Windows Server 2008 and 2008R2 Failover Cluster Startup Switches
I am here today to discuss the troubleshooting switches used to start a Windows 2008 and 2008 R2 Failover Cluster. From time to time, the Failover Cluster Service will not start on its own. You need to start it with a diagnostic switch for troubleshooting purposes and/or to get it back to production.
In Windows 2003 Server Cluster, we had the following switches:

More detailed information on the above switches can be found in KB258078. However, the above switches have changed for Windows 2008 and 2008R2 Failover Clusters. The only switch that is available for Windows Server 2008 Failover Cluster is the FORCEQUORUM (or FQ for abbreviation) switch. The behavior differs from the FORCEQUORUM (or FO abbreviation) that was used previously in Windows Server 2003.
So for our example, let’s say we a 2-node Failover Cluster that is set for Node and Disk Majority. That means that we have a total of three votes. To achieve “quorum”, it needs a majority of votes (two) for fully bring all resources online and make it available to users.
In Windows 2008 Failover Cluster, when you tell the Cluster Service to start, it just immediately starts. The next thing it does is send out notifications to all the nodes that it wants to join a Cluster. It is also going to calculate the number of votes needed to achieve “quorum”. As long as there is another node running or it can bring the Witness Disk online, it will join and merrily go on its way. If there is not another node up and it cannot bring the Witness Disk online, the Cluster Service will start; however, it will be in a “joining” type mode. This means it will be sitting idle waiting for another node to join and achieve “quorum”. If this is the case, you would see something like this:
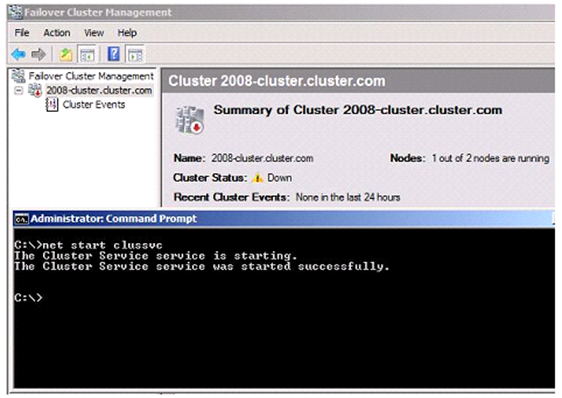
As discussed, we need at least 2 votes to achieve “quorum”. We currently have one node up, so we have one vote. The other node is down and the Witness Disk is unavailable which would account for the other two votes. But you can see that the Cluster Service itself is started. The reason it stays started is that is sitting there just listening for another node to join and give it a majority. Once it does, the Cluster resources will be made available for everyone to use. If you were to run the command to get the state of the nodes, you would see this:
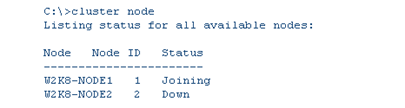
This is where the FORCEQUORUM switch comes into play. When using this, it will force the Cluster to become available even though there is no “quorum”. There are multiple ways of forcing the Cluster Service to start. However, please keep in mind that there are some implications when running this. The implications are explained in this article.
- Go into Service Control Manager and start the Cluster Service with /FORCEQUORUM (or /FQ)
- Go to an Administrative Command Prompt and use either:
- net start clussvc /forcequorum
- net start clussvc /fq
- In Failover Cluster Management, highlight the name of the Cluster in the left pane, and on the far right pane in the Actions column, there is a FORCE CLUSTER START option that you can select shown below.
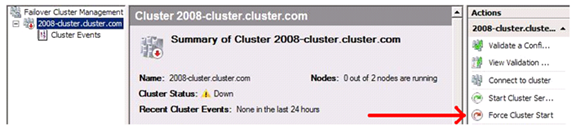
This switch differs from Windows 2003. When you use it on Windows 2003 Server Clusters, you must also specify all other nodes that will be joining while in this state. If I was to just use the commands above and not specify the additional nodes, the other nodes will not be allowed to join the Cluster. I would need to basically fix the problem of the other nodes not being up, then stop the Cluster Service and start it again without the switch. This causes downtime and no one wants that. In Windows 2008 Failover Cluster, the switch will remain in effect until “quorum” is achieved. All you would need to do is start the other node Cluster Service and it will join. Once “quorum” is achieved, mode of the Cluster dynamically changes.
