Azure-Plattformresilienz
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architecting Cloud Native .NET Applications for Azure“, verfügbar in der .NET-Dokumentation oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Die Erstellung einer zuverlässigen Anwendung in der Cloud unterscheidet sich von der herkömmlichen lokalen Anwendungsentwicklung. Während Sie in der Vergangenheit höherwertige Hardware zum Hochskalieren gekauft haben, skalieren Sie in einer Cloudumgebung auf. Anstatt zu versuchen, Ausfälle zu verhindern, besteht das Ziel darin, ihre Auswirkungen zu minimieren und das System stabil zu halten.
Zuverlässige Anwendungen in der Cloud weisen jedoch unterschiedliche Merkmale auf:
- Sie sind resilient, erholen sich von Problemen ordnungsgemäß und funktionieren weiterhin.
- Sie bieten Hochverfügbarkeit (High Availability, HA) und werden bestimmungsgemäß in einem fehlerfreien Zustand ohne nennenswerte Downtime ausgeführt.
Das Verständnis, wie diese Merkmale zusammenarbeiten – und wie sie sich auf die Kosten auswirken – ist entscheidend für die Erstellung einer zuverlässigen cloudnativen Anwendung. Wir werden uns als nächstes ansehen, wie Sie Resilienz und Verfügbarkeit in Ihren cloudnativen Anwendungen mithilfe von Features aus der Azure-Cloud aufbauen können.
Entwurf mit Resilienz
Wir haben gesagt, dass Resilienz Ihre Anwendung in die Lage versetzt, auf Ausfälle zu reagieren und dennoch funktionsfähig zu bleiben. Das Whitepaper Resilienz in Azure bietet Anleitungen zum Erreichen von Resilienz auf der Azure-Plattform. Hier sind einige wichtige Empfehlungen:
Hardwarefehler. Sorgen Sie für Redundanz in der Anwendung, indem Sie Komponenten über verschiedene Domänen hinweg bereitstellen. Stellen Sie z. B. mithilfe von Verfügbarkeitsgruppen sicher, dass Azure-VMs in verschiedenen Racks platziert werden.
Rechenzentrumsfehler. Sorgen Sie mithilfe von rechenzentrenübergreifenden Fehlerisolationszonen für Redundanz in der Anwendung. Stellen Sie z. B. mithilfe von Azure-Verfügbarkeitszonen sicher, dass Azure-VMs in verschiedenen Rechenzentren mit Fehlerisolation untergebracht sind.
Regionaler Ausfall. Replizieren Sie die Daten und Komponenten in eine andere Region, damit Anwendungen schnell wiederhergestellt werden können. Verwenden Sie beispielsweise Azure Site Recovery, um Azure-VMs in eine andere Azure-Region zu replizieren.
Hohe Auslastung. Instanzenübergreifender Lastenausgleich, um Auslastungsspitzen zu bewältigen. Platzieren Sie beispielsweise zwei oder mehr Azure-VMs hinter einem Lastenausgleich, um Datenverkehr an alle virtuellen Computer zu verteilen.
Versehentliche Löschung oder Beschädigung von Daten. Sichern Sie Daten, damit sie wiederhergestellt werden können, wenn sie gelöscht oder beschädigt werden. Verwenden Sie beispielsweise Azure Backup, um Ihre Azure-VMs regelmäßig zu sichern.
Entwerfen mit Redundanz
Der Umfang und die Auswirkungen von Fehlern variieren. Ein Hardwarefehler, z. B. ein fehlerhafter Datenträger, kann sich auf einen einzelnen Knoten in einem Cluster auswirken. Ein fehlerhafter Netzwerkswitch kann sich auf ein gesamtes Serverrack auswirken. Weniger häufige Fehler, z. B. ein Stromausfall, können ein ganzes Rechenzentrum beeinträchtigen. In selten Fällen kommt es vor, dass eine gesamte Region nicht mehr verfügbar ist.
