SQL Server上的一个奇怪的Deadlock及其分析方法
最近遇到了一个看上去很奇怪,分析起来很有意思的死锁问题。这个死锁看上去难以理解。而分析过程中,又使用了很多分析SQL Server死锁的典型方法。记录下来整个分析过程还是很有意义的。
问题重现步骤:
经过提炼,问题重现的步骤非常简单,在SQL 2008上可以很容易地重现。
1. 首先,创建一张表格,上面有一个clustered index,两个non-clustered index。
create table tt(id int identity primary key,a char(36),b char(36),d varchar(max))
go
create index ix_a_bc on tt(a)include(d)
create index ix_b_cd on tt(b)include(d)
2. 向这个表格里插入10000条记录。
insert into tt select NEWID(),'bbb','ddd'
go 10000
3. 查询某一条记录,找到它的a字段的值。(这里以第十条为例)
select * from tt where id = 10
假设我们得到a字段的值是’EF211985-EA72-4A40-81DA-0AAB076E7AA3’。(这是一个随机值,每次测试会不一样。)
4. 现在按照这个值,对表格进行反复更新。如果两个连接同时运行,死锁就一定会发生。(测试1)
while 1 =1
update tt with(rowlock) set d='cd'
where a='EF211985-EA72-4A40-81DA-0AAB076E7AA3'

5. 但是如果把两个non-clustered index里的include (d)去掉,然后运行同样的update语句循环,死锁就不会发生。(测试2)
drop index ix_a_bc on tt
drop index ix_b_cd on tt
create index ix_a_bc on tt(a)include(d)
create index ix_b_cd on tt(b)include(d)
6. 或者把d字段的字段类型,从varchar(max)改成varchar(200),死锁也不会发生。(测试3)
drop index ix_a_bc on tt
drop index ix_b_cd on tt
alter table tt alter column d varchar(200)
create index ix_a_bc on tt(a)include(d)
create index ix_b_cd on tt(b)include(d)
问题分析步骤
为什么两条一模一样的update语句,会相互死锁呢?为什么索引上去掉一个include选项,或者改掉一个数据类型,就不会死锁了呢?要回答这个问题,还是要先仔细分析一下,死锁是如何发生的。
了解SQL Server里死锁发生的直接原因,有两种办法:(1) 收集SQL Trace。(2) 开启1222开关。因为问题可以稳定地在测试环境里重现,我们可以尽可能多地收集信息,把两种方法都用上。
首先我们用下面的脚本打开1222开关。
