Leitfaden zu m:n-Beziehungen
Dieser Artikel ist an Modellierer von Daten gerichtet, die mit Power BI Desktop arbeiten. In ihm werden drei verschiedene m:n-Modellierungsszenarios beschrieben. Außerdem erhalten Sie eine Anleitung, wie Sie Ihre Modelle entsprechend entwerfen können.
Hinweis
Dieser Artikel enthält jedoch keine Einführung zu Modellbeziehungen. Wenn Sie sich bisher noch wenig mit Beziehungen, ihren Eigenschaften und ihrer Konfiguration beschäftigt haben, sollten Sie sich zuerst den Artikel Modellieren von Beziehungen in Power BI Desktop durchlesen.
Außerdem sollten Sie mit dem Sternschemadesign gut vertraut sein. Weitere Informationen finden Sie im Artikel Informationen zum Sternschema und der Wichtigkeit für Power BI.
Genau genommen gibt es drei Arten von m:n-Beziehungen. Sie können in folgenden Szenarios auftreten:
- Sie möchten zwei Dimensionstabellen in Beziehung bringen.
- Sie wollen zwei Faktentabellen in Beziehung bringen.
- Sie möchten Faktentabellen mit höherer Granularität in Beziehung bringen, wenn Zeilen in der Faktentabelle mit höherer Granularität gespeichert sind als die Zeilen in der Dimensionstabelle.
Hinweis
Power BI unterstützt jetzt nativ m:n-Beziehungen. Weitere Informationen finden Sie unter Anwenden von m:n-Beziehungen in Power BI Desktop.
Herstellen von m:n-Beziehungen zwischen Dimensionen
Sehen Sie sich den ersten m:n-Beziehungstyp anhand des folgenden Beispiels an. In einem klassischen Szenario werden zwei Entitäten aufeinander bezogen: Bankkunden und Bankkonten. Behalten Sie im Hinterkopf, dass Kunden mehrere Konten haben können, und dass Konten mehreren Kunden zugeordnet sein können. Wenn einem Konto mehrere Kunden zugeordnet sind, werden diese üblicherweise als Inhaber eines Gemeinschaftskontos bezeichnet.
Es ist sehr einfach, diese Entitäten zu modellieren. In einer Dimensionstabelle werden die Konten gespeichert, und in einer anderen Dimensionstabelle werden die Kunden gespeichert. Wie es für Dimensionstabellen charakteristisch ist, gibt es in jeder Tabelle eine ID-Spalte. Es ist eine dritte Tabelle erforderlich, um die Beziehung zwischen den beiden Tabellen zu modellieren. Diese Tabelle wird üblicherweise als Brückentabelle bezeichnet. In diesem Beispiel ist es ihre Aufgabe, eine Zeile für jede Kunde-Konto-Zuordnung zu speichern. Ein interessanter Hinweis: Wenn diese Tabelle nur ID-Spalten enthält, wird sie als faktenlose Faktentabelle bezeichnet.
Im Folgenden sehen Sie ein vereinfachtes Modellschaubild der drei Tabellen:
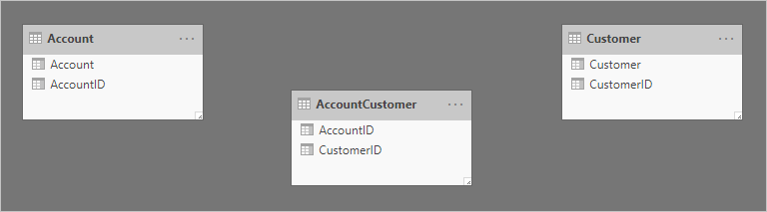
Die erste Tabelle heißt Account (Konto) und enthält zwei Spalten: AccountID (Konto-ID) und Account. Die zweite Tabelle heißt AccountCustomer (Konto – Kunde) und enthält zwei Spalten: AccountID und CustomerID (Kunden-ID). Die dritte Tabelle heißt Customer (Kunde) und enthält zwei Spalten: CustomerID und Customer. Zwischen keiner der Tabellen besteht eine Beziehung.
Zwei 1:n-Beziehungen werden hinzugefügt, um die Tabellen aufeinander zu beziehen. Unten sehen Sie ein aktualisiertes Modellschaubild der aufeinander bezogenen Tabellen. Es wurde eine Faktentabelle namens Transaction hinzugefügt. Darin werden Kontotransaktionen gespeichert. Die Brückentabelle sowie alle ID-Spalten wurden ausgeblendet.
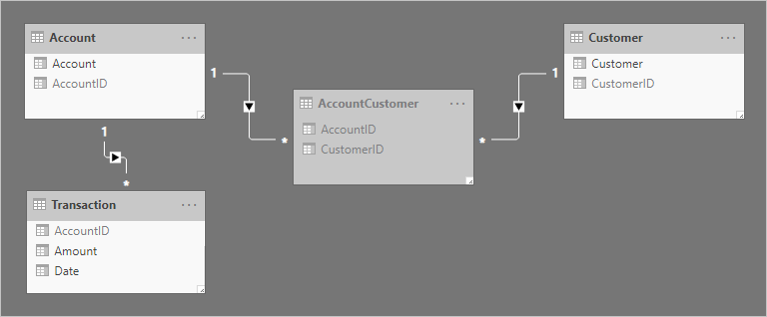
Damit die Funktionsweise der Weitergabe der Beziehungsfilter besser beschrieben werden kann, wurde das Modellschaubild so angepasst, dass die Tabellenzeilen angezeigt werden.
Hinweis
Im Modellschaubild in Power BI Desktop können Tabellenzeilen nicht angezeigt werden. In diesem Artikel wurde das nur getan, um die die Beispiele besser verständlich zu machen.

In der folgenden Aufzählung werden die einzelnen Zeilen der vier Tabellen näher erläutert:
- Die Tabelle Account hat zwei Zeilen:
- AccountID 1 steht für Account-01
- AccountID 2 steht für Account-02
- Die Tabelle Customer hat zwei Zeilen:
- CustomerID 91 steht für Customer-91
- CustomerID 92 steht für Customer-92
- Die Tabelle AccountCustomer hat drei Zeilen:
- AccountID 1 ist CustomerID 91 zugeordnet
- AccountID 1 ist CustomerID 92 zugeordnet
- AccountID 2 ist CustomerID 92 zugeordnet
- Die Tabelle Transaction hat drei Zeilen:
- Date 1. Januar 2019, AccountID 1, Amount (Betrag) 100
- Date 2. Februar 2019, AccountID 2, Amount 200
- Date 3. März 2019, AccountID 1, Amount -25
Sehen Sie sich nun an, was geschieht, wenn das Modell abgefragt wird.
Unten sehen Sie zwei Visuals, die die Spalte Amount aus der Tabelle Transaction zusammenfassen. Im ersten Visual wird nach Konto angeordnet. Die Summe der Spalten Amount ergibt somit das Kontoguthaben. Das zweite Visual ist nach Kunde angeordnet. Die Summe der Spalten Amount ergibt somit das Guthaben der einzelnen Kunden.
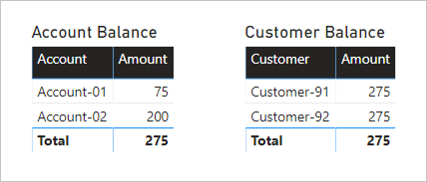
Das erste Visual heißt Account Balance (Kontoguthaben) und hat zwei Spalten: Account und Amount. Das folgende Ergebnis wird dargestellt:
- Der Guthabenbetrag auf „Account-01“ ist 75
- Der Guthabenbetrag auf „Account-02“ ist 200
- Der gesamte Guthabenbetrag ist 275
Das zweite Visual heißt Customer Balance (Kundensaldo) und hat zwei Spalten: Customer und Amount. Das folgende Ergebnis wird dargestellt:
- „Customer-91“ hat ein Guthaben von 275
- „Customer-92“ hat ein Guthaben von 275
- Der Gesamtwert beträgt 275
Ein Blick auf die Tabellenzeilen und das Visual Account Balance zeigt, dass das Ergebnis für jedes Konto sowie der Gesamtbetrag korrekt sind. Das liegt daran, dass jede Kontozuordnung zu einer Weitergabe der Filter auf die Tabelle Transaction für das jeweilige Konto führt.
Beim Visual Customer Balance ist jedoch anscheinend ein Fehler aufgetreten. Für jeden Kunden im Visual Customer Balance wird als Guthaben der Gesamtbetrag angezeigt. Dieses Ergebnis wäre nur korrekt, wenn beide Kunden gemeinschaftliche Inhaber aller Konten wären. In diesem Beispiel ist das jedoch nicht der Fall. Das Problem hat mit der Weitergabe der Filter zu tun. Sie erfolgt nicht durchgängig bis zur Tabelle Transaction.
Sehen Sie sich die Richtungen der Beziehungsfilter ausgehend von der Tabelle Customer bis hin zur Tabelle Transaction genauer an. So müsste Ihnen deutlich auffallen, dass die Beziehung zwischen der Tabelle Account und der Tabelle AccountCustomer in die falsche Richtung weitergegeben wird. Die Filterrichtung für diese Beziehung muss auf Beide festgelegt werden.
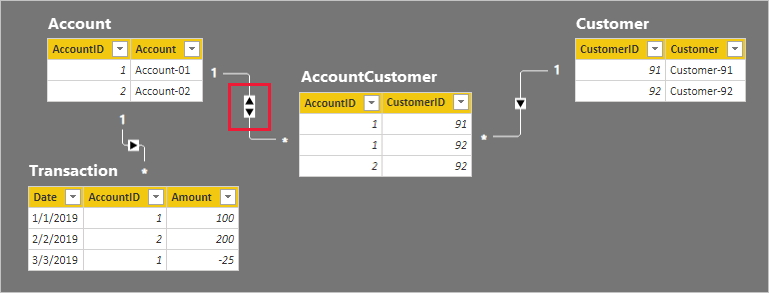

Erwartungsgemäß hat sich am Visual Account Balance nichts geändert.
Das Visual Customer Balance zeigt nun jedoch ein anderes Ergebnis:
- „Customer-91“ hat ein Guthaben von 75
- „Customer-92“ hat ein Guthaben von 275
- Der Gesamtwert beträgt 275
Das Visual Customer Balance zeigt nun ein korrektes Ergebnis an. Sehen Sie sich die Filterrichtungen noch einmal genau an, und versuchen Sie nachzuvollziehen, wie die Guthaben der einzelnen Kunden berechnet wurden. Machen Sie sich dabei auch bewusst, dass sich der sichtbare Gesamtwert auf alle Kunden bezieht.
Wenn Sie sich mit Modellbeziehungen noch nicht so gut auskennen, nehmen Sie möglicherweise an, dass das Ergebnis nicht korrekt ist. Vielleicht fragen Sie sich: Warum beträgt das Gesamtguthaben für Customer-91 und Customer-92 nicht 350 (75 + 275)?
Damit diese Frage beantwortet werden kann, müssen Sie verstanden haben, wie m:n-Beziehungen funktionieren. Für die Guthaben einzelner Kunden können die Guthabenbeträge mehrerer Konten addiert werden, und die einzelnen Guthaben der Kunden selbst sind deshalb nicht additiv.
Anleitung für das Herstellen von Beziehungen zwischen m:n-Dimensionen
Wenn zwischen Dimensionstabellen eine m:n-Beziehung besteht, können Sie der folgenden Anleitung folgen:
- Fügen Sie jede durch eine m:n-Beziehung verbundene Entität als Modelltabelle hinzu, und achten Sie darauf, dass sie eine Spalte für eindeutige Bezeichner (ID) hat.
- Fügen Sie eine Brückentabelle hinzu, um die verbundenen Entitäten zu speichern.
- Erstellen Sie zwischen den drei Tabellen 1:n-Beziehungen.
- Konfigurieren Sie eine bidirektionale Beziehung, damit Filter auf Faktentabellen weitergegeben werden können.
- Wenn ID-Werte zwingend angegeben werden sollen, legen Sie die Eigenschaft Is Nullable der ID-Spalten auf FALSE fest. Die Datenaktualisierung kann dann nicht durchgeführt werden, wenn Bezüge auf fehlende Werte festgestellt werden.
- Blenden Sie die Brückentabelle aus, wenn sie keine Spalten oder Measures enthält, die für die Berichterstellung erforderlich sind.
- Blenden Sie alle ID-Spalten aus, die sich nicht für die Berichterstellung eignen, z. B. IDs, die Ersatzschlüssel sind.
- Wenn eine ID-Spalte nicht ausgeblendet werden sollte, achten Sie darauf, dass sie sich auf der „1“-Seite der Beziehung befindet. Die „n“-seitige Spalte sollten Sie immer ausblenden. So funktionieren Filter am besten.
- Um Verwirrung und Missverständnissen vorzubeugen, können Sie Erklärungen für die Benutzer Ihres Berichts hinzufügen, z. B. Erläuterungen in Textfeldern oder QuickInfos für Visualheader.
Es empfiehlt sich nicht, m:n-Beziehungen zwischen Dimensionstabellen direkt herzustellen. Für diese Art von Design muss eine Beziehung mit einer m:n-Kardinalität konfiguriert werden. Konzeptionell ist das möglich. Es führt jedoch dazu, dass die in Beziehung gesetzten Spalten doppelte Werte enthalten. Es ist ein durchaus gängiger Designansatz. Die hier vorliegenden Dimensionstabellen beinhalten jedoch eine ID-Spalte. Dimensionstabellen sollten die ID-Spalte immer als „1“-Seite einer Beziehung verwenden.
Herstellen von m:n-Beziehungen zwischen Fakten
Beim zweiten Typ eines m:n-Szenarios sollen zwei Faktentabellen aufeinander bezogen werden. Zwei Faktentabellen können direkt aufeinander bezogen werden. Dieser Designansatz kann hilfreich sein für schnelle und einfache Datenanalysen. Es soll aber ausdrücklich darauf hingewiesen werden, dass wir diesen Ansatz nicht empfehlen. Weiter unten in diesem Abschnitt erfahren Sie, warum.
Im Folgenden wird ein Beispiel mit zwei Faktentabellen verwendet: Order (Auftrag) und Fulfillment (Auftragserfüllung). Die Tabelle Order enthält eine Zeile pro Auftragsposition, und die Tabelle Fulfillment kann null oder mehr Zeilen pro Auftragsposition enthalten. Zeilen in der Tabelle Order stehen für Kundenaufträge. Zeilen in der Tabelle Fulfillment stehen für Teile des Auftrags, die bereits versandt wurden. Mit einer m:n-Beziehung werden die beiden OrderID-Spalten aufeinander bezogen. Filter werden dabei nur von der Tabelle Order weitergegeben. Die Tabelle Order filtert dabei die Tabelle Fulfillment.

Die Beziehungskardinalität wird auf „m:n“ festgelegt, damit das Speichern doppelter OrderID-Werte in beiden Tabellen unterstützt wird. In der Tabelle Order dürfen doppelte OrderID-Werte enthalten sein, da ein Auftrag aus mehreren Auftragspositionen bestehen kann. In der Tabelle Fulfillment sind doppelte OrderID-Werte zulässig, da Aufträge aus mehreren Auftragspositionen bestehen können, und die einzelnen Auftragspositionen durch mehrere einzelne Lieferungen erfüllt werden können.
Sehen Sie sich nun die Tabellenzeilen genauer an. Wie Sie in der Tabelle Fulfillment sehen, können Auftragspositionen durch mehrere einzelne Lieferungen erfüllt werden. Wenn eine Auftragsposition nicht angezeigt wird, bedeutet das, sie wurde noch nicht erfüllt.
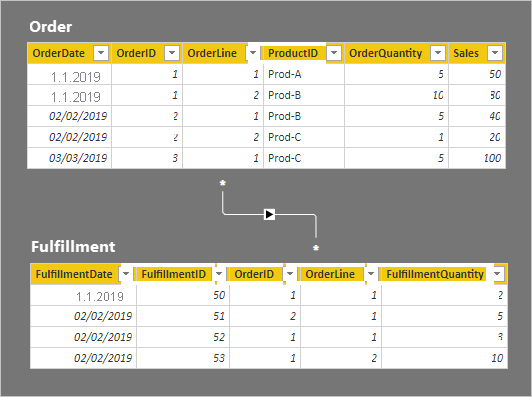
In der folgenden Aufzählung werden die Details zu den Zeilen der zwei Tabellen erläutert:
- Die Tabelle Order besteht aus fünf Zeilen:
- OrderDate (Auftragsdatum) 1. Januar 2019, OrderID 1, OrderLine (Auftragsposition) 1, ProductID Prod-A, OrderQuantity (Auftragsmenge) 5, Sales (Verkäufe) 50
- OrderDate 1. Januar 2019, OrderID 1, OrderLine 2, ProductID Prod-B, OrderQuantity 10, Sales 80
- OrderDate 2. Februar 2019, OrderID 2, OrderLine 1, ProductID Prod-B, OrderQuantity 5, Sales 40
- OrderDate 2. Februar 2019, OrderID 2, OrderLine 2, ProductID Prod-C, OrderQuantity 1, Sales 20
- OrderDate 3. März 2019, OrderID 3, OrderLine 1, ProductID Prod-C, OrderQuantity 5, Sales 100
- Die Tabelle Fulfillment besteht aus vier Zeilen:
- FulfillmentDate (Datum der Erfüllung) 1. Januar 2019, FulfillmentID 50, OrderID 1, OrderLine 1, FulfillmentQuantity (Menge der Erfüllung) 2
- FulfillmentDate 2. Februar 2019, FulfillmentID 51, OrderID 2, OrderLine 1, FulfillmentQuantity 5
- FulfillmentDate 2. Februar 2019, FulfillmentID 52, OrderID 1, OrderLine 1, FulfillmentQuantity 3
- FulfillmentDate 1. Januar 2019, FulfillmentID 53, OrderID 1, OrderLine 2, FulfillmentQuantity10
Sehen Sie sich nun an, was geschieht, wenn das Modell abgefragt wird. Unten sehen Sie ein Tabellenvisual, in dem die Mengen der Aufträge und der Erfüllungen nach der Spalte OrderID der Tabelle Order verglichen werden.
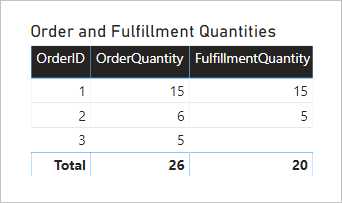
Das Visual stellt ein korrektes Ergebnis dar. Der Nutzen des Modells ist allerdings begrenzt. Sie können nämlich nur nach der Spalte OrderID der Tabelle Order filtern oder anordnen.
Anleitung, um Fakten in m:n-Beziehung zu bringen
Prinzipiell wird davon abgeraten, zwei Faktentabellen mithilfe einer m:n-Kardinalität direkt aufeinander zu beziehen. Der Hauptgrund dafür ist, dass Ihre Berichtsvisuals nicht flexibel gefiltert oder angeordnet werden können. Im Beispiel können Visuals nur nach der Spalte OrderID der Tabelle Order gefiltert oder angeordnet werden. Außerdem kann die Qualität Ihrer Daten beeinträchtigt werden. Wenn es bei Ihren Daten Integritätsprobleme gibt, werden bei der Abfrage manchmal einige Zeilen ausgelassen. Das liegt daran, dass es sich um eine beschränkte Beziehung handelt. Weitere Informationen zu Beziehungen finden Sie unter Modellbeziehungen in Power BI Desktop (Beziehungsauswertung).
Anstatt Faktentabellen direkt aufeinander zu beziehen, sollten Sie lieber das Sternschema als Designansatz verwenden. Dazu fügen Sie Dimensionstabellen hinzu. Die Dimensionstabellen werden dann mithilfe von 1:n-Beziehungen mit den Faktentabellen verbunden. Dieser Designansatz ist stabil, da er flexible Berichterstellungsoptionen bietet. Sie können nach einer beliebigen Spalte der Dimensionstabellen filtern oder anordnen und Zusammenfassungen aller verbunden Faktentabellen erstellen.
Sehen Sie sich im Folgenden eine bessere Lösung an.

Beachten Sie die folgenden Änderungen am Design:
- Das Modell hat nun vier zusätzliche Tabellen: OrderLine, OrderDate, Product und FulfillmentDate.
- Die vier zusätzlichen Tabellen sind alle Dimensionstabellen. Sie sind über 1:n-Beziehungen mit den Faktentabellen verbunden.
- Die Tabelle OrderLine enthält eine Spalte OrderLineID, die den Wert OrderID mit 100 multipliziert darstellt, sowie den Wert OrderLine, einen eindeutigen Bezeichner für jede Auftragsposition.
- Die Tabellen Order und Fulfillment enthalten nun die Spalte OrderLineID, und sie enthalten die Spalten OrderID und OrderLine nicht mehr.
- Die Tabelle Fulfillment enthält nun die Spalten OrderDate und ProductID.
- Die Tabelle FulfillmentDate bezieht sich nur auf die Tabelle Fulfillment.
- Alle Spalten mit eindeutigen Bezeichnern sind ausgeblendet.
Wenn Sie sich die Zeit nehmen, die Designprinzipien des Sternschemas anzuwenden, entstehen Ihnen dadurch die folgenden Vorteile:
- Ihre Berichtsvisuals können nach jeder eingeblendeten Spalte der Dimensionstabellen gefiltert oder angeordnet werden.
- Ihre Berichtsvisuals können Zusammenfassungen jeder eingeblendeten Spalte der Faktentabellen erstellen.
- Filter, die auf die Tabellen OrderLine, OrderDate oder Product angewendet sind, werden für beide Faktentabellen übernommen.
- Alle Beziehungen sind 1:n-Beziehungen und damit reguläre Beziehungen. Probleme mit der Datenintegrität können nicht mehr unentdeckt bleiben. Weitere Informationen zu Beziehungen finden Sie unter Modellbeziehungen in Power BI Desktop (Beziehungsauswertung).
Herstellen von Beziehungen zwischen Fakten mit höherer Granularität
Dieses m:n-Szenario unterscheidet sich stark von den anderen beiden in diesem Artikel bereits erläuterten Szenarios.
Im Folgenden wird ein Beispiel mit vier Tabellen verwendet: Date, Sales, Product und Target (Verkaufsziele). Die Tabellen Date und Product sind Dimensionstabellen, und sie werden über 1:n-Beziehungen auf die Faktentabelle Sales bezogen. Soweit entspricht das dem Sternschemadesign. Die Tabelle Target muss jedoch auf die anderen Tabellen bezogen werden.

Die Tabelle Target enthält drei Spalten: Category (Kategorie), TargetQuantity (Zielmenge) und TargetYear (Zieljahr). In der Tabelle sehen Sie die Granularität von Jahr und Produktkategorie. Anders formuliert: Verkaufsziele, mit denen die Umsatzentwicklung gemessen werden soll, werden jährlich für jede Produktkategorie festgelegt.

Da die Tabelle Target Daten auf einer höheren Ebene speichert als die Dimensionstabellen, kann keine 1:n-Beziehung erstellt werden. Dies gilt allerdings nur für eine der Beziehungen. Im Folgenden erfahren Sie, wie die Tabelle Target auf die Dimensionstabellen bezogen werden kann.
