MIM Handy Tip Series - Breadcrumbing
Everyone put your phones down and get your pencils ready.
It's Pop Quiz time!
If Kris Tackett and Anthony Marsiglia are given equal precedence for the knowledge
attribute as they are the creator's of this blog and I possess the NULL gene - who wins?
Did you figure it out..
Ok, that was a little bit of sly nerd humor mixed in with a portion of the truth with MIM configuration, yet truly I have to yield to these two great colleagues and friends as they have recently have asked me to share some ideas I have for helping the MIM and IdM community at-large.
So I am quite honored and blessed to be able to add some content to this on-line resource.
Therefore, this is my 1st post that I am going to call "MIM Handy Tip" series. This series will highlight some of the configuration items, ideas, or other handy tips and tricks that have been shared with me or that I have found within my research and experience with FIM/MIM. Of course, these bits of info may not apply to every situation and environment but they can be quite handy.
Please keep in mind that a few disclaimers have to be made as this is a way of documentation these days:
1) This is not an exhaustive list as this document will be a "living" document that will continue to evolve
with adds, deletions, changes, etc.
2) This list will not solve every MIM situation or the world. Your mileage may vary so use with knowledge of
your environment.
3) I welcome feedback to add to this list from real-world experiences that you have had within your own MIM-world, though
keep in mind that all of us contributors of this blog reserve the right to add, not add, or change any info/submissions
in order for clarity, efficiency, relevance, etc.
4) As there are numerous ways to code a scenario or drive to the next COS-play event, there could be a few methods to handle
a situation so semantics within a small range is accepted if done respectively.
Without further adieu, here is a concept called "breadcrumbing". This is not a new concept though it is another great trick to help save time later as any time you can change a manual process into an automatic one
In a disparate MIM world, when you have multiple data sources, those systems don't always have the same attributes for each unique user/object and usually one is typically "more correct" (i.e. authoritative) then the other. In order to correctly affect a join automatically, you typically want to have a join rule that matches on a unique attribute value. Quite a bit of the time this is EmployeeID or a similar 1:1 user/object to unique value relationship. Also, in the real world you might have to use manual joins and this is not the most efficient manner of MIM as this identity technology works best when all is auto-magically running without user-intervention (as much as possible). Morevoer, because each connected data source (CDS) should add value to your MIM environment and the fact that the system needs itself to be updated for better data integrity - thus this source data may only be "acceptable" for joins until the CDS has better data consistency. Lastly, though "breadcrumbing" is a great way to handle the transition from "manual joins" (i.e. explicit connector) to "automatic joins", you don't necessarily have to enable this as you could just use a one-time use concept where you are only updating information for the objects in scope to at least have more attribute information than you had before but of course you as the system engineer should be striving for more and then this is just one more item within your arsenal.
TL, DR - Reason why we "breadcrumb": 1) Save sysadmin time and 2) data integrity.
Here is a diagram for your reference, though I will explain the steps to detail out the concept.
[caption id="attachment_9545" align="alignnone" width="909"]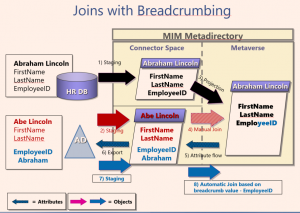 Joins with Breadcrumbing[/caption]
Joins with Breadcrumbing[/caption]
Step 1: HR DB - Normal "Full Import (Stage Only)" run where you are importing and staging within the CS the objects and attributes configured as part of the HR DB MA
Step 2: AD - Normal "Full Import (Stage Only)" run where you are importing and staging within the CS the objects and attributes configured as part of the AD MA
Step 3: Normal projection into the MV since there was not any join criteria that was matched upon review
Step 4: In this case since the user/object was already within the MV and in this case since we want EmployeeID as our anchor, i.e a reliable "breadcrumb" attribute value. This is noted in partial blue because this attribute flowed in from the HR DB, yet it is now going to be associated with the AD CDS as the flow arrows show.
Step 5: We want to flow out this value so that we can use it again upon future imports and sync runs so in this case we want a "full sync" and not a delta so that export attribute flows can happen.
Step 6: Normal AD MA-based export run where we are flowing out the EmployeeID as well as the corrected FirstName to the AD CDS. Keep in mind that this data source (not typically with AD, but can happen with other CDS's) might not support this new attribute so make sure to do your research when flowing export attributes. Case in point, file-based MA's where you might not be able to flow an export as easily. This, by the way should be shown as "updates" within the Synchronization Service Manager's bottom-left pane.
Step 7: Upon future imports (as indicated in this step and normally as a confirming delta import if available with your CDS), we now show that we have the corrected FirstName as well as the new EmployeeID attribute which means that step 8 is now possible without user-intervention.
Quick note: In order for elimination of confusion for new sysadmins, and only by acceptable business policy, it may make sense to delete the connector space (CS) for the MA associated with the CDS. In this example, AD before Step 8, there might be confusion for new sysadmins with respect to why a connector filter works for some users and not for others since, as previously mentioned, any manual join-based objects are considered explicit connectors and may not be affected by filter connector rules. It goes without saying to be careful when deleting connector spaces.
Step 8: The icing on the cake so to speak - upon a delta (or full) sync, the objects will now automatically join based on this "breadcrumb" value, in this case EmployeeID, and future joins will now be automatic if a change is detected for that user/object, if necessary.
A couple final notes:
- If you choose to delete the connector space prior to step 8, you will need to perform a "full import" and a "full sync" to re-establish data integrity.
- Make sure that attribute flow precedence is indicative of its respective source
Though all this being said, the best medicine for MIM is to correctly establish data-integrity. In this case, to train the data entry users of each data source to correct apply best-practices of data standardization, usually in the form of some sort of format integrity policy, i.e. a data dictionary, reference standard, naming convention, etc.
Lastly, did you figure out the answer. Feel free to leave your answers in the comments.
By the way, does anyone still use pencils anymore for tests?
Take care and see you in the MV aka holodeck if you are a Trekkie.
Mr. NULL (CurtusR)