Solution ideas
This article is a solution idea. If you'd like us to expand the content with more information, such as potential use cases, alternative services, implementation considerations, or pricing guidance, let us know by providing GitHub feedback.
This article is an implementation guide and example scenario that provides a sample deployment of the solution that's described in Implement custom speech-to-text:
Architecture
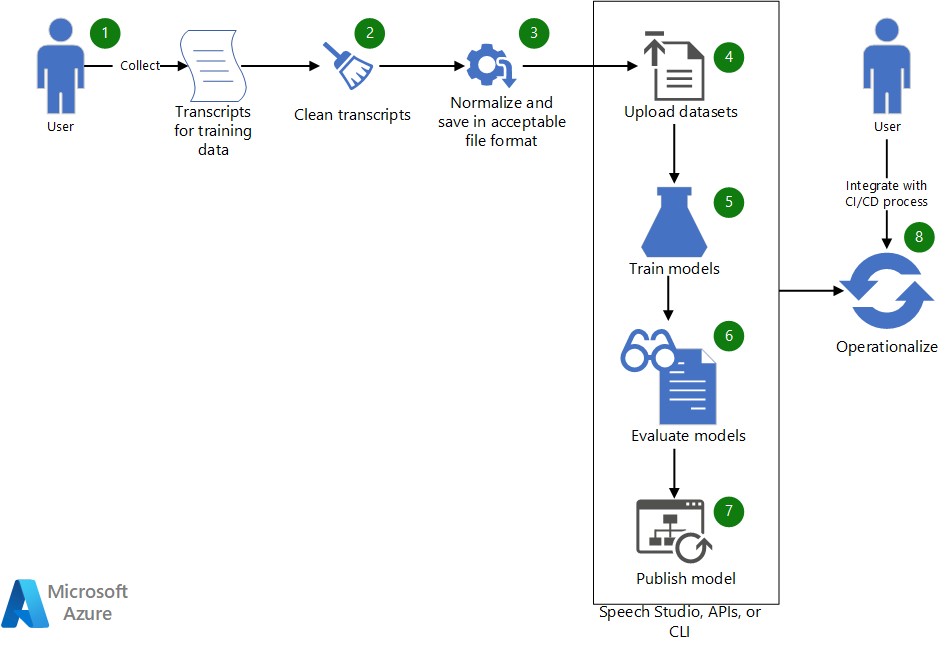
Download a Visio file of this architecture.
Workflow
- Collect existing transcripts to use to train a custom speech model.
- If the transcripts are in WebVTT or SRT format, clean the files so that they include only the text portions of the transcripts.
- Normalize the text by removing any punctuation, separating repeated words, and spelling out any large numerical values. You can combine multiple cleaned-up transcripts into one to create one dataset. Similarly, create a dataset for testing.
- After the datasets are ready, upload them by using Speech Studio. Alternatively, if the dataset is in a blob store, you can use Azure speech to text (STT) API and the Speech CLI. In the API and the CLI, you can pass the dataset's URI an input to create a dataset for model training and testing.
- In Speech Studio or via the API or CLI, use the new dataset to train a custom speech model.
- Evaluate the newly trained model against the test dataset.
- If the performance of the custom model meets your quality expectations, publish it for use in speech transcription. Otherwise, use Speech Studio to review the word error rate (WER) and specific error details and determine what additional data is needed for training.
- Use the APIs and CLI to help operationalize the model building, evaluation, and deployment process.
Components
- Azure Machine Learning is an enterprise-grade service for the end-to-end machine learning lifecycle.
- Azure AI services is a set of APIs, SDKs, and services that can help you make your applications more intelligent, engaging, and discoverable.
- Speech Studio is a set of UI-based tools for building and integrating features from Azure AI Speech service into your applications. Here, it's one alternative for training datasets. It's also used to review training results.
- Speech to text REST API is an API that you can use to upload your own data, test and train a custom model, compare accuracy between models, and deploy a model to a custom endpoint. You can also use it to operationalize your model creation, evaluation, and deployment.
- Speech CLI is a command-line tool for using Speech service without having to write any code. It provides another alternative for creating and training datasets and for operationalizing your processes.
Scenario details
This article is based on the following fictional scenario:
Contoso, Ltd., is a broadcast media company that airs broadcasts and commentary on Olympics events. As part of the broadcast agreement, Contoso provides event transcription for accessibility and data mining.
Contoso wants to use the Azure Speech service to provide live subtitling and audio transcription for Olympics events. Contoso employs female and male commentators from around the world who speak with diverse accents. In addition, each individual sport has specific terminology that can make transcription difficult. This article describes the application development process for this scenario: providing subtitles for an application that needs to deliver accurate event transcription.
Contoso already has these required prerequisite components in place:
- Human-generated transcripts for previous Olympics events. The transcripts represent commentaries from different sports and diverse commentators.
- An Azure Cognitive Service resource. You can create one on the Azure portal.
Develop a custom speech-based application
A speech-based application uses the Azure Speech SDK to connect to the Azure Speech service to generate text-based audio transcription. Speech service supports various languages and two fluency modes: conversational and dictation. To develop a custom speech-based application, you generally need to complete these steps:
- Use Speech Studio, Azure Speech SDK, Speech CLI, or the REST API to generate transcripts for spoken sentences and utterances.
- Compare the generated transcript with the human-generated transcript.
- If certain domain-specific words are transcribed incorrectly, consider creating a custom speech model for that specific domain.
- Review various options for creating custom models. Decide whether one or many custom models will work better.
- Collect training and testing data.
- Ensure the data is in an acceptable format.
- Train, test, and evaluate, and deploy the model.
- Use the custom model for transcription.
- Operationalize the model building, evaluation, and deployment process.
Let's look more closely at these steps:
1. Use Speech Studio, Azure Speech SDK, Speech CLI, or the REST API to generate transcripts for spoken sentences and utterances
Azure Speech provides SDKs, a CLI interface, and a REST API for generating transcripts from audio files or directly from microphone input. If the content is in an audio file, it needs to be in a supported format. In this scenario, Contoso has previous event recordings (audio and video) in .avi files. Contoso can use tools like FFmpeg to extract audio from the video files and save it in a format that's supported by the Azure Speech SDK, like .wav.
In the following code, the standard PCM audio codec, pcm_s16le, is used to extract audio in a single channel (mono) that has a sampling rate of 8 kilohertz (Khz).
ffmpeg.exe -i INPUT_FILE.avi -acodec pcm_s16le -ac 1 -ar 8000 OUTPUT_FILE.wav
2. Compare the generated transcript with the human-generated transcript
To perform the comparison, Contoso samples commentary audio from multiple sports and uses Speech Studio to compare the human-generated transcript with the results transcribed by Azure Speech service. The Contoso human-generated transcripts are in a WebVTT format. To use these transcripts, Contoso cleans them up and generates a simple .txt file that has normalized text without the timestamp information.
For information about using Speech Studio to create and evaluate a dataset, see Training and testing datasets.
Speech Studio provides a side-by-side comparison of the human-generated transcript and the transcripts produced from the models selected for comparison. Test results include a WER for the models, as shown here:
| Model | Error rate | Insertion | Substitution | Deletion |
|---|---|---|---|---|
| Model 1: 20211030 | 14.69% | 6 (2.84%) | 22 (10.43%) | 3 (1.42%) |
| Model 2: Olympics_Skiing_v6 | 6.16% | 3 (1.42%) | 8 (3.79%) | 2 (0.95%) |
For more information about WER, see Evaluate word error rate.
Based on these results, the custom model (Olympics_Skiing_v6) is better than the base model (20211030) for the dataset.
Note the Insertion and Deletion rates, which indicate that the audio file is relatively clean and has low background noise.
