Partial Caching of DataFrame by Vertical and Horizontal Partitioning
The sample Jupyter Scala notebook described in this blog can be downloaded from https://github.com/hdinsight/spark-jupyter-notebooks/blob/master/Scala/PartialCachingByVerticallyAndHorizontallyPartitioningDataFrame.ipynb
In many Spark applications, performance benefit is obtained from caching the data if reused several times in the applications instead of reading them each time from persistent storage. However, there can be situations when the entire data cannot be cached in the cluster due to resource constraint in the cluster and/or the driver. In this blog we describe two schemes that can be used to partially cache the data by vertical and/or horizontal partitioning of the Distributed Data Frame (DDF) representing the data. Note that these schemes are application specific and are beneficial only if the cached part of the data is used multiple times in consecutive transformations or actions.
In the notebook we declare a Student case class with name, subject, major, school and year as members. The application is required to find out the number of students by name, subject, major, school and year.


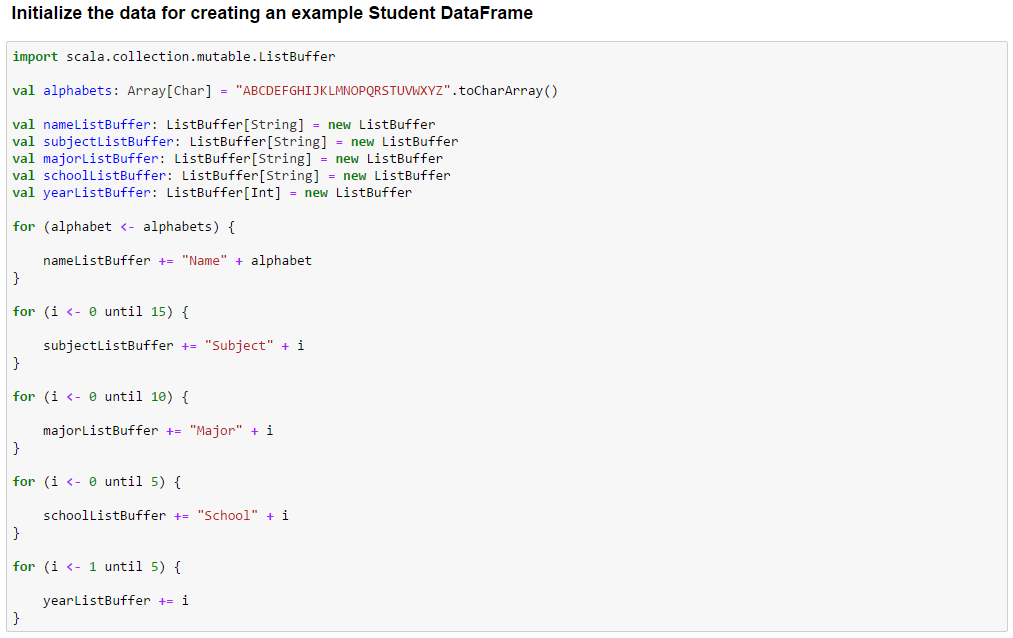
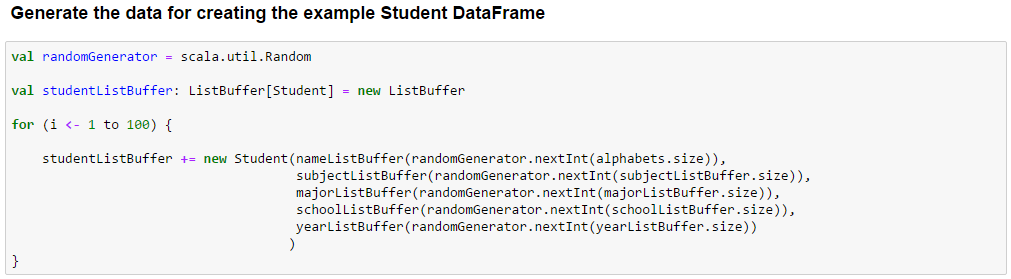
Initialize the Student data with 100 entries with 26 names, 15 subjects, 10 majors, 5 schools and 4 years and create the students DDF.

