Basic Multi-Level Grids
Hi Folks,
Last time, we highlighted several problems with a simple grid index. If you don't recall---and since it's been a while, that wouldn't be a surprise---you may want to review them. In this post I'll start to describe how we get around them.
In SQL Server, we don't use a simple grid like the one described. Instead, we use a multi-level grid, which ends up looking very much like a quad tree. Basically, instead of having one grid level, we have four, with each lower-level grid nested in the one above.
Let's look at an example. If we have a 2x2 grid at each level, then we can tile the object below with three tiles at the top-level grid:
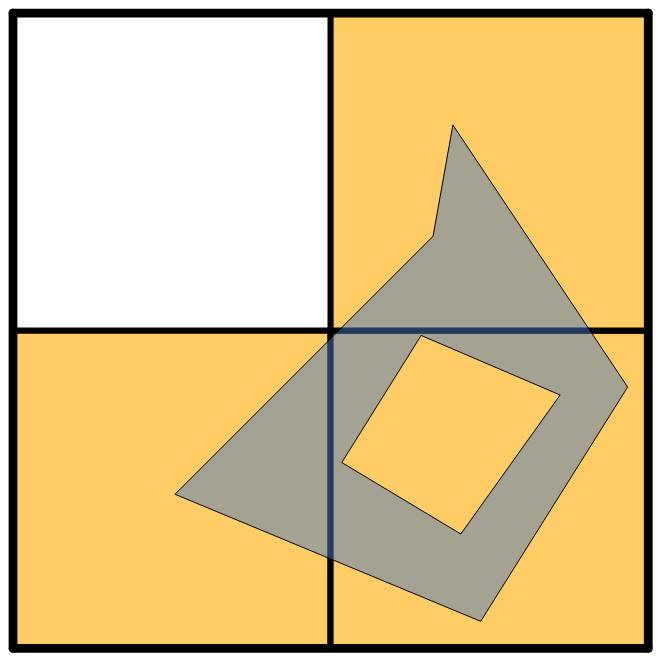
These tiles cover the object, which is a property we want to maintain for our indexing scheme, but there's a lot of extra coverage. This extra means we're likely to have a good number of false positives from our primary filter. We can go to a second-level gridding instead:
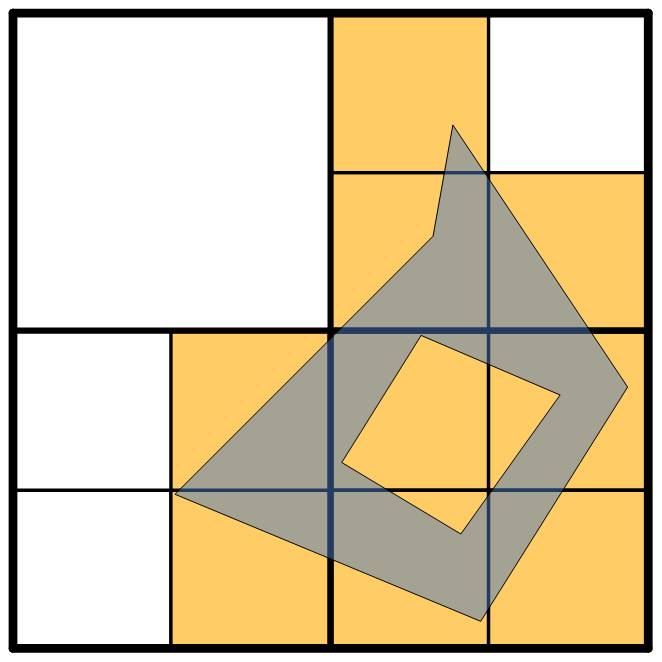
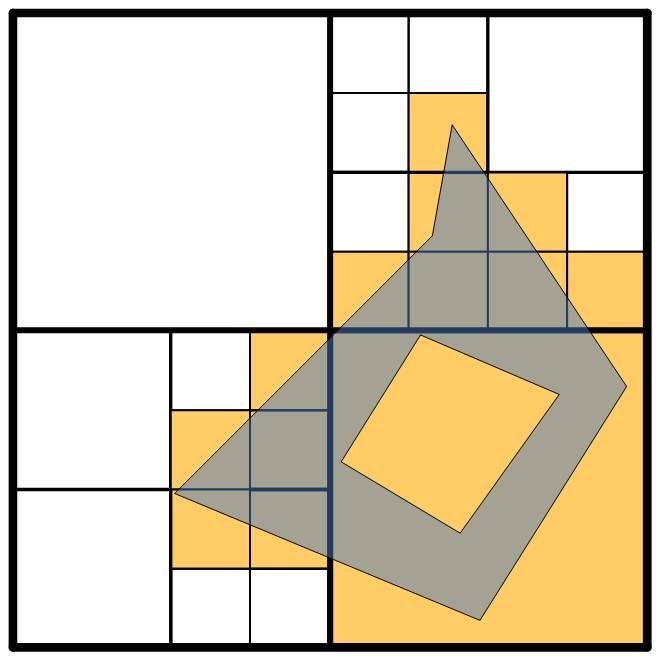
At this level, we've trimmed some of the extra slop from the edges, but our description of the object has become more complex as well. With our four levels, we can push this even further---here's what a fourth-level tiling of the object would look like:
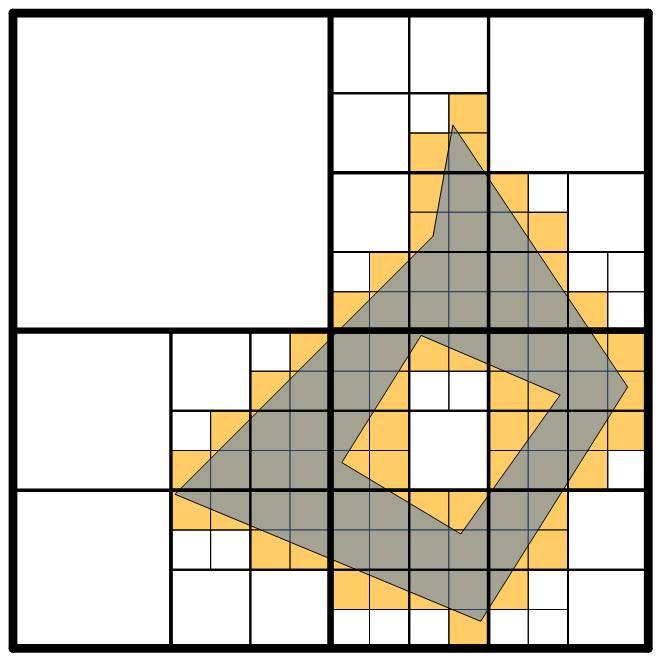
This description is nice and tight---there's very extra covering of the object---but it's also very complicated. What's key to keeping the complexity down is that we don't require that all object use the same level tiling, nor do we require that all tiles for a particular object all be at the same level. We can mix as we wish.
The ability to mix levels in our tiling leads us to two optimizations. The first, which is always used, is that if we find that all subtiles of a particular tile are touched by the object, then we won't further subdivide the cell. Subdividing gives us nothing but more cells. Perhaps this is clearer visually; below is a picture of the same tiling above with this optimization applied:
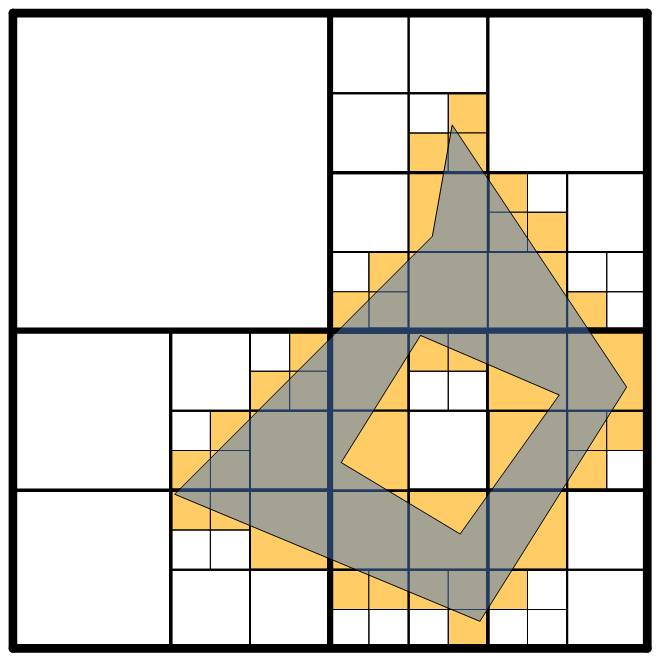
As you can see, this greatly reduces the number of tiles we have, and does so by mixing levels. A second way to reduce tiles is through an explicit limit. We default this limit to 16, but the user can tweak it to their liking. When we decompose an object, we do a breath-first walk down the tree decomposing tiles, and we stop when we hit the pre-defined limit. E.g., we might end up with:
There's much more to say about this, but before I leave it for now, let me point out that while these examples use 2x2 decompositions at each level, we use more. The exact amount is, in fact, adjustable: the user can set each level to low (4x4) medium (8x8) or high (16x16).
How should the user tweak these various parameters? It's hard to give general advice, as it's a very data- and query-dependent calculation, but we feel that we have picked some defaults that will work well for most people. We may have better advice as more people start using the index and we get reports on what worked for them. (Yes, we're begging you to send us your findings!)
Next time we'll continue with some more details about the mult-level grid.
Cheers,
-Isaac