How to create a SQL Server Linked Server to HDInsight HIVE using Microsoft Hive ODBC Driver
Last October 28th Microsoft finally released a new Azure service called “Windows Azure HDInsight Service”, that is our Hadoop offering in the Cloud:
Announcing Windows Azure HDInsight: Where big data meets the cloud
Along with this core service, a series of additional components has been also released to integrate Big Data world with Microsoft BI stack familiar tools and on-premise technologies, the most important one is a new ODBC driver that will permit connection to Hadoop HIVE:
Microsoft® Hive ODBC Driver is a connector to Apache Hadoop Hive available as part of HDInsight clusters.
Microsoft® Hive ODBC Driver enables Business Intelligence, Analytics and Reporting on data in Apache Hive.
You can download the driver from the link below:
Microsoft® Hive ODBC Driver
http://www.microsoft.com/en-us/download/details.aspx?id=40886

This driver can be installed on 32bit or 64bit versions of Windows 7, Windows 8, Windows Server 2008 R2 and Windows Server 2012 and will allow connection to “Windows Azure HDInsight Service” (v.1.6 and later) and “Windows Azure HDInsight Emulator” (v.1.0.0.0 and later). You should install the version that matches the version of the application where you will be using the ODBC driver. Both packages can be installed on the same machine if you need both versions of the driver; they are installed, by default, on different paths:
- 32bit: “C:\Program Files (x86)\Microsoft Hive ODBC Driver”
- 64bit: “C:\Program Files\Microsoft Hive ODBC Driver”
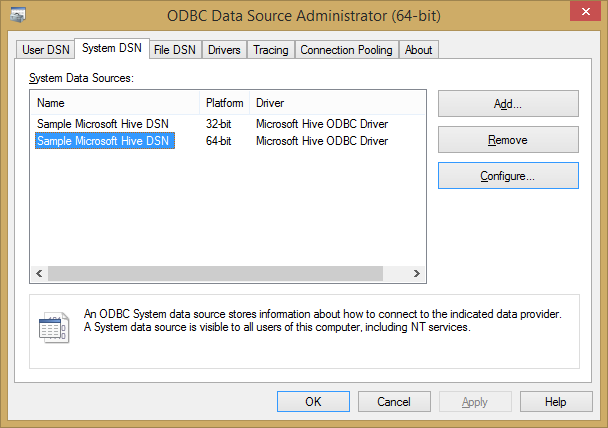
Depending on the version installed, you may need to use a different version of ODBC Data Source Administrator, the 32-bit version (“odbcad32.exe”) is located, on a 64bit machine, inside “C:\Windows\SysWOW64” location. On Windows 8/2012 Server, you can find the right version easily using the “Search” function:

In case of version mismatch between SQL Server and ODBC driver, you will receive an error message as reported below when you will try to execute any query:
OLE DB provider "MSDASQL" for linked server "HiveSample" returned message "[Microsoft][ODBC Driver Manager] The specified DSN contains an architecture mismatch between the Driver and Application".
Msg 7303, Level 16, State 1, Line 1 Cannot initialize the data source object of OLE DB provider "MSDASQL" for linked server "HiveSample".
The setup process is really straightforward, nothing to configure or change until the end:
As you can see in the second print screen, this driver has been developed in collaboration with SIMBA Technologies Inc. , at the end of the installation it’s recommended to go into the installation folder, by default for 64-bit is “C:\Program Files\Microsoft Hive ODBC Driver” and look at the following files/documents:
- “THIRDPARTYNOTICES.TXT”: this is an extract from the file content:
Includes material furnished by Simba Technologies, Inc.Used under license. Note: While Microsoft is not the author of the files below, Microsoft is offering you a license subject to the terms of the Microsoft Software License Terms for Microsoft Hive ODBC Driver (the “Microsoft Program”). Microsoft reserves all other rights. The notices below are provided for informational purposes only and are not the license terms under which Microsoft distributes these files.
- “Microsoft Hive ODBC Driver Install Guide.pdf”: contains lots of very useful information on usage of the driver; I would recommend to read at least sections titled "SQL Query versus HiveQL Query" and "SQL Connector";
Once installed, a sample data source is already pre-configured, but need modifications if you want to reuse for connecting to your HDInsight cluster:
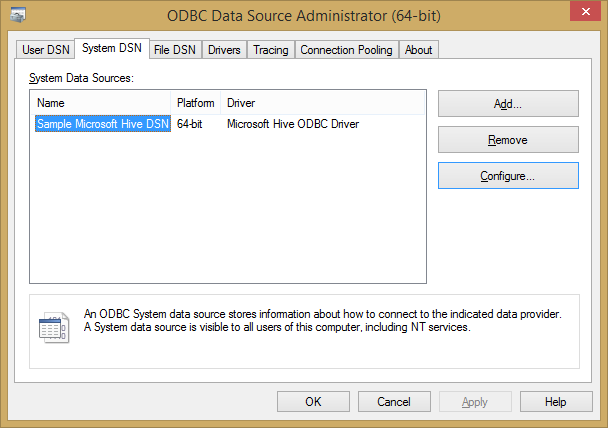
Click on “Configure” and adjust parameters as reported in the print screen below:
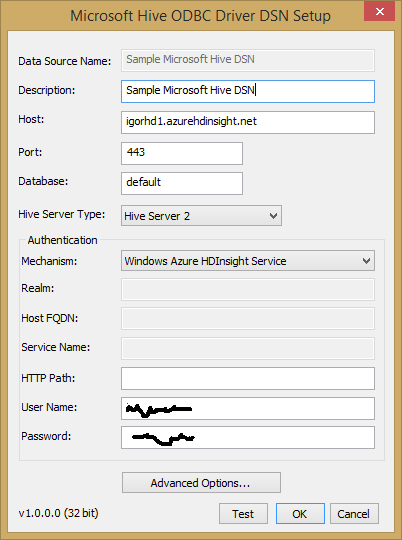
NOTE: If you already tested a beta version of this ODBC driver in earlier HDInsight release, please be aware that the TCP port used has been changed from 563 to 443.
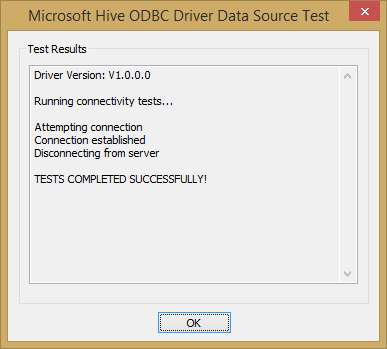
Insert “User Name” and “Password” based on your selection when provisioned the HDInsight cluster and then click on “Test” button; if everything is correct, you should receive the following output:
Be very careful also with the “Advanced Options” button, there are some important parameters to be aware of:
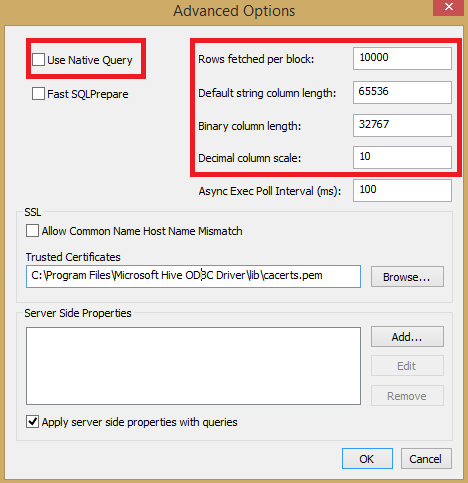
- “Use Native Query”: if you enable this checkbox, the ODBC driver will *not* try to convert TSQL into HiveQL, then you should use it only if you are 100% sure you are submitting pure HiveQL statements; since the context of this blog is SQL Server, you should leave it disabled/unchecked.
- “Rows fetched per block”: if you are going to fetch a large amount of records, tuning this parameter may be required to ensure optimal performances.
- Data types: be very careful with the data type lengths and precisions specified in the right side of the above dialog since they may affect how data is returned, causing incorrect information to be returned due to loss of precision and/or truncation.
Now it’s time to open SQL Server Management Studio and create a “Linked Server” definition using the TSQL statement below:
EXEC master.dbo.sp_addlinkedserver @server = N'HiveSample', @srvproduct=N'HIVE', @provider=N'MSDASQL', @datasrc=N'Sample Microsoft Hive DSN', @provstr=N'Provider=MSDASQL.1;Persist Security Info=True;User ID=<<user_name>>; Password=<<password>>;'
You can now see the new “Linked Server” definition along with the sample table existing in the HIVE data warehouse on HDInsight cluster:
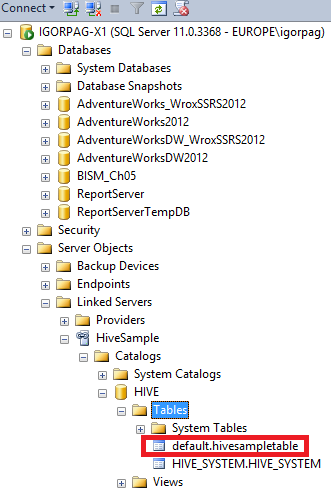
Now I want to run a simple SELECT statement to access data in the default HIVE sample table:
select * from [HiveSample].[HIVE].[default].hivesampletable
Unfortunately something went wrong and got the following error:
OLE DB provider "MSDASQL" for linked server "HiveSample" returned message "Requested conversion is not supported.".
Msg 7341, Level 16, State 2, Line 1 Cannot get the current row value of column "[MSDASQL].clientid" from OLE DB provider "MSDASQL" for linked server "HiveSample".
This seems very strange to me since [clientid] in HIVE is a basic “string” type and the ODBC connector should be able to translate. Trusting the error message above, I was able to successfully execute the above query introducing an explicit type conversion in TSQL using CONVERT function as shown below and changing the "default string column lenght" (ODBC DSN advanced options) parameter value to (8000):
select convert(varchar(8000),[clientid]) from [HiveSample].[HIVE].[default].hivesampletable
The reason for the error above is that HIVE does *not* provide the maximum data length for “string” columns in the column metadata, then you need to use explicit cast/convert techniques in SQL Server TSQL to deal with it. Obviously you can use different lower numbers from 8000, since it's the maximum char length you can specify without using MAX qualifier in VARCHAR, it's up to you, but be sure to set the ODBC DSN advanced options parameters accordingly.
IMPORTANT: Be very careful with the parameter values contained in the ODBC “Advanced Options” property page, as described early in this post, since you may retrieve incorrect data due to precision lost and/or truncation.
In addition to the four-parts syntax used above, you can also use the OPENQUERY syntax as reported in the example below:
select * from openquery (HiveSample, ' select sessionid from hivesampletable)
If you want to check the HIVE native data type of a specific table, you can use the following Power Shell command:
Invoke-Hive "describe hivesampletable"
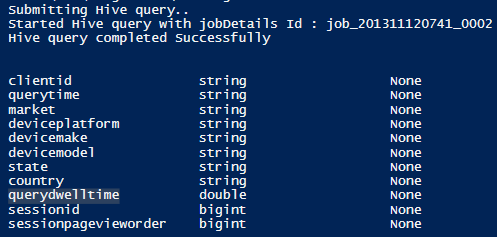
NOTE: In order to use the Power Shell cmdlet for HDInsight, you need to follow the instructions below:
Install and configure PowerShell for HDInsight
Another useful query, still using Power Shell for submission, is reported below to show all the tables present in the HIVE metastore:
Invoke-Hive "show tables"
When you submit queries to HDInsight HIVE using the ODBC connector, be aware that every query will be translated to a Hadoop Map-Reduce Job, then the execution time may be long: if in your SQL Server installation you normally use a query timeout different from the default value of (0), that is infinite wait, you may have to change it, otherwise you will get an error before HDInsight will be able to process your query/job. In the properties of the “Linked Server”, you can see and eventually change the connection and query timeout values:
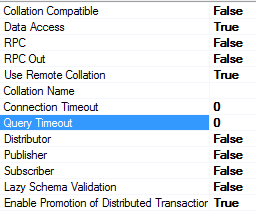
You may also have to change the SQL Server instance wide timeout value for “Query Timeout”, since by default is equal to 600 seconds (10 minutes), using the script below as an example for infinite wait:
sp_configure 'show advanced options',1
go
reconfigure
go
sp_configure 'remote query timeout (s)',0
go
reconfigure
go
Finally, remember that this is v1 of this new technology, then not all HIVE aspects are covered by the driver, then I would recommend you to check if everything you need is included. This is a short list of what is supported and what is not yet:
- The following data types are supported: TINYINT, SMALLINT, INT, BIGINT, FLOAT, DOUBLE, DECIMAL, BOOLEAN, STRING , TIMESTAMP;
- The aggregate data types (ARRAY, MAP and STRUCT) are not yet supported. Columns of aggregate types are treated as STRING columns;
- Quoted Identifiers—When quoting identifiers, HiveQL uses back quotes (`) while SQL uses double quotes ("). Even when a driver reports the back quote as the quote character, some applications still generate double-quoted identifiers.
- HiveQL does not support the AS keyword between a table reference and its alias.
- JOIN, INNER JOIN and CROSS JOIN—SQL INNER JOIN and CROSS JOIN syntax is translated to HiveQL JOIN syntax.
- TOP N/LIMIT—SQL TOP N queries are transformed to HiveQL LIMIT queries.
If you are a SQL Server DBA and then an expert of TSQL language, and want to know exactly which syntax and HiveQL syntax are supported, you can see the official link to the Hadoop HIVE documentation on Apache web site:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual
That’s all SQL Server folks…. Welcome to the Big data world!