Trainieren Ihres Datenanalysemodells mit PyTorch
In der vorherigen Phase dieses Tutorials haben wir das Dataset abgerufen, das wir zum Trainieren unseres Datenanalysemodells mit PyTorch einsetzen. Nun ist es an der Zeit, diese Daten zu verwenden.
Um das Datenanalysemodells mit PyTorch zu trainieren, müssen Sie die folgenden Schritte ausführen:
- Laden Sie die Daten. Wenn Sie den vorherigen Schritt dieses Tutorials abgeschlossen haben, haben Sie dies bereits erledigt.
- Definieren Sie ein neuronales Netz.
- Definieren Sie eine Verlustfunktion.
- Trainieren Sie das Modell anhand der Trainingsdaten.
- Testen Sie das Netzwerk mit den Testdaten.
Definieren eines neuronalen Netzes
In diesem Tutorial erstellen Sie ein einfaches neuronales Netzmodell mit drei linearen Ebenen. Die Struktur des Modells ist wie folgt:
Linear -> ReLU -> Linear -> ReLU -> Linear
Eine lineare Ebene wendet eine lineare Transformation auf die eingehenden Daten an. Sie müssen die Anzahl der Eingabefeatures und der Ausgabefeatures angeben, die der Anzahl der Klassen entsprechen sollen.
Eine ReLU-Ebene ist eine Aktivierungsfunktion, mit der alle eingehenden Features auf 0 oder größer festgelegt werden. Wenn eine ReLU-Ebene angewendet wird, wird jede Zahl kleiner als 0 in 0 geändert, während andere Zahlen gleich bleiben. Wir wenden die Aktivierungsebene auf die beiden ausgeblendeten Ebenen und keine Aktivierung auf der letzten linearen Ebene an.
Modellparameter
Modellparameter hängen von unserem Ziel und den Trainingsdaten ab. Die Eingabegröße hängt von der Anzahl der Features ab, die wir in das Modell eingeben – in unserem Fall vier. Die Ausgabegröße ist drei, da es drei mögliche Schwertlilienarten gibt.
Mit drei linearen Ebenen ((4,24) -> (24,24) -> (24,3)) hat das Netz 744 Gewichtungen (96+576+72).
Die Lernrate (lr) legt fest, wie stark Sie die Gewichtungen unseres Netz in Bezug auf den Verlustgradienten anpassen. Je niedriger der Wert ist, desto langsamer ist das Training. In diesem Tutorial legen Sie lr auf 0,01 fest.
Wie funktioniert ein neuronales Netz?
Hier erstellen wir ein Feedforward-Netz. Während des Trainings verarbeitet das Netzwerk die Eingabe über alle Ebenen, berechnet den Verlust, um zu verstehen, wie weit die vorhergesagte Bezeichnung des Bilds von der richtigen abweicht, und gibt die Abstufungen zurück an das Netzwerk, um die Gewichtungen der Ebenen zu aktualisieren. Durch die Iteration über ein großes Dataset von Eingaben „lernt“ das Netzwerk, seine Gewichtungen festzulegen, um die besten Ergebnisse zu erzielen.
Eine Vorwärtsfunktion (Forward) berechnet den Wert der Verlustfunktion, eine Rückwärtsfunktion (Backward) die Gradienten der lernbaren Parameter. Wenn Sie unser neuronales Netzwerk mit PyTorch erstellen, müssen Sie nur die Vorwärtsfunktion definieren. Die Rückwärtsfunktion wird automatisch definiert.
- Kopieren Sie in Visual Studio den folgenden Code in die Datei
DataClassifier.py, um die Modellparameter und das neuronale Netz zu definieren.
# Define model parameters
input_size = list(input.shape)[1] # = 4. The input depends on how many features we initially feed the model. In our case, there are 4 features for every predict value
learning_rate = 0.01
output_size = len(labels) # The output is prediction results for three types of Irises.
