Datenbankdateien und Dateigruppen
Gilt für:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Mindestens verfügt jede SQL Server-Datenbank über zwei Betriebssystemdateien: eine Datendatei und eine Protokolldatei. Datendateien enthalten Daten und Objekte wie z. B. Tabellen, Indizes, gespeicherte Prozeduren und Sichten. Protokolldateien enthalten die Informationen, die zum Wiederherstellen aller Transaktionen in der Datenbank erforderlich sind. Datendateien können für die Zuordnung und Verwaltung in Dateigruppen zusammengefasst werden.
Datenbankdateien
SQL Server-Datenbanken weisen drei Dateitypen auf, wie in der folgenden Tabelle dargestellt.
| Datei | Beschreibung |
|---|---|
| Primär | Diese Datei enthält die Startinformationen für die Datenbank und verweist auf die anderen Dateien in der Datenbank. Jede Datenbank verfügt über eine primäre Datendatei. Die empfohlene Dateinamenerweiterung für primäre Datendateien ist MDF. |
| Secondary | Hierbei handelt es sich um optionale, benutzerdefinierte Datendateien. Daten können auf mehrere Datenträger verteilt werden, indem jede Datei auf einem anderen Laufwerk abgelegt wird. Die empfohlene Dateinamenerweiterung für sekundäre Datendateien ist NDF. |
| Transaktionsprotokoll | Das Protokoll enthält Informationen, die zum Wiederherstellen der Datenbank verwendet werden. Für jede Datenbank muss mindestens eine Protokolldatei vorhanden sein. Die empfohlene Dateinamenerweiterung für Transaktionsprotokolle ist LDF. |
Beispielsweise umfasst eine einfache Datenbank mit dem Namen Sales eine primäre Datei, die alle Daten und Objekte enthält, sowie eine Protokolldatei, die die Informationen aus dem Transaktionsprotokoll enthält. Es kann auch eine komplexere Datenbank namens Orders erstellt werden, die eine primäre Datei und fünf sekundäre Dateien enthält. Die Daten und Objekte in der Datenbank verteilen sich auf alle sechs Dateien, und die vier Protokolldateien enthalten die Transaktionsprotokollinformationen.
Standardmäßig werden die Daten und Transaktionsprotokolle auf dem gleichen Laufwerk und unter dem gleichen Pfad abgelegt. Dies ist für Produktionsumgebungen möglicherweise nicht die optimale Wahl. Es wird empfohlen, Daten und Protokolldateien auf verschiedenen Datenträgern zu speichern.
Logische und physische Dateinamen
SQL Server-Dateien weisen zwei Dateinamentypen auf:
logical_file_name: Der logische Dateiname wird dazu verwendet, in allen Transact-SQL-Anweisungen auf die physische Datei zu verweisen. Der logische Dateiname muss den Regeln für SQL Server-Bezeichner entsprechen und innerhalb der logischen Dateinamen in der Datenbank eindeutig sein.
os_file_name: Der Name der Betriebssystemdatei ist der Name der physischen Datei inklusive des Verzeichnispfads. Er muss den betriebssystemspezifischen Regeln für Dateinamen entsprechen.
Weitere Informationen zu und Argument finden Sie unter ALTER DATABASE File and Filegroup Options (Transact-SQL).For more information on the NAME and FILENAME argument, see ALTER DATABASE File and Filegroup Options (Transact-SQL)
Wichtig
SQL Server-Daten und -Protokolldateien können sowohl auf FAT- als auch auf NTFS-Dateisystemen platziert werden. Aufgrund seiner Sicherheitsaspekte wird für Windows-Systeme die Verwendung des NTFS-Dateisystems empfohlen.
