensymbol, um den Überwachungsbereich zu öffnen.

Im Überwachungsbereich werden die Anzahl der Zeilen und die Zeit für die einzelnen Transformationsschritte angezeigt.

Klicken Sie auf eine Transformation, um ausführliche Informationen über die Spalten und die Partitionierung der Daten zu erhalten.

Wenn Sie die Schritte dieser Schnellstartanleitung korrekt ausgeführt haben, wurden 83 Zeilen und zwei Spalten in den Senkenordner geschrieben. Sie können den Blobspeicher überprüfen, um die Daten zu verifizieren.
Nächste Schritte
In den folgenden Artikeln finden Sie Informationen zur Unterstützung von Azure Synapse Analytics: