Schnellstart: Verschieben und Transformieren von Daten mit Dataflows und Datenpipelines
In diesem Tutorial erfahren Sie, wie die Dataflow- und Datenpipeline-Benutzeroberfläche eine leistungsstarke und umfassende Data Factory-Lösung erstellen kann.
Voraussetzungen
Für Ihren Einsteig müssen die folgenden Voraussetzungen erfüllt sein:
- Ein Mandantenkonto mit einem aktiven Abonnement. Erstellen Sie ein kostenloses Konto.
- Stellen Sie sicher, dass Sie über einen für Microsoft Fabric aktivierten Workspace verfügen: Erstellen Sie einen Workspace, der nicht der Standardarbeitsbereich „Eigener Arbeitsbereich“ ist.
- Eine Azure SQL Datenbank mit Tabellendaten.
- Ein Blob Storage-Konto.
Datenflüsse im Vergleich zu Pipelines
Mit Dataflows Gen2 können Sie eine Low-Code-Schnittstelle und mehr als 300 Daten- und KI-basierte Transformationen nutzen, sodass Sie Daten einfacher und flexibler säubern, vorbereiten und transformieren können als mit anderen Tools. Datenpipelines erlauben es Ihnen, umfangreiche vorgefertigte Datenorchestrierungsfunktionen nutzen, um flexible Datenworkflows zu erstellen, die Ihren Unternehmensanforderungen entsprechen. In einer Pipeline können Sie logische Gruppierungen von Aktivitäten erstellen, die eine Aufgabe ausführen, z. B. das Aufrufen eines Dataflows zum Säubern und Vorbereiten Ihrer Daten. Obwohl zwischen den beiden Funktionen eine Überschneidung besteht, hängt die Auswahl, welche für ein bestimmtes Szenario verwendet werden soll, davon ab, ob Sie den vollen Umfang von Pipelines benötigen oder die einfacheren, aber eingeschränkteren Funktionen von Datenflüssen verwenden können. Weitere Informationen finden Sie im Fabric-Entscheidungsleitfaden
Transformieren von Daten mit Dataflows
Führen Sie die unten angegebenen Schritte aus, um Ihren Dataflow einzurichten.
Schritt 1: Erstellen eines Dataflows
Wählen Sie Ihren für Fabric aktivierten Arbeitsbereich aus, und wählen Sie dann Neu aus. Wählen Sie dann Dataflow Gen2 aus.
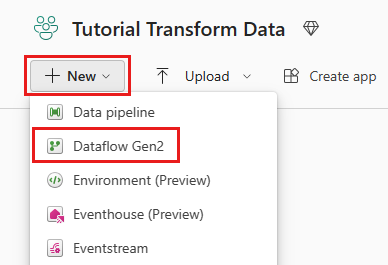
Das Fenster „Dataflow-Editor“ wird angezeigt. Wählen Sie die Karte Aus SQL Server importieren aus.
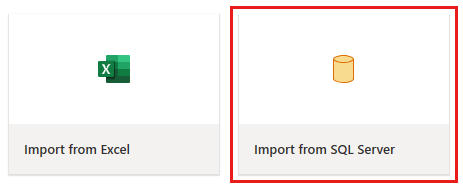

Schritt 2: Bereitstellen von Daten
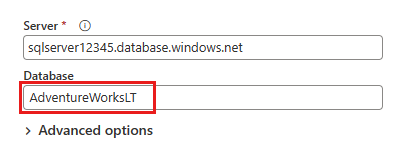
Geben Sie im nächsten Dialogfeld Verbinden mit einer Datenquelle die Details ein, um eine Verbindung mit Ihrer Azure SQL-Datenbank herzustellen, und wählen Sie dann Weiter aus. In diesem Beispiel verwenden Sie die AdventureWorksLT-Beispieldatenbank, die beim Einrichten der Azure SQL-Datenbank in den Voraussetzungen konfiguriert wurde.
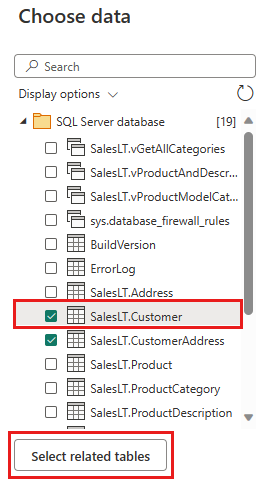
Wählen Sie die Daten aus, die Sie transformieren möchten, und wählen Sie dann Erstellen aus. Wählen Sie in dieser Schnellstartanleitung SalesLT.Customer aus den AdventureWorksLT-Beispieldaten aus, die für Azure SQL DB bereitgestellt werden, und dann die Schaltfläche Verwandte Tabellen auswählen, um automatisch zwei weitere verwandte Tabellen einzuschließen.


Schritt 3: Transformieren Ihrer Daten
Wenn sie nicht ausgewählt ist, wählen Sie die Schaltfläche Diagrammansicht in der Statusleiste unten auf der Seite aus, oder wählen Sie im Menü Ansicht oben im Power Query-Editor die Option Diagrammansicht aus. Jede dieser Optionen kann die Diagrammansicht umschalten.
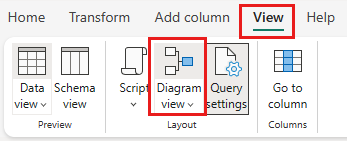
Klicken Sie mit der rechten Maustaste auf Ihre SalesLT Customer-Abfrage, oder wählen Sie die vertikalen Auslassungspunkte rechts neben der Abfrage aus, und wählen Sie dann Abfragen zusammenführen aus.
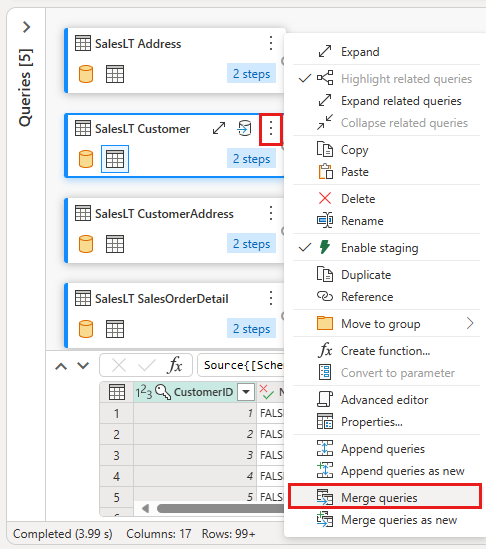
Konfigurieren Sie die Zusammenführung, indem Sie die Tabelle SalesLTOrderHeader als rechte Tabelle für die Zusammenführung, die Spalte CustomerID aus jeder Tabelle als Verknüpfungsspalte Links außen als Verknüpfungsart auswählen. Wählen Sie dann OK aus, um die Zusammenführungsabfrage hinzuzufügen.
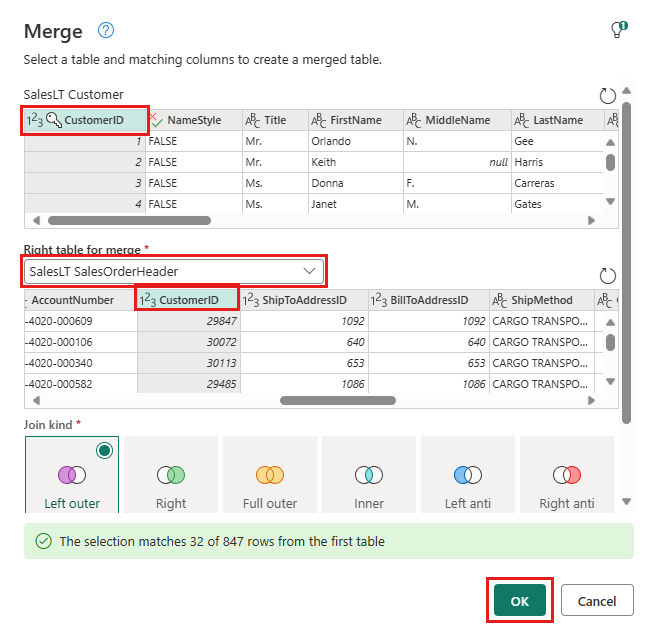
Wählen Sie die Schaltfläche Datenziel hinzufügen, die wie ein Datenbanksymbol mit einem Pfeil darüber aussieht, aus der neuen Zusammenführungsabfrage aus, die Sie gerade erstellt haben. Wählen Sie dann Azure SQL-Datenbank als Datenziel aus.
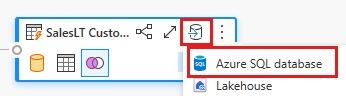
Geben Sie die Details für Ihre Azure SQL-Datenbankverbindung an, in der die Zusammenführungsabfrage veröffentlicht wird. In diesem Beispiel können Sie auch die AdventureWorksLT-Datenbank verwenden, die wir als Datenquelle für das Ziel verwendet haben.
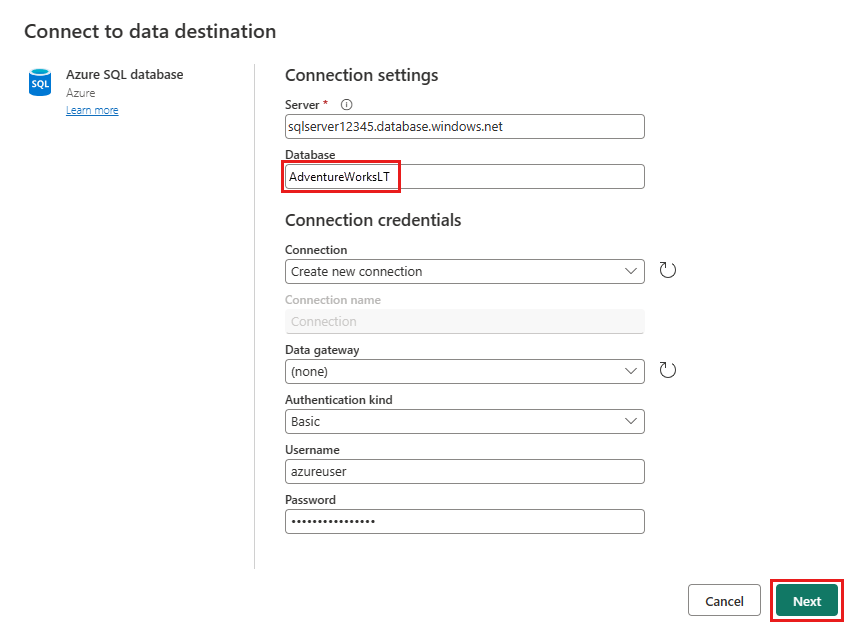
Wählen Sie eine Datenbank zum Speichern der Daten aus, geben Sie einen Tabellennamen an, und wählen Sie dann Weiter aus.
