Azure HDInsight: How to run Presto in one simple step and query across data sources such as Cosmos DB, SQL DB & Hive
I have seen in past few months many inquiries on how to run Presto in HDInsight In this post we have provided an easy way for you to install Presto in HDInsight as well as configure various data sources which Presto can query.
One of the unique advantages of HDInsight is decoupling between storage and Big Data processing engines. You can use number of different engines such as Hive, Pig, Spark, Presto, LLAP (Interactive Hive) and get insights from your big data without any data migration.
What is Presto?
Presto is a distributed SQL query engine optimized for ad-hoc analysis at interactive speed. It supports standard ANSI SQL, including complex queries, aggregations, joins, and window functions. Presto is becoming popular SQL interactive query engine that has grabbed the attention and mind-share in Big data communities.
What are the key advantages of Presto?
1- It's very fast - Presto was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses.
2- Presto can query data where it lives - Presto supports many data sources via the number of connectors that community has built. You can query HDFS , Hive, Azure Storage or data stored in SQL Server , My SQL , CosmosDB or Cassandra etc.
You can install Presto in one simple step with HDInsight Script Action feature
Run the Presto Script on Head Node and Worker Nodes of your HDInsight 3.6 Hadoop cluster. You will need at least 4 worker nodes https://raw.githubusercontent.com/hdinsight/presto-hdinsight/master/installpresto.sh 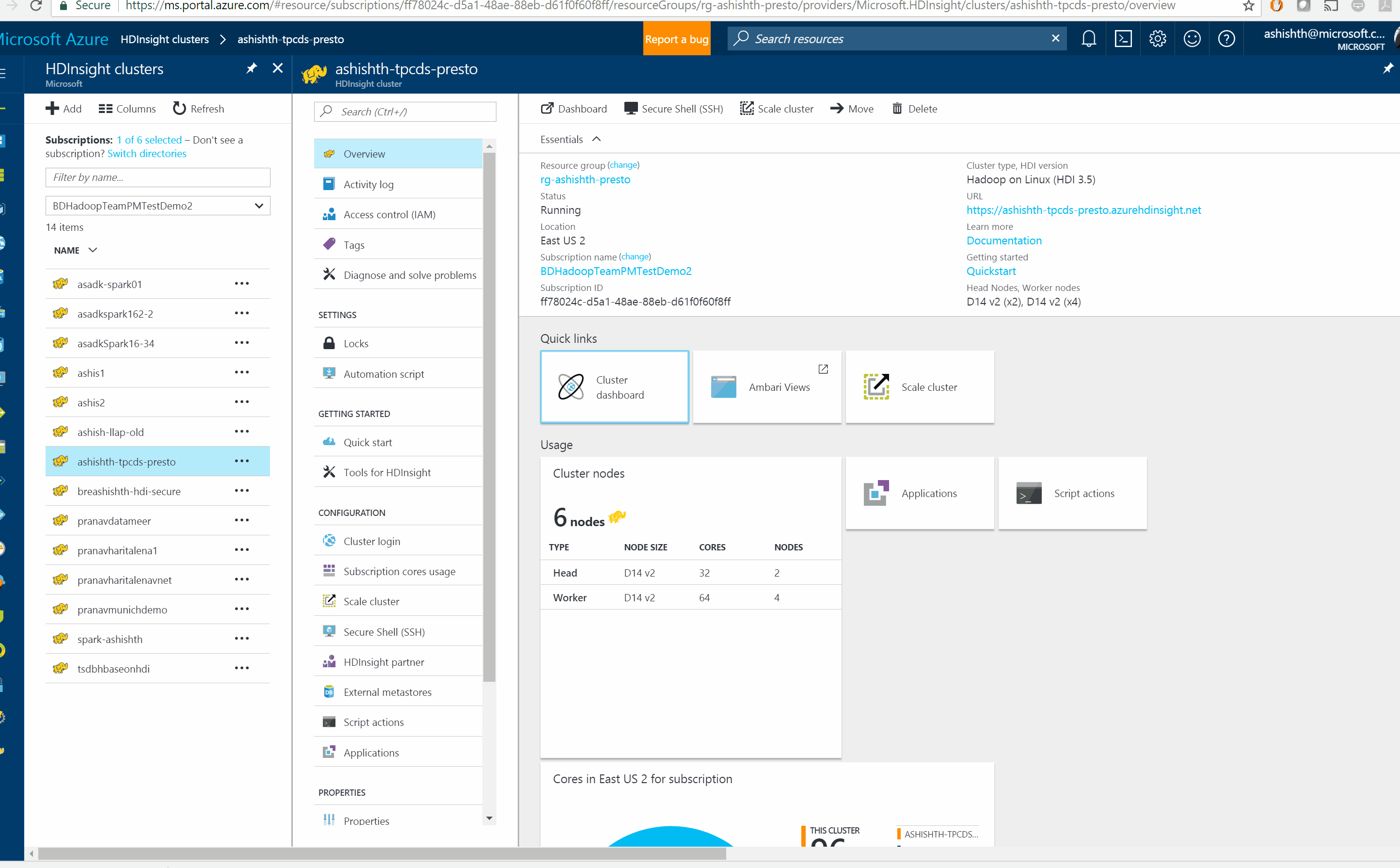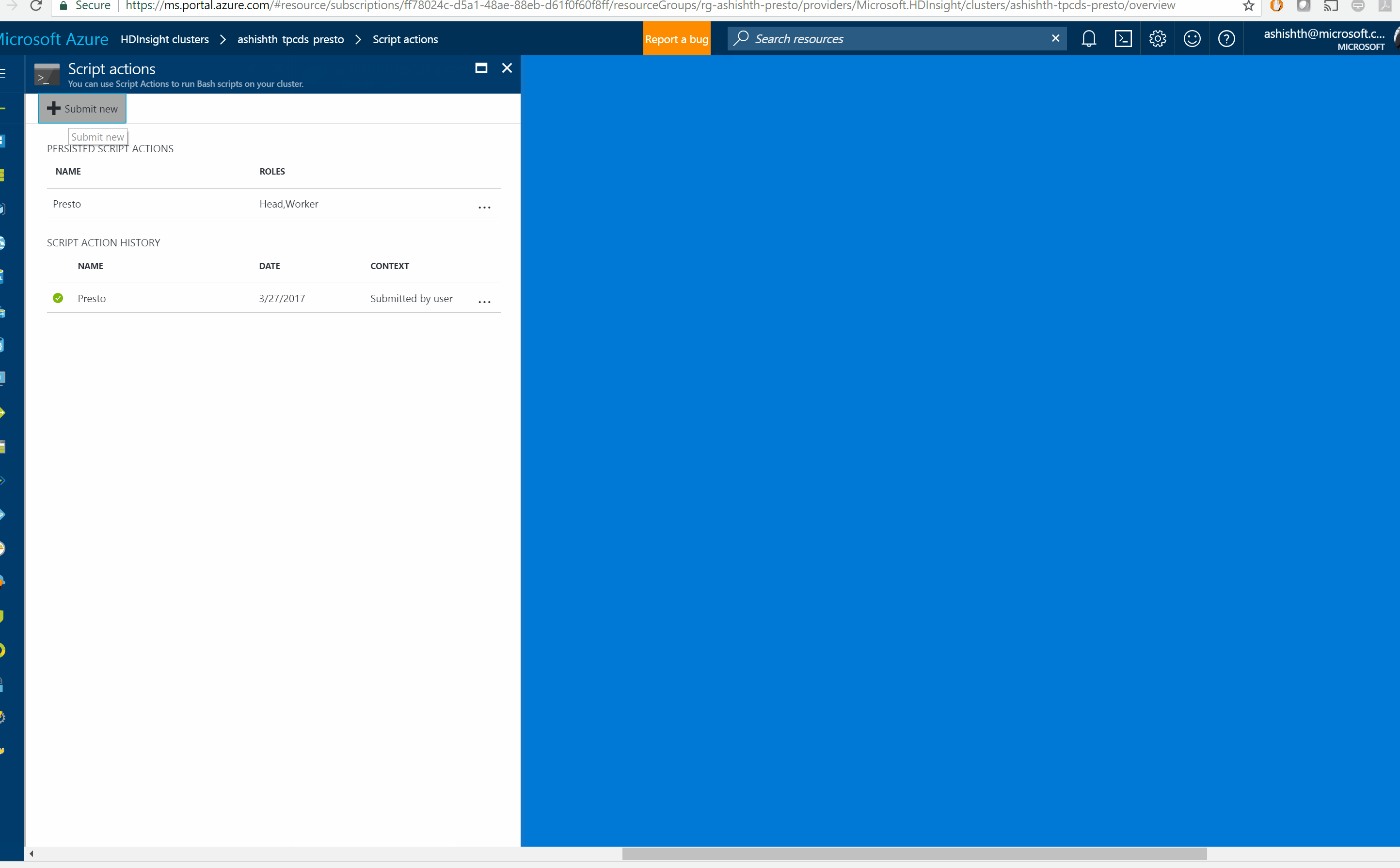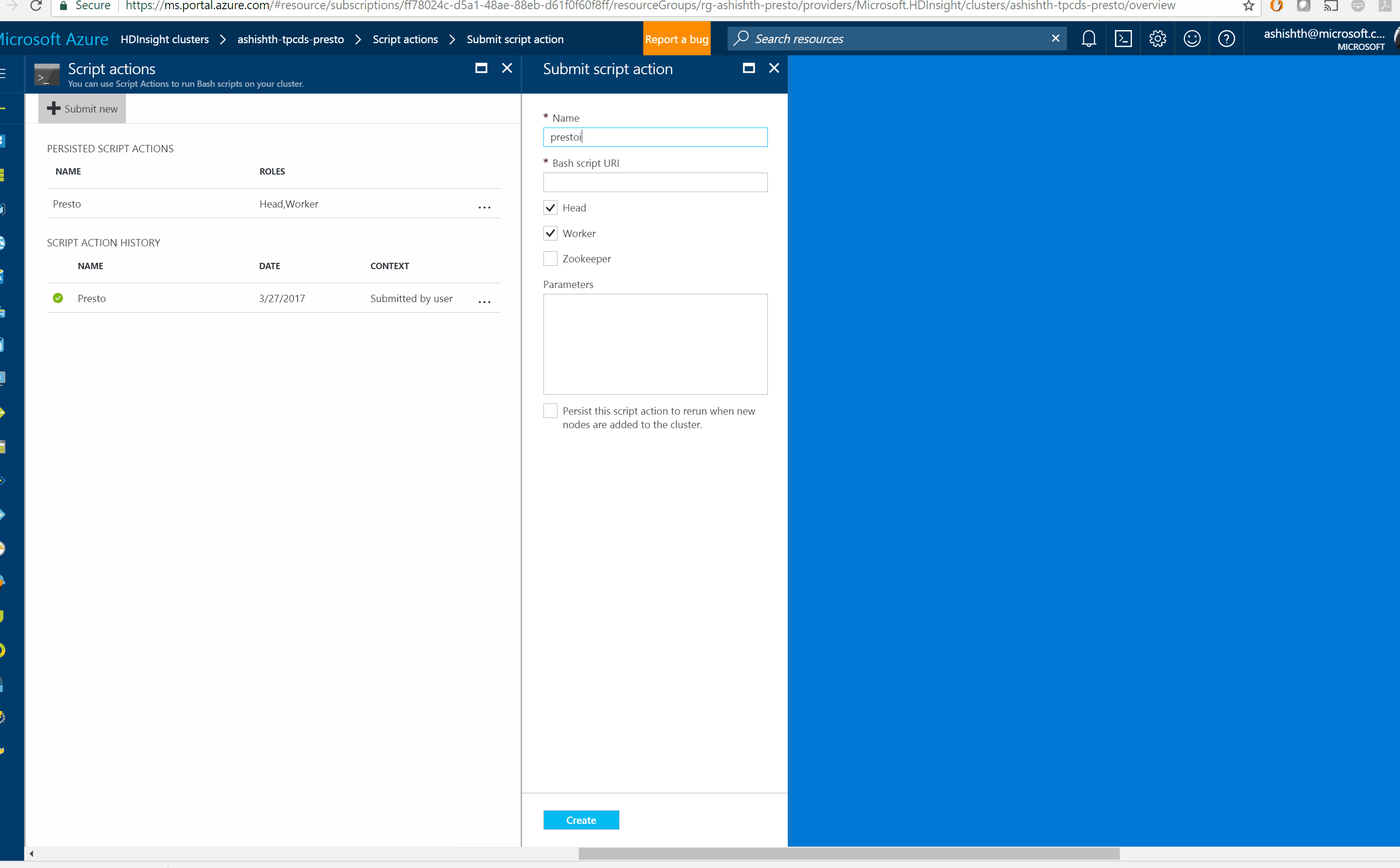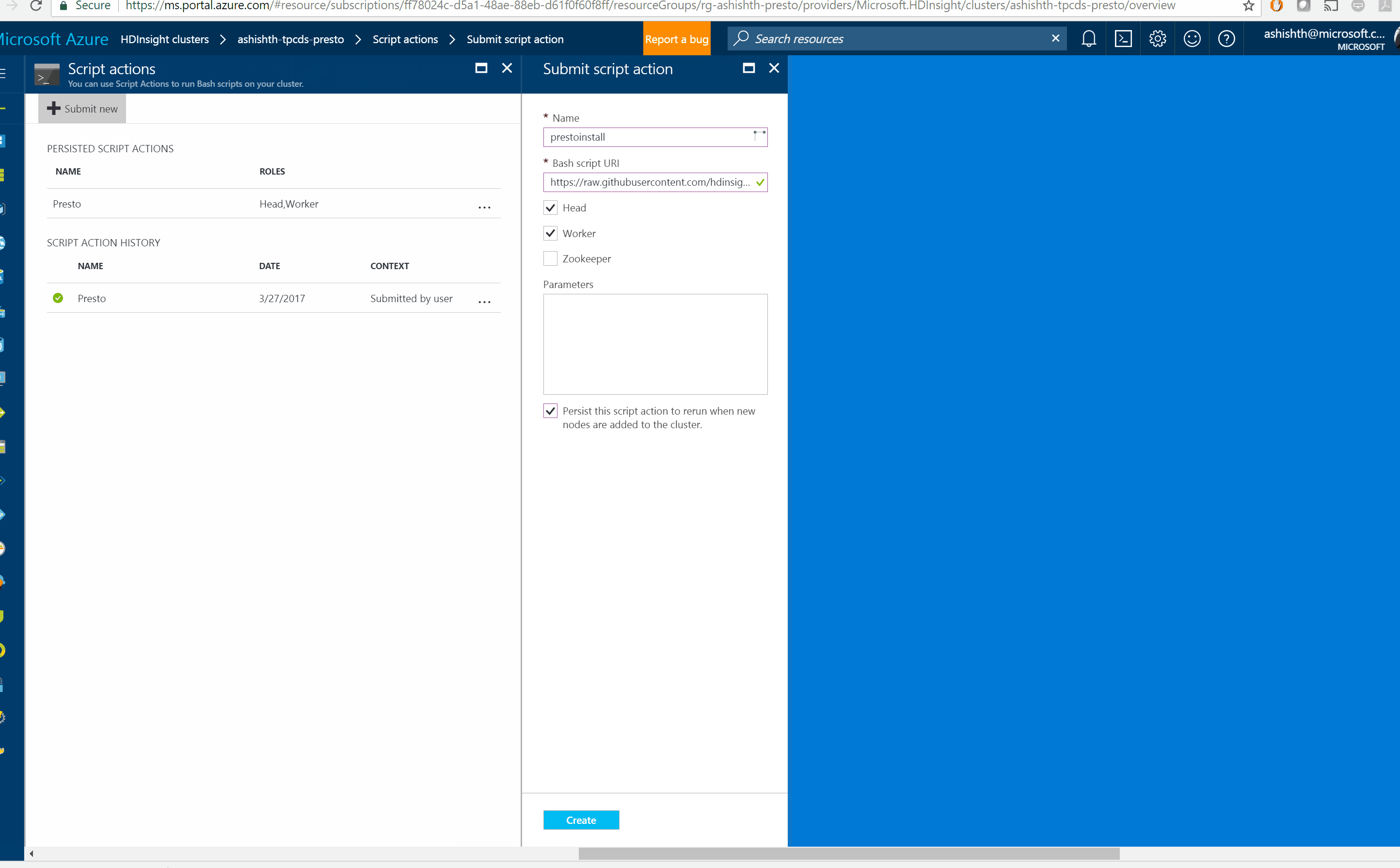
Once Presto is installed, you can SSH into Head Node and start running queries in Presto. We have configured out of box connectors for Hive as well as TPCDS. presto --schema default 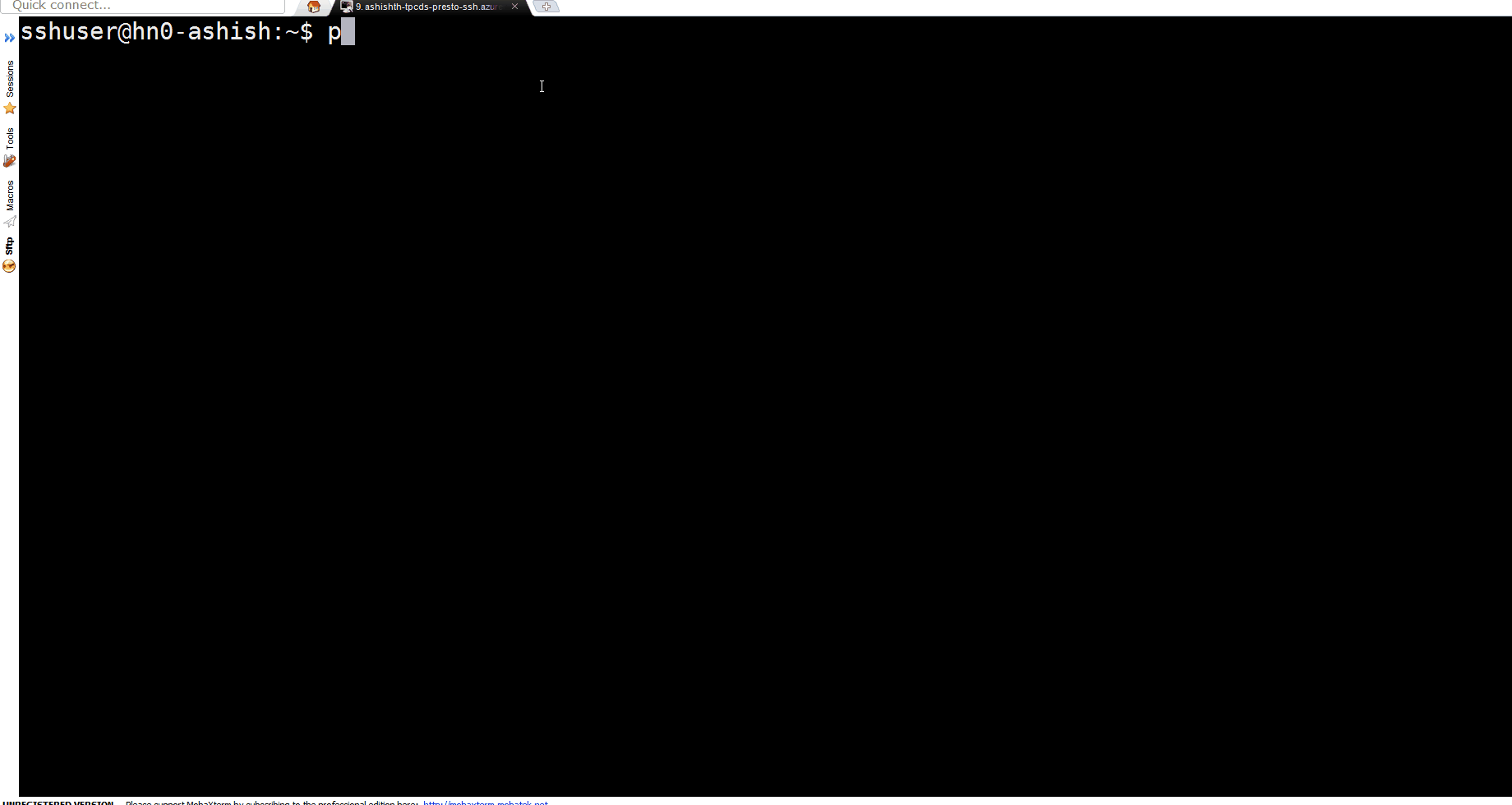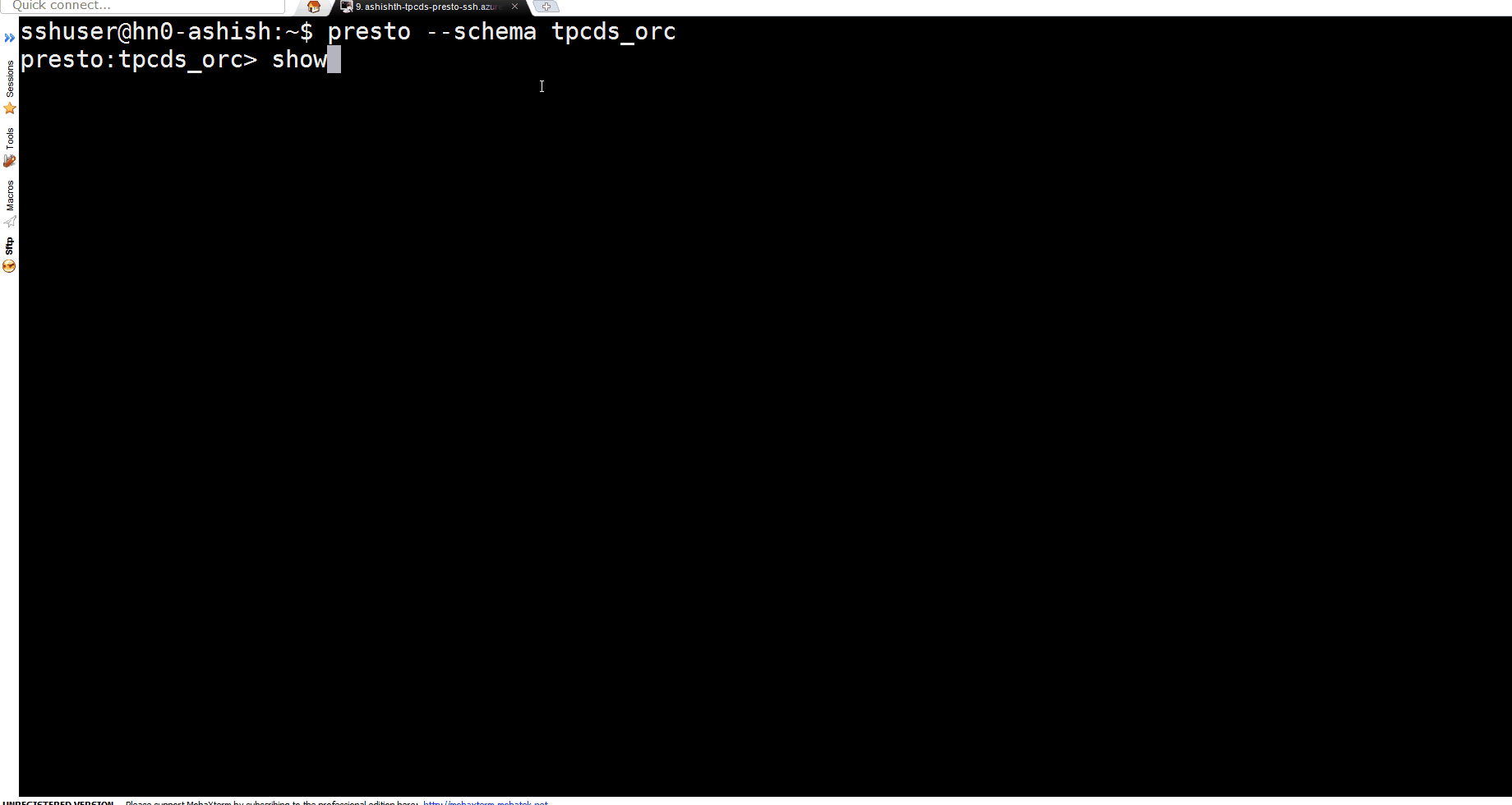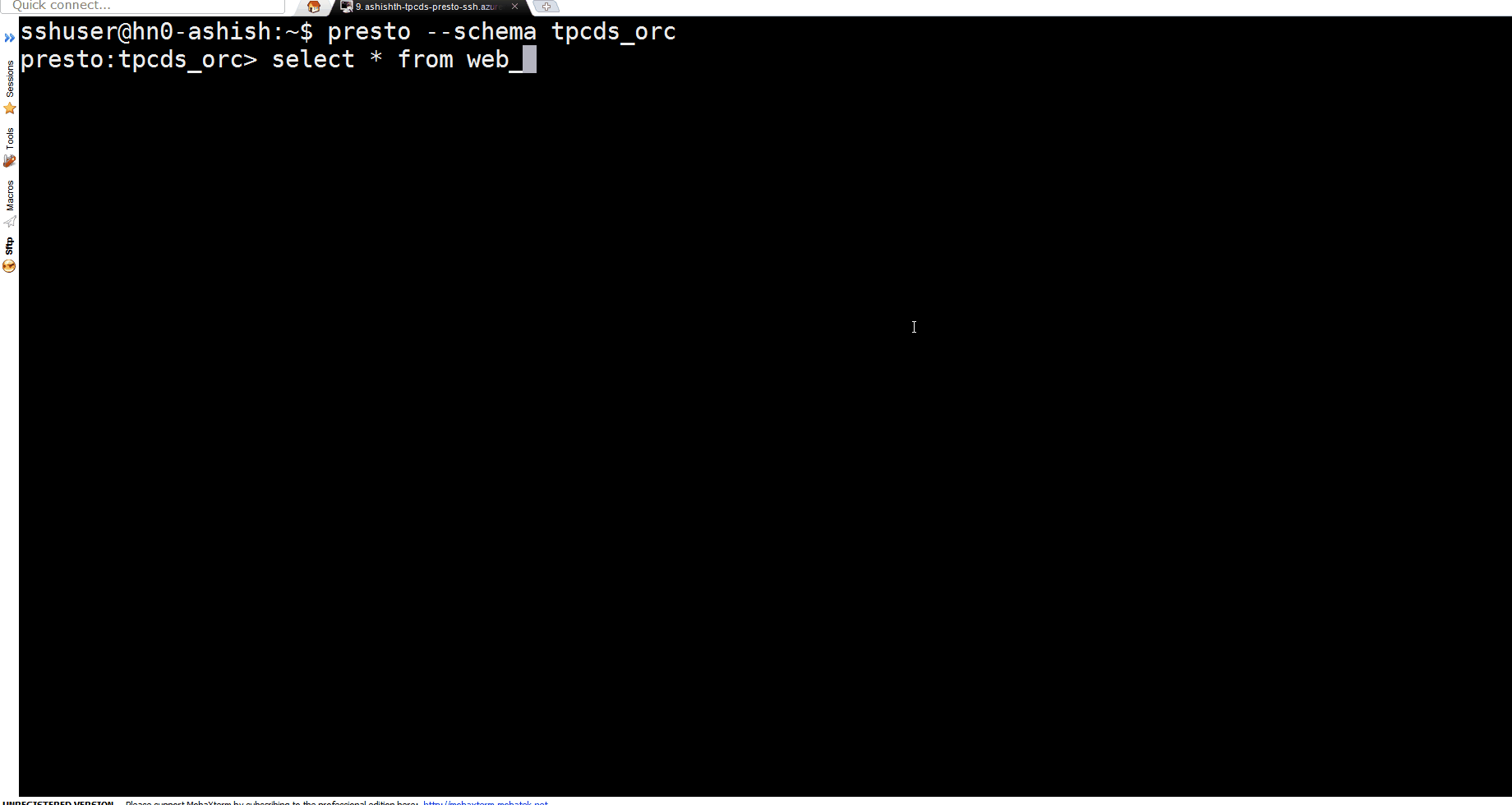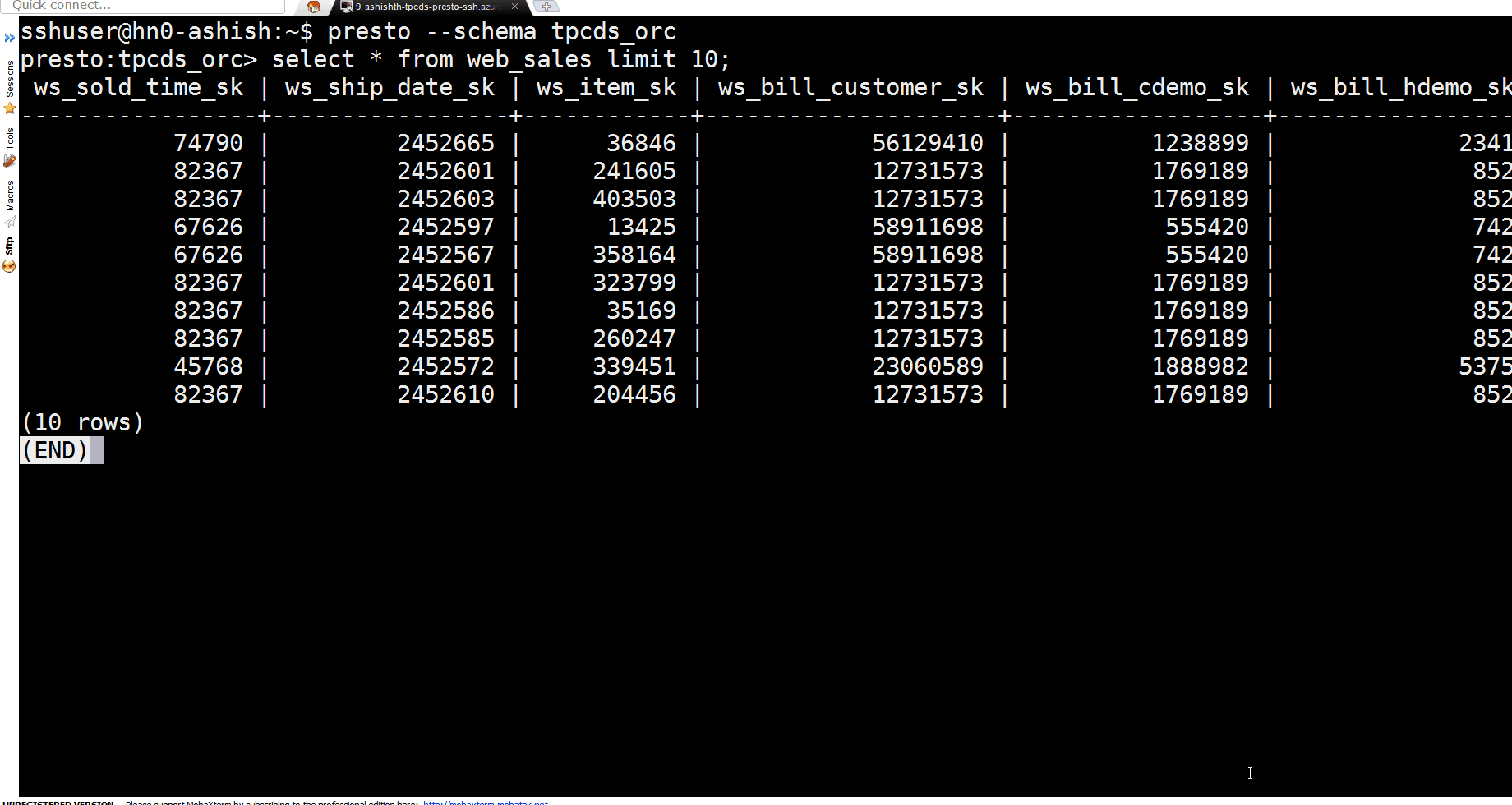