dbcc traceon (1222, -1)
然后,在运行update语句的连接里,运行下面的脚本,了解连接的SPID。后面我们可以用来做SQL Trace的filter。
select @@spid
假设我们得到的结果,一个是54,一个是60。
现在我们开启SQL Profiler,连到SQL Server上,新建一个Trace,在选择事件的时候,先勾上”Show all events”、”Show all columns”,然后选上Locks下面的这些events。
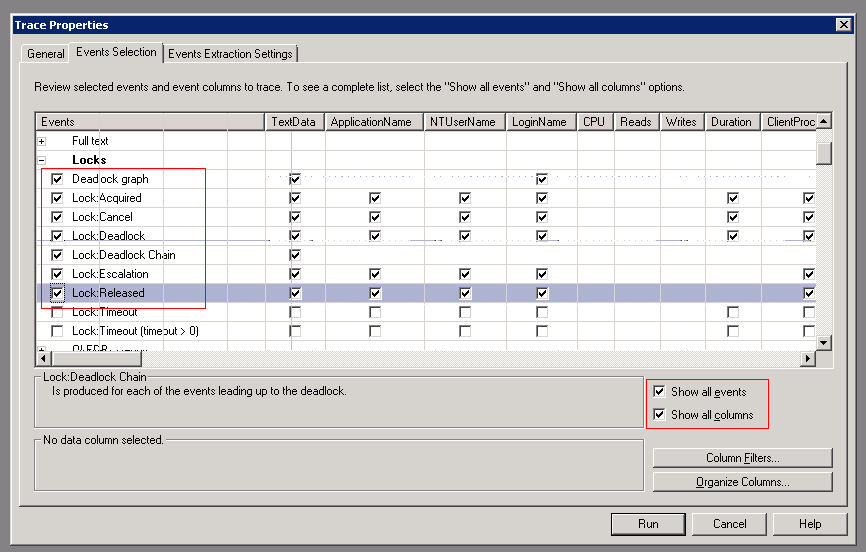
在TSQL下面,选上这些events。
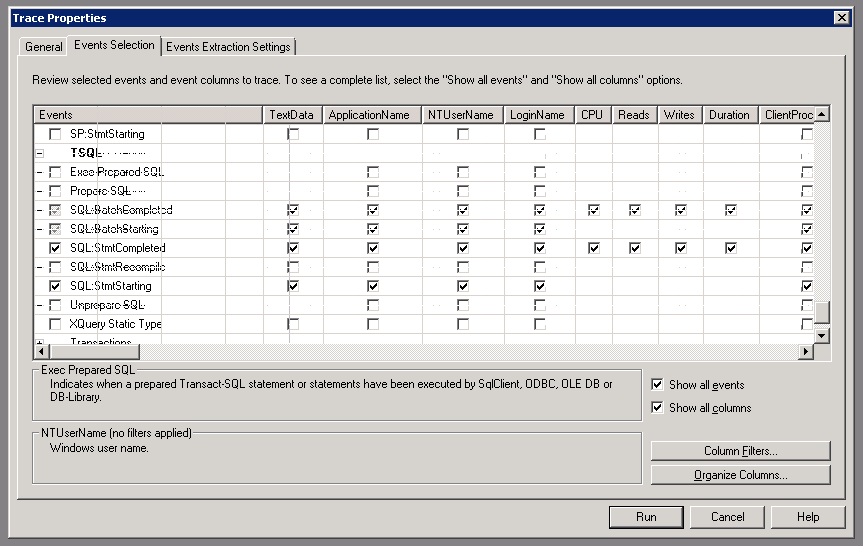
点击Column Filters,在SPID上设置只跟踪SPID为54,60,6和20的连接。
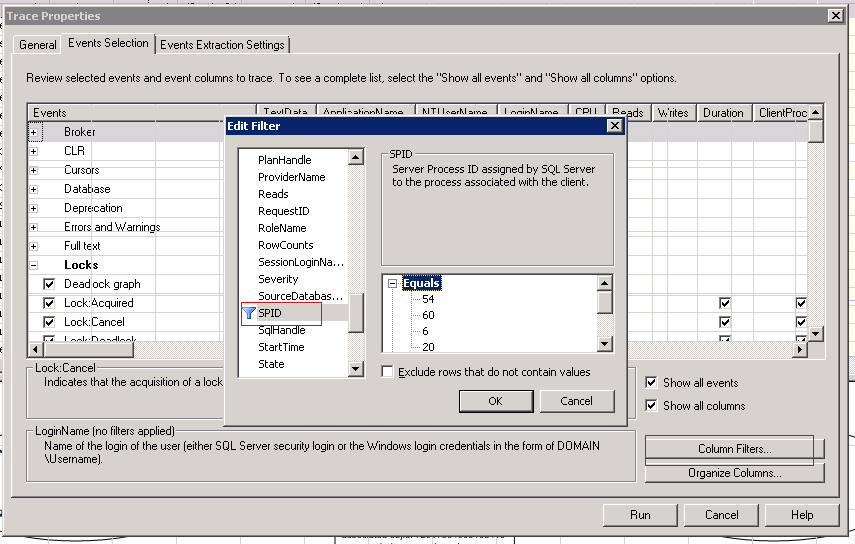
然后运行两个连接里的update循环,让问题发生。
随后,我们运行sp_readerrorlog指令。可以在SQL errorlog里发现下面的,关于上次死锁的记录。记录比较长,关键的地方我用黄色背景标出。
deadlock-list
deadlock victim=process5e27708
process-list
process id=process5e27708 taskpriority=0 logused=0 waitresource=KEY: 8:72057594066108416 (ef8a9edf5a1e) waittime=1750 ownerId=11864845 transactionname=UPDATE lasttranstarted=2011-12-01T16:41:39.540 XDES=0xca9a7950 lockMode=X schedulerid=4 kpid=6380 status=suspended spid=60 sbid=0 ecid=0 priority=0 trancount=2 lastbatchstarted=2011-12-01T16:41:39.407 lastbatchcompleted=2011-12-01T16:37:13.077 lastattention=2011-12-01T16:20:33.170 clientapp=Microsoft SQL Server Management Studio - Query hostname=AOBAI hostpid=4672 loginname=FAREAST\haiwxu isolationlevel=read committed (2) xactid=11864845 currentdb=8 lockTimeout=4294967295 clientoption1=671090784 clientoption2=390200
executionStack
frame procname=adhoc line=2 stmtstart=24 stmtend=188 sqlhandle=0x020000001cf53c334179280da1f74e588b7179146497bde9
