Inside Vista SP1 File Copy Improvements
Windows Vista SP1 includes a number of enhancements over the original Vista release in the areas of application compatibility, device support, power management, security and reliability. You can see a detailed list of the changes in the Notable Changes in Windows Vista Service Pack 1 whitepaper that you can download here. One of the improvements highlighted in the document is the increased performance of file copying for multiple scenarios, including local copies on the same disk, copying files from remote non-Windows Vista systems, and copying files between SP1 systems. How were these gains achieved? The answer is a complex one and lies in the changes to the file copy engine between Windows XP and Vista and further changes in SP1. Everyone copies files, so I thought it would be worth taking a break from the “Case of…” posts and dive deep into the evolution of the copy engine to show how SP1 improves its performance.
Copying a file seems like a relatively straightforward operation: open the source file, create the destination, and then read from the source and write to the destination. In reality, however, the performance of copying files is measured along the dimensions of accurate progress indication, CPU usage, memory usage, and throughput. In general, optimizing one area causes degradation in others. Further, there is semantic information not available to copy engines that could help them make better tradeoffs. For example, if they knew that you weren’t planning on accessing the target of the copy operation they could avoid caching the file’s data in memory, but if it knew that the file was going to be immediately consumed by another application, or in the case of a file server, client systems sharing the files, it would aggressively cache the data on the destination system.
File Copy in Previous Versions of Windows
In light of all the tradeoffs and imperfect information available to it, the Windows file copy engine tries to handle all scenarios well. Prior to Windows Vista, it took the straightforward approach of opening both the source and destination files in cached mode and marching sequentially through the source file reading 64KB (60KB for network copies because of an SMB1.0 protocol limit on individual read sizes) at a time and writing out the data to the destination as it went. When a file is accessed with cached I/O, as opposed to memory-mapped I/O or I/O with the no-buffering flag, the data read or written is stored in memory, at least until the Memory Manager decides that the memory should be repurposed for other uses, including caching the data of other files.
The copy engine relied on the Windows Cache Manager to perform asynchronous read-ahead, which essentially reads the source file in the background while Explorer is busy writing data to a different disk or a remote system. It also relied on the Cache Manager’s write-behind mechanism to flush the copied file’s contents from memory back to disk in a timely manner so that the memory could be quickly repurposed if necessary, and so that data loss is minimized in the face of a disk or system failure. You can see the algorithm at work in this Process Monitor trace of a 256KB file being copied on Windows XP from one directory to another with filters applied to focus on the data reads and writes:
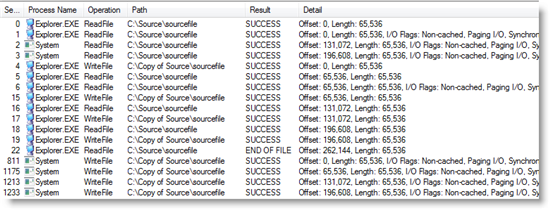
Explorer’s first read operation at event 0 of data that’s not present in memory causes the Cache Manager to perform a non-cached I/O, which is an I/O that reads or writes data directly to the disk without caching it in memory, to fetch the data from disk at event 1, as seen in the stack trace for event 1:

In the stack trace, Explorer’s call to ReadFile is at frame 22 in its BaseCopyStream function and the Cache Manager invokes the non-cached read indirectly by touching the memory mapping of the file and causing a page fault at frame 8.
Because Explorer opens the file with the sequential-access hint (not visible in trace), the Cache Manager’s read-ahead thread, running in the System process, starts to aggressively read the file on behalf of Explorer at events 2 and 3. You can see the read-ahead functions in the stack for event 2:
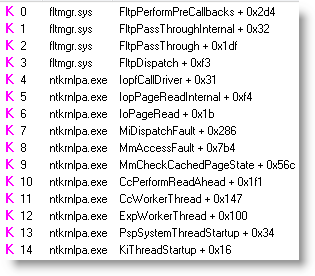
You may have noticed that the read-ahead reads are initially out of order with respect to the original non-cached read caused by the first Explorer read, which can cause disk head seeks and slow performance, but Explorer stops causing non-cached I/Os when it catches up with the data already read by the Cache Manager and its reads are satisfied from memory. The Cache Manager generally stays 128KB ahead of Explorer during file copies.
At event 4 in the trace, Explorer issues the first write and then you see a sequence of interleaved reads and writes. At the end of the trace the Cache Manager’s write-behind thread, also running in the System process, flushes the target file’s data from memory to disk with non-cached writes.
Vista Improvements to File Copy
During Windows Vista development, the product team revisited the copy engine to improve it for several key scenarios. One of the biggest problems with the engine’s implementation is that for copies involving lots of data, the Cache Manager write-behind thread on the target system often can’t keep up with the rate at which data is written and cached in memory. That causes the data to fill up memory, possibly forcing other useful code and data out, and eventually, the target’s system’s memory to become a tunnel through which all the copied data flows at a rate limited by the disk.