Warnung
Datendateigruppen und Protokolldateien für Lese-/Schreibvorgänge werden in mit NTFS komprimierten Dateisystemen nicht unterstützt. Nur schreibgeschützte Datenbanken und schreibgeschützte sekundäre Dateigruppen können auf einem mit NTFS komprimierten Dateisystem platziert werden. Um Speicherplatz zu sparen, wird dringend empfohlen, anstelle der Dateisystemkomprimierung die Datenkomprimierung zu verwenden.
Wenn mehrere Instanzen von SQL Server auf einem einzelnen Computer ausgeführt werden, empfängt jede Instanz ein anderes Standardverzeichnis, um die Dateien für die in der Instanz erstellten Datenbanken zu speichern. Weitere Informationen finden Sie unter Dateispeicherorte für Standard- und benannte Instanzen von SQL Server.
Datendateiseiten
Die Seiten in einer SQL Server-Datendatei erhalten aufeinander folgende Seitennummern, beginnend mit null (0) für die erste Seite in der Datei. Jede Datei in einer Datenbank verfügt über eine eindeutige ID-Nummer. Um eine Seite in einer Datenbank eindeutig zu identifizieren, ist sowohl die Datei-ID als auch die Seitennummer erforderlich. Im folgenden Beispiel werden die Seitennummern in einer Datenbank dargestellt, die über eine 4 MB umfassende primäre Datendatei und eine 1 MB umfassende sekundäre Datendatei verfügt.
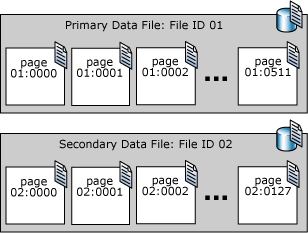
Eine Dateiheaderseite ist die erste Seite, die Informationen zu den Attributen der Datei enthält. Viele der anderen Seiten am Anfang der Datei enthalten ebenfalls Systeminformationen, wie z. B. Zuordnungstabellen. Eine der Systemseiten, die sowohl in der primären Datendatei als auch in der ersten Protokolldatei gespeichert ist, ist eine Datenbank-Startseite, die Informationen zu den Attributen der Datenbank enthält.
Dateigröße
SQL Server-Dateien können ausgehend von ihrer ursprünglich angegebenen Größe automatisch wachsen. Wenn Sie eine Datei definieren, können Sie eine bestimmte Schrittweite für die Vergrößerung angeben. Sobald die Datei vollständig aufgefüllt ist, wird sie um den als Schrittweite festgelegten Wert vergrößert. Wenn eine Dateigruppe mehrere Dateien enthält, beginnt die automatische Vergrößerung erst dann, wenn alle Dateien vollständig gefüllt sind.
Weitere Informationen zu Seiten und Seitentypen finden Sie im Handbuch zur Architektur von Seiten und Blöcken.
Für jede Datei kann zudem eine Maximalgröße angegeben werden. Wenn keine Maximalgröße angegeben wird, kann die Datei so lange vergrößert werden, bis der gesamte verfügbare Speicherplatz auf dem Datenträger belegt ist. Dieses Feature ist besonders nützlich, wenn SQL Server als in eine Anwendung eingebettete Datenbank verwendet wird, in der der Benutzer keinen bequemen Zugriff auf einen Systemadministrator hat. Der Benutzer kann festlegen, dass die Dateien nach Bedarf automatisch vergrößert werden, sodass die administrative Arbeit reduziert werden kann, die mit der Überwachung des freien Speicherplatzes in der Datenbank und der manuellen Zuordnung von zusätzlichem Speicherplatz verbunden ist.
Weitere Informationen zur Verwaltung von Transaktionsprotokolldateien finden Sie unter Verwalten der Größe der Transaktionsprotokolldatei.