8000),@2 varchar(8000))UPDATE [tt] WITH(rowlock) set [d] = @1 WHERE [a]=@2
frame procname=adhoc line=2 stmtstart=24 stmtend=188 sqlhandle=0x02000000a1ec593be12cd271e013ded3a22a397943e8f879
update tt with(rowlock) set d='cd'
where a='EF211985-EA72-4A40-81DA-0AAB076E7AA3
inputbuf
while 1 =1
update tt with(rowlock) set d='cd'
where a='EF211985-EA72-4A40-81DA-0AAB076E7AA3'
process id=process5e09dc8 taskpriority=0 logused=0 waitresource=KEY: 8:72057594065518592 (d08358b1108f) waittime=1750 ownerId=11864847 transactionname=UPDATE lasttranstarted=2011-12-01T16:41:39.540 XDES=0xcb98d3c0 lockMode=U schedulerid=1 kpid=4200 status=suspended spid=54 sbid=0 ecid=0 priority=0 trancount=2 lastbatchstarted=2011-12-01T16:41:37.473 lastbatchcompleted=2011-12-01T16:37:19.577 lastattention=2011-12-01T16:37:19.577 clientapp=Microsoft SQL Server Management Studio - Query hostname=AOBAI hostpid=4672 loginname=FAREAST\haiwxu isolationlevel=read committed (2) xactid=11864847 currentdb=8 lockTimeout=4294967295 clientoption1=671090784 clientoption2=390200
executionStack
frame procname=adhoc line=2 stmtstart=24 stmtend=188 sqlhandle=0x020000001cf53c334179280da1f74e588b7179146497bde9
8000),@2 varchar(8000))UPDATE [tt] WITH(rowlock) set [d] = @1 WHERE [a]=@2
frame procname=adhoc line=2 stmtstart=24 stmtend=188 sqlhandle=0x02000000a1ec593be12cd271e013ded3a22a397943e8f879
update tt with(rowlock) set d='cd'