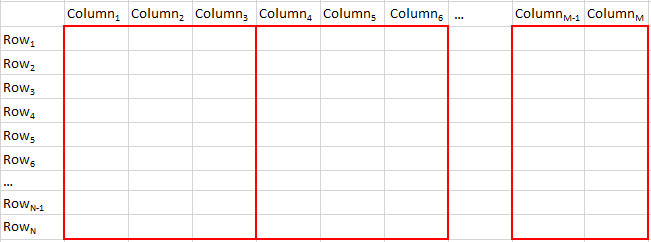
The first scheme is to partition the DDF vertically along column boundaries with each partition containing one or more columns along with the left over columns taken care of. Following is the schematic representation of this partitioning scheme:
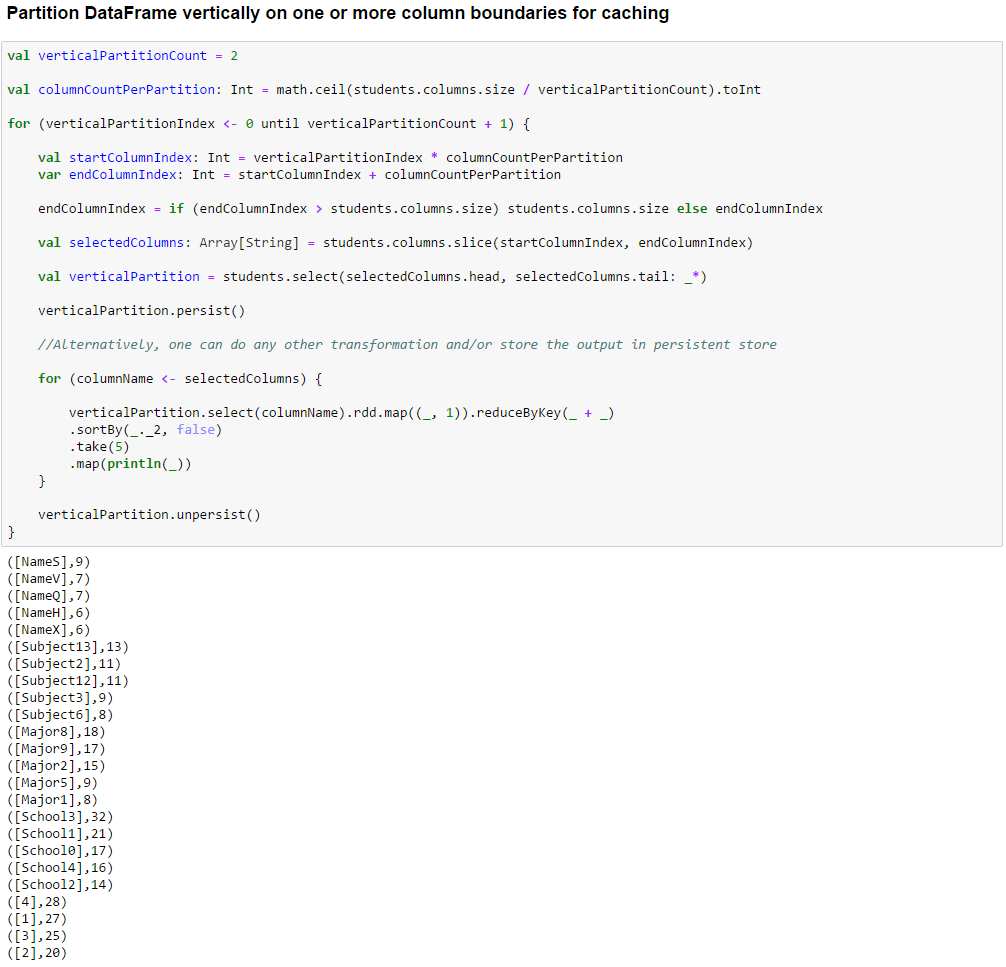
The idea is to persist (cache) a vertical partition into memory, compute the frequency of unique entries per column in the cached partition (or do some other transformation and action depending on the application), unpersist the cached partition, persist the next partition into memory and continue until all partitions are exhausted.