# Define neural network
class Network(nn.Module):
def __init__(self, input_size, output_size):
super(Network, self).__init__()
self.layer1 = nn.Linear(input_size, 24)
self.layer2 = nn.Linear(24, 24)
self.layer3 = nn.Linear(24, output_size)
def forward(self, x):
x1 = F.relu(self.layer1(x))
x2 = F.relu(self.layer2(x1))
x3 = self.layer3(x2)
return x3
# Instantiate the model
model = Network(input_size, output_size)
Außerdem müssen Sie das Ausführungsgerät basierend auf dem verfügbaren Gerät auf Ihrem PC festlegen. PyTorch bietet keine dedizierte Bibliothek für GPU, doch Sie können das Ausführungsgerät manuell bestimmen. Das Gerät ist eine Nvidia-GPU, sofern auf Ihrem Computer vorhanden, oder Ihre CPU, falls nicht.
- Kopieren Sie den folgenden Code, um das Ausführungsgerät festzulegen:
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device\n")
model.to(device) # Convert model parameters and buffers to CPU or Cuda
- Bestimmen Sie im letzten Schritt eine Funktion zum Speichern des Modells:
# Function to save the model
def saveModel():
path = "./NetModel.pth"
torch.save(model.state_dict(), path)
Hinweis
Möchten Sie mehr über neuronale Netzwerke mit PyTorch erfahren? Sehen Sie sich die PyTorch-Dokumentation an.
Definieren einer Verlustfunktion
Eine Verlustfunktion berechnet einen Wert, der schätzt, wie weit die Ausgabe vom Ziel entfernt ist. Das Hauptziel besteht darin, den Wert der Verlustfunktion zu reduzieren, indem die Gewichtungsvektorwerte durch Rückpropagierung in neuronalen Netzwerken geändert werden.
Der Verlustwert unterscheidet sich von der Modellgenauigkeit. Die Verlustfunktion stellt dar, wie gut sich ein Modell nach jeder Iteration der Optimierung für das Trainingsdataset verhält. Die Genauigkeit des Modells wird anhand der Testdaten berechnet und gibt den Prozentsatz richtiger Vorhersagen wieder.
In PyTorch enthält das neuronale Netzwerkpaket verschiedene Verlustfunktionen, die die Bausteine von Deep Neural Networks bilden. Wenn Sie mehr über diese Besonderheiten erfahren möchten, beginnen Sie mit dem obigen Hinweis. Hier verwenden wir die vorhandenen Funktionen, die für eine solche Klassifizierung optimiert sind, und eine Kreuzentropie-Verlustfunktion für die Klassifizierung sowie einen Adam-Optimierer. Für den Optimierer legt die Lernrate (lr) fest, wie stark Sie die Gewichtungen unseres Netzes in Bezug auf den Verlustgradienten anpassen. Sie legen sie hier auf 0,001 fest – je niedriger, desto langsamer das Training.
- Kopieren Sie den folgenden Code in die Datei
DataClassifier.pyin Visual Studio, um die Verlustfunktion und einen Optimierer zu definieren.
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Trainieren Sie das Modell anhand der Trainingsdaten.
Um das Modell zu trainieren, müssen Sie eine Schleife über unseren Dateniterator ausführen, die Eingaben an das Netzwerk übergeben und optimieren. Um die Ergebnisse zu überprüfen, vergleichen Sie einfach nach jeder Trainingsepoche die prognostizierten Bezeichnungen mit den tatsächlichen Bezeichnungen im Validierungsdataset.
Das Programm zeigt den Trainingsverlust, den Validierungsverlust und die Genauigkeit des Modells für jede Epoche oder für jede vollständige Iteration des Trainingsdatasets an. Es speichert das Modell mit der höchsten Genauigkeit, und nach 10 Epochen zeigt das Programm die endgültige Genauigkeit an.
- Fügen Sie der
DataClassifier.py-Datei den folgenden Code hinzu.