where a='EF211985-EA72-4A40-81DA-0AAB076E7AA3
inputbuf
while 1 =1
update tt with(rowlock) set d='cd'
where a='EF211985-EA72-4A40-81DA-0AAB076E7AA3'
resource-list
keylock hobtid=72057594066108416 dbid=8 objectname=PerfAnalysis.dbo.tt indexname=ix_a_bc id=lock5e66c00 mode=U associatedObjectId=72057594066108416
owner-list
owner id=process5e09dc8 mode=U
waiter-list
waiter id=process5e27708 mode=X requestType=wait
keylock hobtid=72057594065518592 dbid=8 objectname=PerfAnalysis.dbo.tt indexname=PK__tt__3213E83F10E07F16 id=lock6648e80 mode=X associatedObjectId=72057594065518592
owner-list
owner id=process5e27708 mode=X
waiter-list
waiter id=process5e09dc8 mode=U requestType=wait
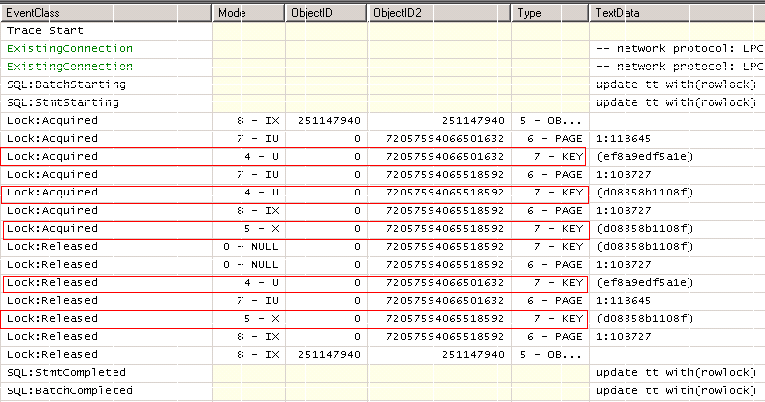
从executionStack里可以看到,死锁的确是发生在两条update语句上。连接1(spid=54,process id=process5e09dc8),另外一个连接2(spid=60,process id=process5e27708)。
分析resource-list的内容,可以知道死锁发生的直接原因,是连接1在ix_a_bc索引上持有一个U-key锁,要申请索引PK__tt__3213E83F10E07F16上的U-key锁。而连接2在PK__tt__3213E83F10E07F16上有一个X锁,要在ix_a_bc索引上申请一个X锁。(SQL Trace里的Deadlock Graph事件也能告诉你类似的信息。不过1222的输出可能更全面一些。)
为什么会有这种情况发生呢?1222的输出已经不能告诉我们更多的信息了。我们需要分析SQL Trace里的锁申请和释放记录,来了解当时究竟发生了些什么。
我们先看一次成功地update,SQL Server是怎么申请和释放锁资源的。Lock:Acquired和Lock:Released这两个event能够告诉我们。不过这两个event的输出比较难读,需要把字段Mode, ObjectID, ObjectID2和Type拖到前面来看。
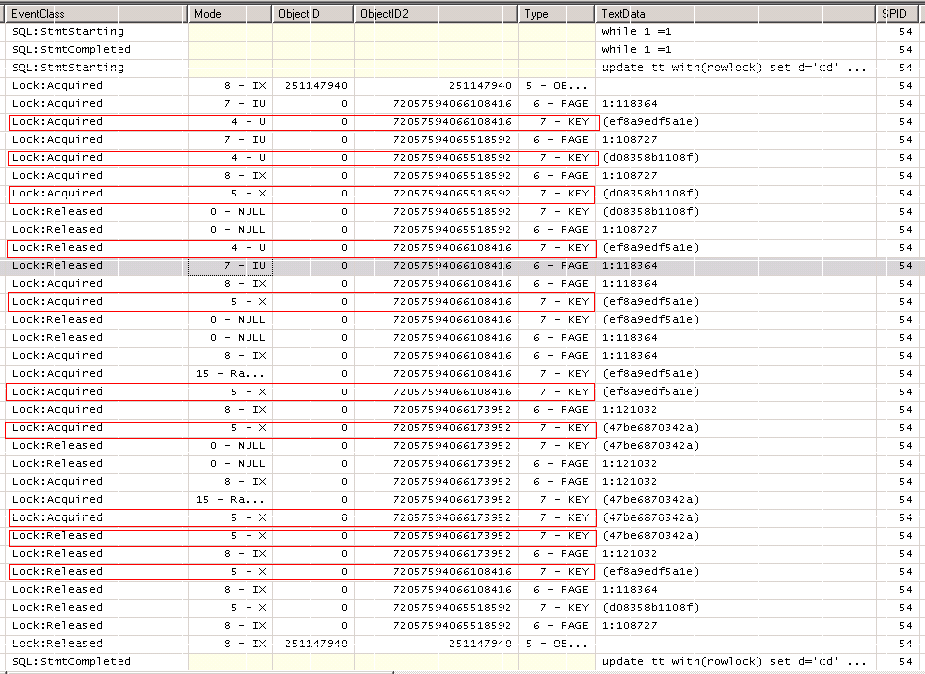
ObjectID2字段里的值,也就是1222输出里的hobtid。具体的值和表格、索引名字的对照关系,可以用下面的脚本检查。
select o.name ,i.name ,i.type from
