Rapid Progress in Automatic Image Captioning
This blog post is authored by John Platt , Deputy Managing Director and Distinguished Scientist at Microsoft Research.
I have been excited for many years now in the grand challenge of image understanding. There are as many definitions of image understanding as there are computer vision researchers, but if we can create a system that can automatically generate descriptive captions of an image as well as a human, then I think we’ve achieved the goal.
This summer, about 12 interns and researchers at Microsoft Research decided to “go for it” and create an automatic image captioning software system. Given all of the advances in deep learning for object classification and detection, we thought it was time to build a credible system. Here’s an example output from our system: which caption do you think was generated by a person and which by the system?

- An ornate kitchen designed with rustic wooden parts
- A kitchen with wooden cabinets and a sink
[The answer is below]
The project itself was amazingly fun to work on; for many of us, it was the most fun we've had at work in years. The team was multi-disciplinary, involving researchers with expertise in computer vision, natural language, speech, machine translation, and machine learning.
Not only was the project great to work on: I’m also proud of the results, which are in a preprint. You can think about a captioning system as a machine translation system, from pixels to (e.g.) English. Machine translation experts use the BLEU metric to compare the output of a system to a human translation. BLEU breaks the captions into chunks of length (1 to 4 words), and then measures the amount of overlap between the system and human translations. It also penalizes short system captions.
To understand the highest possible BLEU score we could attain, we tested one human-written caption (as a hypothetical “system”) vs. four others. I’m happy to report that, in terms of BLEU score, we actually beat humans! Our system achieved 21.05% BLEU score, while the human “system” scored 19.32%.
Now, you should take this superhuman BLEU score with a gigantic boulder of salt. BLEU has many limitations that are well-known in the machine translation community. We also tried testing with the METEOR metric, and got somewhat below human performance (20.71% vs 24.07%).
The real gold standard is to conduct a blind test and ask people which caption is better (sort of like what I asked you above). We used Amazon’s Mechanical Turk to ask people to compare pairs of captions: is one better, the other one, or are they about the same? For 23.3% of test images, people thought that the system caption was the same or better than a human caption.
The team is pretty psyched about the result. It’s quite a tough problem to even approach human levels of image understanding. Here’s a tricky example: 
System says: “A cat sitting on top of a bed”
Human says: “A person sitting on bed behind an open laptop computer and a cat sitting beside and looking at the laptop screen area”
As you can see, the system is perfectly correct, but the human uses his or her experience in the world to create a much more detailed caption.
[The answer to the puzzle, above: the system said “A kitchen with wooden cabinets and a sink”]
How it works
At a high level, the system has three components, as shown below:
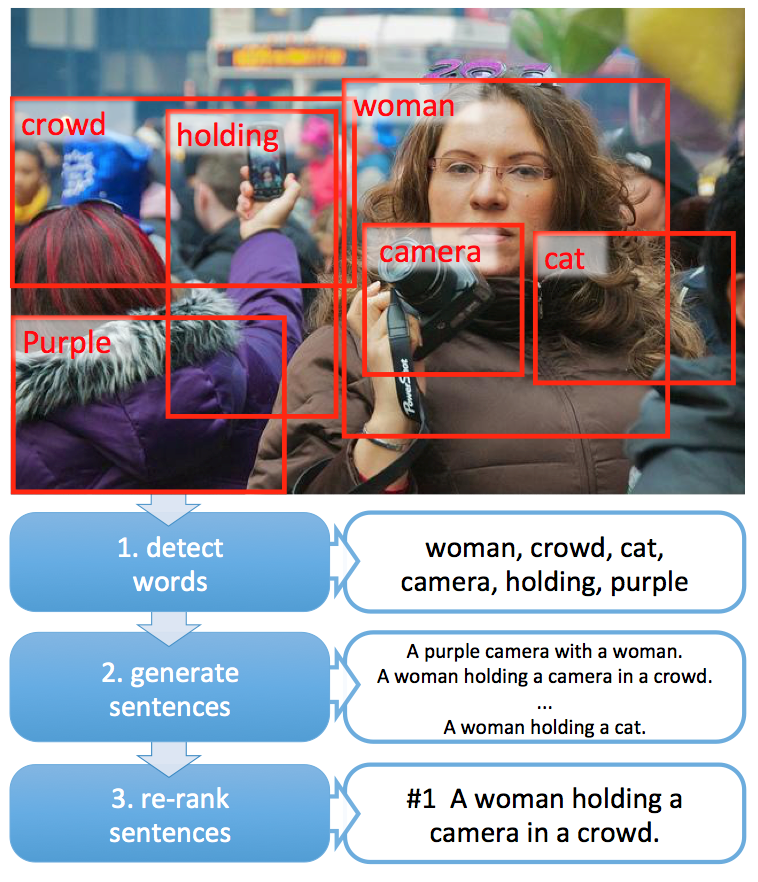
First, the system breaks the image into a number of regions that are likely to be objects (based on edges). Then a deep neural networks is applied to each region to generate a high-level feature vector that captures relevant visual information. Next, we take that feature vector as input to a neural network that is trained to produce words that appear in the relevant captions. During that training, we don’t hand-assign each word to each region; instead, we use a trick (called “Multiple Instance Learning”) to let the neural network figure out which region best matches each word.
The result is a bag of words that are detected within the image, in no particular order. It’s interesting to look at which regions caused which words to be detected:

Next, we put together the words in a sensible sentence, using a language model. You may have heard of language models: they take a training corpus of text (say, Shakespeare), and generate new text that “sounds like” that corpus (e.g., new pseudo-Shakespeare). What we do is train a caption language model to produce new captions. We add a “steering wheel” to the language model, by creating a “blackboard” of the words detected from the image. The language model is encouraged to produce those words, and as it does, it erases each one from the “blackboard”. This discourages the system from repeating the same words over and over again (which I call the Malkovich problem).
The word detector and the language model are both local, meaning they only look at one segment of the image to generate each word, and only consider one word at a time to generate. There is no sense of global semantics or appropriateness of the caption to the image. To solve this, we create a similarity model, using deep learning to learn which captions are most appropriate for which images. We re-rank using this similarity model (and features of the overall sentence) and produce the final answer.
This, of course, is a high-level description of the system. You can find out more in the preprint.
Plenty of research activity
Sometimes, an idea is “in the air” and gets invented by multiple groups at the same time. That certainly seems to be true of image captioning. Before 2014, there were previous attempts at automatic image captioning systems that did not exploit deep learning. Some examples are Midge and BabyTalk. We certainly benefited from the experience of these previous systems.
This year, there has been a delightful Cambrian explosion of image captioning systems based on deep learning. It appears as if many groups were aiming towards submitting papers to the CVPR 2015 conference (with a due date of Friday, Nov 14). The papers I know about (from Andrej Karpathy and my co-authors from Berkeley) are:
Baidu/UCLA: https://arxiv.org/pdf/1410.1090v1.pdf
Berkeley: https://arxiv.org/abs/1411.4389
Google: https://googleresearch.blogspot.com/2014/11/a-picture-is-worth-thousand-coherent.html
Stanford: https://cs.stanford.edu/people/karpathy/deepimagesent/
University of Toronto: https://arxiv.org/pdf/1411.2539v1.pdf
This type of collective progress is just awesome to see. Image captioning is a fascinating and important problem, and I would like to better understand the strengths and weaknesses of these approaches. (I note that several people used recurrent neural networks and/or LSTM models). As a field, if we can agree on standardized test sets (such as COCO), and standard metrics, we'll continue to move closer to that goal creating a system that can automatically generate descriptive captions of an image as well as a human. The results from our work this summer and from others suggests we're moving in the right direction.