Sounds Interesting and want to learn more about Presto and it's Inner-workings in HDInsight as well as how to setup UX components (e.g. Airpal)? Please follow the documentation here
Configuring Presto to query multiple data sources
Now, let's do something interesting. We will connect Presto to couple of other data sources such as Cosmos DB (Mongo API) and Azure SQL DB, we can then write a query that joins the tables across these data sources. First, we will need to SSH into the cluster and add the connection strings for your data sources. The configuration file is located at
/var/lib/presto/presto-hdinsight-master and edit appConfig-default.json
Update the configuration file with Cosmos DB Mongo connection string and Azure SQL DB connection string
SQL DB Connector 'sqlserver': ['connector.name=sqlserver','connection-url=jdbc:sqlserver://<SERVER NAME>.database.windows.net:1433;database=<DATABASE ANME>;user=<USER NAME>@<;password=<PASSWORD>@;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;', 'connection-user=USER NAME','connection-password=<PASSWORD>']
Cosmos DB (MongoDB API) Connector 'cosmosdb': ['connector.name=mongodb','mongodb.seeds=<COSMOS DB ACCOUNT>.documents.azure.com:<PORT>','mongodb.credentials=<USER NAME>:<PASSWORD>@<COLLECTION NAME>','mongodb.ssl.enabled=true'],
After adding the the connectors your config (appConfig-default.json) should look like this
{<br>"schema": "https://example.org/specification/v2.0.0",<br>"metadata": {<br>},<br>"global": {<br>"site.global.data_dir": "/var/lib/presto/data",<br>"site.global.config_dir": "/var/lib/presto/etc",<br>"site.global.app_name": "presto-server-0.174",<br>"site.global.app_pkg_plugin": "${AGENT_WORK_ROOT}/app/definition/package/plugins/",<br>"site.global.singlenode": "false",<br>"site.global.coordinator_host": "${COORDINATOR_HOST}",<br>"site.global.presto_query_max_memory": "728GB",<br>"site.global.presto_query_max_memory_per_node": "56GB",<br>"site.global.presto_server_port": "9090",<br>"site.global.catalog":<br>"{'sqlserver': ['connector.name=sqlserver',<br>'connection-url=jdbc:sqlserver://<DATABASE SERVER>.database.windows.net:1433;database=<DATABASE>;<br>user=<USER>@<DATABASE