Narrow plan和Wide plan
Narrow plan和Wide plan
早些时间team里面的Simon同学碰到一个很有意思的有关UPDATE 语句性能的案例。他的客户跟他说,在SQL server 系统上,客户发现UPDATE的语句性能不够稳定。在SQL profiler trace 里面客户发现UPDATE语句大部分时间执行的都很快,但有时执行的比较慢,不知道是怎么回事呢。
检查语句性能少不了查看语句的执行计划。客户在他的profiler trace里面捕捉了语句的执行计划然后发了给Simon。在trace里面,UPDATE语句非常的简单:
UPDATEtablexxxSETcol1= xxx WHEREc1=@p1
然而,就是这么简单的语句,它的执行计划却是很不一样:

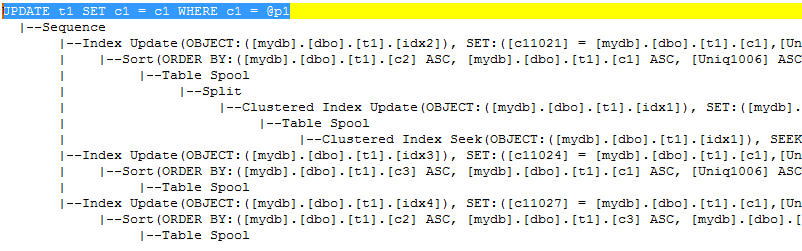
一开始我有些诧异,为什么执行计划相差这么大呢?我把客户的table 的schema要了过来,在自己的SQL server 上设法重现了这个问题,终于找到了问题的答案。 原来问题和narrow plan 和wide plan 有关系。
那么narrow plan 和wide plan 究竟是怎么回事呢?
Narrow plan 又叫per-row plan。Wide plan 又叫per-index plan 。narrow plan 和wide plan 代表SQL server的 不同的数据更新的执行计划。narrow plan是指SQL server 在做更新(比如insert/delete/update)的时候, SQL server不依赖optimizer,而是依赖存储引擎对相应的index做简单的地逐行更新。一般而言,当需要update的行数较少的时候,就会使用narrow plan。但是narrow plan的不好的地方就是,因为是逐行更新,所以需要定位每一行,这样如果页面如果不在内存里面,就需要读取磁盘,那么磁盘会比较忙,影响磁盘的性能。而wide plan,就是optimizer自己生成所有index更新执行计划,不依赖存储引擎。这样做的好处就是它可以生成一个对index 批量更新的较好的方法,而不是依赖存储引擎逐行更新的方式。
我们来看一个简单的例子(数据库版本:SQL server 2012):
usetempdb
go
--如果表mytable已经存在则drop掉
ifexists(selectnamefromsys.tableswherename='mytable')
droptablemytable
go
--创建表
createtablemytable(c1int,c2int,c3varchar(20),c4datetime)
go
setnocounton
begintran
declare@iint
set@i=0
while(@i<100000)
begin
--产生c1在1-100内的行
if(@i<100)insertintomytablevalues(@i,@i%100,'sdfd',getdate()+@i)
else
--产生c1比100大的行,
insertintomytablevalues(100+@i%100,@i%1000,'sdfd',getdate()+@i)
set@i=@i+1
if(@i%1000=0)beginif (@@TRANCOUNT>0)committran;begintran;end
end
if(@@TRANCOUNT>0)committran
--看看c1值的分布情况
selectcount(*)ascount,c1frommytablegroupbyc1orderbycount(1)desc
go
--建立多个索引
createclusteredindexcidxonmytable(c1)
createindexidx1onmytable(c2)
createindexidx2onmytable(c3)
createindexidx3onmytable(c4)
createindexidx4onmytable(c2,c3)
--如果运行这句,那么会返回一行:
--select * from mytable where c1=1
--传入p=1,应该只update 一行,因为c1=1的只有一行,它的执行计划是narrow plan
setstatisticsprofileon
declare@pint
set@p=1
updatemytablesetc1=c1wherec1=@pOPTION (RECOMPILE);
setstatisticsprofileoff
执行计划如下:

上面的执行计划就是narrow plan。它使用了一个table spool,然后逐行对index 进行更新。而我们知道,更新clustered index的时候, nonclustered index也需要更新的(想想为什么?),但是为什么上面的执行计划没有显示出来,因为SQL server 依赖存储引擎对这些nonclustered index 自动进行了更新。其实如果你查看它的xml计划,是可以看到这些更新的:
setstatisticsxmlon
declare@pint
set@p=1
updatemytablesetc1=c1wherec1=@pOPTION (RECOMPILE);
setstatisticsxmloff

--传入p=100,应该update 多行,它的执行计划是wide plan
setstatisticsprofileon
declare@pint
set@p=100
updatemytablesetc1=c1wherec1=@pOPTION (RECOMPILE);
setstatisticsprofileoff
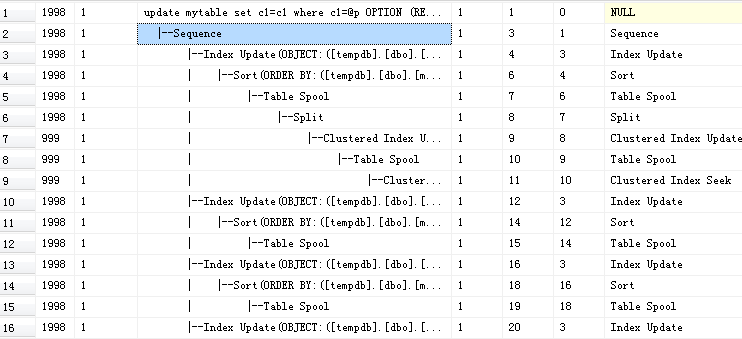
你可以看到,上面的执行计划包括了每个index的update,而且都使用了table spool,使得可以对index进行批量的更新。这些是optimizer生成的执行计划,不再依赖储存引擎更新index。
回到客户的问题。为什么update有时候会变慢呢?原来,大部分的update语句只update 少数的几行,比较快,而有时会update大量的行,这时候使用了wide plan,性能就变慢了。
你可能会问,如果强制SQL server 使用narrow plan,会不会更快呢? 答案是不确定的。我们可以测试一下。Trace flag 2338告诉SQL server 尽量使用 narrow plan,而8790则要求wide plan:
--测试不同的plan,对于@p=1的情况
setstatisticsprofileon
setstatisticsioon
setstatisticstimeon
go
declare@pint
set@p=1
updatemytablesetc1=c1wherec1=@pOPTION (RECOMPILE);
--
dbcctraceon(8790)--force wide plan
updatemytablesetc1=c1wherec1=@pOPTION (RECOMPILE);
dbcctraceoff(8790)
go
setstatisticsiooff
setstatisticstimeoff
setstatisticsprofileoff
--测试不同的plan,对于@p=100的情况
setstatisticsprofileon
setstatisticsioon
setstatisticstimeon
go
declare@pint
set@p=100
dbcctraceon(2338)--force narrow plan
updatemytablesetc1=c1wherec1=@pOPTION (RECOMPILE);
dbcctraceoff(2338)
updatemytablesetc1=c1wherec1=@pOPTION (RECOMPILE);
go
setstatisticsiooff
setstatisticstimeoff
setstatisticsprofileoff
然而最后,Simon发现,结果相差不是很大。这大概是因为数据量可能不够大的缘故。