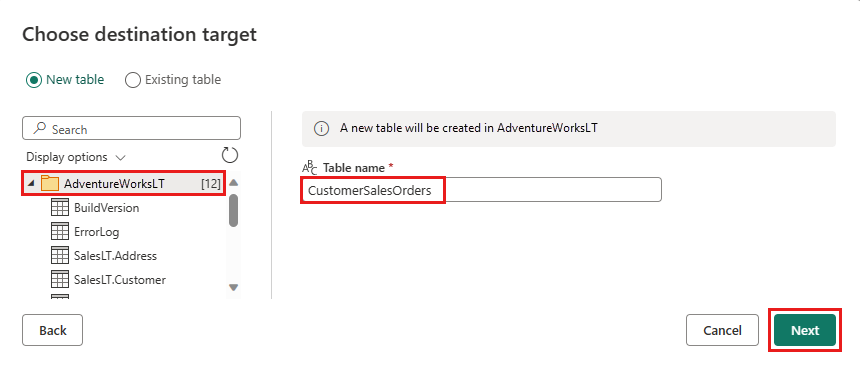
Sie können die Standardeinstellungen im Dialogfeld Zieleinstellungen auswählen beibehalten und einfach Einstellungen speichern auswählen, ohne hier Änderungen vorzunehmen.
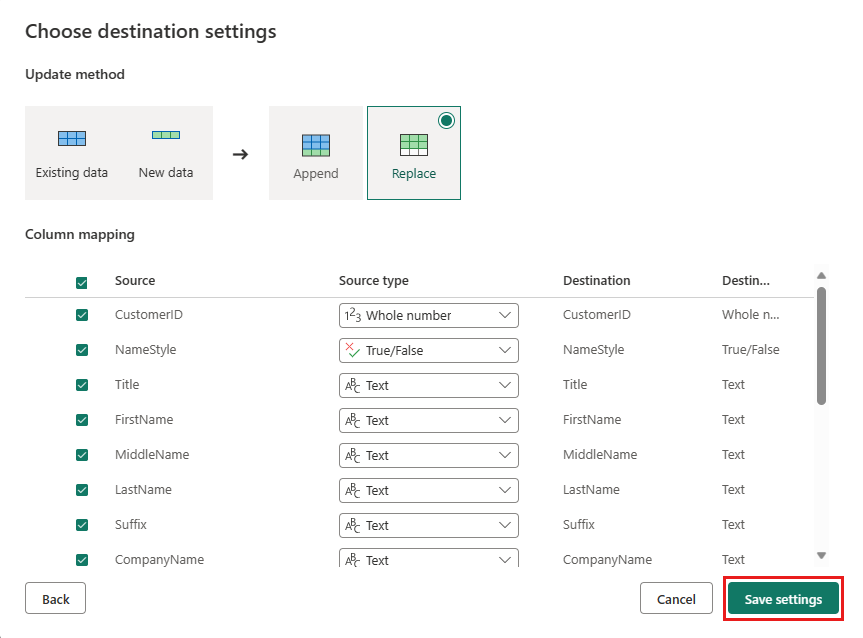
Wählen Sie auf der Dataflow-Editor-Seite Veröffentlichen aus, um den Dataflow zu veröffentlichen.



Verschieben von Daten mit Datenpipelines
Nachdem Sie nun einen Dataflow Gen2 erstellt haben, können Sie ihn in einer Pipeline ausführen. In diesem Beispiel kopieren Sie die aus dem Dataflow generierten Daten in ein Textformat in einem Azure Blob Storage-Konto.
Schritt 1: Erstellen einer neuen Datenpipeline
Wählen Sie in Ihrem Arbeitsbereich Neu und dann Datenpipeline aus.
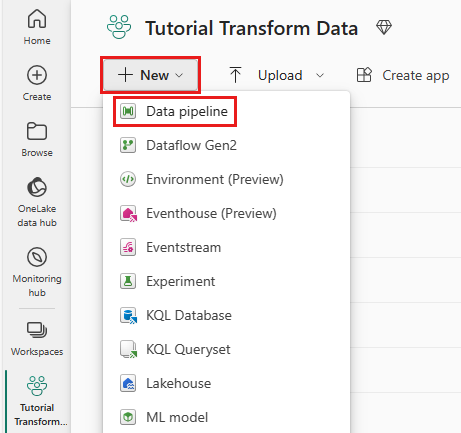
Benennen Sie Ihre Pipeline, und wählen Sie dann Erstellen aus.