SERVER>;password=<PASSWORD>@;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;',<br>'connection-user=<USER>','connection-password=<PASSWORD>'],<br>'cosmosdb': ['connector.name=mongodb','mongodb.seeds=<DATABASE SERVER>.documents.azure.com:<PORT>',<br>'mongodb.credentials=<USER NAME>:<PASSWORD>@<COLLECTION NAME>','mongodb.ssl.enabled=true'],<br>'hive': ['connector.name=hive-hadoop2',<br>'hive.metastore.uri=thrift://hn0-ashish.340aizga0o4ehlr2vhae25fxwb.cx.internal.cloudapp.net:9083,<br>thrift://hn1-ashish.340aizga0o4ehlr2vhae25fxwb.cx.internal.cloudapp.net:9083',<br>'hive.config.resources=/etc/hadoop/conf/hdfs-site.xml,/etc/hadoop/conf/core-site.xml'], 'tpch': ['connector.name=tpch']}",<br>"site.global.jvm_args": "['-server', '-Xmx95G', '-XX:+UseG1GC', '-XX:G1HeapRegionSize=32M', '-XX:+UseGCOverheadLimit',<br>'-XX:+ExplicitGCInvokesConcurrent', '-XX:+HeapDumpOnOutOfMemoryError', '-XX:OnOutOfMemoryError=kill -9 %p']",<br>"site.global.log_properties": "['com.facebook.presto=WARN']",<br>"site.global.event_listener_properties": "['event-listener.name=event-logger']",<br>"application.def": ".slider/package/presto1/presto-yarn-package.zip",<br>"java_home": "/usr/lib/jvm/java"<br>},<br>"components": {<br>"slider-appmaster": {<br>"jvm.heapsize": "512M"<br>}<br>}<br>}