Datenbank-Momentaufnahmedateien
Das von einer Datenbankmomentaufnahme zum Speichern der Kopie-bei-Schreibvorgang-Daten verwendete Dateiformat hängt davon ab, ob die Momentaufnahme von einem Benutzer erstellt oder intern verwendet wird:
- Eine von einem Benutzer erstellte Datenbankmomentaufnahme speichert die Daten in mindestens einer Sparsedatei. Die Technologie von Dateien mit geringer Dichte ist eine Funktion des NTFS-Dateisystems. Anfangs enthält eine Sparsedatei keine Benutzerdaten. Zudem ist dieser Datei kein Speicherplatz für Benutzerdaten zugeordnet. Allgemeine Informationen zum Verwenden von Sparsedateien in Datenbankmomentaufnahmen sowie zum Wachstum von Datenbankmomentaufnahmen finden Sie unter Anzeigen der Größe der Sparsedatei einer Datenbank-Momentaufnahme (Transact-SQL).
- Datenbankmomentaufnahmen werden intern von bestimmten DBCC-Befehlen verwendet. Zu diesen Befehlen zählen DBCC CHECKDB, DBCC CHECKTABLE, DBCC CHECKALLOC und DBCC CHECKFILEGROUP. Eine interne Datenbankaufnahme verwendet alternative Datenströme mit geringer Dichte der ursprünglichen Datenbankdateien. So wie Sparsedateien stellen auch alternative Datenströme eine Funktion des NTFS-Dateisystems dar. Die Verwendung alternativer Datenströme mit geringer Dichte ermöglicht das Zuordnen mehrerer Datenzuweisungen zu einer einzelnen Datei bzw. zu einem einzelnen Ordner, ohne Auswirkung auf die Dateigröße oder -umfangstatistiken.
Dateigruppen
- Die primäre Dateigruppe enthält die primäre Datendatei und alle sekundären Dateien, die nicht in andere Dateigruppen eingefügt werden.
- Benutzerdefinierte Dateigruppen können erstellt werden, um Datendateien zum Zweck der Verwaltung, Datenzuordnung und -verteilung zu Gruppen zusammenzufassen.
Beispielsweise können Data1.ndf, Data2.ndf und Data3.ndf entsprechend auf drei unterschiedlichen Datenträgern erstellt und der Dateigruppe fgroup1 zugewiesen werden. Anschließend kann eine Tabelle speziell für die Dateigruppe fgroup1 erstellt werden. Abfragen für Daten in der Tabelle werden auf alle drei Datenträger verteilt, wodurch die Leistung gesteigert wird. Dieselbe Leistungssteigerung kann auch durch die Verwendung einer einzigen Datei erzielt werden, wenn diese auf einem RAID-Stripeset (Redundant Array of Independent Disks; redundantes Datenträgerarray) erstellt wird. Dateien und Dateigruppen ermöglichen Ihnen jedoch das problemlose Hinzufügen neuer Dateien zu neuen Datenträgern.
Alle Datendateien werden in den Dateigruppen gespeichert, die in der folgenden Tabelle aufgeführt werden.
| Dateigruppe | Beschreibung |
|---|---|
| Primär | Die Dateigruppe, die die primäre Datei enthält. Alle Systemtabellen sind Teil der primären Dateigruppe. |
| Speicheroptimierte Tabelle | Die speicheroptimierte Dateigruppe basiert auf Filestream-Dateigruppen. |
| Filestream | |
| Benutzerdefiniert | Dies bezeichnet jede Dateigruppe, die durch den Benutzer erstellt wird, wenn dieser die Datenbank erstmals erstellt oder zu einem späteren Zeitpunkt ändert. |
Standarddateigruppe (Primär)
Wenn Objekte in der Datenbank ohne Angabe einer Dateigruppe erstellt werden, werden sie der Standarddateigruppe zugewiesen. Zu jedem Zeitpunkt wird genau eine Dateigruppe zur Standarddateigruppe erklärt. Die Dateien in der Standarddateigruppe müssen groß genug sein, um alle neuen Objekte aufnehmen zu können, die nicht anderen Dateigruppen zugeordnet werden.