Schritt 2: Konfigurieren Ihres Dataflows
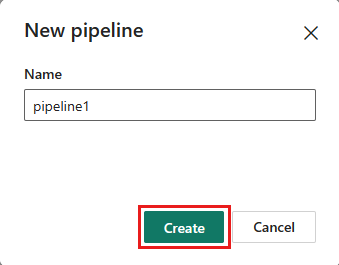
Fügen Sie Ihrer Datenpipeline eine neue Dataflowaktivität hinzu, indem Sie auf der Registerkarte Aktivitäten die Option Dataflow auswählen.

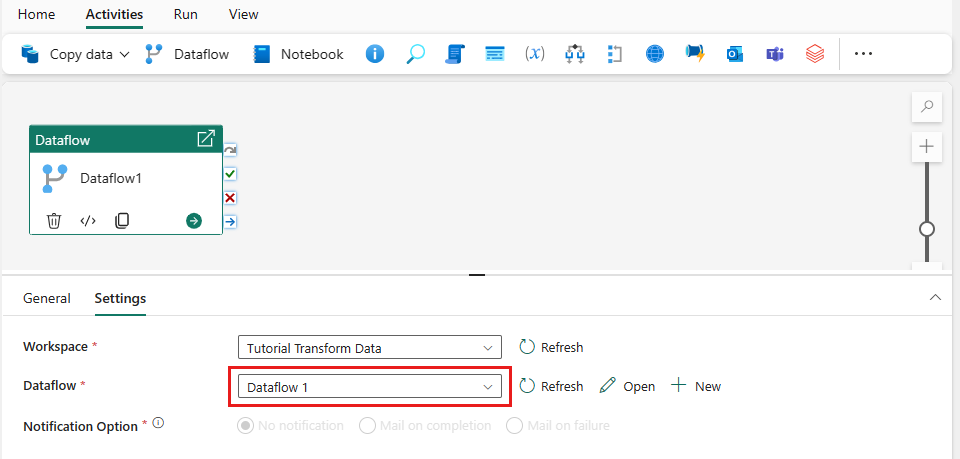
Wählen Sie den Dataflow auf dem Pipelinebereich und dann die Registerkarte Einstellungen aus. Wählen Sie den zuvor erstellten Dataflow aus der Dropdownliste aus.
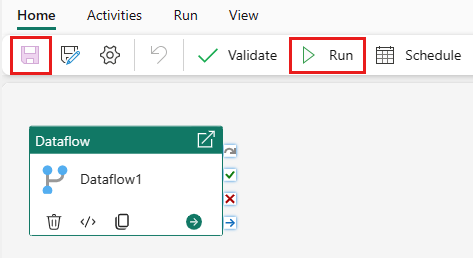
Wählen Sie Speichern und dann Ausführen aus, um den Dataflow auszuführen, damit zunächst die zusammengeführte Abfragetabelle aufgefüllt wird, die Sie im vorherigen Schritt entworfen haben.
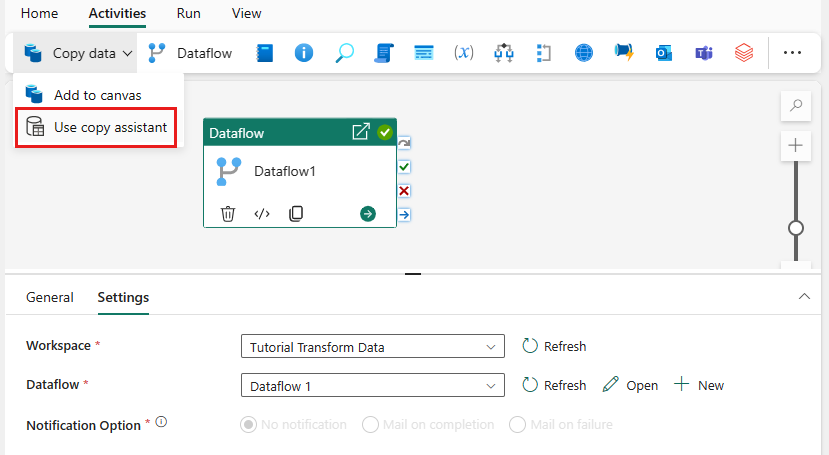
Schritt 3: Verwenden des Kopier-Assistenten zum Hinzufügen einer Kopieraktivität
Wählen Sie Daten kopieren auf der Canvas aus, um den Kopier-Assistenten für erste Schritte zu öffnen. Alternativ können Sie in der Dropdownliste Daten kopieren auf der Registerkarte Aktivitäten im Menüband die Option Kopier-Assistent verwenden auswählen.