# Training Function
def train(num_epochs):
best_accuracy = 0.0
print("Begin training...")
for epoch in range(1, num_epochs+1):
running_train_loss = 0.0
running_accuracy = 0.0
running_vall_loss = 0.0
total = 0
# Training Loop
for data in train_loader:
#for data in enumerate(train_loader, 0):
inputs, outputs = data # get the input and real species as outputs; data is a list of [inputs, outputs]
optimizer.zero_grad() # zero the parameter gradients
predicted_outputs = model(inputs) # predict output from the model
train_loss = loss_fn(predicted_outputs, outputs) # calculate loss for the predicted output
train_loss.backward() # backpropagate the loss
optimizer.step() # adjust parameters based on the calculated gradients
running_train_loss +=train_loss.item() # track the loss value
# Calculate training loss value
train_loss_value = running_train_loss/len(train_loader)
# Validation Loop
with torch.no_grad():
model.eval()
for data in validate_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
val_loss = loss_fn(predicted_outputs, outputs)
# The label with the highest value will be our prediction
_, predicted = torch.max(predicted_outputs, 1)
running_vall_loss += val_loss.item()
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
# Calculate validation loss value
val_loss_value = running_vall_loss/len(validate_loader)
# Calculate accuracy as the number of correct predictions in the validation batch divided by the total number of predictions done.
accuracy = (100 * running_accuracy / total)
# Save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
# Print the statistics of the epoch
print('Completed training batch', epoch, 'Training Loss is: %.4f' %train_loss_value, 'Validation Loss is: %.4f' %val_loss_value, 'Accuracy is %d %%' % (accuracy))
Testen Sie das Modell anhand der Testdaten.
Nachdem wir das Modell trainiert haben, können wir es mit dem Testdataset testen.
Wir fügen zwei Testfunktionen hinzu. Die erste testet das Modell, das Sie im vorherigen Teil gespeichert haben. Sie testet das Modell mit dem Testdataset mit 45 Elementen und gibt die Genauigkeit des Modells aus. Bei der zweiten Funktion handelt es sich um eine optionale Funktion, mit der die Zuverlässigkeit des Modells bei der Vorhersage jeder der drei Schwertlilienarten getestet werden kann – dargestellt durch die Wahrscheinlichkeit einer erfolgreichen Klassifizierung der einzelnen Arten.
- Fügen Sie der Datei
DataClassifier.pyden folgenden Code hinzu.
# Function to test the model
def test():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
running_accuracy = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
outputs = outputs.to(torch.float32)
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
total += outputs.size(0)
running_accuracy += (predicted == outputs).sum().item()
print('Accuracy of the model based on the test set of', test_split ,'inputs is: %d %%' % (100 * running_accuracy / total))
# Optional: Function to test which species were easier to predict
def test_species():
# Load the model that we saved at the end of the training loop
model = Network(input_size, output_size)
path = "NetModel.pth"
model.load_state_dict(torch.load(path))
labels_length = len(labels) # how many labels of Irises we have. = 3 in our database.
labels_correct = list(0. for i in range(labels_length)) # list to calculate correct labels [how many correct setosa, how many correct versicolor, how many correct virginica]
labels_total = list(0. for i in range(labels_length)) # list to keep the total # of labels per type [total setosa, total versicolor, total virginica]
with torch.no_grad():
for data in test_loader:
inputs, outputs = data
predicted_outputs = model(inputs)
_, predicted = torch.max(predicted_outputs, 1)
label_correct_running = (predicted == outputs).squeeze()
label = outputs[0]
if label_correct_running.item():
labels_correct[label] += 1
labels_total[label] += 1
label_list = list(labels.keys())
for i in range(output_size):
print('Accuracy to predict %5s : %2d %%' % (label_list[i], 100 * labels_correct[i] / labels_total[i]))
Abschließend fügen wir den Hauptcode hinzu. Dadurch wird das Modelltraining gestartet, das Modell gespeichert und die Ergebnisse auf dem Bildschirm angezeigt. Wir führen nur zwei Iterationen [num_epochs = 25] mit dem Trainingssatz durch, sodass der Trainingsprozess nicht zu lange dauern wird.
- Fügen Sie der Datei
DataClassifier.pyden folgenden Code hinzu.
if __name__ == "__main__":
num_epochs = 10
train(num_epochs)
print('Finished Training\n')
test()
test_species()
Führen wir den Test durch! Stellen Sie sicher, dass die Dropdownmenüs in der oberen Symbolleiste auf Debug festgelegt sind. Ändern Sie Solution Platform in x64, um das Projekt auf Ihrem lokalen Computer ausführen, wenn Sie ein 64-Bit-Gerät verwenden, oder in x86 für ein 32-Bit-Gerät.
