Hello 2018 | Recap of "Top 10" Posts of 2017
As we ring in the new year, we'd like to kick things off in our usual fashion – with a quick recap of our most popular posts from the year just concluded. So here are our "Top 10" posts from 2017, sorted in increasing order of readership – enjoy!
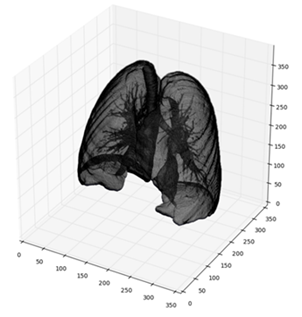
10. Quick-Start Guide to the Data Science Bowl Lung Cancer Detection Challenge, Using Deep Learning, Microsoft Cognitive Toolkit and Azure GPU VMs
Lung cancer – which is the leading cancer when it comes to mortality in both women and men in the US – suffers from a low rate of early diagnosis. The Data Science Bowl competition aimed to help by having participants use machine learning to determine whether CT scans of the lung have cancerous lesions or not. Success in the competition required that data scientists get started quickly and iterate rapidly. Through this post, we showed how to compute features of scanned images with a pre-trained Convolutional Neural Network (CNN), and use these features to classify scans as cancerous or not using a boosted tree – all within one hour.
9. Machine Learning for Developers – How to Build Intelligent Apps & Services
Traditionally, developers would build rules-based engines into their source code. When their knowledge of a problem became clearer, the rules engine would be modified, and existing apps would be patched and updated. With ML, however, we are training machines to recognize patterns and relationships in data across a wide group of problem sets. This training is used to build an ML model, which can be thought of as an API in that it accepts a data set and returns a result that can be acted upon. When more data is acquired, the model can be retrained to produce more accurate predictions. Couple this approach with the cloud and we can publish models online and build apps that consume them, thus removing the need for local rules engines. This means we can retrain ML models without having to touch our apps and in many cases, we remove the need to ever patch or update. This post helps demystify these topics from the viewpoint of a software developer.

8. A Plethora of Microsoft Training Options on AI, Machine Learning & Data Science, including MOOCs
How to learn about all things AI and ML from Microsoft and stay in the loop on our future offerings. Several hands-on training options are included.

7. Announcing Microsoft Machine Learning Library for Apache Spark
Our announcement of the Microsoft Machine Learning library for Apache Spark. This library helps you increase your productivity on Spark, increase your rate of experimentation, and take advantage of cutting-edge ML techniques including deep learning on very large datasets.

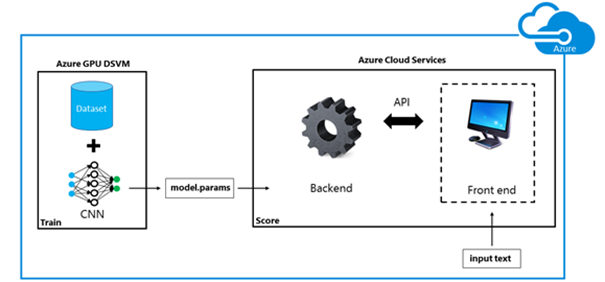
6. Cloud-Scale Text Classification with Convolutional Neural Networks on Microsoft Azure
How to create an end-to-end text classification system using deep learning on Azure. The CNNs discussed in this post were trained at the character level, i.e. we do not use words or groups of words as the input to a network. Rather, we encode each sentence as a matrix, mapping each character of the sentence to a dictionary. The resulting matrix is fed into a convolutional network, which can learn increasingly abstract hierarchical representations of this input. These features are used to determine the class of the text. We demonstrate how easy it is to train one of these networks on our high-performance GPU DSVMs by distributed computation with 4 GPUs. Once the model is trained, one can quickly create a web service in Azure Web Apps to host the prediction system. The code used for this is open source and accessible via this post.
5. Microsoft Updates its Deep Learning Toolkit
The Microsoft Cognitive Toolkit, previously known as CNTK, is a system for deep learning that is used extensively by a variety of Microsoft products, by companies worldwide with a need to deploy deep learning at scale, and by students interested in the latest algorithms and techniques to speed advances in areas such as image recognition, speech and more. Cognitive Toolkit can be used on-premises or in the cloud with Azure GPUs, and is available on GitHub via an open source license.

4. Introducing the New Data Science Virtual Machine on Windows Server 2016
We introduced the Windows Server 2016 version of our extremely popular Azure Data Science Virtual Machine (DSVM), and it included many new additions such as unified support for Deep Learning on GPU or CPU-only based virtual machines, and an upgrade to the latest version of the Microsoft R Server 9.1 (Note: The latter product was renamed the Microsoft Machine Learning Server later in 2017).

3. Introducing Microsoft Machine Learning Server 9.2 Release
We launched Microsoft Machine Learning Server 9.2, our most comprehensive ML / AI platform for the enterprise, with many exciting updates such as full data science lifecycle support (i.e. for data preparation, modeling and operationalization), Python as a peer to R, and a repertoire of high performance distributed ML and advanced analytics algorithm packages. This flexible platform offers a choice of languages and brings together the best of open source and proprietary innovations. It enables best-in-class operationalization support for batch and real-time. We also announced simplified licensing as part of this announcement.

2. Free edX Course – Introduction to Artificial Intelligence
AI is widely expected define the next generation of software. Given all the hype and confusing terminology out there, we created an edX overview course for those of you who are just getting started. The course was designed to help participants explore key concepts and underlying technologies, and to get started with using AI to build intelligent apps.

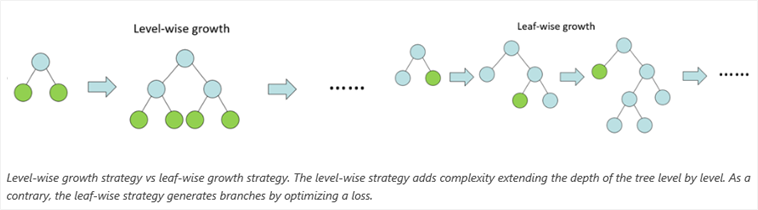
1. Lessons Learned From Benchmarking Fast Machine Learning Algorithms
Our top post of 2017 is relevant to pretty much anybody who wants their machine learning to be quicker: Boosted decision trees are responsible for more than half the winning solutions in ML challenges, according to trusted sources. In addition to superior performance, these algorithms have practical appeal as they require minimal tuning. This post evaluates two popular tree boosting software packages, XGBoost and LightGBM, including their GPU implementations. We explain the algorithms behind these libraries and evaluate them across different datasets. All code is open source and included as part of the post.
So, there you have it! Stay tuned to this channel for more exciting ML and AI platform news from Microsoft through 2018. And here's wishing all our readers a very happy and prosperous new year!
ML Blog Team