What is in the Power Tools v1.0 release?
For those of you who have been paying close attention, you know that August 6th is the date I promised the first Power Tools to be released. So where are they?
We are not there yet, we released the first release candidate today, I need to finish two more threat models and then we are ready to rock & roll, so it will be this week, better be because I am going on vacation for 3 weeks and I promised my boss it will be done before I leave. So please be patient a little bit longer, it will not be long before you can enjoy these great new tools.
Which Tools?
So here is a list of the new features and functionality we are adding, most of these you have been asking us for, so here it is, no need to wait for a completely new release.
- Dependency Viewer
- Refactoring
- Move Schema
- Expand Wildcard
- Fully Quality Name
- Refactor in to strongly typed DataSet definitions
- Refactor Command Generator
- Data Generation
- Sequential Data Bound Generator
- Editors for the Data Bound Generator, Sequential Data Bound Generator and RegEx String Generator to make configuration easier
- The RegEx editor also tries to interpret your CHECK CONSTRAINTs and create a matching RegEx expression that you can use to generate data values that match the constraint definition
- The RegEx editor can also be used for interactively defining and testing RegEx expressions and evaluate the output visually, which makes it a lot easier to create the right RegEx expression for your value domain.
- MSBuild Tasks
- SqlSchemaCompareTask; allows you to compare schemas between two database from the command line using MSBuild.
- SqlDataCompareTask; allows you to compare the content of tables within two databases from the command line using MSBuild.
- T-SQL Static Code Analysis
- Miscellaneous tools
- SQL script pre-processor command-line utility, which will expand all SQLCMD includes and variable definitions (sqlspp.exe)
- Schema Manager API
A More Detailed Look
Dependency Viewer
The Dependency Viewer is a new tool window that can be accesses by right clicking on a node inside Schema View and choosing the "View Dependencies" option. This will bring up the Dependency Viewer tool window. The dependency viewer shows the internal graph/dependency chain maintained internally, which is build up when we load the project and parse all the schema objects inside the project.
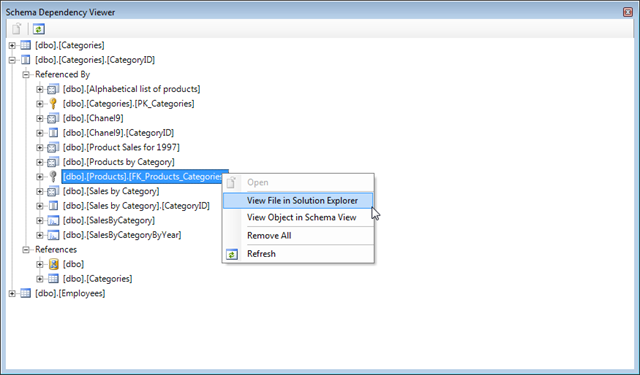
The viewer shows which objects are "Referenced By" and "References" the object you selected. You can also drag objects in to the viewer, or continue to right click "View Dependencies" on objects, the viewer remembers which objects you selected. Right clicking on an object in the viewer will bring up an context menu that allows you to select the object inside "Solution Explorer", "Schema View" or open the object inside the T-SQL editor by using the "Open" command. The "Remove" command will remove the object selected from the viewer (this will not remove it from the project), "Remove All" will remove all objects from the viewer. Refresh re-queries the internal schema manager for any updates.
Refactoring
Refactoring is a huge feature of VSDBPro! It really shows the abilities of the product and the power gained by understanding the relationships between all schema objects and the definitions of each schema object. When we shipped we purposely limited ourselves to rename refactoring, instead of adding more we added an extensibility mechanism that allows us to add new refactoring types and targets out-of-band, through Power Tools or other means.