- Klicken Sie zum Ausführen des Projekts auf der Symbolleiste auf die Schaltfläche
Start Debugging, oder drücken SieF5.
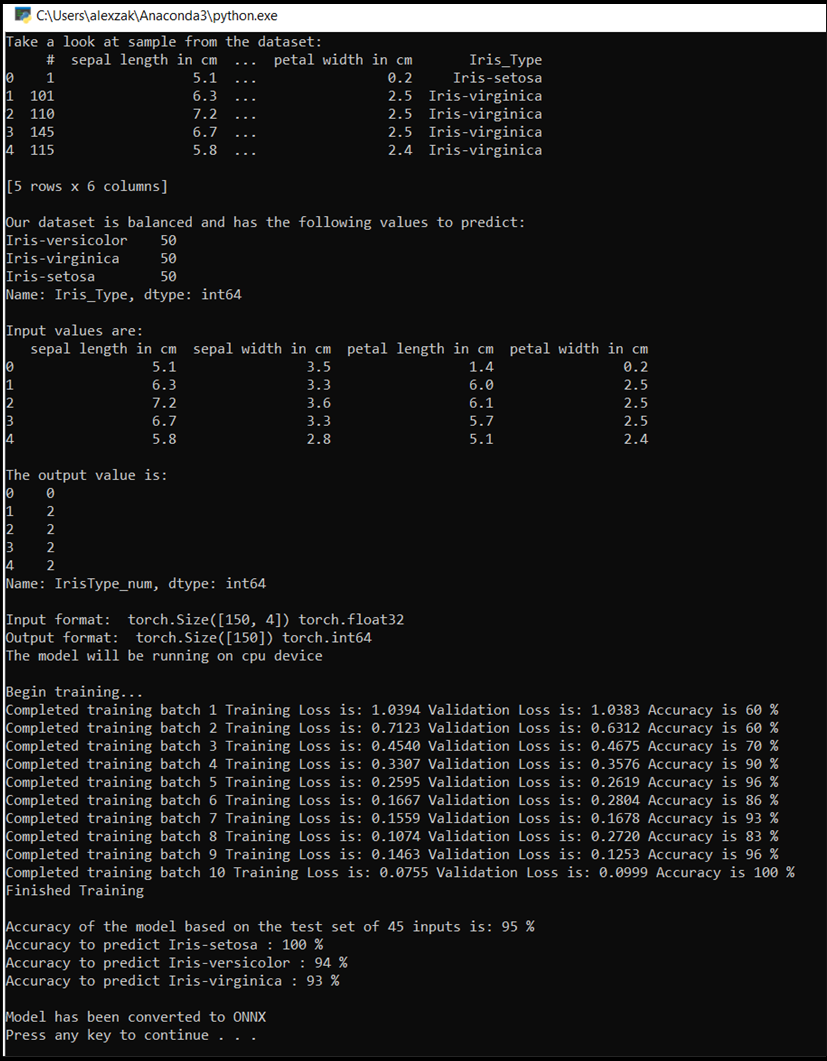
Das Konsolenfenster wird geöffnet, in dem Sie den Trainingsprozess einsehen können. Gemäß Ihrer Festlegung wird der Verlustwert mit jeder Epoche ausgegeben. Es wird erwartet, dass der Verlustwert mit jeder Schleife abnimmt.
Sobald das Training abgeschlossen ist, sollten Sie eine Ausgabe ähnlich der nachfolgenden erwarten. Ihre Zahlen sind nicht genau gleich. Das Training hängt von vielen Faktoren ab und liefert nicht immer identische Ergebnisse, aber sie sollten ähnlich aussehen.
Nächste Schritte
Nachdem wir nun über ein Klassifizierungsmodell verfügen, besteht der nächste Schritt darin, das Modell in das ONNX-Format zu konvertieren.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für