Another problem they noted was that when copying from a remote system, the file’s contents are cached twice on the local system: once as the source file is read and a second time as the target file is written. Besides causing memory pressure on the client system for files that likely won’t be accessed again, involving the Cache Manager introduces the CPU overhead that it must perform to manage its file mappings of the source and destination files.
A limitation of the relatively small and interleaved file operations is that the SMB file system driver, the driver that implements the Windows remote file sharing protocol, doesn’t have opportunities to pipeline data across high-bandwidth, high-latency networks like WLANs. Every time the local system waits for the remote system to receive data, the data flowing across the network drains and the copy pays the latency cost as the two systems wait for the each other’s acknowledgement and next block of data.
After studying various alternatives, the team decided to implement a copy engine that tended to issue large asynchronous non-cached I/Os, addressing all the problems they had identified. With non-cached I/Os, copied file data doesn’t consume memory on the local system, hence preserving memory’s existing contents. Asynchronous large file I/Os allow for the pipelining of data across high-latency network connections, and CPU usage is decreased because the Cache Manager doesn’t have to manage its memory mappings and inefficiencies of the original Vista Cache Manager for handling large I/Os contributed to the decision to use non-cached I/Os. They couldn’t make I/Os arbitrarily large, however, because the copy engine needs to read data before writing it, and performing reads and writes concurrently is desirable, especially for copies to different disks or systems. Large I/Os also pose challenges for providing accurate time estimates to the user because there are fewer points to measure progress and update the estimate. The team did note a significant downside of non-cached I/Os, though: during a copy of many small files the disk head constantly moves around the disk, first to a source file, then to destination, back to another source, and so on.
After much analysis, benchmarking and tuning, the team implemented an algorithm that uses cached I/O for files smaller than 256KB in size. For files larger than 256KB, the engine relies on an internal matrix to determine the number and size of non-cached I/Os it will have in flight at once. The number ranges from 2 for files smaller than 2MB to 8 for files larger than 8MB. The size of the I/O is the file size for files smaller than 1MB, 1MB for files up to 2MB, and 2MB for anything larger.
To copy a file 16MB file, for example, the engine issues eight 2MB asynchronous non-cached reads of the source file, waits for the I/Os to complete, issues eight 2MB asynchronous non-cached writes of the destination, waits again for the writes to complete, and then repeats the cycle. You can see that pattern in this Process Monitor trace of a 16MB file copy from a local system to a remote one:
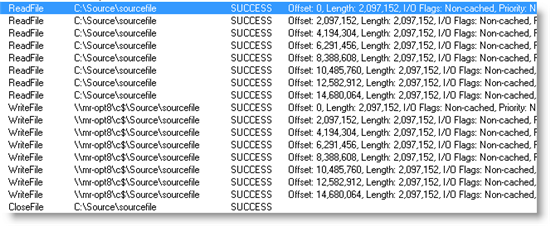
While this algorithm is an improvement over the previous one in many ways, it does have some drawbacks. One that occurs sporadically on network file copies is out-of-order write operations, one of which is visible in this trace of the receive side of a copy:

Note how the write operation offsets jump from 327,680 to 458,752, skipping the block at offset 393,216. That skip causes a disk head seek and forces NTFS to issue an unnecessary write operation to the skipped region to zero that part of the file, which is why there are two writes to offset 393,216. You can see NTFS calling the Cache Manager’s CcZeroData function to zero the skipped block in the stack trace for the highlighted event:
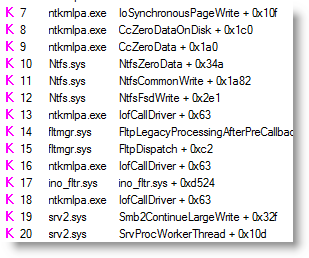
A bigger problem with using non-cached I/O is that performance can suffer in publishing scenarios. If you copy a group of files to a file share that represents the contents of a Web site for example, the Web server must read the files from disk when it first accesses them. This obviously applies to servers, but most copy operations are publishing scenarios even on client systems, because the appearance of new files causes desktop search indexing, triggers antivirus and antispyware scans, and queues Explorer to generate thumbnails for display on the parent directory’s folder icon.
Perhaps the biggest drawback of the algorithm, and the one that has caused many Vista users to complain, is that for copies involving a large group of files between 256KB and tens of MB in size, the perceived performance of the copy can be significantly worse than on Windows XP. That’s because the previous algorithm’s use of cached file I/O lets Explorer finish writing destination files to memory and dismiss the copy dialog long before the Cache Manager’s write-behind thread has actually committed the data to disk; with Vista’s non-cached implementation, Explorer is forced to wait for each write operation to complete before issuing more, and ultimately for all copied data to be on disk before indicating a copy’s completion. In Vista, Explorer also waits 12 seconds before making an estimate of the copy’s duration and the estimation algorithm is sensitive to fluctuations in the copy speed, both of which exacerbate user frustration with slower copies.