So here is the first set of additions to refactoring:
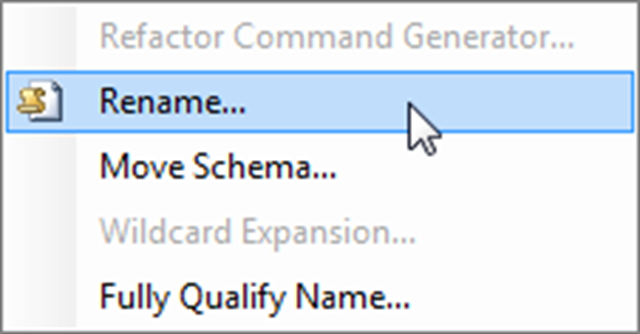
New refactoring types
- Move Schema; this allows you to move an object between existing schemas
- Wildcard Expansion; this will take any SELECT * and convert it in to a properly defined column list, if the table or view is referenced through an alias we will use the alias the properly expand the column list otherwise we propend the fully qualified table or view name
- Fully Qualify Name; this will fully qualify each object reference, this disambiguates the your query statements completely
A new refactoring target
- We are adding a new refactoring target, namely strongly type DataSet definitions. If you have a solution (.SLN) which contains a database project (.DBPROJ) and a VB.NET or C# project which itself contains a strongly type DataSet definition (which is an XSD at the end of the day), we will refactor in to the strongly type DataSet definition if the refactoring touches an object used in the DataSet.
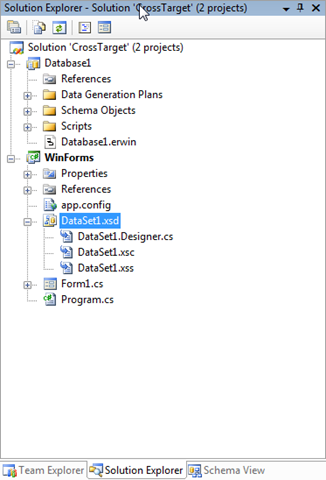
In this example we have a solution with a C# project that references the Customers table, however the Last Name column contains a space which is inconsistent so we will use rename refactoring to remove the space.
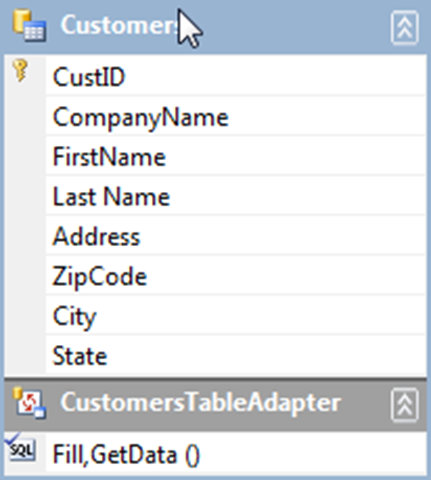
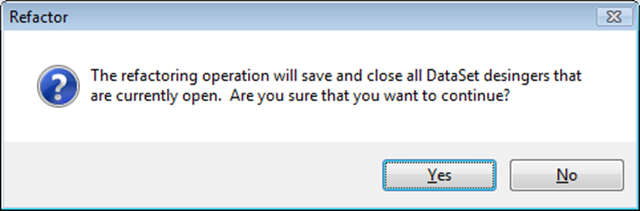
If the DataSet designer is open, refactoring will cause the following dialog to appear, notifying you we are going to evaluate the content of the XSD.
The refactoring preview windows will show you the following results
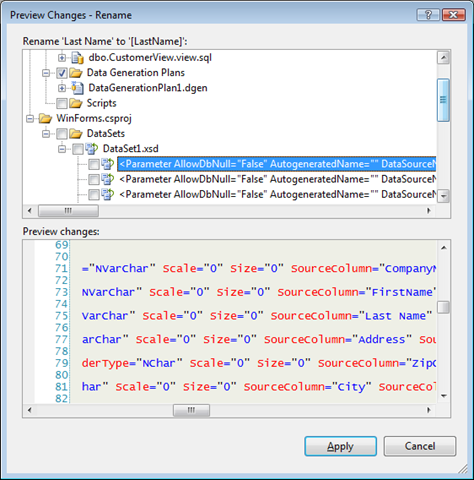
Note that the DataSet is not by default included as a refactoring target, you need to opt-in to propagate the changes in to the DataSet. When you select the DataSet we will only update the XSD, not your C# or VB.NET code, so your application will recompile and work, but for example text labels inside your code might be mismatched. Anyhow this is a great preview of where we are going with the product and our desire to bridge the gaps between the application and data tier developers.
Refactoring Command Generator
You might know that every time you perform a refactoring operation we create a log file, which describes the type of operation that you performed, on which object, what the exact change was and which other objects were affected. The log files live in the "Refactoring Logs" directory in your project directory, if you select "Show All Files" in "Solution Explore" you will see them as well.
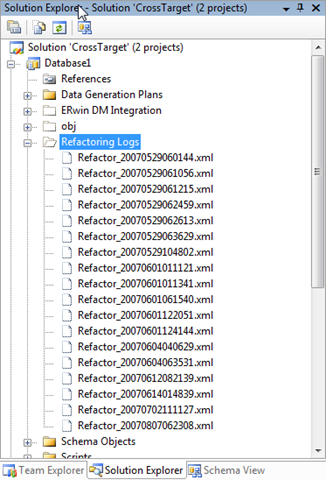
We added a tool to use these log files and extract useful information out of them. For example of you renamed an object the build system will not create a rename operation, since in time it can not distinct a DROP/ADD column of the same type from a renamed object. Using the refactoring logs we preserved the intend of the user. The Refactoring Command Generator tool will take these logs and create deployment statement that reflect the operation of the user. So a rename of a table or column will be reflect through sp_rename, a move schema will be reflected through a ALTER SCHEMA TRANFER.
The Refactor Command Generator is available through the standard refactoring context menu and through the Data->Refactoring menu. There is also a command line version named RefactorCmdGen.exe which lives in the %ProgramFiles%\Microsoft Visual Studio 8\DBPro directory.
Data Generation
We added a new generator named the "Sequential Data Bound Generator", the big difference with the Data Bound Generator is that, this one only has a single row in memory at a given time and rows are dispatched in the order they are retrieved from the query results. The Data Bound Generator uses the query to fill a dictionary, holds this in memory for the duration of the generation and randomly select values from the dictionary.
To make configuration of the hardest generators a bit easier we added editors for the Data Bound, Sequential Data Bound and RegEx String generators. The editor manifest themselves by adding ... at the end of the row in the Column Details window.
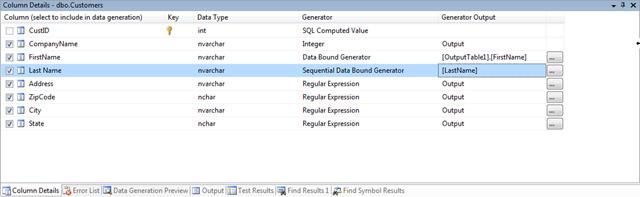
The data bound generator share the same editor, which allows you to select the connection and enter the query (sorry no query builder yet).
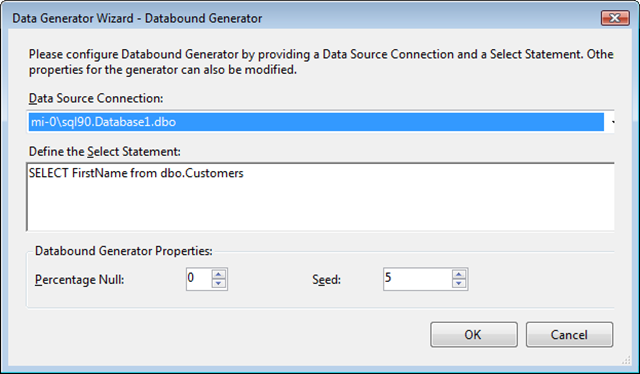
The RegEx editor is more advanced.