Herstellen von Beziehungen zwischen Zeiträumen mit höherer Granularität
Die Beziehung zwischen den Tabellen Date und Target sollte eine 1:n-Beziehung sein. Das liegt daran, dass die Spaltenwerte für TargetYear Datumsangaben sind. In diesem Beispiel ist jeder Spaltenwert für TargetYear das erste Datum des Jahrs für ein Verkaufsziel.
Tipp
Wenn Fakten mit einer höheren Zeitgranularität als „Tag“ gespeichert werden, müssen Sie den Datentyp für Spalten auf Datum festlegen oder auf Ganze Zahl, wenn Sie Datumsschlüssel verwenden. Speichern Sie in der Spalte einen Wert, der für den ersten Tag des Zeitraums steht. Ein Jahreszeitraum wird beispielsweise als 1. Januar des entsprechenden Jahres gespeichert, ein Monatszeitraum als erster Tag des jeweiligen Monats.
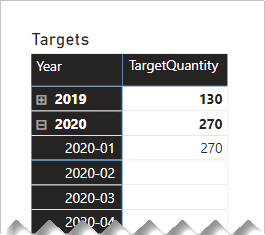
Dabei müssen Sie sorgfältig vorgehen, damit Filter auf Monats- oder Datumsebene sinnvolle Ergebnisse liefern. Ohne spezielle Berechnungslogik geben Berichtsvisuals in Berichten möglicherweise den ersten Tag eines jeweiligen Jahres als Datum für Verkaufsziele an. Die Zusammenfassung für alle anderen Tage und Monate (mit Ausnahme des Januars) ergeben als Zielmenge LEER.
Im folgenden Matrixvisual sehen Sie, was geschieht, wenn sich ein Berichtbenutzer die Monate eines Jahres ansehen möchte. Im Visual ist eine Zusammenfassung der Spalte TargetQuantity dargestellt. Die Option Elemente ohne Daten anzeigen wurde für die Matrixzeilen aktiviert.
Um dieses Fehlverhalten zu umgehen, sollten Sie die Zusammenfassung Ihrer Faktendaten mithilfe von Measures steuern. Eine Möglichkeit, die Zusammenfassung zu steuern, ist es, LEER zurückzugeben, wenn Zeiträume niedrigerer Ebenen abgefragt werden. Eine andere Möglichkeit, die mit komplexeren Funktionen und Operatoren der DAX-Bibliothek definiert wird, ist es, Werte in den Zeiträumen niedrigerer Ebenen zuzuteilen.
Sehen Sie sich die folgende Measuredefinition an, die die DAX-Funktion ISFILTERED verwendet. Es wird nur ein Wert zurückgegeben, wenn die Spalten Date oder Month nicht gefiltert sind.
Target Quantity =
IF(
NOT ISFILTERED('Date'[Date])
&& NOT ISFILTERED('Date'[Month]),
SUM(Target[TargetQuantity])
)
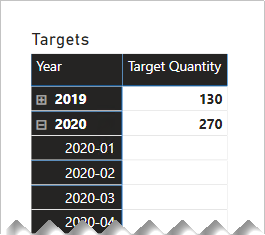
Für das folgende Matrixvisual wird nun das Measure TargetQuantity verwendet. Hier sehen Sie, dass alle Zielmengen für Monate LEER sind.
Herstellen von Beziehungen zwischen Fakten mit höherer Granularität (kein Datum)
Wenn eine Beziehung einer Spalte ohne Datum aus einer Dimensionstabelle zu einer Faktentabelle hergestellt werden soll, und sie eine höhere Granularität als die Dimensionstabelle hat, ist ein anderer Designansatz erforderlich.
In den Category-Spalten aus den Tabellen Product und Target sind doppelte Werte enthalten. Es gibt also kein „1“ für eine 1:n-Beziehung. In diesem Fall müssen Sie eine m:n-Beziehung erstellen. Die Beziehung sollte Filter in eine einzige Richtung weitergeben, nämlich von der Dimensionstabelle auf die Faktentabelle.

