Hyper-V Virtual Switch Performance - Dynamic VMQ
After working in the hypervisor team for few years, during Windows 8 time frame, I decided to move back to networking as a lead, to lead the increased investments in networking. We built a lot of features such as SR-IOV support, Dynamic VMQ, Extensible Virtual Switch etc.
In this post I would talk about a feature we built called dynamic VMQ, a feature designed to provide optimal processor utilization across changing workload that was not possible with static processor allocation for VMQ as done in Windows 7 (or Windows Server 2008 R2 release). However, before we dig deeper into dynamic VMQ, let me recap the processor utilization for no VMQ and static VMQ cases.
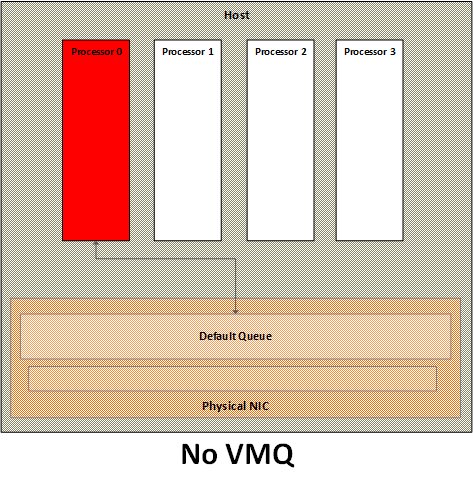
No VMQ
With no VMQ, all networking packets gets processed on a single processor, resulting in a single processor becoming the bottleneck for the overall network throughput.
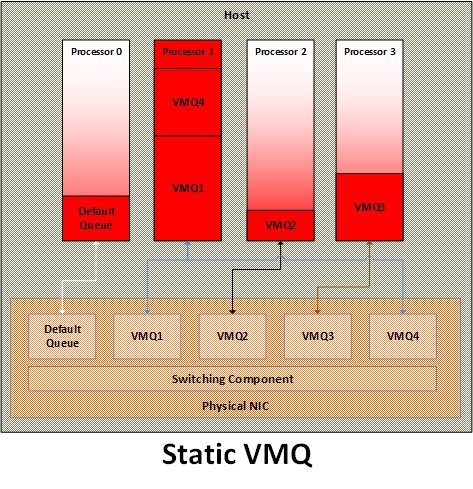
Static VMQ
With static VMQ, queues for different VMs gets affinitized to processors in a round-robin fashion. This happens during VM startup and stays until the VM is restarted. If this assignment is not optimal as in either multiple network heavy VMQs are affinitized to the same processor (either permanently or due to changing workload) or multiple smaller VMQs are affinitized to different processors, it results in either processor bottleneck and reduced throughput or extraneous processor utilization and power consumption.
Dynamic VMQ
The basic premise of dynamic VMQ was to use as many processors as needed for network packet processing. Under low network throughput, fewer processors are used, thus resulting in lower power consumption. As power is one of the major cost contributor to the data center, this helps reduce the overall power footprint of the data center. Under high network throughput, more processors are used, thus allowing best utilization of the processing power of the data center and meet the needs of most demanding workloads.
