The Cloud Data Science Process
This post is by Mona Soliman Habib, Principal Data Scientist in the Information Management & Machine Learning team at Microsoft.
Data scientists solve real life business problems by applying a broad set of technical skills to explore, transform, and model data of various shapes and forms to produce actionable predictions. The Cloud Data Science Process (CDSP) describes the steps typically traversed in the course of completing a data science project. The steps in this process have also been conceptualized in both data mining and data science contexts as a life cycle or workflow. Here are a few examples:
The CRoss Industry Standard Process for Data Mining (CRISP-DM) model
All of these conceptualizations of the data science process are in agreement about the basic core steps involved and about the iterative nature of the process.
Here are the core steps of the data science process:
Business understanding
Data understanding
Data acquisition
Data processing
Hypothesis and modeling
Evaluation and metrics
Model deployment
Operationalization
Monitoring
Model maintenance and optimization
Each of the core steps can be further broken down when diving into the specifics of the problem at hand. For instance, the business understanding step may include:
An initial opportunity assessment
Identification of the business questions that are candidates for data science solutions,
Problem formulation
Cost-benefit analysis
Data acquisition, to take another step, may include:
Data collection from public and/or private sources
Data storage on premise and/or in the cloud
Data aggregation from heterogeneous sources
Data movement
Human labeling exercises
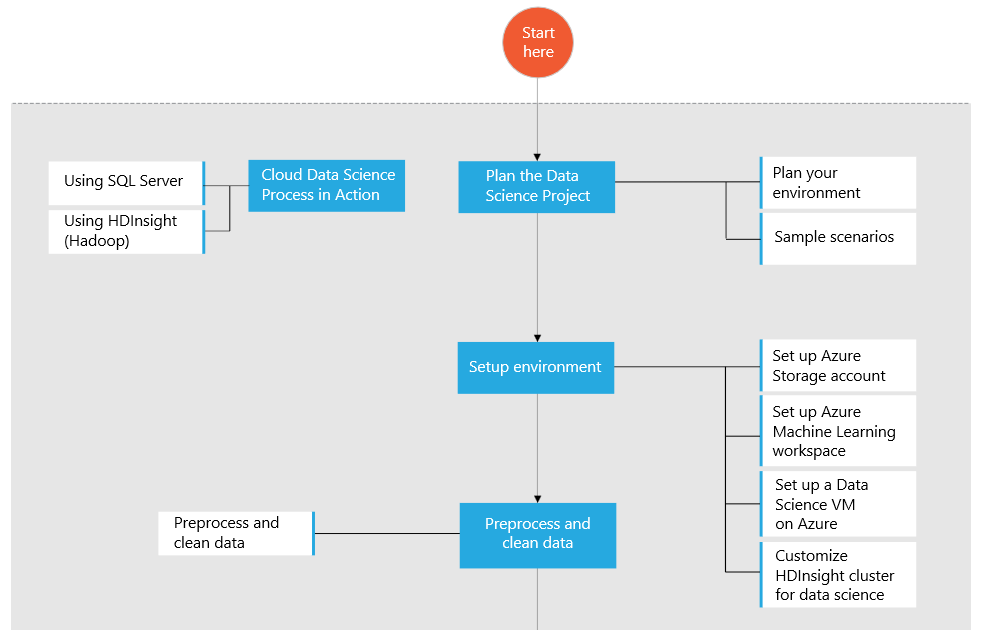
Data scientists use a variety of tools, languages and computing environments to address the varying scale and complexity of data science projects. The Cloud Data Science Process demonstrates how to use the Azure platform to conduct end-to-end data science projects in the cloud. Starting from raw data and guiding you through all of the steps up to and including the building of a fully managed, operationalized model using Azure ML web service APIs. The CDSP map walks you through each of the typical data science tasks, such as ingesting data from various sources, preparing it for modeling in Azure ML, and creating operationalized models that can be consumed by end user applications. The CDSP showcases solutions and scenarios of varying scale and complexity. It recommends Azure resources and other programming languages and tools for handling data, depending on its location, size and complexity. It also provides supporting artifacts such as guides, tutorials, templates, and published code. The CDSP will continue to evolve over time to cover new scenarios and technologies.
Planning the data science project is the first step of the CDSP. This step helps guide you through a series of choices you must make concerning options that will be based on the data characteristics (the location, size, format, and content type), required pre-processing, familiarity with the data and the preference of cloud environment to use. The following steps in the CDSP include setting up the cloud data science environment, data pre-processing and cleaning, data preparation for modeling, modeling in Azure ML, deploying and publishing the model as a web service, and finally consuming the model in applications via the web service API.
Several end-to-end walkthroughs that use the public NYC Taxi Trips dataset have been provided to familiarize you with the CDSP as implemented in Azure. One uses SQL Server VM and the other uses HDInsight (Hadoop) Hive tables for managing the data. More sample scenarios and links to the walkthroughs are available in the Cloud Data Science Process in Azure Machine Learning article.
Each of these walkthroughs addresses three prediction tasks based on the tip amounts recorded for the taxi fares:
Binary classification: to predict whether or not a tip was paid for a trip.
Multiclass classification: to predict the range of tip paid for the trip, divided into 5 bins, e.g., no tip class, tip is between $0 and $5, tip is between $5 and $10, etc.
Regression task: to predict the amount of tip paid for a trip.
To provide some additional details here to give you the flavor of one of the scenarios covered, the end-to-end walkthrough using SQL Server follows these steps in the CDSP:
Set up a data science virtual machine in Azure, which serves as a SQL Server and an IPython Notebook server, and is pre-configured with useful Azure and data science tools.
Get the data from its public source.
Bulk import the data into a SQL Server database using partitioned tables for parallel loading and efficient querying.
Explore the data, engineer features, and sample the data in SQL Server Management Studio.
Explore the data, engineer features, and sample the data in IPython Notebook.
Ingest the data for modeling into Azure ML.
Train various models for binary classification, multiclass classification, and regression.
Publish model(s) as web services, ready for consumption in C# applications, R, Python, and Excel via web service APIs.
A webinar recording that describes the CDSP and an end-to-end walkthrough using SQL Server is available here. Do share your thoughts and feature requests to extend the Cloud Data Science Process, your feedback is very important to us.
Mona