After changing the configuration, you will need to rebuild the instance of Presto so that it understands the new configuration.
Stop and destroy the current running instance of presto.
sudo slider stop presto1 --force<br>sudo slider destroy presto1 --force
Start a new instance of presto with new connector settings.
sudo slider create presto1 --template /var/lib/presto/presto-hdinsight-master/appConfig-default.json --resources /var/lib/presto/presto-hdinsight-master/resources-default.json
Wait (This could take up-to 2 minutes) for the new instance to be ready and note the presto coordinator address. This address will be used to start Presto-cli
sudo slider registry --name presto1 --getexp presto
{
"coordinator_address" : [ {
"value" : "10.0.0.xx:9090",
"level" : "application",
"updatedTime" : "Wed May 17 05:58:36 UTC 2017"
} ]
Run the Presto CLI presto-cli --server 10.0.0.XX:9090
Read Data from SQL DB table
select * from sqlserver.SalesLT.SalesOrderDetail limit 10
Read data from Hive Table
select * from hive.tpcds_orc.web_sales limit 10;
Read data from CosmosDB
select * from cosmosdb.prestocollection.orders limit 5;
Let's write a query that does UNION ALL across Azure SQL DB table SalesOrderDetails [AdventureWorks sample]and Hive Table Web_Sales [TPCDS data]
select avg(UnitPrice) from sqlserver.SalesLT.SalesOrderDetail as avgprice UNION ALL select avg(web_sales.ws_wholesale_cost) as avgcost from hive.tpcds_orc.web_sales; 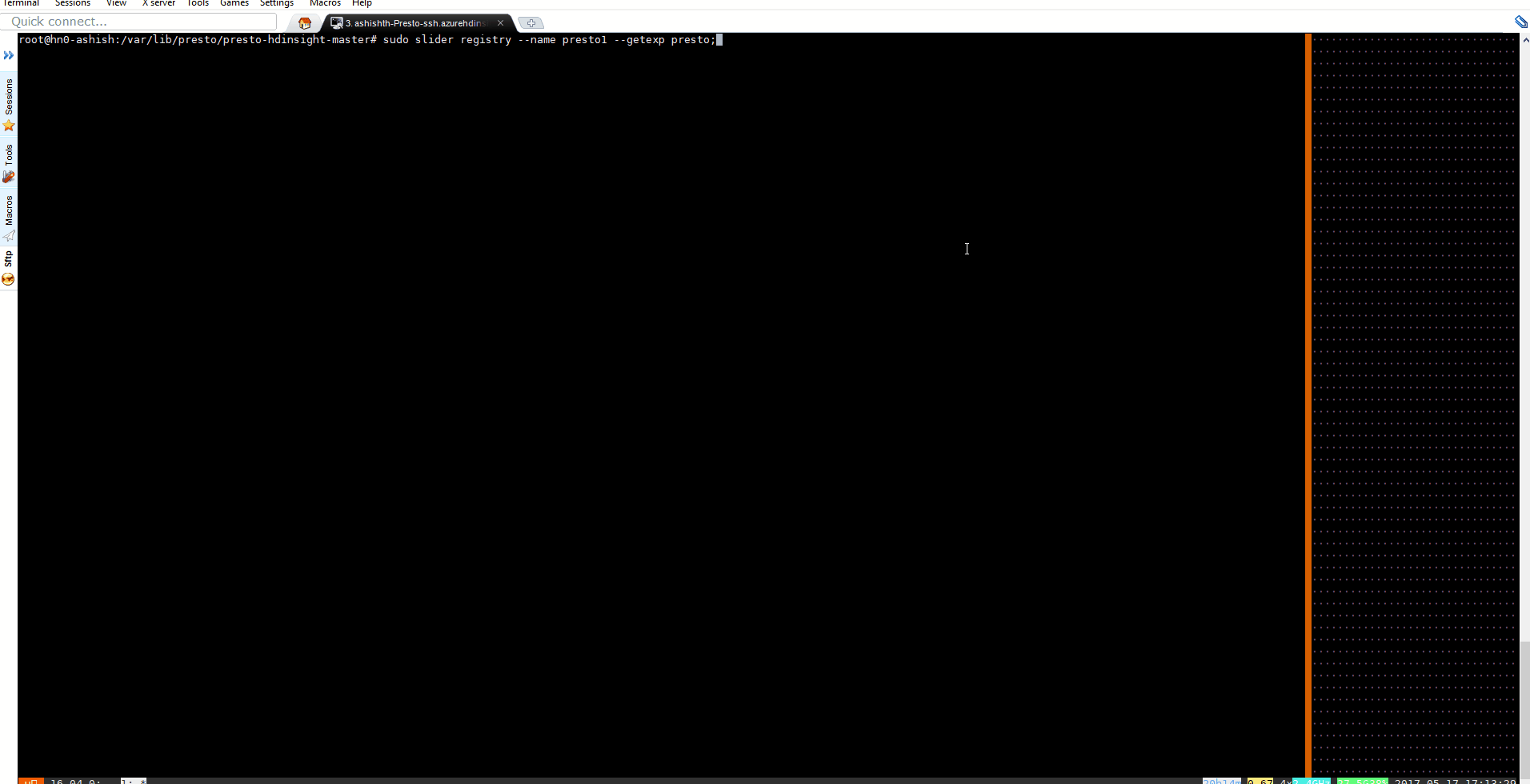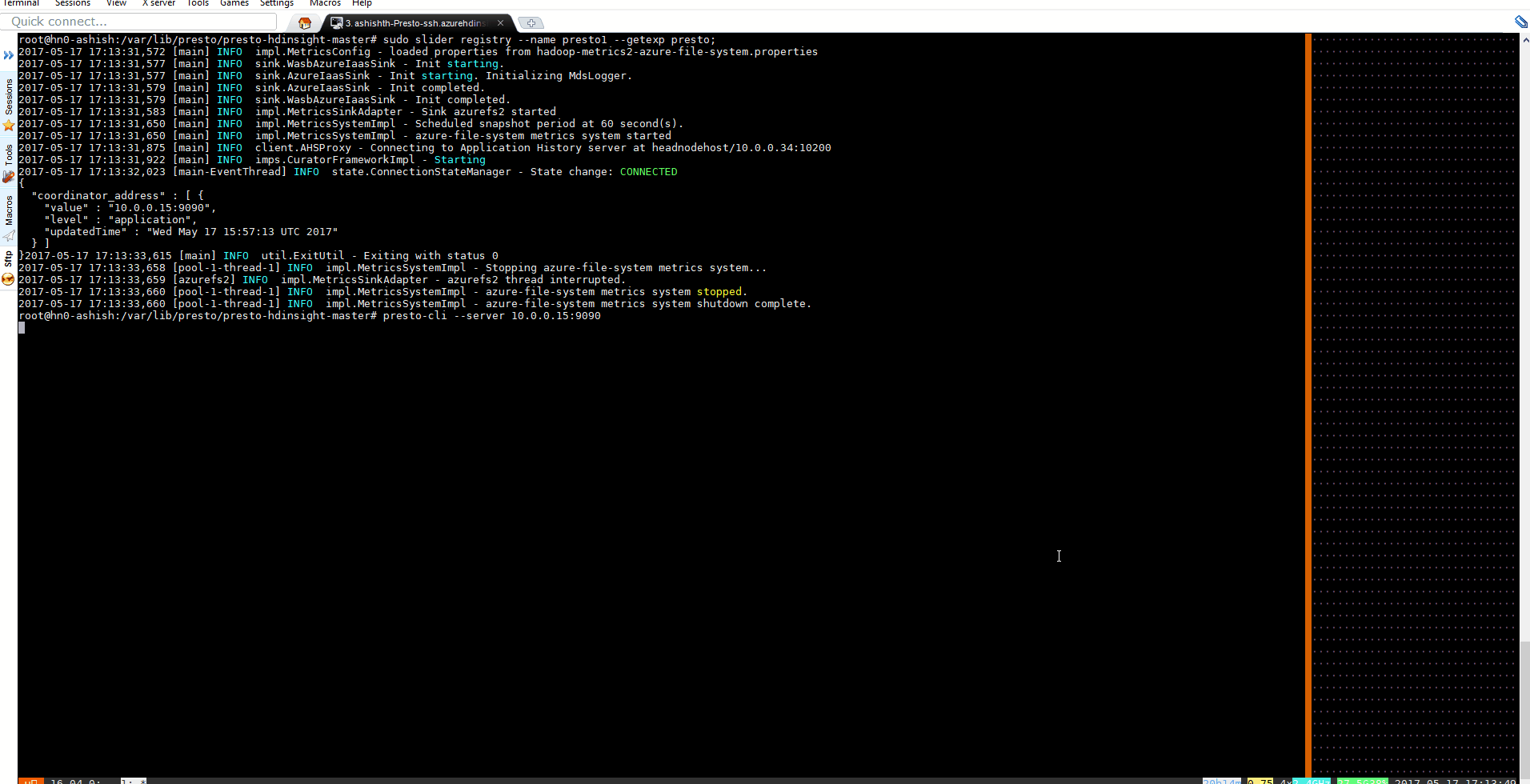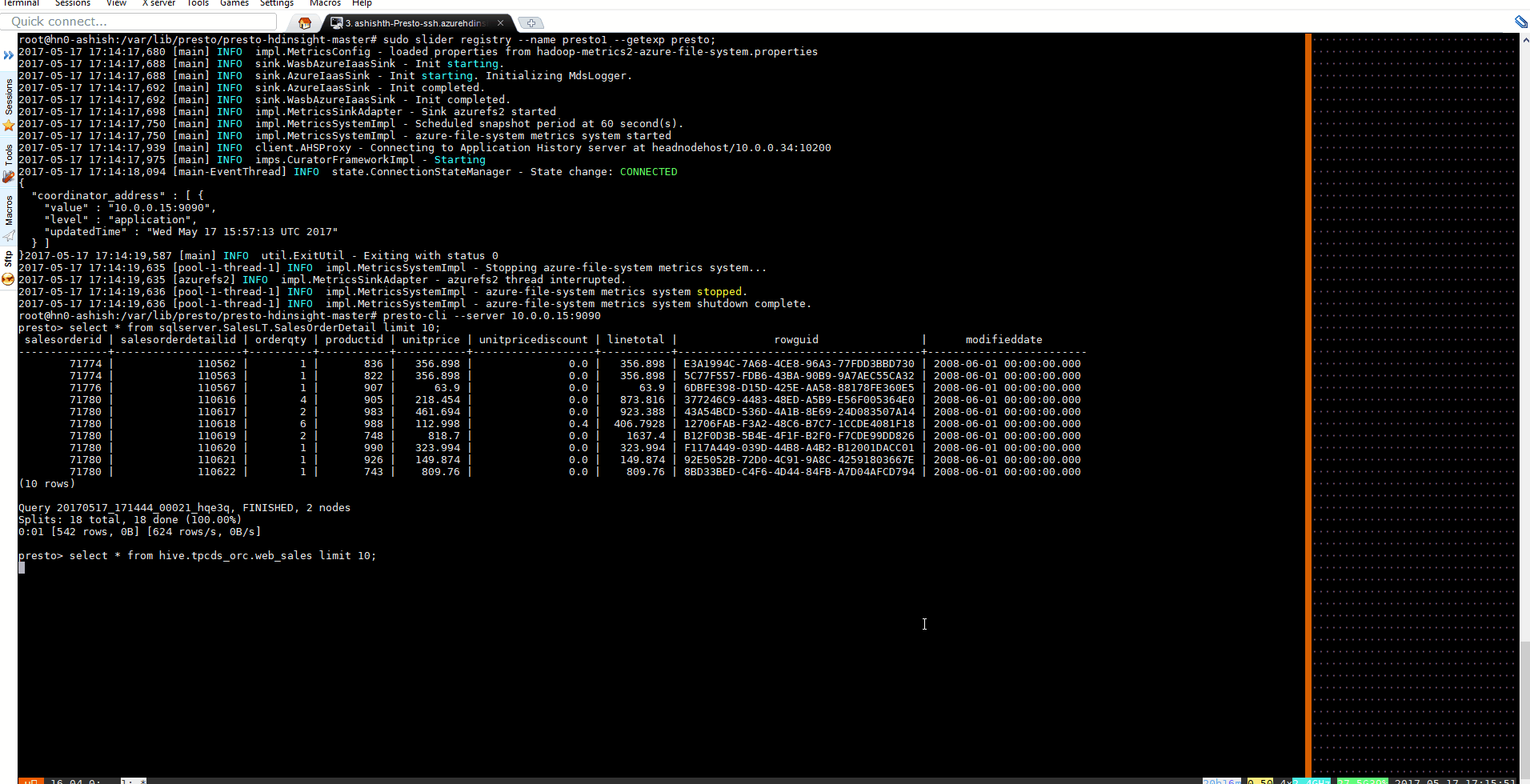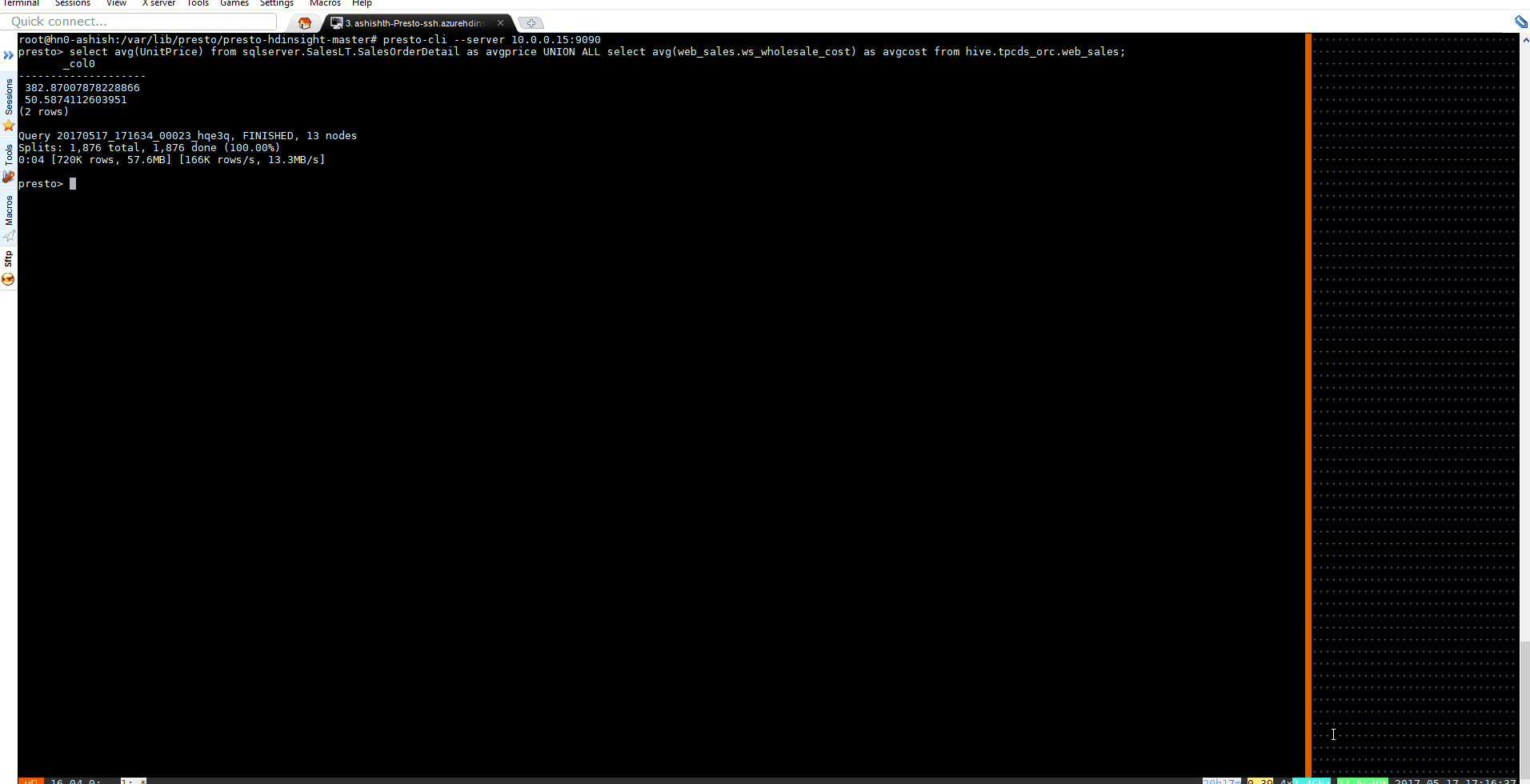
Cosmos DB
Let's create a Table orders in CosmosDB, which we will use to combine with the results with Hive and Azure SQL DB
CREATE TABLE IF NOT EXISTS cosmosdb.prestocollection.orders ( orderkey bigint, orderstatus varchar, totalprice double, orderdate date );<br>INSERT INTO cosmosdb.prestocollection.orders VALUES(2, 'good', 40.0, current_date);INSERT INTO cosmosdb.prestocollection.orders VALUES(1, 'bad', 80.0, current_date);INSERT INTO cosmosdb.prestocollection.orders VALUES(1, 'good', 30.0, current_date);
Finally we can write a query that goes across all three data sources
select avg(TotalPrice) as totalcost from cosmosdb.prestocollection.orders UNION ALL select avg(web_sales.ws_wholesale_cost) as avgcost from hive.tpcds_orc.web_sales Union ALL select avg(UnitPrice) from sqlserver.SalesLT.SalesOrderDetail as avgprice ;
In this blog post we used TPCDS data in Hive and AdventureWorks database in Azure SQL DB. If you are interested in creating your own TPCDS benchmarks for HDInsight (Spark, Presto, LLAP & Hive). Please read this
How is Presto supported in HDInsight?
Custom components, such as Presto, receive commercially reasonable support to help you to further troubleshoot the issue. This might result in resolving the issue OR asking you to engage available channels for the open source technologies where deep expertise for that technology is found. For example, there are many community sites that can be used, like: MSDN forum for HDInsight, https://stackoverflow.com. and Presto community site : https://prestodb.io/community.html