Use H2O.ai on Azure HDInsight
We're hosting an upcoming webinar to present you how to use H2O on HDInsight and to answer your questions. Sign up for our upcoming webinar on combining H2O and Azure HDInsight.
We recently announced that H2O and Microsoft Azure HDInsight have integrated to provide Data Scientists with a Leading Combination of Engines for Machine Learning and Deep Learning. Through H2O’s AI platform and its Sparkling Water solution, users can combine the fast, scalable machine learning algorithms of H2O with the capabilities of Spark, as well as drive computation from Scala/R/Python and utilize the H2O Flow UI, providing an ideal machine learning platform for application developers.
In this blog, we will provide a detailed step-by-step guide to help you set up the first H2O on HDInsight solution.
Step 1: setting up the environment
The first step is to create an HDInsight cluster with H2O installed. You can either create an HDInsight cluster and install H2O during provision time, or you can also install H2O on an existing cluster. Please note that H2O on HDInsight only works for Spark 2.0 on HDInsight 3.5 as of today, which is the default version of HDInsight.
For more information on how to create a cluster in HDInsight, please refer to the documentation here (/en-us/azure/hdinsight/hdinsight-hadoop-provision-linux-clusters). For more information on how to install an application on an existing cluster, please refer to the documentation here (/en-us/azure/hdinsight/hdinsight-apps-install-applications)
Please be noted that we’ve recently updated our UI with less clicks, so you need to click “custom” button to install applications on HDInsight.
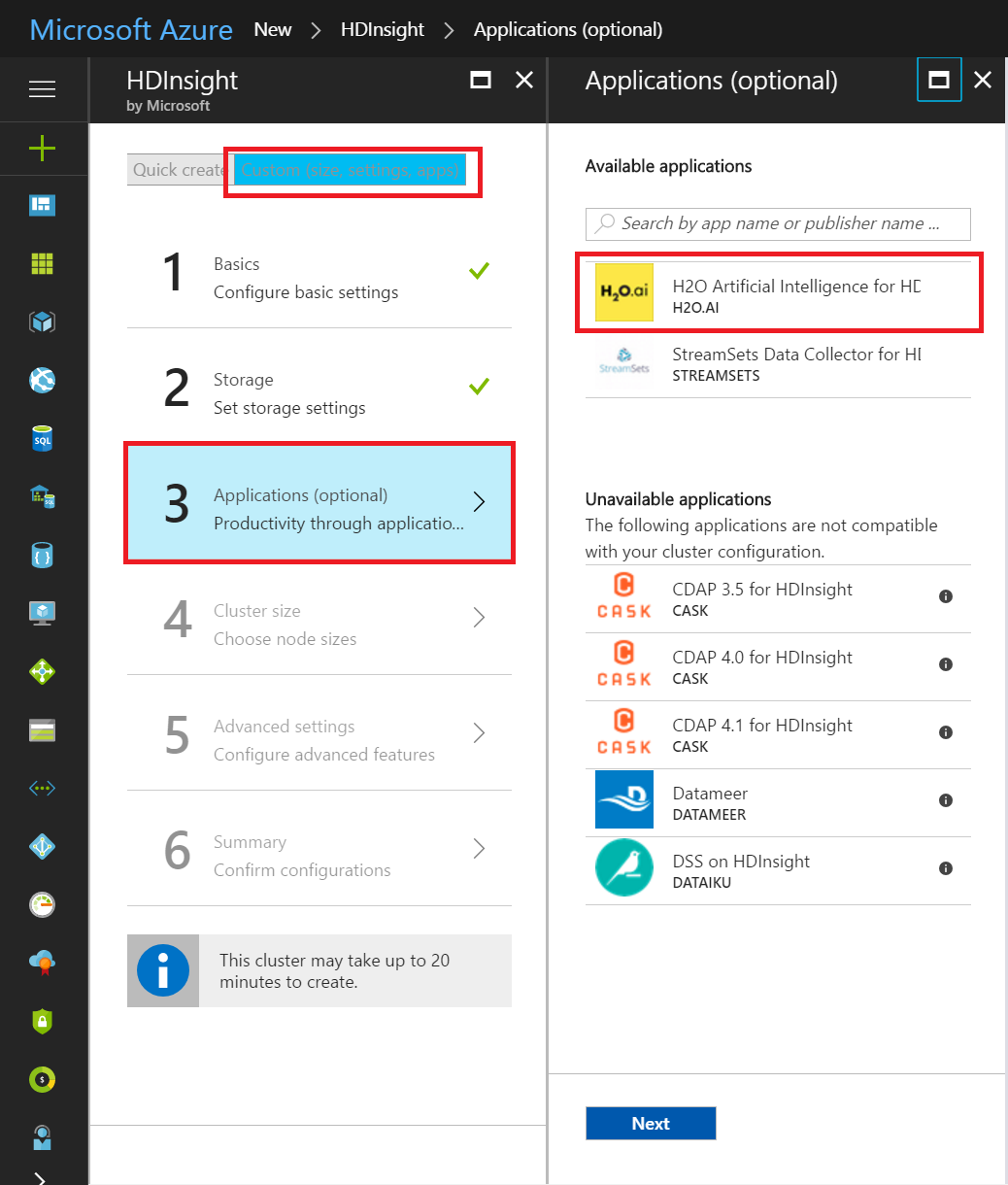
Step 2: Setting up the environment
After installing H2O on HDInsight, you can simply use the built-in Jupyter notebooks to write your first H2O on HDInsight applications. You can simply go to (https://yourclustername.azurehdinsight.net/jupyter) to open the Jupyter Notebook. You will see a folder named “H2O-PySparkling-Examples”.
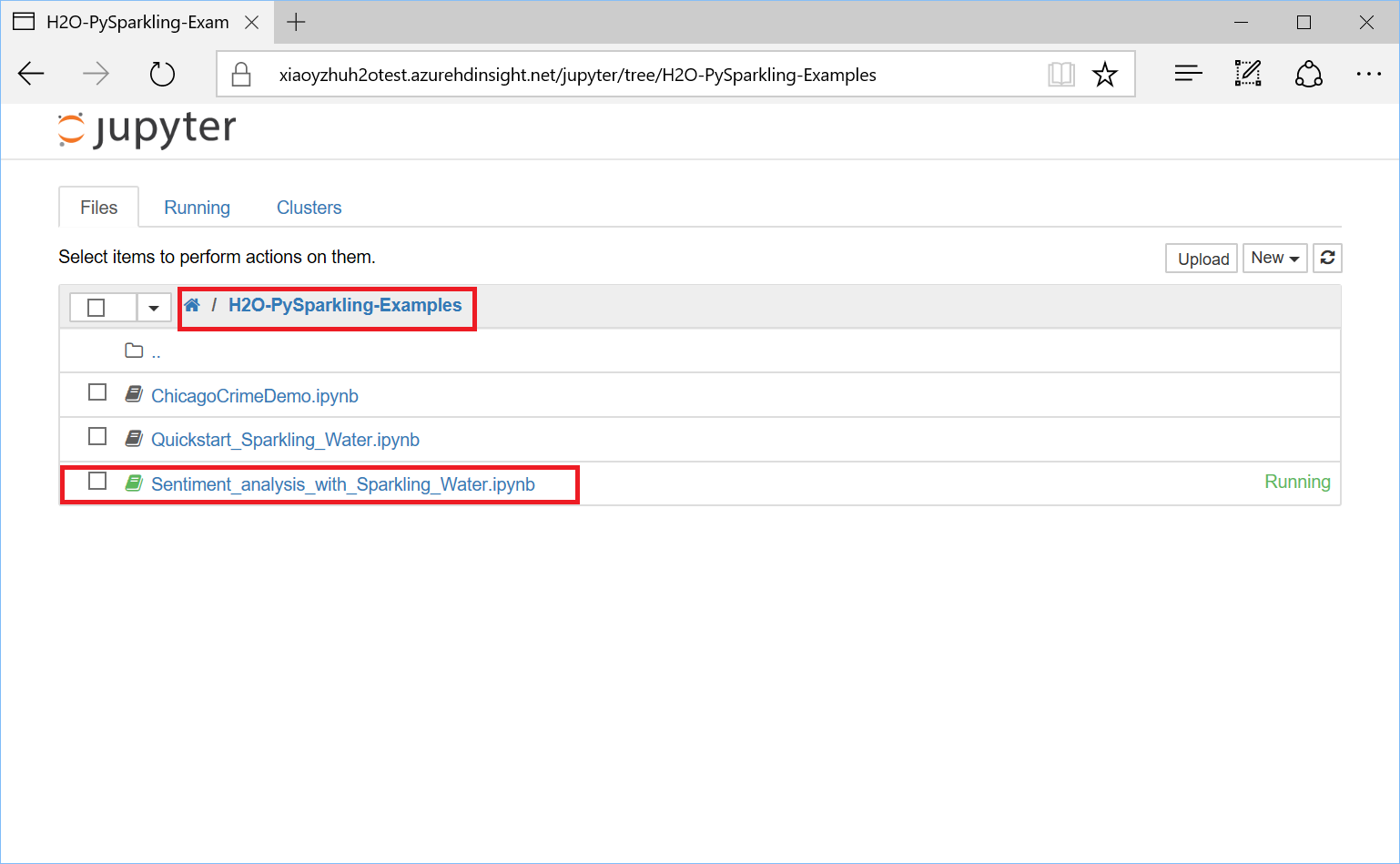
There are a few examples in the folder, but I recommend starting with the one named “Sentiment_analysis_with_Sparkling_Water.ipynb”. Most of the details on how to use the H2O PySparkling Water APIs are already covered in the Notebook itself, so here I will give some high-level overviews.