Sehen Sie sich nun die Tabellenzeilen genauer an.

In der Tabelle Target sind vier Zeilen enthalten: Zwei Zeilen für jedes Zieljahr (2019 und 2020) und zwei Kategorien („Clothing“ (Kleidung) und „Accessories“ (Accessoires)). In der Tabelle Product sind drei Produkte enthalten. Zwei gehören zur Kategorie „Clothing“ und eine zur Kategorie „Accessories“. Ein Produkt der Kleidungskategorie hat die Farbe „Green“ (Grün), die anderen beiden Produkte sind „Blue“ (Blau).
Das folgende Tabellenvisual ordnet nach der Spalte Category aus der Tabelle Produkt an und führt zu folgendem Ergebnis.
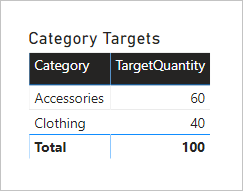
Das Visual kommt zum richtigen Ergebnis. Im Folgenden erfahren Sie nun, was geschieht, wenn die Zielmenge nach der Spalte Color (Farbe) der Tabelle Produkt angeordnet wird.

Das Visual interpretiert die Daten hier also falsch. Warum?
Ein auf die Spalte Color der Tabelle Product angewendeter Filter führt zu zwei Zeilen. Eine der Zeilen steht für die Kategorie „Clothing“, die andere für die Kategorie „Accessories“. Diese zwei Kategoriewerte werden als Filter an die Tabelle Target weitergegeben. Anders gesagt: Da die Farbe „Blau“ von Produkten aus zwei Kategorien verwendet wird, werden diese Kategorien dazu genutzt, um die Zielwerte zu filtern.
Um dieses Fehlverhalten zu umgehen, sollten Sie wie oben bereits erläutert die Zusammenfassung Ihrer Faktendaten mithilfe von Measures steuern.
Sehen Sie sich die folgende Measuredefinition an. Wie Sie sehen können, werden alle Spalten aus der Tabelle Product, die sich unter der Kategorieebene befinden, auf Filter überprüft.
Target Quantity =
IF(
NOT ISFILTERED('Product'[ProductID])
&& NOT ISFILTERED('Product'[Product])
&& NOT ISFILTERED('Product'[Color]),
SUM(Target[TargetQuantity])
)
Für das folgende Tabellenvisual wird nun das Measure TargetQuantity verwendet. Sie können sehen, dass alle Zielmengen für „Color“ LEER sind.

Das endgültige Modelldesign sieht folgendermaßen aus:

Anleitung für das Herstellen einer Beziehung von Fakten mit höherer Granularität
Wenn Sie eine Beziehung zwischen einer Dimensionstabelle und einer Faktentabelle herstellen müssen, und in der Faktentabelle Zeilen mit einer höheren Granularität als in der Dimensionstabelle gespeichert werden, können Sie folgender Anleitung folgen:
- Für Datumsangaben in einer Faktentabelle mit höherer Granularität:
- Speichern Sie in der Faktentabelle das erste Datum des Zeitraums.
- Erstellen Sie eine 1:n-Beziehung zwischen der Tabelle „Date“ und der Faktentabelle
- Für andere Fakten mit höherer Granularität:
- Erstellen Sie eine m:n-Beziehung zwischen der Dimensionstabelle und der Faktentabelle.
- Für beide Arten:
- Steuern Sie die Zusammenfassung mit Measurelogik. Wenn für das Filtern oder Anordnen Spalten aus niedrigeren Ebenen von Dimensionstabellen verwendet werden, sollte LEER zurückgegeben werden.
- Blenden Sie Spalten aus Faktentabellen aus, die zusammengefasst werden können. So kann die Faktentabelle nur mithilfe von Measures zusammengefasst werden.
Zugehöriger Inhalt
Weitere Informationen zu diesem Artikel finden Sie in den folgenden Ressourcen:
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für