Redundanz ist eine Möglichkeit, Anwendungsresilienz bereitzustellen. Die genaue Redundanzstufe hängt von Ihren geschäftlichen Anforderungen ab und wirkt sich sowohl auf die Kosten als auch die Komplexität Ihres Systems aus. Beispielsweise ist eine Bereitstellung in mehreren Regionen teurer und komplexer zu verwalten als eine Bereitstellung in einer Region. Sie benötigen operative Verfahren zur Verwaltung von Failover und Failback. Die zusätzlichen Kosten und die höhere Komplexität sind für einige Geschäftsszenarien ggf. gerechtfertigt, während dies für andere nicht der Fall ist.
Zur Planung von Redundanz müssen Sie die kritischen Pfade in Ihrer Anwendung identifizieren und dann feststellen, ob an jedem Punkt des Pfades Redundanz vorliegt. Wenn ein Subsystem ausfällt, führt die Anwendung dann einen Failover auf ein anderes System durch? Schließlich benötigen Sie ein klares Verständnis der in die Azure-Cloudplattform integrierten Features, die Sie nutzen können, um Ihre Redundanzanforderungen zu erfüllen. Hier finden Sie Empfehlungen für die Konzeption von Redundanz:
Stellen Sie mehrere Instanzen von Diensten bereit. Wenn Ihre Anwendung von einer einzelnen Instanz eines Diensts abhängig ist, entsteht dadurch ein Single Point of Failure. Durch die Bereitstellung von mehreren Instanzen werden Resilienz und Skalierbarkeit verbessert. Beim Hosten in Azure Kubernetes Service können Sie redundante Instanzen (Replikatgruppen) deklarativ in der Kubernetes-Manifestdatei festlegen. Der Wert für die Anzahl der Replikate kann programmgesteuert, über das Portal oder über Features zur automatischen Skalierung verwaltet werden.
Nutzen eines Lastenausgleichs. Der Lastenausgleich verteilt die Anforderungen Ihrer Anwendung auf fehlerfreie Dienstinstanzen und entfernt fehlerhafte Instanzen automatisch aus der Rotation. Beim Bereitstellen in Kubernetes kann der Lastenausgleich in der Kubernetes-Manifestdatei im Abschnitt „Dienste“ angegeben werden.
Planen für die Bereitstellung in mehreren Regionen. Wenn Sie Ihre Anwendung in einer einzelnen Region bereitstellen und diese Region nicht mehr verfügbar ist, wird ihre Anwendung ebenfalls nicht mehr verfügbar sein. Dies kann unter den Bedingungen der Vereinbarungen zum Servicelevel Ihrer Anwendung inakzeptabel sein. Erwägen Sie stattdessen die Bereitstellung Ihrer Anwendung und der zugehörigen Dienste in mehreren Regionen. Beispielsweise wird ein Azure Kubernetes Service-Cluster (AKS) in einer einzelnen Region bereitgestellt. Um Ihr System vor einem regionalen Fehler zu schützen, können Sie Ihre Anwendung in mehreren AKS-Clustern in verschiedenen Regionen bereitstellen und das Feature Regionspaare verwenden, um Plattformupdates zu koordinieren und Wiederherstellungsmaßnahmen zu priorisieren.
