You need a Data Asset -- not a Data Warehouse
Last Friday, I had a chance to speak, along with Dr. Craig, to a pretty cool group of folks in Washington DC about how we think about creating data-centric assets, and why we think it's important to inject some new concepts into our national conversation about healthcare quality and research. It was a good conversation, and it seemed like there were at least a few "a-ha" moments for people over the course of the day (myself included).
That evening, as we sat on the tarmac at Dulles awaiting our second de-icing in a last-ditch attempt to get out from under the big storm, it occurred to me that I hadn't ever really written about this, and that perhaps I should do that while I was stranded in the airport terminal over the weekend. As it turns out, we made it into the air and I spent a much more entertaining weekend at home watching Avatar (awesome) and enjoying holiday meals at Elephant and Castle (bangers and mash) and Artisanal Brasserie (pork belly hash). But now I'm back at work - so time for a few thoughts.
When we talk about Amalga UIS helping to create data assets - what are we really talking about, and why is it any different than a traditional data warehouse? Glad you asked!
All the data...
A data asset is a collection of all the information relevant to an organization, regardless of source and of type. We call it an "asset" because this data, not the systems that created it or that are used on any given day to interact with it, represents the true long-term capability of an organization to thrive. The potential of that organization to measure itself, to learn, to adapt to new situations and technologies, to predict future outcomes and improve operations, all rely on its ability to find, use and re-use data.
This is what Amalga does - it captures all the information, and stores it in data atomic form. "Data atomic" means that rather than try to selectively normalize incoming data elements into some predetermined information model, we simply capture them exactly as they arrive - and save every scrap of metadata that comes along with them in self-contained "data atoms." By doing this, we ensure that we never lose fidelity, history or context.
In contrast, a traditional data warehouse makes its judgments at ingestion time about what attributes are (or are not) important, and normalizes the information "up front" in an attempt to create a cleaner and more easily queried data set. We just flat out think this is the wrong choice - because the time you receive information is the worst possible time to lock down and limit how it can be used.
Instead, the right time to make decisions about data structure and normalization is "just in time" - when specific information is going to be used for a particular purpose. That purpose will dictate which elements are important or valid, and what kinds of transformation or normalization need to be applied. The key is to realize that the "right choices" will change from use to use and day to day; unless you've retained the full-fidelity, original data and meta-data, you can never be prepared for the next question you run into down the road.
This makes some people really uncomfortable. Data in the repository could be contradictory, or maybe there's information in there that can't be translated into this or that coding system. And for sure that's going to be true, but the alternative - frankly, willful ignorance -- is a whole lot worse. In the Amalga case, you've at least got a full representation from the best sources of truth available. You can do queries on that data, present it to users to be interpreted, and generally use it in a lot of ways, even in its "messy" state. And when or if the time comes for you to do a particular normalization pass, you still have all the raw information you started with - so you can do at least as a good a job as you could have back when you first received the information. With a traditional data warehousing approach, if it doesn't fit some incomplete preordained model of the world - onto the floor it goes.
In Real Time...
Another key attribute of a data asset is population in real time, message by message - rather than by batch process. Pivoting an organization to be truly data-driven demands an understanding of how things are going right now - not how things went over the course of the last quarter. A fully-leveraged Amalga data asset is a central part of daily operations, feeding worklists on the floor, raising alerts when service levels drop below acceptable levels, delivering images and reports back to folks who are waiting for them, and driving quality dashboards that point the way towards action, not just reflection.
This demand for real time information needs to extend beyond the walls of our institutions as well. The nation is defining a set of "meaningful use" outcome and quality metrics that will become the yardstick we use to understand how we're doing, what works - and what does not. Why should we accept a world where we fly "blind" until institutions report their aggregated numbers every quarter? We need a national data asset - there is no reason we shouldn't be able to track granular outcomes on a real time basis - and catch events like regional e-coli outbreaks within hours rather than weeks.
And Fast, too!
Of course, the astute reader is screaming out that one big trick remains. Holding all this data, in its original form, with all its metadata - how do you possibly answer questions with acceptable speed? After all, EAV tables and variant columns don't lend themselves to great performance in the real world.
Amalga handles this by leveraging the fact that - when you've got all the original data - you can "extrude" as many different transformations of that information as you need. Today's reality is that storage is cheap - really cheap - so we've solved this problem by creating a pipeline that allows data to be cast and re-cast as needed to deliver performance to support any type of query.
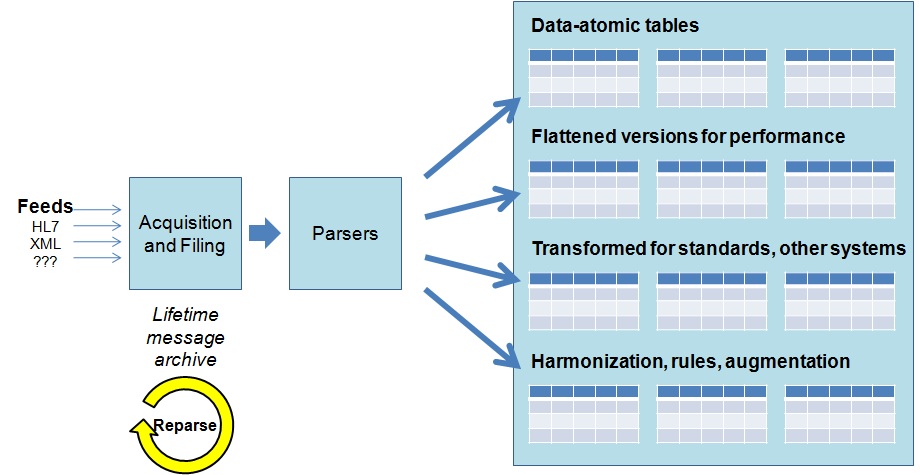
That "re-casting" is the critical piece. Like everything about Amalga, performance optimizations are flexible and "just in time." Query patterns evolve over time - and the pipeline process makes it super-easy to go back to source data and create new views, pivots and transformations to support those evolving needs.
I am really proud of the products we've created and assembled here in Health Solutions. "Connected Health" is exactly the right approach for the nation, and it's one that Microsoft has the right DNA to deliver on. Comprehensive Data Assets are a central piece of that connected story - and when you see things start to fall into place and the usage goes viral - you just know you're on the right track.