SP1 Improvements
During Vista SP1’s development, the product team decided to revisit the copy engine to explore ways to improve both the real and perceived performance of copy operations for the cases that suffered in the new implementation. The biggest change they made was to go back to using cached file I/O again for all file copies, both local and remote, with one exception that I’ll describe shortly. With caching, perceived copy time and the publishing scenario both improve. However, several significant changes in both the file copy algorithm and the platform were required to address the shortcomings of cached I/O I’ve already noted.
The one case where the SP1 file copy engine doesn't use caching is for remote file copies, where it prevents the double-caching problem by leveraging support in the Windows client-side remote file system driver, Rdbss.sys. It does so by issuing a command to the driver that tells it not to cache a remote file on the local system as it is being read or written. You can see the command being issued by Explorer in the following Process Monitor capture:

Another enhancement for remote copies is the pipelined I/Os issued by the SMB2 file system driver, srv2.sys, which is new to Windows Vista and Windows Server 2008. Instead of issuing 60KB I/Os across the network like the original SMB implementation, SMB2 issues pipelined 64KB I/Os so that when it receives a large I/O from an application, it will issue multiple 64KB I/Os concurrently, allowing for the data to stream to or from the remote system with fewer latency stalls.
The copy engine also issues four initial I/Os of sizes ranging from 128KB to 1MB, depending on the size of the file being copied, which triggers the Cache Manager read-ahead thread to issue large I/Os. The platform change made in SP1 to the Cache Manager has it perform larger I/O for both read-ahead and write-behind. The larger I/Os are only possible because of work done in the original Vista I/O system to support I/Os larger than 64KB, which was the limit in previous versions of Windows. Larger I/Os also improve performance on local copies because there are fewer disk accesses and disk seeks, and it enables the Cache Manager write-behind thread to better keep up with the rate at which memory fills with copied file data. That reduces, though not necessarily eliminates, memory pressure that causes active memory contents to be discarded during a copy. Finally, for remote copies the large I/Os let the SMB2 driver use pipelining. The Cache Manager issues read I/Os that are twice the size of the I/O issued by the application, up to a maximum of 2MB on Vista and 16MB on Server 2008, and write I/Os of up to 1MB in size on Vista and up to 32MB on Server 2008.
This trace excerpt of a 16MB file copy from one SP1 system to another shows 1MB I/Os issued by Explorer and a 2MB Cache Manager read-ahead, which is distinguished by its non-cached I/O flag:
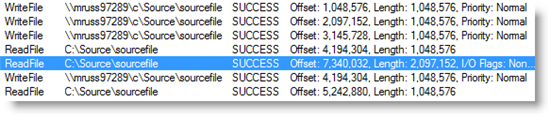
Unfortunately, the SP1 changes, while delivering consistently better performance than previous versions of Windows, can be slower than the original Vista release in a couple of specific cases. The first is when copying to or from a Server 2003 system over a slow network. The original Vista copy engine would deliver a high-speed copy, but, because of the out-of-order I/O problem I mentioned earlier, trigger pathologic behavior in the Server 2003 Cache Manager that could cause all of the server’s memory to be filled with copied file data. The SP1 copy engine changes avoid that, but because the engine issues 32KB I/Os instead of 60KB I/Os, the throughput it achieves on high-latency connections can approach half of what the original Vista release achieved.
The other case where SP1 might not perform as well as original Vista is for large file copies on the same volume. Since SP1 issues smaller I/Os, primarily to allow the rest of the system to have better access to the disk and hence better responsiveness during a copy, the number of disk head seeks between reads from the source and writes to the destination files can be higher, especially on disks that don’t avoid seeks with efficient internal queuing algorithms.
One final SP1 change worth mentioning is that Explorer makes copy duration estimates much sooner than the original Vista release and the estimation algorithm is more accurate.
Summary
File copying is not as easy as it might first appear, but the product team took feedback they got from Vista customers very seriously and spent hundreds of hours evaluating different approaches and tuning the final implementation to restore most copy scenarios to at least the performance of previous versions of Windows and drastically improve some key scenarios. The changes apply both to Explorer copies as well as to ones initiated by applications using the CopyFileEx API and you’ll see the biggest improvements over older versions of Windows when copying files on high-latency, high-bandwidth networks where the large I/Os, SMB2’s I/O pipelining, and Vista’s TCP/IP stack receive-window auto-tuning can literally deliver what would be a ten minute copy on Windows XP or Server 2003 in one minute. Pretty cool.