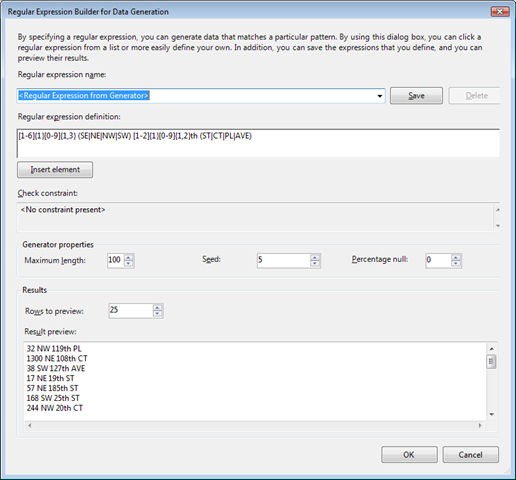
It shows the expression and creates sample output, so you can validate the results. You can also select from a set of predefined expressions and add your own. The editor is also capable of interpreting CHECK CONSTAINTS and propose a matching expression that meets the value domain definition defined by the constraint.
MSBuild Tasks
We added two MSBuild tasks to perform schema and data comparisons from the command line.
- SqlSchemaCompareTask; allows you to compare schemas between two databases.
- SqlDataCompareTask; allows you to compare the content of tables and views within two databases .
T-SQL Static Code Analysis
One of the biggest features we are adding is T-SQL Static Code Analysis, like refactoring it build on top of our ability that we fully understand all object definitions and relationships, which allows us to perform cross cutting analysis over your schema. For example we can detect that a column is defined as an INT, a variable of a stored procedure as REAL and that you are assigning the column value to the variable, therefore incurring the cost of an implicit conversion. Rule: "SR0014: Maintain data type compatibility" will warn you for these kind of occurrences.
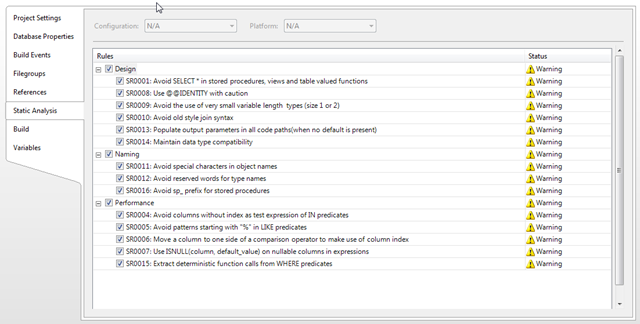
You can configure the rules used in the new project property page named "Static Analysis", you can determine which rules to include and if you want to threat them as warnings or errors. You can suppress warnings/errors by right clicking on the line in the Error List, and choosing Suppress Message(s), this will add the objects in to an XML file named StaticCodeAnalysis.SuppressMessages.xml which is added to your project when you add the first suppression. In order to run the static code analysis, you choose Data->Static Code Analysis->Run. This will run each rule selected and report the results in the Error List.
In the current implementation we do not allow you to write your own rules, in the Rosario release this will be enabled, for now send me email through the link in this blog to make your desired rules known. We will update them frequently, right now we have about 82 rules defined, you find the first 15 in this release, we have about 15 more to come to you shortly. An other limitation is that you can only run static code analysis from the IDE, there is no command line or MSBuild equivalent, this will also be solved in the Rosario release.
Miscellaneous tools
In order to use build scripts generated with VSDBPro with tools that do not understand SQLCMD variables and or include file, we added a simple command line tool that pre-processes SQL scripts and expand all includes (:r) and SQLCMD variable references. (sqlspp.exe)
Schema Manager API
The last part of the Power Tools is a small but very powerful API that provides access to the internals of the system, called the Schema Manager. This API can be used to add, update, delete schema objects to the system, to enumerate schema objects and files. This API is used by Computer Associates (CA) to integrate ERWin 7.2 with VSDBPro so you can make changes in ERWin and store them schema definition inside a database project. See https://ca.com/us/content/campaign.aspx?cid=144449 for more details on the ERWin integration.
That is it!
I hope there is something in here you like, please continue to send me your feedback, good or bad.
Thanks,
-GertD
"DataDude" Software Architect