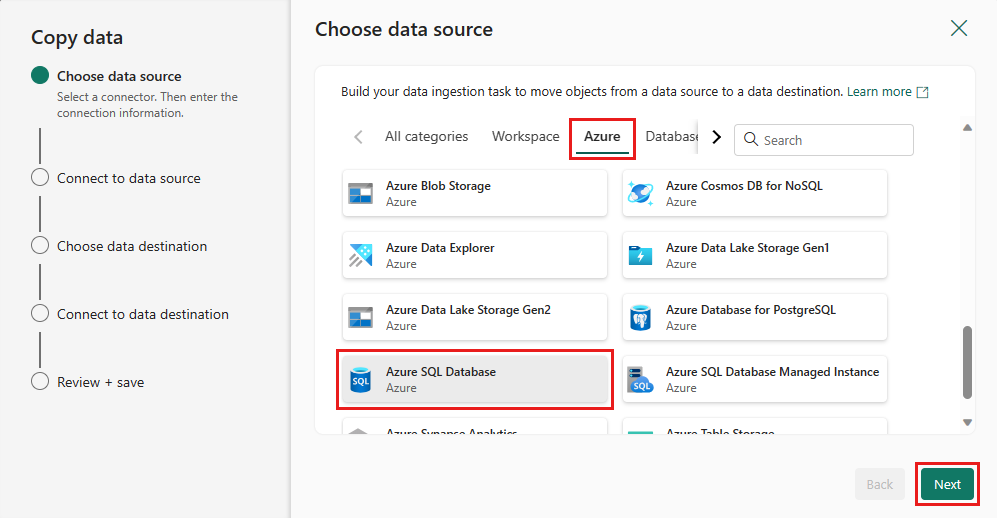
Wählen Sie Ihre Datenquelle aus, indem Sie einen Datenquellentyp auswählen. In diesem Tutorial verwenden Sie die Azure SQL-Datenbank, die zuvor beim Erstellen des Dataflows verwendet wurde, um eine neue Zusammenführungsabfrage zu generieren. Scrollen Sie unter den Beispieldatenangeboten nach unten, und wählen Sie die Registerkarte Azure aus und dann Azure SQL-Datenbank. Wählen Sie dann Weiter aus, um fortzufahren.
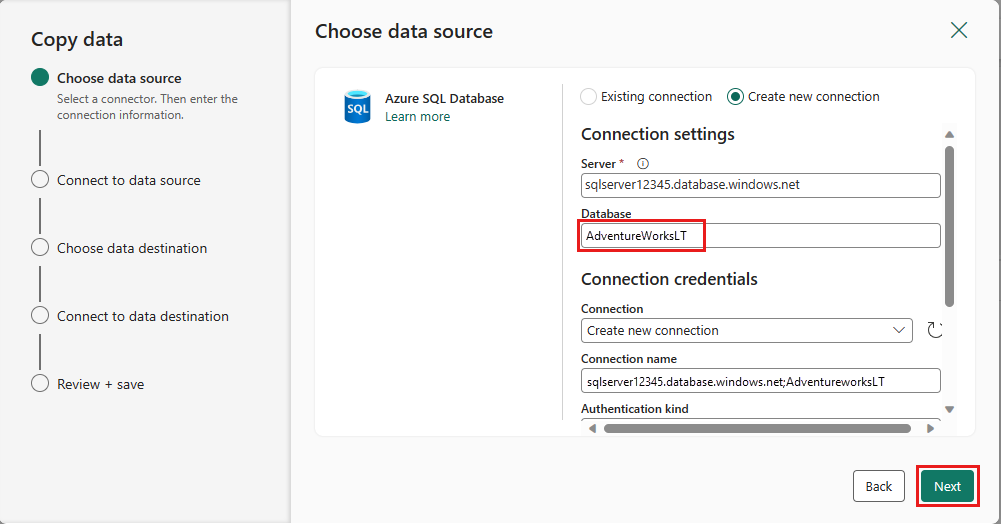
Stellen Sie eine Verbindung mit Ihrer Datenquelle her, indem Sie Neue Verbindung erstellen auswählen. Geben Sie die erforderlichen Verbindungsinformationen im Bereich ein, und geben Sie adventureWorksLT für die Datenbank ein, in der die Zusammenführungsabfrage im Dataflow generiert wurde. Wählen Sie Weiteraus.
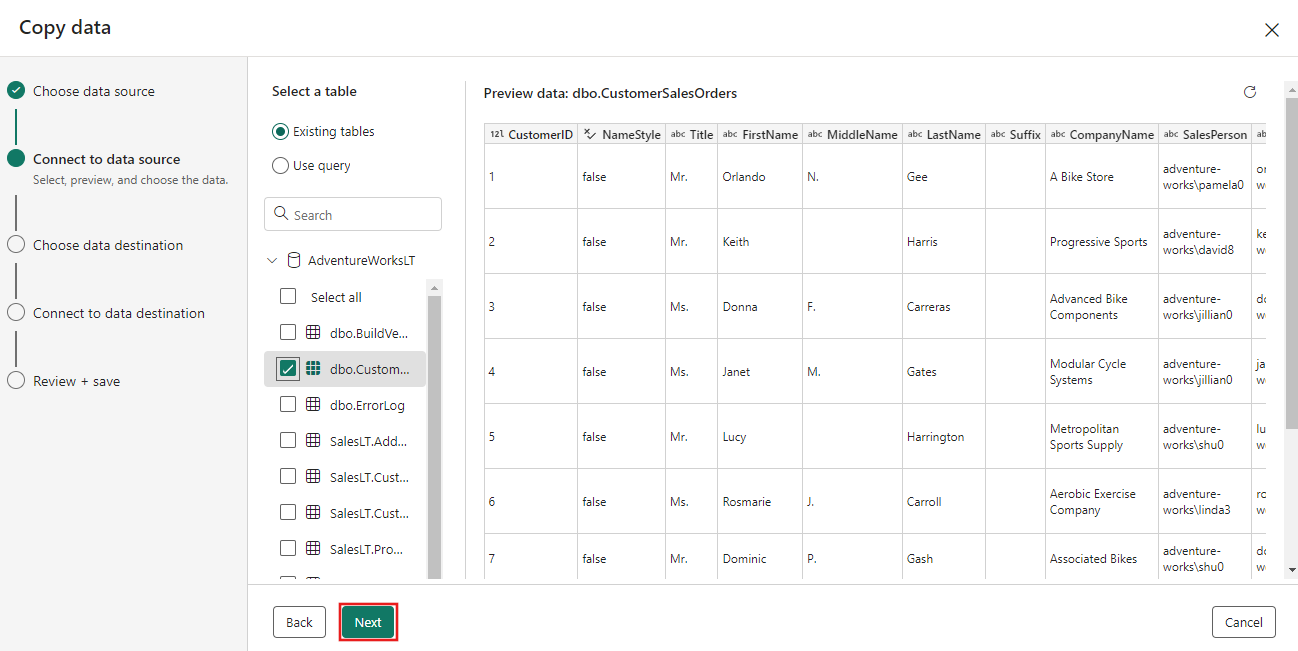
Wählen Sie die Tabelle aus, die Sie zuvor im Dataflow-Schritt generiert haben, und wählen Sie dann Weiter aus.