3. If certain domain-specific words are transcribed incorrectly, consider creating a custom speech model for that specific domain
Based on the results in the preceding table, for the base model, Model 1: 20211030, about 10 percent of the words are substituted. In Speech Studio, use the detailed comparison feature to identify domain-specific words that are missed. The following table shows one section of the comparison.
| Human-generated transcript | Model 1 | Model 2 |
|---|---|---|
| olympic champion to go back to back in the downhill since nineteen ninety eight the great katja seizinger of Germany what ninety four and ninety eight | olympic champion to go back to back in the downhill since nineteen ninety eight the great catch a sizing are of Germany what ninety four and ninety eight | olympic champion to go back to back in the downhill since nineteen ninety eight the great katja seizinger of Germany what ninety four and ninety eight |
| she has dethroned the olympic champion goggia | she has dethroned the olympic champion georgia | she has dethroned the olympic champion goggia |
Model 1 doesn't recognize domain-specific words like the names of the athletes "Katia Seizinger" and "Goggia." However, when the custom model is trained with data that includes the athletes' names and other domain-specific words and phrases, it's able to learn and recognize them.
4. Review various options for creating custom models. Decide whether one or many custom models will work better
By experimenting with various ways to build custom models, Contoso found that they could achieve better accuracy by using language and pronunciation model customization. (See the first article in this guide.) Contoso also noted minor improvements when they included acoustic (original audio) data for building the custom model. However, the benefits weren't significant enough to make it worth maintaining and training for a custom acoustic model.
Contoso found that creating separate custom language models for each sport (one model for alpine skiing, one model for luge, one model for snowboarding, and so on) provided better recognition results. They also noted that creating separate acoustic models based on the type of sport to augment the language models wasn't necessary.
5. Collect training and testing data
The Training and testing datasets article provides details about collecting the data needed for training a custom model. Contoso collected transcripts for various Olympics sports from diverse commentators and used language model adaptation to build one model per sport type. However, they used one pronunciation file for all custom models (one for each sport). Because the testing and training data are kept separate, after a custom model was built, Contoso used event audio whose transcripts weren't included in the training dataset for model evaluation.
6. Ensure the data is in an acceptable format
As described in Training and testing datasets, datasets that are used to create a custom model or to test the model need to be in a specific format. Contoso's data is in WebVTT files. They created some simple tools to produce text files that contain normalized text for language model adaptation.
7. Train, test and evaluate, and deploy the model
New event recordings are used to further test and evaluate the trained model. It can take a couple of iterations of testing and evaluation to fine-tune a model. Finally, when the model generates transcripts that have acceptable error rates, it's deployed (published) to be consumed from the SDK.
8. Use the custom model for transcription
After the custom model is deployed, you can use the following C# code to use the model in the SDK for transcription:
String endpoint = "Endpoint ID from Speech Studio";
string locale = "en-US";
SpeechConfig config = SpeechConfig.FromSubscription(subscriptionKey: speechKey, region: region);
SourceLanguageConfig sourceLanguageConfig = SourceLanguageConfig.FromLanguage(locale, endPoint);
recognizer = new SpeechRecognizer(config, sourceLanguageConfig, audioInput);
Notes about the code:
endpointis the endpoint ID of the custom model that's deployed in step 7.subscriptionKeyandregionare the Azure AI services subscription key and region. You can get these values from the Azure portal by going to the resource group where the Azure AI services resource was created and looking at its keys.
9. Operationalize the model building, evaluation, and deployment process
After the custom model is published, it needs to be evaluated regularly and updated if new vocabulary is added. Your business might evolve, and you might need more custom models to increase coverage for more domains. The Azure Speech team also releases new base models, which are trained on more data, as they become available. Automation can help you keep up with these changes. The next section of this article provides more details about automating the preceding steps.
Deploy this scenario
For information about how to use scripting to streamline and automate the entire process of creating datasets for training and testing, building and evaluating models, and publishing new models as needed, see Custom-speech-STT on GitHub.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Pratyush Mishra | Principal Engineering Manager
Other contributors:
- Mick Alberts | Technical Writer
- Rania Bayoumy | Senior Technical Program Manager
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
- What is Custom Speech?
- What is text to speech?
- Train a Custom Speech model
- Implement custom speech to text
- Azure/custom-speech-STT on GitHub