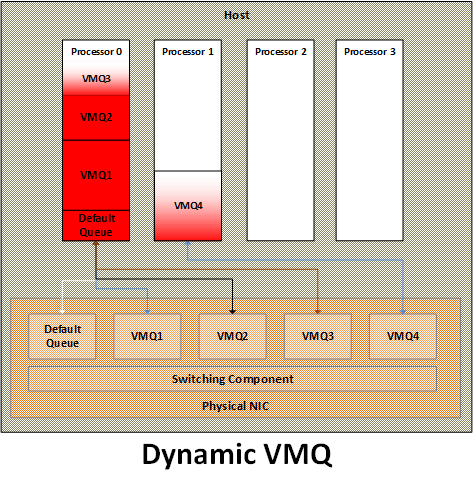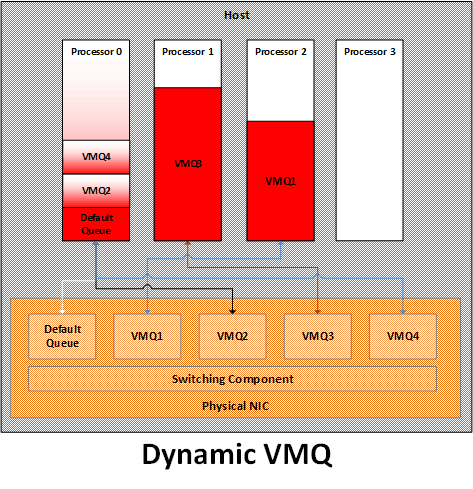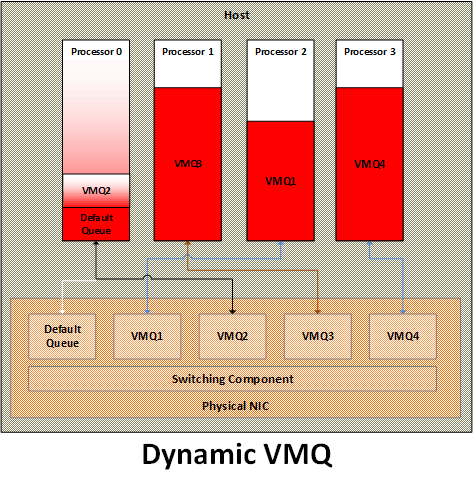
The key requirement to support dynamic VMQ from NICs is to allow dynamic change in VMQ to processor affinity. A NIC driver can advertise support for dynamic affinity during its initialization and VMSWITCH can leverage that to optimize the processor utilization.
VMSWITCH uses a set of data and heuristics to determine the optimal VMQ to processor affinity. It tracks the overall processor utilization of each processor. It also calculates the total time spent in network processing for each VMQ as well as the total number of network packets processed for each VMQ.
Using these numbers, VMSWITCH detects, whether a processor has exceeded its threshold capacity or not. If the processor has exceeded the threshold capacity, it is treated as bottleneck and a VMQ spreading selection algorithm is run to see if there is a candidate VMQ to move "away" from the processor. If a candidate VMQ is found, another selection algorithm is run to find the candidate destination processor. A successful selection results in target VMQ moving to destination processor.
Conversely, if a processor is associated with a VMQ and the processor usage goes below a minimum threshold, a coalescing algorithm runs to coalesce the VMQs to fewer processors. This results in using more processors when the network processing demand is high and fewer processors usage when the demand is low.
Please do note that, even though dynamic VMQ allows a more optimal usage of multiple processors in the system and fixes the problems with static VMQ, a single VMQ is still limited to a single processor. In Windows server 2012 R2, we have built a feature called virtual RSS to allow a single VMQ to use more than one processor thus allowing a single VM to achieve much higher throughput.
Ping Pong Problem
One problem we encountered with the dynamic VMQ was the ping pong effect. Under certain conditions, the processor and VMQ usage resulted in a situation, where one VMQ would continuously move from one processor to another. This happened mainly when the VMQ move resulted in the destination processor becoming the bottleneck and source processor becoming a good candidate for moving a VMQ. The VMQ would jump back and forth between source and destination processor. In the performance analysis, this turned out to not be a deal breaker as the effect of change in VMQ processor affinity was minimal. However, in Windows Server 2012 R2, with the work on virtual RSS, a temporal affinity using credit based system was added to take care of this problem.
Summary
In this post I described dynamic VMQ, how it works to provide optimal processor utilization under dynamic workload. In a future post, I would describe virtual RSS, how it solves the single processor bottleneck for each VMQ and allows a single VM to achieve more than 30Gbps throughput. In that post, I would also describe the fix for the ping pong problem mentioned above.