Die PRIMARY-Dateigruppe stellt die Standarddateigruppe dar, sofern diese nicht mithilfe der ALTER DATABASE-Anweisung geändert wird. Systemobjekte und -tabellen sind weiterhin der Dateigruppe PRIMARY (primäre Dateigruppe) und nicht der neuen Standarddateigruppe zugeordnet.
Speicheroptimierte Datendateigruppe
Weitere Informationen zu speicheroptimierten Dateigruppen finden Sie unter Speicheroptimierte Dateigruppe.
Filestream-Dateigruppe
Weitere Informationen zu Filestream-Dateigruppen finden Sie unter FILESTREAM und Erstellen einer FILESTREAM-aktivierten Datenbank.
Datei- und Dateigruppenbeispiel
Im folgenden Beispiel wird eine Datenbank auf einer SQL Server-Instanz erstellt. Die Datenbank verfügt über eine primäre Datendatei, eine benutzerdefinierte Dateigruppe und eine Protokolldatei. Die primäre Datendatei befindet sich in der primären Dateigruppe, und die benutzerdefinierte Dateigruppe verfügt über zwei sekundäre Datendateien. Durch die ALTER DATABASE-Anweisung wird die benutzerdefinierte Dateigruppe als Standarddateigruppe festgelegt. Anschließend wird eine Tabelle unter Angabe der benutzerdefinierten Dateigruppe erstellt. (Dieses Beispiel verwendet einen generischen Pfad, c:\Program Files\Microsoft SQL Server\MSSQL.1 , um die Angabe einer SQL Server-Version zu vermeiden.)
USE master;
GO
-- Create the database with the default data
-- filegroup, filestream filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON PRIMARY
( NAME='MyDB_Primary',
FILENAME=
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE=4MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP MyDB_FG1
( NAME = 'MyDB_FG1_Dat1',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
( NAME = 'MyDB_FG1_Dat2',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM
( NAME = 'MyDB_FG_FS',
FILENAME = 'c:\Data\filestream1')
LOG ON
( NAME='MyDB_log',
FILENAME =
'c:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE=1MB,
MAXSIZE=10MB,
FILEGROWTH=1MB);
GO
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
GO
-- Create a table in the user-defined filegroup.
USE MyDB;
CREATE TABLE MyTable
( cola int PRIMARY KEY,
colb char(8) )
ON MyDB_FG1;
GO
-- Create a table in the filestream filegroup
CREATE TABLE MyFSTable
(
cola int PRIMARY KEY,
colb VARBINARY(MAX) FILESTREAM NULL
)
GO
In der folgenden Abbildung werden die Ergebnisse des vorherigen Beispiels (ohne die Filestream-Daten) zusammengefasst.

Füllstrategie für Dateien und Dateigruppen
Dateigruppen verwenden eine proportionale Füllstrategie über alle Dateien innerhalb einer Dateigruppe hinweg. Da Daten in die Dateigruppe geschrieben werden, schreibt das SQL Server-Datenbankmodul eine Menge proportional zum freien Speicherplatz in der Datei in jede Datei innerhalb der Dateigruppe, anstatt alle Daten in die erste Datei bis vollständig zu schreiben. Dann werden Daten in die nächste Datei geschrieben. Wenn z. B. Datei „f1“ über 100 MB und Datei „f2“ über 200 MB freien Speicherplatz verfügt, stammt ein Block aus Datei „f1“, zwei Blöcke aus Datei „f2“ usw. Auf diese Weise werden beide Dateien zum ungefähr gleichen Zeitpunkt vollständig gefüllt, und es wird eine einfache Aufteilung der Daten erzielt.
Nehmen Sie z. B. an, eine Dateigruppe enthält drei Dateien, und für jede Datei wurde die automatische Vergrößerung festgelegt. Wenn der Speicherplatz in allen Dateien der Dateigruppe vollständig verbraucht ist, wird nur die erste Datei erweitert. Wenn die erste Datei gefüllt ist und keine Daten mehr in die Dateigruppe geschrieben werden können, wird die zweite Datei vergrößert. Wenn die zweite Datei gefüllt ist und keine Daten mehr in die Dateigruppe geschrieben werden können, wird die dritte Datei vergrößert. Wenn die dritte Datei gefüllt ist und keine Daten mehr in die Dateigruppe geschrieben werden können, wird erneut die erste Datei vergrößert usw.
