What’s in a(n Identifier) Name?
Unicode serves as the basis for the char data type in many modern programming languages, including Visual Basic .NET and C#. So what type of local language support do programming languages and frameworks need to provide? Support for international string literals is a given. But should programming keywords and syntax be localized? Or is it sufficient to enable international character use in code identifiers? Microsoft has generally taken the latter approach. This article describes the capabilities of the .NET Framework and Visual Studio when working with international code identifiers.
Common Language Specification Identifier Grammar
The Common Language Specification (CLS) for the .NET Framework states that code identifiers can consist of any character defined within Unicode 3.0. This includes Unicode Extension A (Ext A) characters [U+3400 through U+4DB5]. It does not include Unicode Extension B (Ext B) characters [U+20000 through U+2A6D6], as these were first assigned character data in Unicode 3.1.
CLS Identifier Syntax {allowed Unicode character categories}:
<identifier> ::= <identifier_start> ( <identifier_start> | <identifier_extend> )
<identifier_start> ::= [ {Ll} {Lm} {Lo} {Lt} {Lu} {Nl} ]
<identifier_extend> ::= [ {Cf} {Mc} {Mn} {Nd} {Pc} ]
For the full definition of CLS-supported programming language identifiers, see Annex 7 of this report.
For the full list of Unicode 3.0 character categories, see Table 4-5 in this PDF file.
See this MSDN topic for the .NET Framework 4 character classes.
It should be noted that many characters fall into categories other than those defined in the above syntax. Examples:
Character |
Code point |
Unicode category |
Allowed as identifier? |
༉ |
U+0F09 |
Punctuation Other {Po} |
No |
྾ |
U+0FBE |
Symbol Other {So} |
No |
① |
U+2460 |
Number Other {No} |
No |
ิ |
U+0E34 |
Non-spacing Mark {Mn} |
Extend only |
The result is that this table's characters categories and Ext B code points, while present in Unicode 3.0, are not recognized as valid identifiers by CLS-compliant language parsers or compilers. In fact, any attempt to include Ext B characters in Visual Studio managed code project or item names results in the following warning dialog:
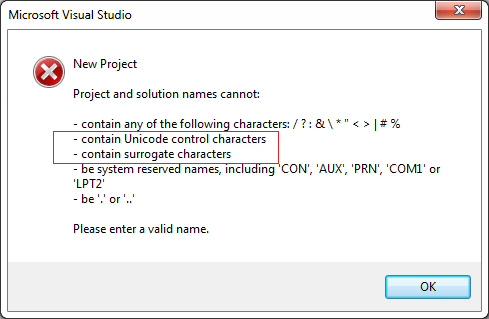
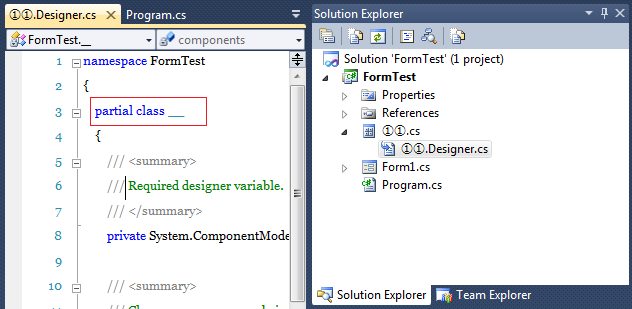
You can use characters from CLS identifier non-allowed categories to name projects or items, but the characters in any resulting object names are replaced with underscores. In the following example, I've used Visual Studio's New Item dialog to add a UserControl named '①①'. The resulting class name is a pair of underscores: '__':
Using the Visual Studio Code Editor, I attempt here to define an identifier using an Ext B character (in this case, U+200A4):
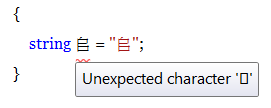
The result is a red squiggly line displayed under the identifier, signifying a syntax error. Placing the mouse pointer over the squiggle prompts the message, "Unexpected character '□'". Additionally, the following three entries appear in the Error List window:
- Unexpected character '□'
- Unexpected character '□'
- Invalid token '□' in class, struct, or interface member declaration
The language parser interprets the character as two code points - U+D840 and U+DCA4. Because these code points are unassigned in Unicode 3.0, the parser cannot recognize them as a valid token. (The character doesn't render properly in the tooltip because of failed font association - the topic of another article.)
The same warning is displayed when I attempt to name an identifier using a character from Unicode's Number Other {No} category:
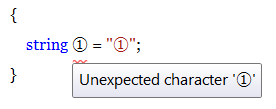
Note that in both cases, the string literal is valid, as literals can consist of any range of Unicode values.
You can also successfully name the identifiers using any Unicode 3.0-defined character falling within the CLS-allowed categories for identifiers. Examples:

[ Reader bonus quiz: Who can name the five languages listed here? ]
XAML Name Grammar
Although XAML is based on Unicode 5.0, it's more restrictive than the CLS with respect to Unicode character categories. Unlike the CLS, XAML doesn't allow {Lm} characters (Letter, modifier) in the name start position and doesn't allow {Pc} (Punctuation, connector) or {Cf} (Other, format) characters in the extended name.
XamlName ::= NameStartChar (NameChar)*
NameStartChar ::= LetterCharacter | '_'
NameChar ::= NameStartChar | DecimalDigit | CombiningCharacter
LetterCharacter ::= [ {Ll} {Lo} {Lt} {Lu} {Nl} ]
DecimalDigit ::= [ {Nd} ]
CombiningCharacter ::= [ {Mn} {Mc} ]
See this MSDN topic for the full definition.
The impact for WPF and Silverlight developers is that custom controls names in these projects are limited to the character categories listed above. In fact, it's possible to create a valid VB .NET or C# custom control whose name is subsequently unrecognizable by the XAML parser. While this is a corner case, it's something to be mindful of when experimenting with Unicode identifiers.
XML Name Grammar
XML name grammar differs from both CLS and XAML. Appendix B of the Extensible Markup Language (XML) 1.0 (Fourth Edition) defines which character classes from Unicode 2.0 can be used in element and attribute names. As Unicode 2.0 predates all Unicode extensions, neither Extension A nor Extension B characters can be used.
XML 1.0 4th Edition Name Syntax:
<name> ::= <name_start> ( <name_start> | <name_extender> )
<name_start> ::= [ {Ll} {Lo} {Lt} {Lu} {Nl} ]
<name_extender> ::= [ {Lm} {Mc} {Me} {Mn} {Nd} ]
See this W3C recommendation for the full definition, including caveats.
Note that this isn't the latest edition of XML or even of XML 1.0. I call it out here because it's the version that is used by the XmlLite control to validate XML document elements and attributes. XmlLite is used by multiple Visual Studio native code components to parse XML. The documents that those components use XmlLite to parse must follow the more restrictive grammar.
Question to this blog's readers:
Have you or any of your colleagues used non-ASCII characters when defining code identifiers or XML/XAML names? If yes, would you mind sharing your experiences in the comments? If you prefer, you can also send email to MSDDGDX at LIVE.COM.