Exciting New Templates in Azure ML!
This post is by Xinwei Xue, Senior Data Scientist at Microsoft
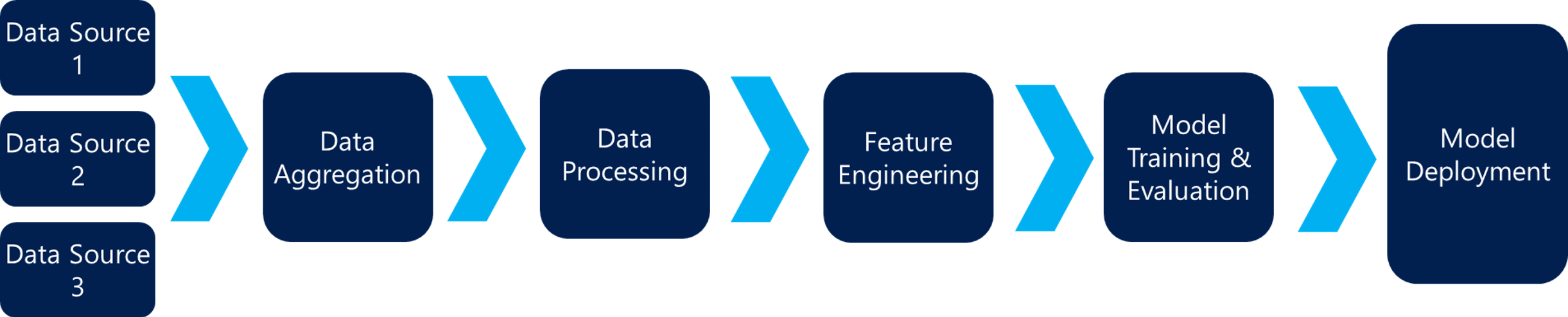
We are excited to announce the availability of three new templates in Azure ML Studio – for online fraud detection, retail forecasting and text classification.Templates are different from Azure ML sample experiments – they demonstrate industry best practices and common building blocks used in an ML solution for a specific domain, starting from data preparation, data processing, feature engineering, model training to model deployment (as a web service) as shown in the picture below.
The goal for Azure ML templates is to make data scientists more productive in building and deploying their custom ML solutions on the cloud. Templates include a collection of pre-configured Azure ML modules as well as custom R scripts in the Execute R Script modules to enable an end-to-end solution.
Each Azure ML template includes the following:
- A data schema applicable to the specific domain
- Domain specific data processing and feature engineering
- Models training algorithms fit to the specific domain
- Domain specific evaluation metric (if applicable)
Templates are iterative in nature and designed for the ease of understanding and experimentation by users. Each template has multiple steps and multiple experiments following the diagram below, with detailed documentation and instructions on how to use the template available in the Azure ML Gallery.
Fraud Detection
Fraud detection is one of the earliest industrial applications of data mining and ML. Fraud detection is typically handled as a binary classification problem, and the class population is unbalanced because instances of fraud are usually very rare compared to the overall volume of transactions.
When fraudulent transactions are discovered, businesses typically take measures to block certain accounts from transacting as soon as possible, to prevent further losses. Therefore, account-level model performance metrics, in addition to transaction level metrics such as ROC curves are often important. Therefore, account-level tagging and sampling are often applied instead of transaction-level. As is typical for binary classification applications, count-based features are generated (using the Learning with Count Modules) to increase the model prediction power.
This template walks through the end-to-end process using an online purchase transaction fraud detection scenario. The methodology in this template can be easily extended to fraud detection scenarios in other domains. The fraud detection experiments can be found below (or can be searched from the ML gallery using “fraud detection” within quotes).
Online Fraud Detection: Step 1 of 5: Generate tagged data
Online Fraud Detection: Step 2 of 5: Data Preprocessing
Online Fraud Detection: Step 3 of 5: Feature engineering
Online Fraud Detection: Step 4 of 5: Train and Evaluation Model
Online Fraud Detection: Step 5 of 5: Publish as web service
Retail Forecasting
Accurate and timely forecasting is an essential enabler of inventory planning, product pricing, promotion and placement and plays a critical role in the success of retail businesses. As part of Azure ML, we now have a template for data scientists to easily build and deploy a retail forecasting solution. The template walks through steps in the process of building a pipeline that automatically provides weekly sale forecasts for each store and each retail product. The template presents both time-series and regression approaches.
Our retail forecasting experiments can be found below (or can be searched from the ML gallery using “retail forecasting” within quotes).
Retail Forecasting: Step 1 of 6, data preprocessing
Retail Forecasting: Step 2 of 6, train time series models
Retail Forecasting: Step 3 of 6, feature engineering
Retail Forecasting: Step 4 of 6, train regression models
Retail Forecasting: Step 5 of 6, evaluate models
Retail Forecasting: Step 6A of 6, deploy a web service with a time series model
Retail Forecasting: Step 6B of 6, deploy a web service with a regression model
Text Classification
There are broad applications of text classification: categorizing news articles into topics, organizing web pages into hierarchical categories, filtering spam, sentiment analysis, predicting user intent from search queries, routing support tickets, analyzing customer feedback and so forth.
The goal of text classification is to assign a piece of text one or more predefined classes or categories. That piece of text can be a document, news article, search query, email, tweet, support request, customer feedback, user product review etc.
This template demonstrates how to do text processing, feature engineering, train a sentiment classification model and publish it as a web service using a Twitter sentiment dataset. The text classification experiments can be found below (or can be searched from the ML gallery using “text classification” within quotes).
Text Classification: Step 1 of 5, data preprocessing
Text Classification: Step 2 of 5, text preprocessing
Text Classification: Step 3A of 5, n-grams TF feature extraction
Text Classification: Step 3B of 5, unigrams TF-IDF feature extraction
Text Classification: Step 4 of 5, train and evaluate models
Text Classification: Step 5A of 5, deploy web service with n-grams TF model
Text Classification: Step 5B of 5, deploy web service with unigrams TF-IDF model
We plan to publish many more such templates, so do stay tuned. If you have thoughts on improving any of these templates or suggestions for new ones to create, do let us know through your comments below.
Xinwei