Wählen Sie als Ziel Azure Blob Storage und dann Weiter aus.
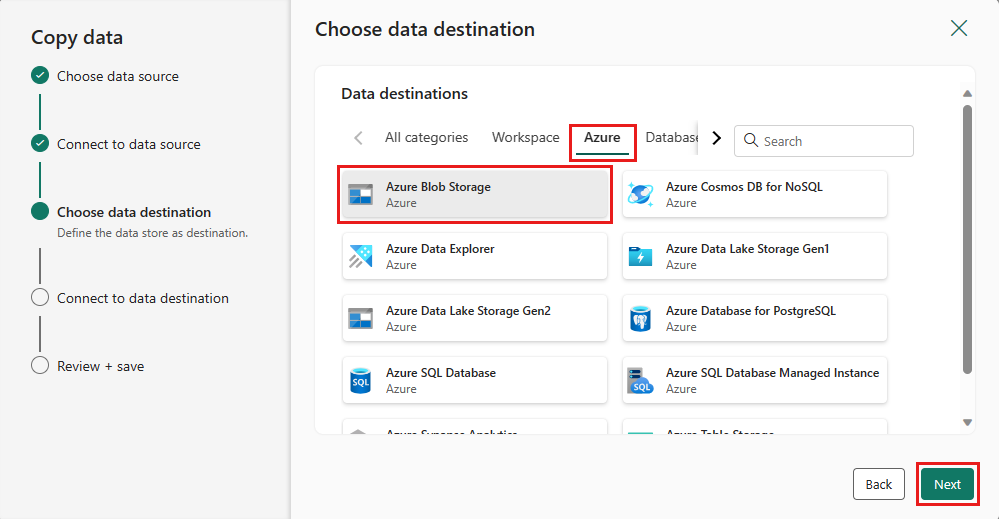
Stellen Sie eine Verbindung mit Ihrem Datenziel her, indem Sie Neue Verbindung erstellen auswählen. Geben Sie die Details für Ihre Verbindung an, und wählen Sie dann Weiter aus.
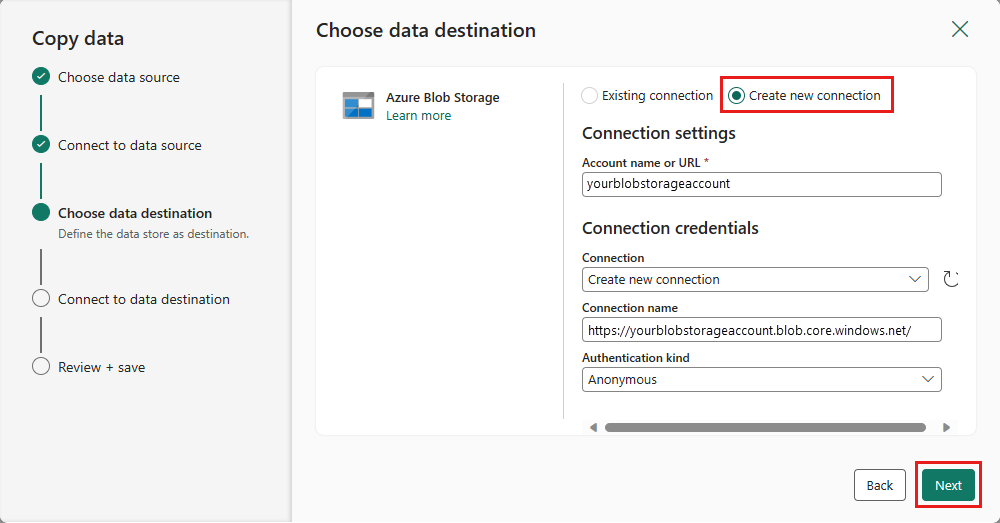
Wählen Sie Ihren Ordnerpfad aus, geben Sie einen Dateinamen an, und wählen Sie dann Weiter aus.