Aktivieren der Georeplikation. Die Georeplikation für Dienste wie Azure SQL-Datenbank und Cosmos DB erstellt sekundäre Replikate Ihrer Daten in mehreren Regionen. Während beide Dienste Daten in derselben Region automatisch replizieren, schützt die Georeplikation Sie vor einem regionalen Ausfall, indem Sie einen Failover zu einer sekundären Region durchführen können. Eine weitere bewährte Methode für die Georeplikation dreht sich um das Speichern von Containerimages. Um einen Dienst in AKS bereitzustellen, müssen Sie das Image in einem Repository speichern und von dort pullen. Azure Container Registry ist in AKS integriert und kann Containerimages sicher speichern. Zur Verbesserung der Leistung und Verfügbarkeit sollten Sie in Erwägung ziehen, Ihre Images in jeder Region, in der Sie über einen AKS-Cluster verfügen, per Georeplikation in eine Registrierung zu replizieren. Jeder AKS-Cluster pullt dann Containerimages aus der lokalen Containerregistrierung in seiner Region, wie in Abbildung 6-4 dargestellt:
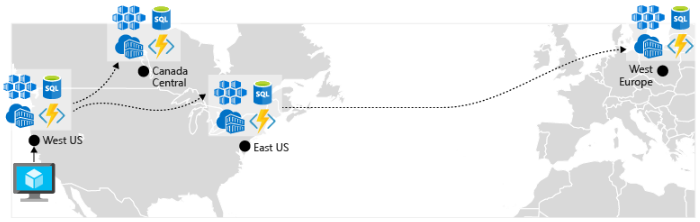
Abbildung 6-4. Replizierte Ressourcen in Regionen
- Implementieren eines Lastenausgleichs für DNS-Datenverkehr.Azure Traffic Manager bietet Hochverfügbarkeit für kritische Anwendungen durch Lastenausgleich auf DNS-Ebene. Es kann den Datenverkehr basierend auf Geografie, Clusterantwortzeit und sogar Anwendungsendpunktintegrität an verschiedene Regionen weiterleiten. Azure Traffic Manager kann beispielsweise Kundendatenverkehr an den nächstgelegenen AKS-Cluster und die nächstgelegene Anwendungsinstanz weiterleiten. Wenn Sie mehrere AKS-Cluster in verschiedenen Regionen bereitgestellt haben, steuern Sie die Weiterleitung des Datenverkehrs an die in jedem Cluster ausgeführten Anwendungen mit Traffic Manager. Abbildung 6-5 zeigt dieses Szenario.
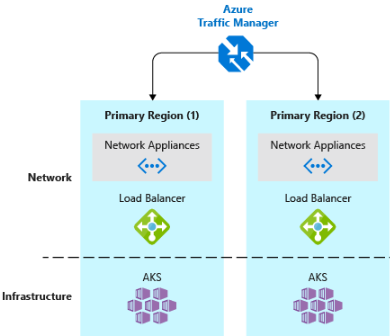
Abbildung 6-5. AKS und Azure Traffic Manager
Skalierbarkeitsorientiertes Design
Die Cloud beruht auf Skalierung. Die Möglichkeit, Systemressourcen zu erhöhen bzw. zu verringern, um der zunehmenden bzw. abnehmenden Systemlast gerecht zu werden, ist ein wichtiger Grundsatz der Azure-Cloud. Für eine effektive Skalierung einer Anwendung müssen Sie jedoch die Skalierungsfeatures der einzelnen Azure-Dienste kennen, die Sie in Ihre Anwendung einbeziehen. Hier sind Empfehlungen für die effektive Implementierung der Skalierung in Ihrem System.
Entwurf im Hinblick auf Skalierung. Eine Anwendung muss für die Skalierung konzipiert sein. Zunächst sollten Dienste zustandslos sein, damit Anforderungen an jede Instanz weitergeleitet werden können. Zustandslose Dienste zu verwenden, bedeutet auch, dass das Hinzufügen oder Entfernen einer Instanz keine negativen Auswirkungen auf aktuelle Benutzer hat.
Partitionieren von Workloads. Durch die Zerlegung von Domänen in unabhängige, in sich geschlossene Microservices kann jeder Dienst unabhängig von anderen skaliert werden. In der Regel haben Dienste unterschiedliche Skalierbarkeitsbedürfnisse und -anforderungen. Die Partitionierung ermöglicht es Ihnen, nur die wirklich erforderlichen Faktoren zu skalieren, ohne die unnötigen Kosten für die Skalierung einer gesamten Anwendung.