The first thing you need to do is to configure the environment. Most of the configurations are already taken care by the system, such as the FLOW UI address, Spark jar location, the Sparkling water egg file, etc.
There are three important parameter to configure: the driver memory, executor memory, and the number of executors. The default values are optimized for the default 4 node cluster, but your cluster size might vary.
Tuning these parameters are outside of scope of this blog, as it is more of a Spark resource tuning problem. There are a few good reference articles such as this one (https://blog.cloudera.com/blog/2015/03/how-to-tune-your-apache-spark-jobs-part-2/).
Note that all spark applications deployed using a Jupyter Notebook will have "yarn-cluster" deploy-mode. This means that the spark driver node will be allocated on any worker node of the cluster, not on the head nodes.
In this example, we simply allocate 75% of an HDInsight cluster worker nodes to the driver and executors (21 GB each), and put 3 executors, since the default HDInsight cluster size is 4 worker nodes (3 executors + 1 driver)

Please refer to the Jupyter Notebook tutorial (/en-us/azure/hdinsight/hdinsight-apache-spark-jupyter-notebook-kernels) for more information on how to use Jupyter Notebooks on HDInsight.
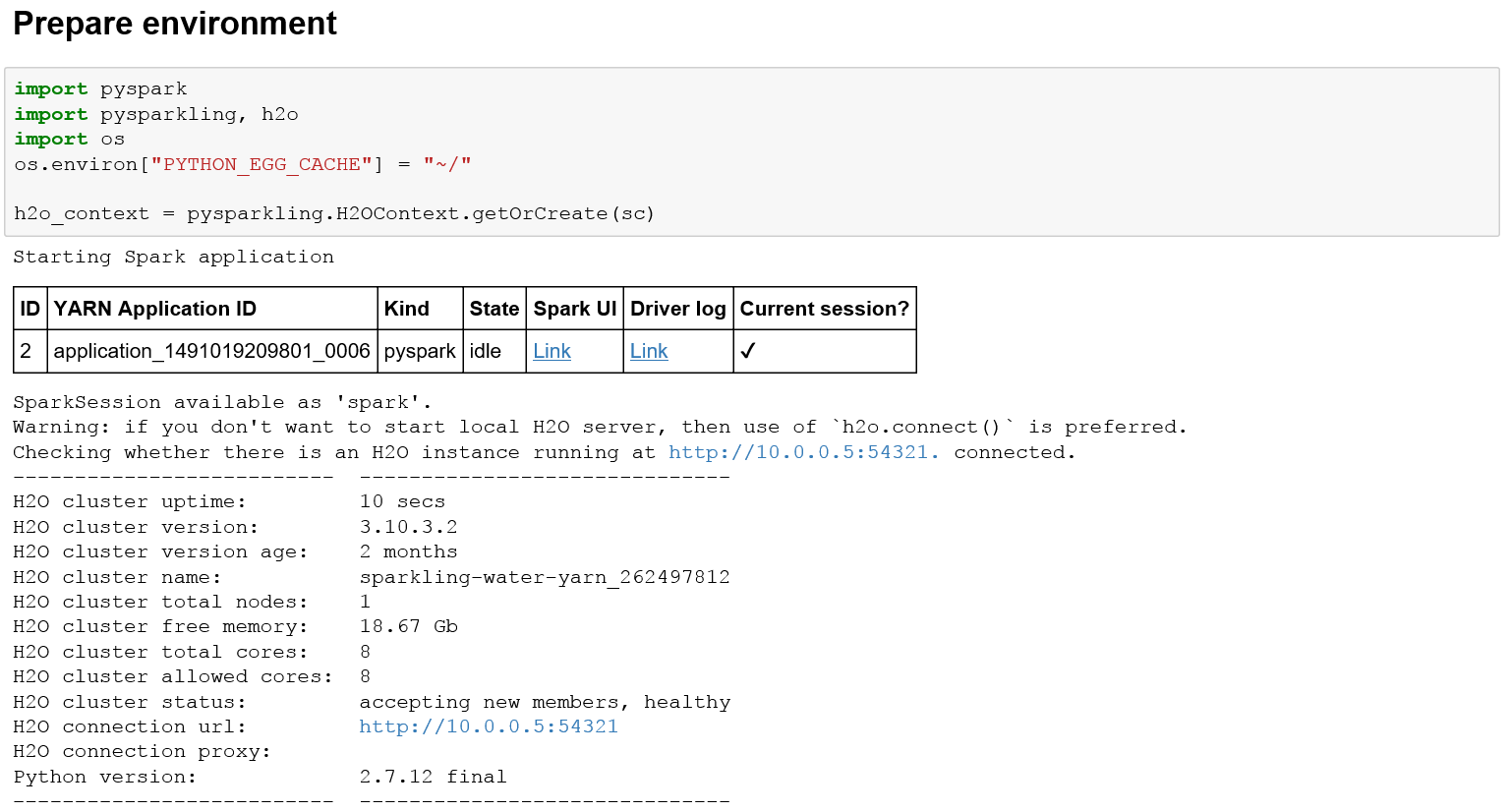
The second step here is to create an H2O context. Since one default spark context is already configured in the Jupyter Notebook (called sc), in H2O, we just need to call
h2o_context = pysparkling.H2OContext.getOrCreate(sc)
so H2O can recognize the default spark context.
After executing this line of code, H2O will print out the status, as well as the YARN application it is using.
After this, you can use H2O APIs plus the Spark APIs to write your applications. To learn more about Sparkling Water APIs, refer to the H2O GitHub site here: https://github.com/h2oai/sparkling-water 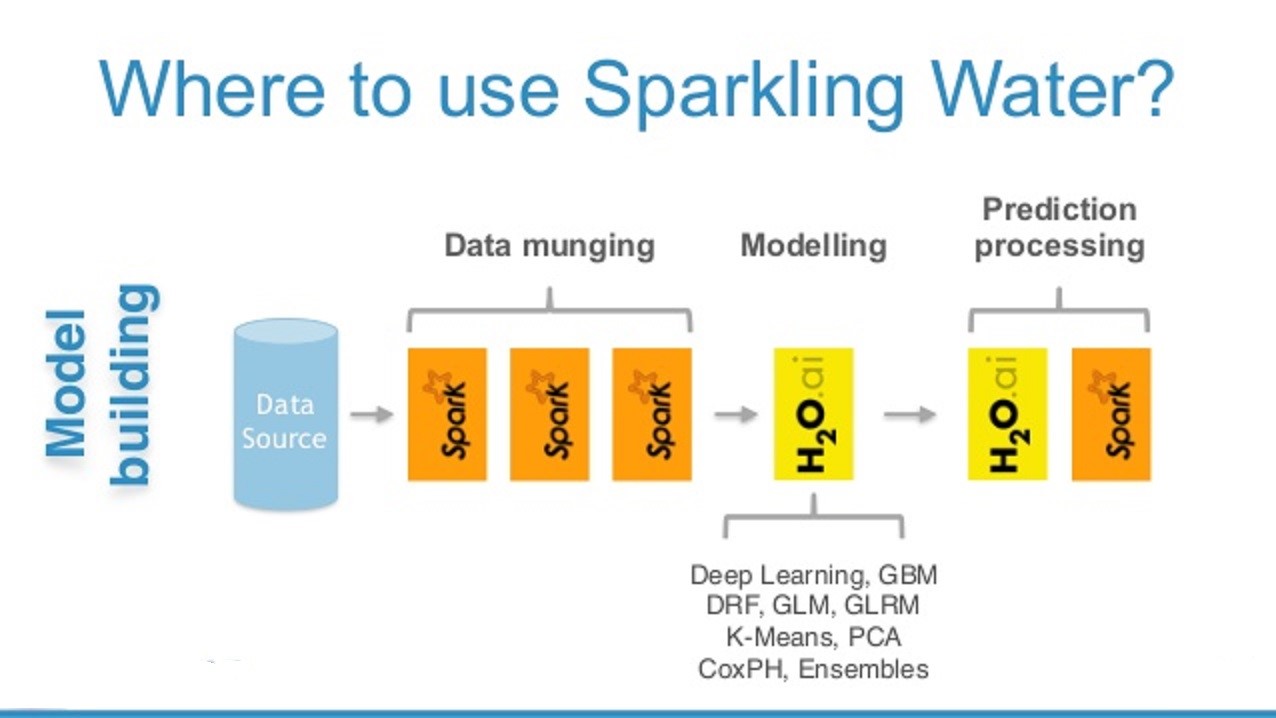
This sentiment analysis example has a few steps to analyze the data:
- Load data to Spark and H2O frames
- Data munging using H2O API
- Remove columns
- Refine Time Column into Year/Month/Day/DayOfWeek/Hour columns
- Data munging using Spark API
- Select columns Score, Month, Day, DayOfWeek, Summary
- Define UDF to transform score (0..5) to binary positive/negative
- Use TF-IDF to vectorize summary column
- Model building using H2O API
- Use H2O Grid Search to tune hyper parameters
- Select the best Deep Learning model
Please refer to the Jupyter Notebook for more details.