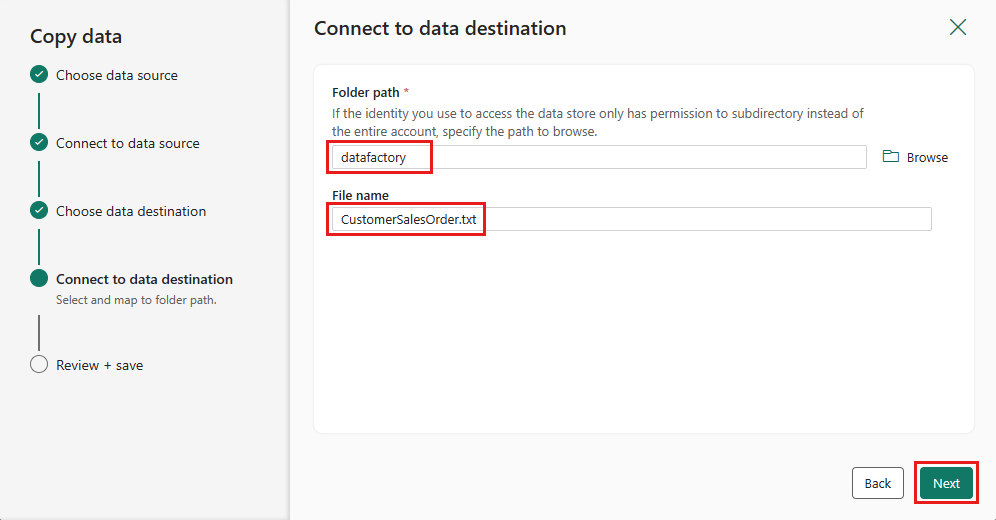
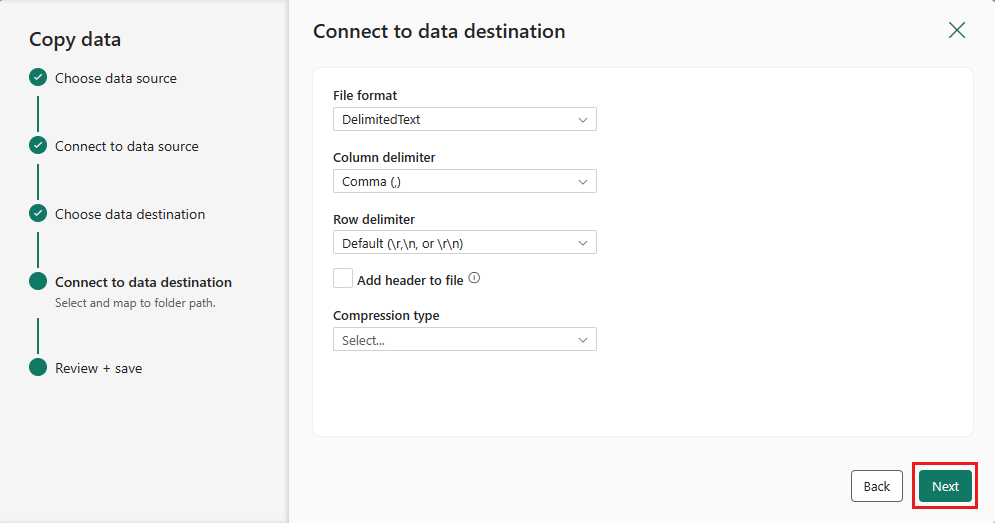
Wählen Sie erneut Weiter aus, um das Standarddateiformat, das Spaltentrennzeichen, das Zeilentrennzeichen und den Komprimierungstyp zu übernehmen, optional auch einen Header.
Schließen Sie Ihre Einstellungen ab. Überprüfen Sie sie dann, und wählen Sie Speichern + Ausführen aus, um den Vorgang abzuschließen.
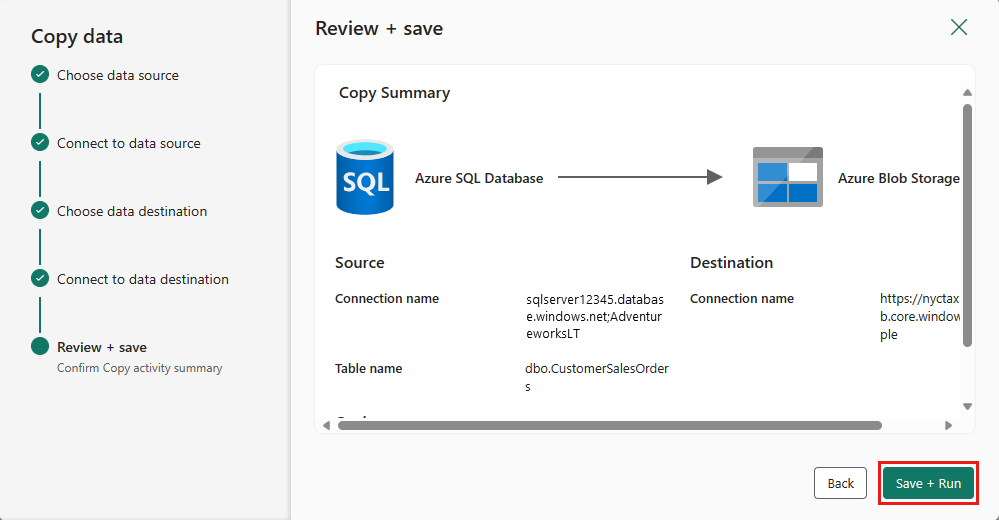
Schritt 5: Entwerfen Ihrer Datenpipeline und Speichern zum Ausführen und Laden von Daten
Um die Kopier-Aktivität nach der Dataflow-Aktivität auszuführen, ziehen Sie von Erfolgreich in der Dataflow-Aktivität zur Kopier-Aktivität. Die Copy-Aktivität wird erst ausgeführt, nachdem die Dataflow-Aktivität erfolgreich war.