Bevorzugen der Aufskalierung. Cloudbasierte Anwendungen bevorzugen das Aufskalieren von Ressourcen im Gegensatz zum Hochskalieren. Beim Aufskalieren (auch als horizontale Skalierung bezeichnet) werden weitere Dienstressourcen zu einem bestehenden System hinzugefügt, um ein gewünschtes Leistungsniveau zu erreichen und freizugeben. Beim Hochskalieren (auch als vertikale Skalierung bezeichnet) werden die vorhandenen Ressourcen durch leistungsfähigere Hardware (mehr Datenträger, Arbeitsspeicher und Prozessorkerne) ersetzt. Das Aufskalieren kann mit den Features zur automatischen Skalierung, die in einigen Azure-Cloudressourcen verfügbar sind, automatisch aufgerufen werden. Durch das Aufskalieren über mehrere Ressourcen wird auch das Gesamtsystem redundant. Schließlich ist das Hochskalieren einer einzelnen Ressource in der Regel teurer als das Hochskalieren vieler kleinerer Ressourcen. Abbildung 6-6 zeigt die beiden Ansätze:
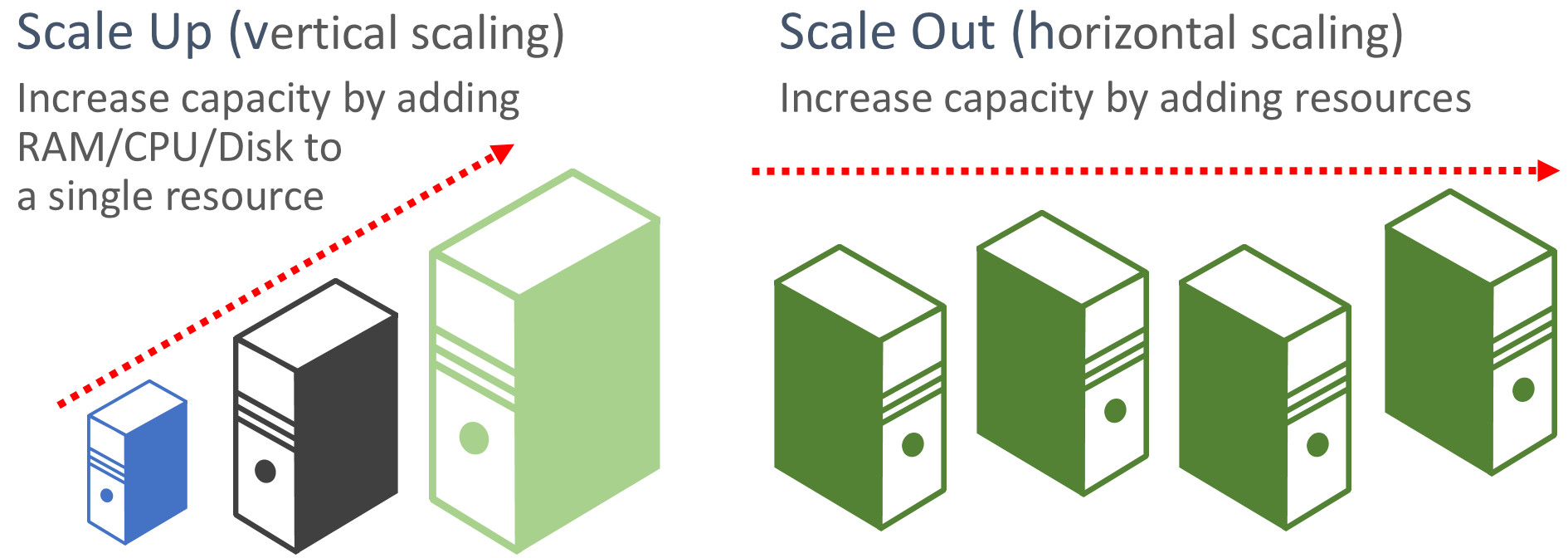
Abbildung 6-6. Hochskalieren im Vergleich zum Aufskalieren
Proportionale Skalierung. Denken Sie beim Skalieren eines Diensts an Ressourcengruppen. Wenn Sie einen bestimmten Dienst drastisch aufskalieren würden, welche Auswirkungen hätte das auf Back-End-Datenspeicher, Caches und abhängige Dienste? Einige Ressourcen wie Cosmos DB können proportional aufskaliert werden, viele andere hingegen nicht. Sie möchten sicherstellen, dass Sie eine Ressource nicht so weit aufskalieren, dass sie andere zugeordnete Ressourcen auslastet.