However, there may be situations when caching multiples columns in entirety is not possible depending on the data size and cluster resources. The second scheme is an extension of the first scheme that solves this problem by partitioning the DDF vertically across column boundaries and then horizontally along row boundaries. Following is the schematic representation of this partitioning scheme:
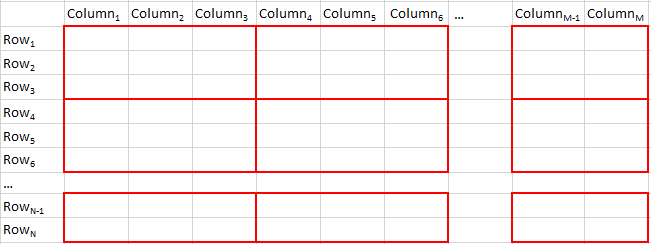
In both the schemes columns are chosen in each vertical partition by selecting ranges of names of contiguous columns. Since rows do not have any default identifier like names in DDF, a row index is added to each row of each vertical partition using the zipWithIndex method on the Resilient Distributed Dataset (RDD) underlying the DDF and then filtered on ranges of consecutive row indices. The idea here is also to persist (cache) a block partition into memory, compute the frequency of the entries per column in the cached partition (or do some other transformation and action depending on the application), store or union the results mapped to column names, unpersist the cached partition, persist the next block partition in the same vertical partition and continue until all the block partitions are exhausted and then move on to the first block partition of the next vertical partition.

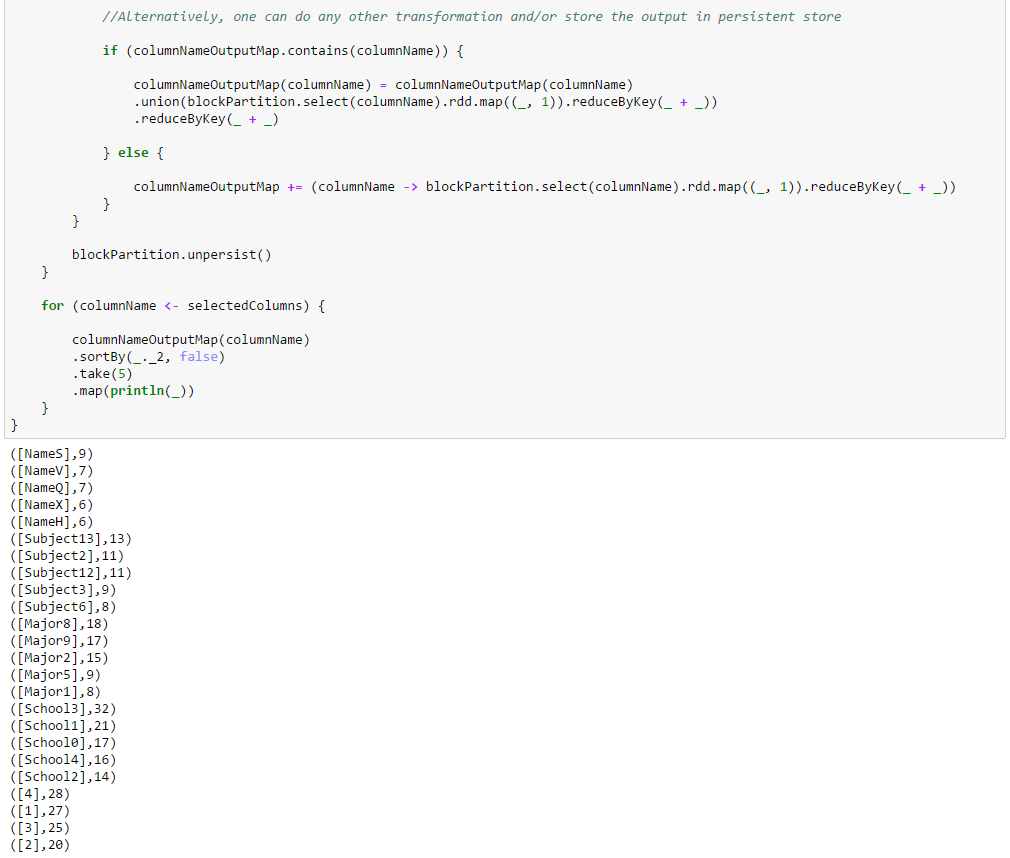
The correctness of the schemes can be verified in the result by comparing the number of students distributed over the years which add up to 100 as expected.
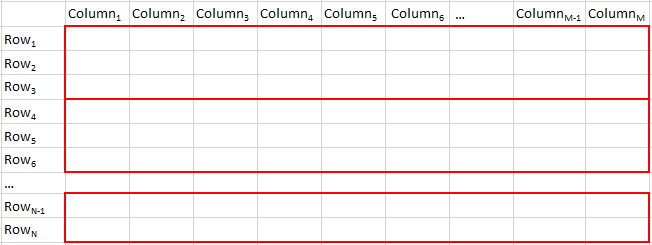
An extension of the second scheme can be to partition the data horizontally along row boundaries only as shown in the following schematic representation:
[Contributed by Arijit Tarafdar]