Klicken Sie auf Speichern, um Ihre Datenpipeline zu speichern. Wählen Sie dann Ausführen aus, um Ihre Datenpipeline auszuführen und Ihre Daten zu laden.
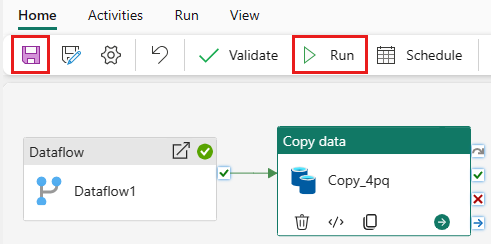
Planen der Pipelineausführung
Sobald Sie die Entwicklung und das Testen Ihrer Pipeline abgeschlossen haben, können Sie ihre automatische Ausführung planen.
Wählen Sie im Fenster des Pipeline-Editors auf der Registerkarte Start die Option Zeitplan aus.
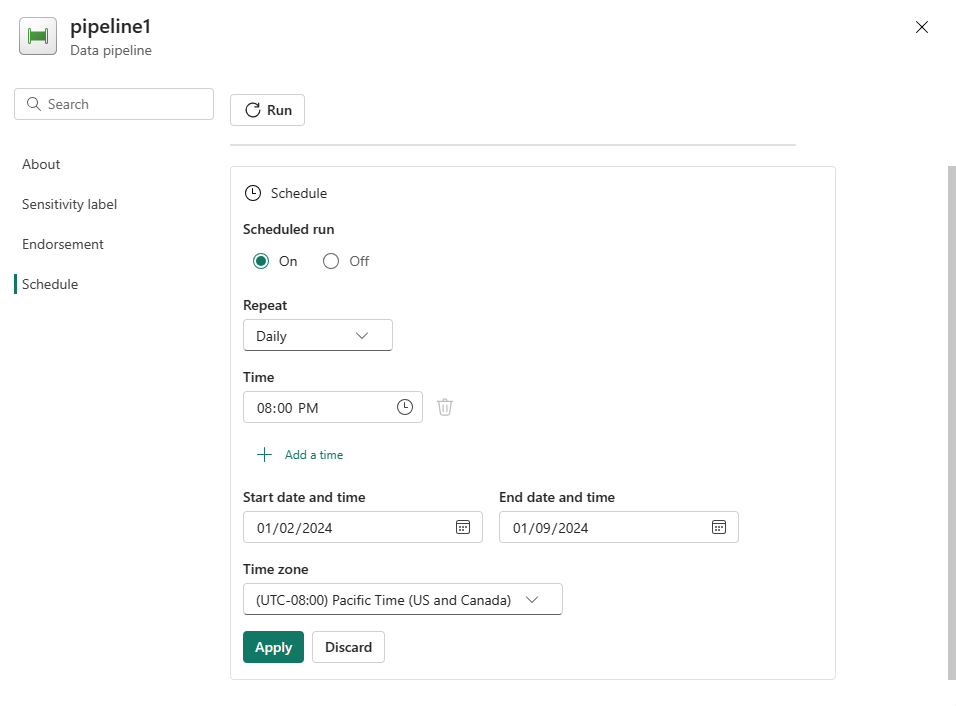
Konfigurieren Sie den Zeitplan nach Bedarf. Im folgenden Beispiel wird die tägliche Ausführung der Pipeline bis zum Ende des Jahres um 20:00 Uhr geplant.
Zugehöriger Inhalt
In diesem Beispiel wird gezeigt, wie Sie einen Dataflow Gen2 erstellen und konfigurieren, um eine Zusammenführungsabfrage zu erstellen und in einer Azure SQL-Datenbank zu speichern und anschließend Daten aus der Datenbank in eine Textdatei in Azure Blob Storage zu kopieren. Sie haben Folgendes gelernt:
- Erstellen Sie einen Dataflow.
- Transformieren Sie Daten mit dem Dataflow.
- Erstellen Sie mithilfe des Dataflows eine Datenpipeline.
- Ordnen Sie die Ausführung der Schritte in der Pipeline an.
- Kopieren Sie Daten mit dem Kopier-Assistenten.
- Führen Sie Ihre Datenpipeline aus, und planen Sie sie.
Erfahren Sie im nächsten Schritt mehr über die Überwachung Ihrer Pipelineausführungen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für