Vermeiden Sie Affinität. Eine bewährte Methode ist es, sicherzustellen, dass ein Knoten keine lokale Affinität benötigt, was oft als Fixierte Sitzung bezeichnet wird. Eine Anforderung sollte zu jeder Instanz weitergeleitet werden können. Wenn Sie den Status beibehalten müssen, sollte er in einem verteilten Cache gespeichert werden, z. B. Azure Redis Cache.
Nutzung von Funktionen der automatischen Plattformskalierung. Verwenden Sie nach Möglichkeit integrierte Autoskalierungsfeatures anstelle von benutzerdefinierten Mechanismen oder Mechanismen von Drittanbietern. Verwenden Sie wo möglich geplante Skalierungsregeln, um sicherzustellen, dass die Ressourcen ohne Startverzögerung zur Verfügung stehen. Fügen Sie jedoch automatische reaktive Skalierungsregeln hinzu, um gegebenenfalls unerwartete Änderungen der Nachfrage zu bewältigen. Weitere Informationen finden Sie im Leitfaden für die automatische Skalierung.
Aggressives Aufskalieren. Eine letzte Möglichkeit wäre die aggressive Aufskalierung, sodass Sie unmittelbare Spitzen im Datenverkehr schnell bewältigen können, ohne dass Sie Verluste erleiden. Anschließend sollten Sie das System vorsichtig abskalieren (d. h. nicht benötigte Instanzen entfernen), um es stabil zu halten. Eine einfache Möglichkeit, dies zu implementieren, besteht darin, die Abkühlzeit, d. h. die Zeit, die zwischen den Skalierungsvorgängen gewartet wird, auf fünf Minuten für das Hinzufügen von Ressourcen und bis zu 15 Minuten für das Entfernen von Instanzen festzulegen.
Integrierte Wiederholung in Diensten
In einem früheren Abschnitt haben wir die bewährte Methode der Implementierung programmgesteuerter Wiederholungsvorgänge empfohlen. Beachten Sie, dass viele Azure-Dienste und ihre entsprechenden Client-SDKs auch Wiederholungsmechanismen enthalten. In der folgenden Liste sind die Wiederholungsfeatures in den vielen Azure-Diensten zusammengefasst, die in diesem Buch erläutert werden:
Azure Cosmos DB. Die DocumentClient-Klasse aus der Client-API versucht automatisch, fehlerhafte Versuche zu wiederholen. Die Anzahl der Wiederholungen und die maximale Wartezeit sind konfigurierbar. Ausnahmen, die von der Client-API ausgelöst werden, sind entweder Anforderungen, die die Wiederholungsrichtlinie überschreiten, oder nicht vorübergehende Fehler.
Azure Redis Cache. Der Redis StackExchange-Client verwendet eine Verbindungs-Manager-Klasse, die bei fehlerhaften Versuchen Wiederholungen vorsieht. Die Anzahl der Wiederholungsversuche, die spezifische Wiederholungsrichtlinie und die Wartezeit sind alle konfigurierbar.
Azure Service Bus: Der Service Bus-Client stellt eine RetryPolicy-Klasse zur Verfügung, die mit einem Wiederholungsintervall, einer Wiederholungsanzahl und TerminationTimeBuffer konfiguriert werden kann, was die maximale Zeit angibt, die ein Vorgang dauern kann. Die Standardrichtlinie sieht maximal neun Wiederholungsversuche mit einem Backoffzeitraum von 30 Sekunden zwischen den Versuchen vor.
Azure SQL-Datenbank. Bei Verwendung der Entity Framework Core-Bibliothek wird die Unterstützung von Wiederholungen bereitgestellt.
Azure Storage. Die Speicherclientbibliothek unterstützt Wiederholungsvorgänge. Die Strategien variieren zwischen Azure-Speichertabellen, Blobs und Warteschlangen. Darüber hinaus wechseln alternative Wiederholungen zwischen primären und sekundären Speicherdienststandorten, wenn das Feature für Georedundanz aktiviert ist.
Azure Event Hubs. Die Event Hub-Clientbibliothek verfügt über eine RetryPolicy-Eigenschaft, die ein konfigurierbares Feature für den exponentiellen Backoff enthält.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für