Regeln für das Entwerfen von Dateien und Dateigruppen
Für Dateien und Dateigruppen gelten die folgenden Regeln:
- Eine Datei oder Dateigruppe kann nicht von mehreren Datenbanken verwendet werden. So können z. B. die Dateien „sales.mdf“ und „sales.ndf“, die Daten und Objekte der Datenbank „sales“ enthalten, von keiner anderen Datenbank verwendet werden.
- Eine Datei kann nur Mitglied einer einzigen Dateigruppe sein.
- Transaktionsprotokolldateien können niemals Teil einer Dateigruppe sein.
Empfehlungen
Empfehlungen für die Arbeit mit Dateien und Dateigruppen:
- Die meisten Datenbanken funktionieren problemlos mit nur einer einzigen Datendatei und einer einzigen Transaktionsprotokolldatei.
- Wenn Sie mehrere Datendateien verwenden, erstellen Sie eine zweite Dateigruppe für die zusätzlichen Datei und legen diese Dateigruppe als Standarddateigruppe fest. Auf diese Weise enthält die primäre Datei nur die Systemtabellen und -objekte.
- Um eine optimale Leistung zu erzielen, sollten Sie Dateien oder Dateigruppen so weit wie möglich auf unterschiedlichen verfügbaren Datenträgern erstellen. Verteilen Sie Objekte, die viel Speicherplatz beanspruchen, auf unterschiedliche Dateigruppen.
- Verwenden Sie Dateigruppen, um Objekte auf bestimmte physische Datenträger verteilen zu können.
- Verteilen Sie unterschiedliche Tabellen, die in denselben Joinabfragen verwendet werden, auf unterschiedliche Dateigruppen. Auf diese Weise wird die Leistung verbessert, da die verknüpften Daten in parallelen Datenträger-E/A-Vorgängen gesucht werden.
- Verteilen Sie Tabellen, auf die häufig zugegriffen wird, und die nicht gruppierten Indizes, die zu diesen Tabellen gehören, auf unterschiedliche Dateigruppen. Durch die Verwendung verschiedener Dateigruppen wird die Leistung verbessert, da auf Dateien, die sich auf unterschiedlichen physischen Datenträgern befinden, parallele E/A-Vorgänge ausgeführt werden können.
- Platzieren Sie die Transaktionsprotokolldatei(en) nicht auf demselben physischen Datenträger wie die anderen Dateien und Dateigruppen.
- Wenn Sie ein Volume oder eine Partition erweitern müssen, auf dem sich Datenbankdateien mit Tools wie Diskpart befinden, sollten Sie zuerst alle System- und Benutzerdatenbanken sichern und SQL Server-Dienste beenden. Außerdem sollten Sie in Erwägung ziehen, nach erfolgreicher Erweiterung von Datenträgervolumes den Befehl
DBCC CHECKDBauszuführen, um die physische Integrität aller auf dem Volume befindlicher Datenbanken sicherzustellen.
Weitere Informationen und Empfehlungen zur Verwaltung von Transaktionsprotokolldateien finden Sie unter Verwalten der Größe der Transaktionsprotokolldatei.
Verwandte Inhalte
CREATE DATABASE (SQL Server Transact-SQL)
ALTER DATABASE-Optionen Datei und Dateigruppe (Transact-SQL)
Datenbanktrennzeichen und Anfügen (SQL Server)
Handbuch zur Architektur und Verwaltung von Transaktionsprotokollen in SQL Server
Handbuch zur Architektur von Seiten und Blöcken
Verwalten der Größe der Transaktionsprotokolldatei
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für