In Windows Server 2008 R2 Failover Cluster, there is the same FORCEQUORUM (or FQ) switch as well as a new switch.
This new switch is /IPS or /IgnorePersistentState. This switch is a little different in what it does. What this switch does is to start the Cluster Service as well as make the resources available; but, all groups and resources will be in an offline state.
Under normal circumstances, when the Cluster Service starts, the default behavior is to bring all the resources online. What this switch does is ignore the current PersistentState value of the resources and leave everything offline. When you go into Failover Cluster Management and look at the groups, you will see all resources offline.
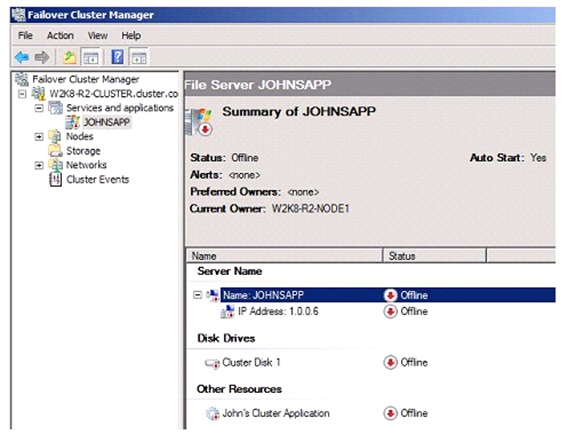
I do need to bring up a couple of important notes about this switch.
- The Cluster Group will still be brought online. This switch will only affect the Services and Applications groups that you have in the Cluster.
- You must still be able to achieve “quorum.” In the case of a Node and Disk Majority, the Witness Disk must still be able to come online.
This switch is not one that would be used that often, but when you need it, it is a blessing. Here are a couple of scenarios where the /IPS switch would come in handy.
SCENARIO 1
I have a Failover Cluster that held the limit of 1000 Hyper-V Virtual Machines. If you are trying to troubleshoot an issue, you can use the switch and then manually bring online only a couple of them. Do whatever troubleshooting you need to accomplish without the stress that all these machines coming online would put on the node. Once your troubleshooting is complete, you can then start the other nodes, bring the other virtual machines online, go about your business, etc.
SCENARIO 2
I am the administrator of the Failover Cluster and get called that my Cluster node that holds the John’s Cluster Application resource is in a pseudo hung state. Both Explorer and Failover Cluster Management hang up while the rest of the machine is real slow. If I try and move this group over to another node, that node experiences the same problems and errors. So I reboot them and when the Cluster Service starts, the machine goes into this pseudo hung state again. Looking through the event logs, I see that the Cluster Service starts fine. But I do see that John’s Cluster Application is throwing errors in the event log and those were the last things listed. I do some research on the errors and see that it is caused by a log file this application uses as being corrupt. All I have to do is delete this file and the application will dynamically recreate the file, start fine, and no longer hang the machine. That seems simple enough. But wait, I do not have access to the Clustered Drive that this application is on as Explorer hangs and I also cannot get to it from a command prompt.
In the days before Windows 2008 R2 Failover Cluster, I would have to:
- Power off all other nodes.
- Set the Cluster Service to MANUAL or DISABLED
- Disable the Cluster Disk Driver
- Reboot this machine
- Delete the file
- Re-enable the Cluster Disk Driver
- Set the Cluster Service to AUTOMATIC and start it
- Power up all other nodes
The above was the only way I was going to be able to get access to the drives. Something like this can be painful and time consuming. If the nodes take about 15 minutes to boot because of the devices and the memory, it just adds to the frustrations.
This is where the /IPS Switch comes in. Your steps would now be:
- Stop the Cluster Service on all other nodes
- Reboot this one node since it is hung
- While that node is rebooting, on the other node, start the Cluster Service with the IPS Switch:
- Net start clussvc /ips
- Go to the group that has the disk
- Bring the disk online
- Delete the file
- Bring the rest of the group online
For those who like to see stuff on MSDN, you can get a little more information on the /IPS switch here.
So as a recap, these are the only switches available for Windows Server 2008 and 2008 R2 Failover Clusters.

The switches can make things easier, less frustrating, and causes less downtime. This can mean production/dollars lost are more at a minimum and that makes everyone happy.