Step 3: use FLOW UI to monitor the progress and visualize the model
H2O Flow is an interactive web-based computational user interface where you can combine code execution, text, mathematics, plots and rich media into a single document, much like Jupyter Notebooks. With H2O Flow, you can capture, rerun, annotate, present, and share your workflow. H2O Flow allows you to use H2O interactively to import files, build models, and iteratively improve them. Based on your models, you can make predictions and add rich text to create vignettes of your work - all within Flow’s browser-based environment. In this blog, we will only focus on its visualization part.
H2O FLOW web service lives in the Spark driver and is routed through the HDInsight gateway, so it can only be accessed when the spark application/Notebook is running
You can click the available link in the Jupyter Notebook, or you can directly access this URL:
https://yourclustername-h2o.apps.azurehdinsight.net/flow/index.html
In this example, we will demonstrate its visualization capabilities. Simply click “Model > List Grid Search Results” (since we are trying to use Grid Search to tune hyper parameters)
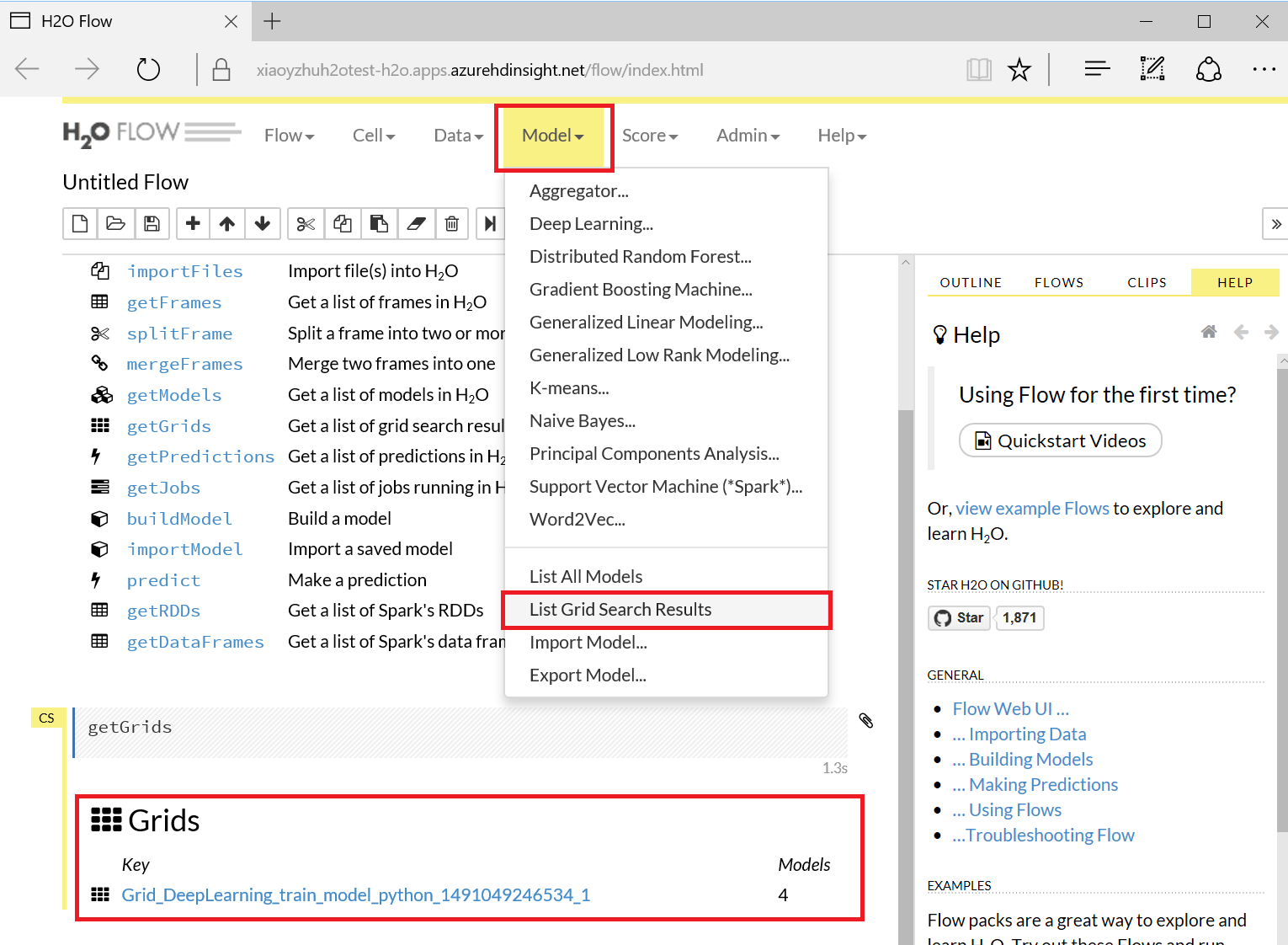
Then you can access the 4 grid search results:
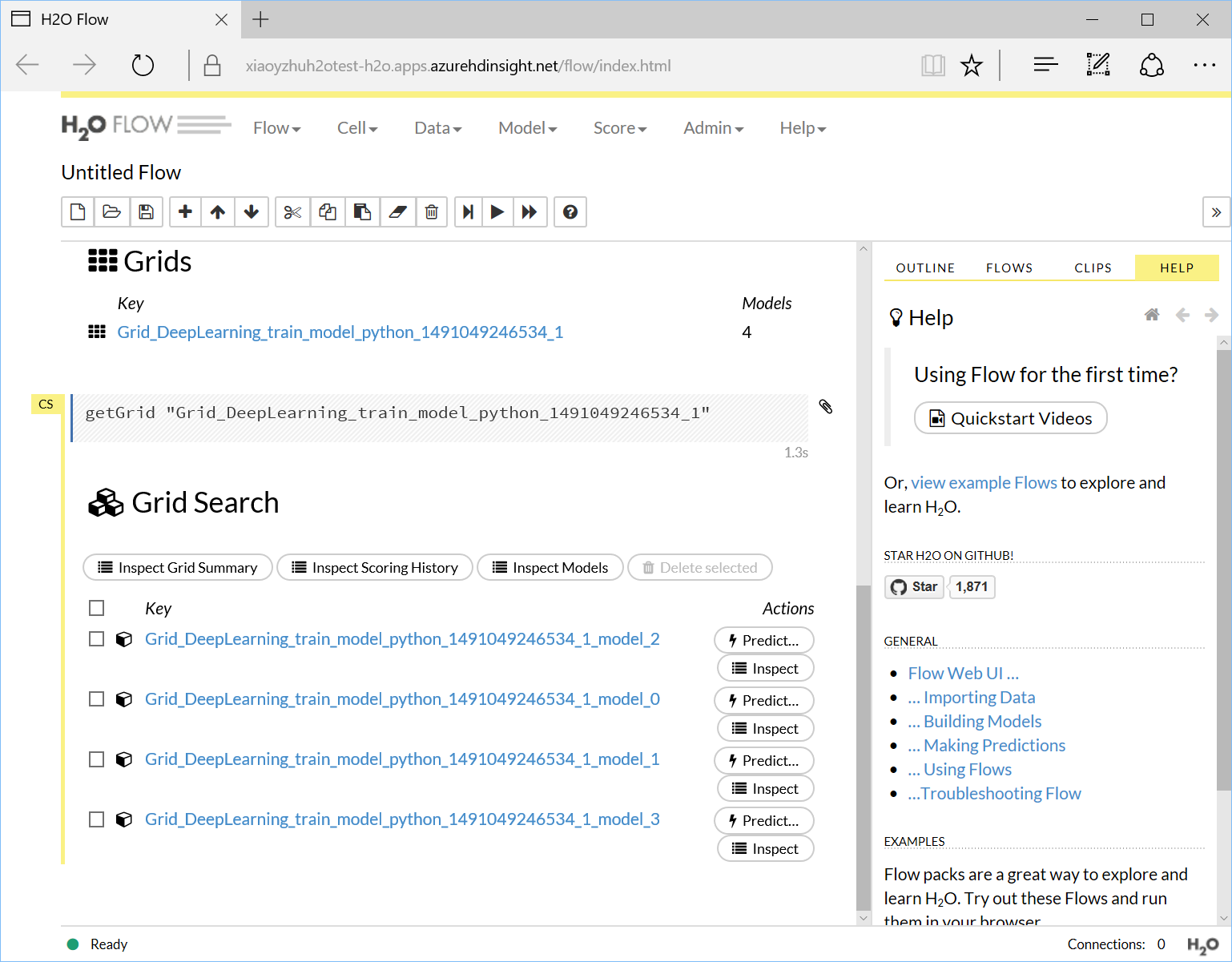
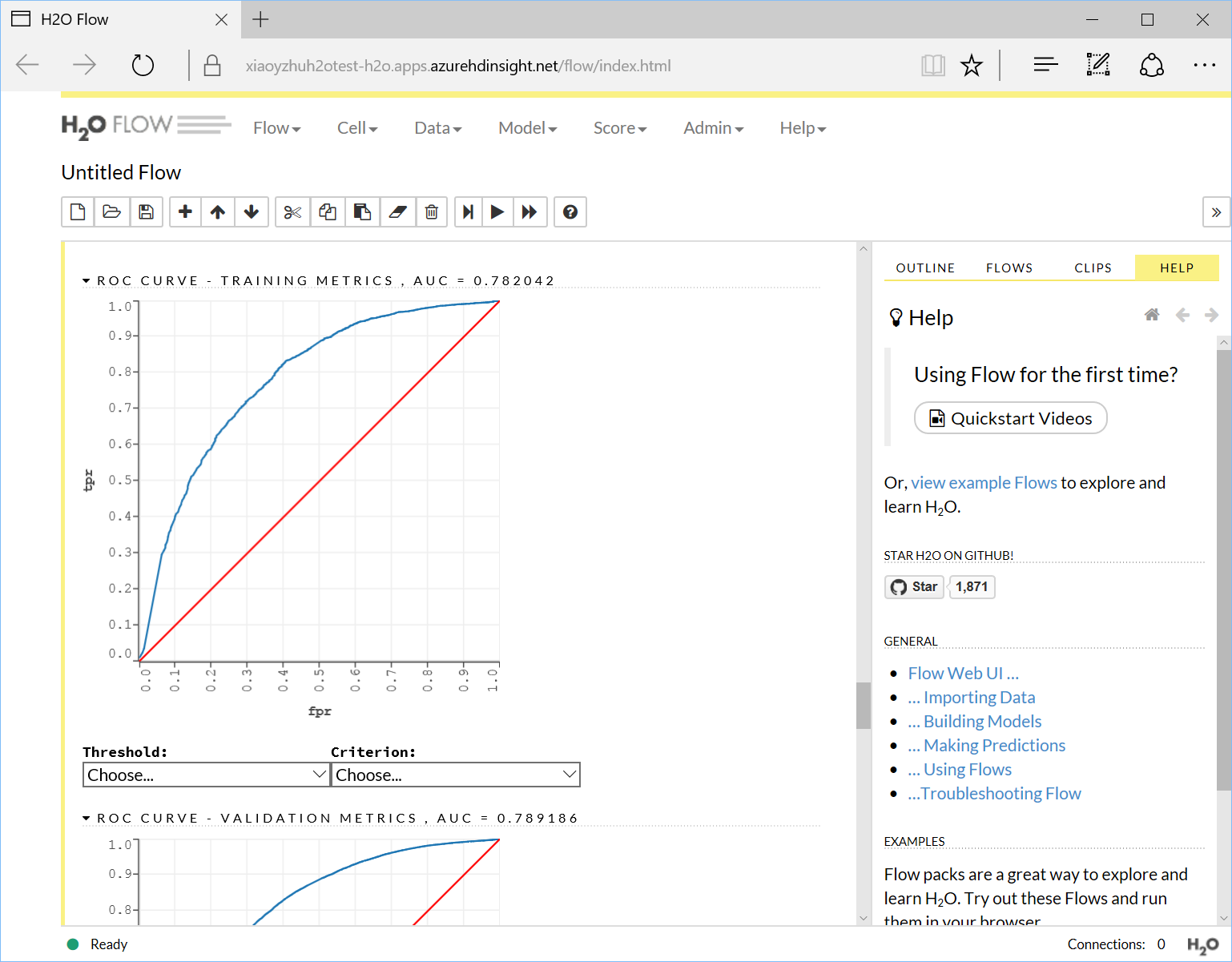
And you can view the details of each model. For example, you can visualize the ROC curve as below:
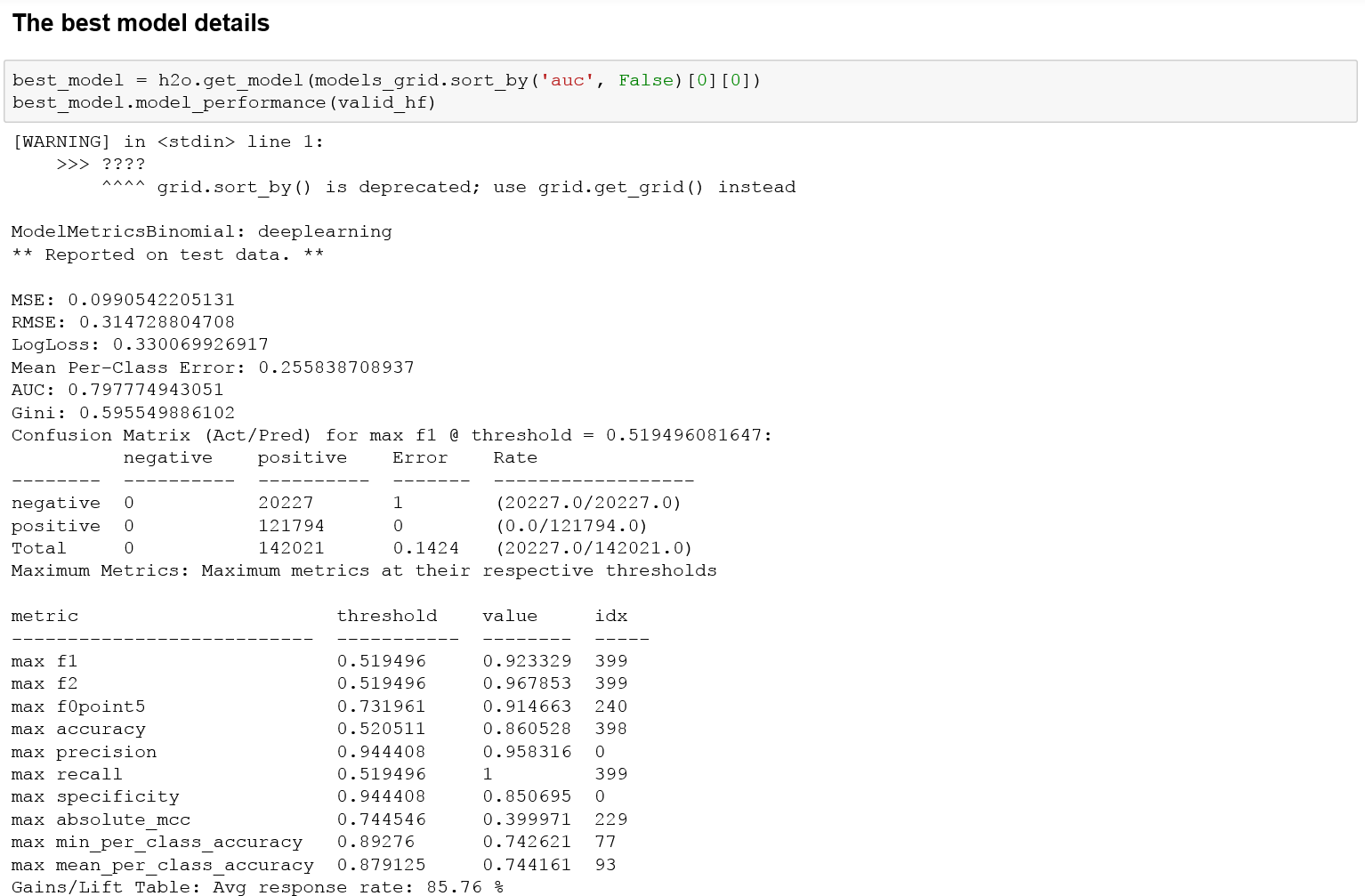
In Jupyter Notebooks, you can also view the performance in text format:
Summary
In this blog, we have walked you through the detailed steps on how to create your first H2O application on HDInsight for your machine learning applications. For more information on H2O, please visit H2O site (https://www.h2o.ai/); For more information on HDInsight, please visit HDInsight site (https://azure.microsoft.com/en-us/services/hdinsight/)
This blog-post is co-authored by Pablo Marin(@pablomarin), Solution Architect in Microsoft.