CosmosDB change feed processor 2.1 released (monitoring enhancements)
There is new version of CosmosDB Change feed processor library released, version 2.1 and two main enhancements are:
- Upgrade to Microsoft.Azure.DocumentDB 2.0 nuget package
- Extensions to the monitoring
Microsoft.Azure.DocumentDB upgrade
The change feed library was built against latest SDK 2.0. Short! New SDK version brings several improvements and one of the most important change was the new multiplexing connection model. More about it in future blog post.
Extensions to the monitoring
When you take change feed processing seriously, I mean, production ready, you need to be sure that the processing of the feed is working as expected. You need to be sure that "the feed is flowing" which means the feed is in progress and as soon as there is a document change (insert, replace), the change feed processor receives it.
I wrote about the monitoring in my previous post. The whole monitoring is built on so called "remaining work estimator" which estimates the number of the documents till the end of the feed. There was an improvement introduced into the library.
It's possible to get the estimation per partition now! Why does it matter? Because it give you better visibility into the system. You are able to see what partition is left behind and how far.
Let's see how to create the remaining work estimator instance:
And let's see how to use it:
And that's the result:
Real life scenario
I'm working on the event sourcing system powered by CosmosDB (I'll be writing about it in the future posts) and we are heavily dependent on the change feed. We need to be sure the system works 24/7. We need to be prepared for failures also when using change feed. In this case when a partition processing is stuck. So, we are monitoring change feed on several levels.
Who process what
We monitor what process consumes what partition. In other words, we are able to say what process is consuming what partitions. In practice, we record the following metric: data center, role, instance id, database account, partitions.
What's the estimated work left to process
We have a runner which runs periodically and reports what is the estimated work left per account/partition. That's the input for the graphs and alerting. It is built on top of the estimator shown in this post. If any estimated work hits a limit, it means we have a problem with "stuck" partition.
See the graph of the simulation from our test environment:
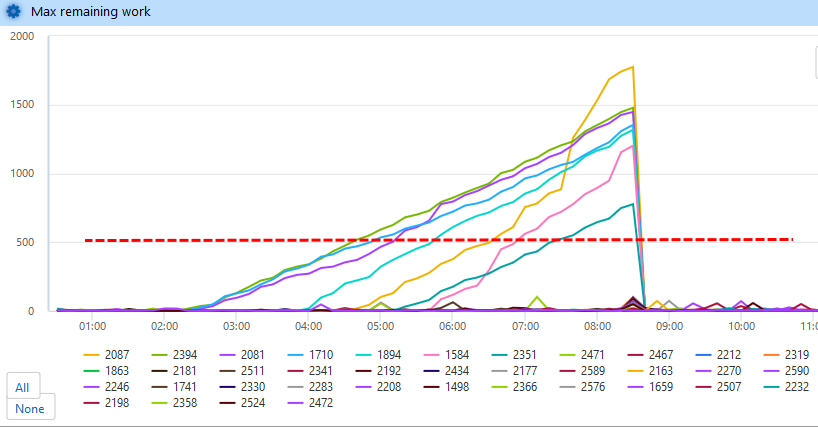
The red dotted line is an alert level. Once we are alerted, we are able to see what partitions are stuck. Because we record who process what, we are able to find out the instance which was processing the partition last time and diagnose the issue.
That's all for now, happy monitoring!
Previous posts: