Event-driven scaling in Azure Functions
In the Consumption and Premium plans, Azure Functions scales CPU and memory resources by adding more instances of the Functions host. The number of instances is determined on the number of events that trigger a function.
Each instance of the Functions host in the Consumption plan is limited, typically to 1.5 GB of memory and one CPU. An instance of the host is the entire function app, meaning all functions within a function app share resource within an instance and scale at the same time. Function apps that share the same Consumption plan scale independently. In the Premium plan, the plan size determines the available memory and CPU for all apps in that plan on that instance.
Function code files are stored on Azure Files shares on the function's main storage account. When you delete the main storage account of the function app, the function code files are deleted and can't be recovered.
Runtime scaling
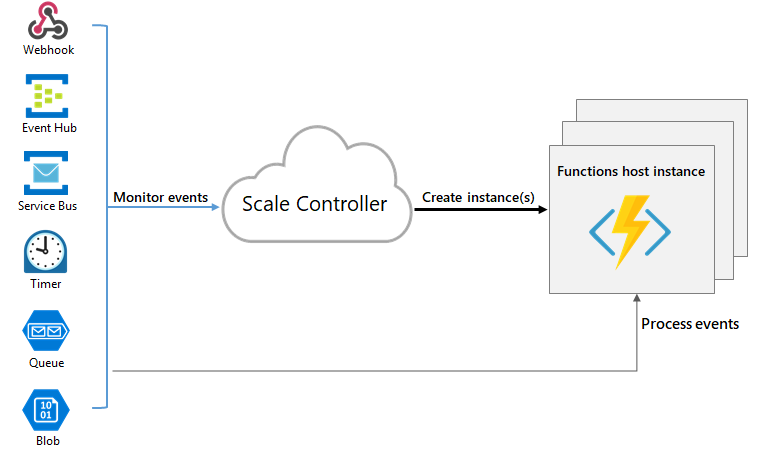
Azure Functions uses a component called the scale controller to monitor the rate of events and determine whether to scale out or scale in. The scale controller uses heuristics for each trigger type. For example, when you're using an Azure Queue storage trigger, it uses target-based scaling.
The unit of scale for Azure Functions is the function app. When the function app is scaled out, more resources are allocated to run multiple instances of the Azure Functions host. Conversely, as compute demand is reduced, the scale controller removes function host instances. The number of instances is eventually "scaled in" when no functions are running within a function app.
Cold Start
After your function app has been idle for a number of minutes, the platform may scale the number of instances on which your app runs down to zero. The next request has the added latency of scaling from zero to one. This latency is referred to as a cold start. The number of dependencies required by your function app can affect the cold start time. Cold start is more of an issue for synchronous operations, such as HTTP triggers that must return a response. If cold starts are impacting your functions, consider running in a Premium plan or in a Dedicated plan with the Always on setting enabled.
Understanding scaling behaviors
Scaling can vary based on several factors, and apps scale differently based on the triggers and language selected. There are a few intricacies of scaling behaviors to be aware of:
- Maximum instances: A single function app only scales out to a maximum allowed by the plan. A single instance may process more than one message or request at a time though, so there isn't a set limit on number of concurrent executions. You can specify a lower maximum to throttle scale as required.
- New instance rate: For HTTP triggers, new instances are allocated, at most, once per second. For non-HTTP triggers, new instances are allocated, at most, once every 30 seconds. Scaling is faster when running in a Premium plan.
- Target-based scaling: Target-based scaling provides a fast and intuitive scaling model for customers and is currently supported for Service Bus Queues and Topics, Storage Queues, Event Hubs, and Cosmos DB extensions. Make sure to review target-based scaling to understand their scaling behavior.
Limit scale-out
You may wish to restrict the maximum number of instances an app used to scale out. This is most common for cases where a downstream component like a database has limited throughput. By default, Consumption plan functions scale out to as many as 200 instances, and Premium plan functions will scale out to as many as 100 instances. You can specify a lower maximum for a specific app by modifying the functionAppScaleLimit value. The functionAppScaleLimit can be set to 0 or null for unrestricted, or a valid value between 1 and the app maximum.
az resource update --resource-type Microsoft.Web/sites -g <RESOURCE_GROUP> -n <FUNCTION_APP-NAME>/config/web --set properties.functionAppScaleLimit=<SCALE_LIMIT>
Scale-in behaviors
Event-driven scaling automatically reduces capacity when demand for your functions is reduced. It does this by draining instances of their current function executions and then removes those instances. This behavior is logged as drain mode. The grace period for functions that are currently executing can extend up to 10 minutes for Consumption plan apps and up to 60 minutes for Premium plan apps. Event-driven scaling and this behavior don't apply to Dedicated plan apps.
The following considerations apply for scale-in behaviors:
- For Consumption plan function apps running on Windows, only apps created after May 2021 have drain mode behaviors enabled by default.
- To enable graceful shutdown for functions using the Service Bus trigger, use version 4.2.0 or a later version of the Service Bus Extension.
Best practices and patterns for scalable apps
There are many aspects of a function app that impacts how it scales, including host configuration, runtime footprint, and resource efficiency. For more information, see the scalability section of the performance considerations article. You should also be aware of how connections behave as your function app scales. For more information, see How to manage connections in Azure Functions.
For more information on scaling in Python and Node.js, see Azure Functions Python developer guide - Scaling and concurrency and Azure Functions Node.js developer guide - Scaling and concurrency.
Billing model
Billing for the different plans is described in detail on the Azure Functions pricing page. Usage is aggregated at the function app level and counts only the time that function code is executed. The following are units for billing:
- Resource consumption in gigabyte-seconds (GB-s). Computed as a combination of memory size and execution time for all functions within a function app.
- Executions. Counted each time a function is executed in response to an event trigger.
Useful queries and information on how to understand your consumption bill can be found on the billing FAQ.
Next steps
To learn more, see the following articles:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for