sys.indexes i inner join sys.objects o on i.object_id = o.object_id
inner join sys.partitions p on p.index_id = i.index_id and p.object_id = i.object_id
where p.partition_id = 72057594065518592
-- 72057594065518592就是其中的一个ObjectID2值。
通过上面这个脚本,我们可以知道出现在SQL Trace里的ObjectID2和实际的索引之间的对应关系:
72057594065518592:PK__tt__3213E83F10E07F16
72057594066108416:ix_a_bc
72057594066173952: ix_b_cd
所以SQL Server在Key级别加锁、放锁的顺序是:
索引名 |
锁类型 |
申请/释放 |
阶段 |
连接1(SPID 54) |
连接2(SPID 60) |
ix_a_bc |
U |
申请 |
1 |
J |
J |
PK__tt__3213E83F10E07F16 |
U |
申请 |
1 |
L |
J |
PK__tt__3213E83F10E07F16 |
X |
申请 |
1 |
|
J |
ix_a_bc |
U |
释放 |
1 |
|
J |
ix_a_bc |
X |
申请 |
2 |
|
L |
ix_b_cd |
X |
申请 |
2 |
|
|
ix_b_cd |
X |
释放 |
2 |
|
|
ix_a_bc |
X |
释放 |
2 |
|
|
PK__tt__3213E83F10E07F16 |
X |
释放 |
2 |
|
|
从上图可以看出,Update语句似乎是分两步执行。第一步SQL先通过索引ix_a_bc找到了记录本身(PK__tt__3213E83F10E07F16),将其更新。第二步SQL Server又更新了两个non-clustered index上的数据,因为这两个索引有include了发生修改的d字段。最后,把三个X锁释放掉。前面那个死锁的例子,连接1正运行到第一步,而连接2运行到了第二步。由于连接2在完成第一步以后把ix_a_bc上的U锁释放掉了,使得连接1能够开始其第一步的运行,申请到了ix_a_bc上的U锁。而连接2马上又要申请ix_a_bc上的X锁,两边就相互阻塞住,死锁就这样发生了。
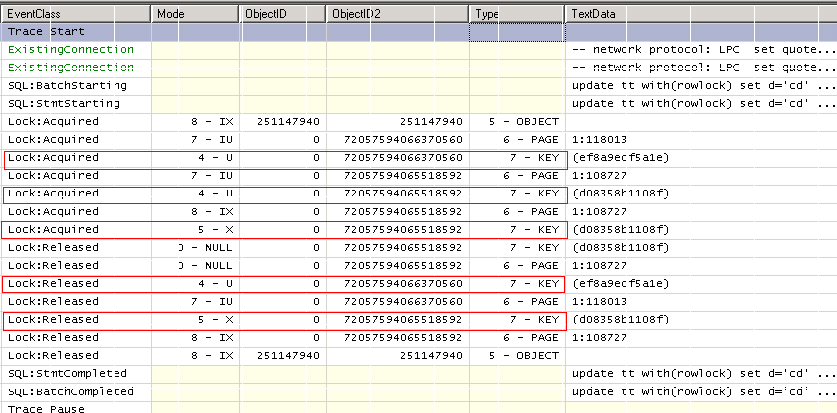
为什么把non-clustered index上的include字段去掉,能够解决死锁问题呢(测试2)?我们再用SQL Trace,跟踪一下数据类型修改以后的Update的执行过程。信息的收集和分析方法跟前面的一样。
索引名 |
锁类型 |
申请/释放 |
ix_a_bc |
U |
申请 |
PK__tt__3213E83F10E07F16 |
U |
申请 |
PK__tt__3213E83F10E07F16 |
X |
申请 |
ix_a_bc |
U |
释放 |
PK__tt__3213E83F10E07F16 |
X |
释放 |
如果把d字段的数据类型从varchar(max)改成varchar(200)会怎么样呢(测试3)?用同样的方法跟踪。
索引名 |
锁类型 |
申请/释放 |
ix_a_bc |
U |
申请 |
PK__tt__3213E83F10E07F16 |
U |
申请 |
PK__tt__3213E83F10E07F16 |
X |
申请 |
ix_a_bc |
U |
释放 |
PK__tt__3213E83F10E07F16 |
X |
释放 |
我们可以看到,不管用那一种方法,Update都从两步简化成了一步。SQL Server只需通过索引ix_a_bc找到了记录本身(PK__tt__3213E83F10E07F16),将其更新。第二步就不需要做了。这样,死锁就不会发生。
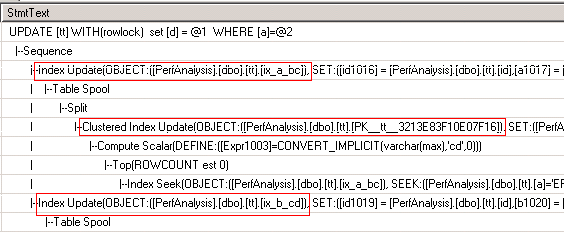
那么为什么会有这种变化呢?要理解SQL Server加锁放锁的行为,我们必须分析语句的执行计划。这里,我用在update语句前加”set statistics profile on”的方法,得到一个文字型输出的执行计划。
set statistics profile on
go
update tt with(rowlock) set d='cd'
where a='EF211985-EA72-4A40-81DA-0AAB076E7AA3'
测试1:(d varchar(max), 在索引里included, 有死锁)
测试2:(d varchar(max), 在索引里没有included, 没有死锁)
测试3:(d varchar(200), 在索引里有included, 没有死锁)
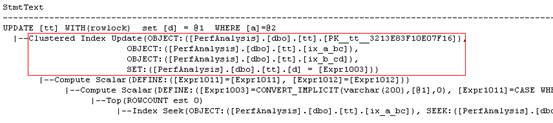
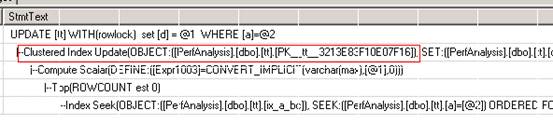{kind=link}
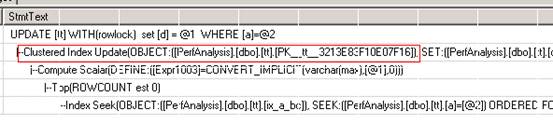
这三个执行计划很能说明问题。第一个执行计划里,有三个Index Update。这也就说明了SQL为什么要申请3个X锁。第二个执行计划里,只有一个Index Update。这是因为d字段没有被两个non-clustered index所包含,SQL Server只需要更新clustered index即可。第三个执行计划非常有趣。它只有一次update,但是包含了三个Object。也就是说,SQL一步就把三个index一起更新掉了。所以测试三也是一步做完的,不会有死锁。
分析到这里,问题基本已经比较清楚。我们可以得出以下结论:
1. SQL Server的加锁数量、以及顺序,跟语句的执行计划有关系。
2. 表格上的索引越多、数据类型越复杂,执行计划也会越复杂,从而导致遇到阻塞或者死锁的几率增加。
3. 消除死锁,可以先检查语句的执行计划,从调整执行计划入手,引导SQL Server申请比较少的锁。
对于这个死锁案例本身,将varchar(max)包含在一个索引里,是不太妥当的。这样会大大增加索引的复杂度,也增加了SQL Server的维护成本。解决这个索引的比较好的方法,是将字段d从索引里移除,或者把它改成一个有合适长度限制的varchar类型。